基于特征选择和SVM的电信客户离网预测
2019-07-12卢光跃张宏建闫真光
卢光跃, 张宏建, 闫真光, 吴 洋
(西安邮电大学 陕西省信息通信网络及安全重点实验室, 陕西 西安 710121)
随着通信和互联网行业的快速发展,电信客户更换运营商的次数日益增加。运营商获取一个新客户的成本是维持原有客户成本的5~6倍,但是每增加5%的客户,就可为运营商带来将近85%的收益。因此,有效地预测客户离网情况,可提升客户挽留率[1]。
在预测电信客户离网时,利用数据挖掘领域中的二分类问题,可对电信客户是否离网进行判断。常用的算法包括K近邻算法(K-nearest neighbors method, KNN)[2]、随机森林算法[3]和支持向量机(support vector machine,SVM)算法[4]等。KNN算法优点是预测精度高、对异常值不敏感,缺点是计算复杂度大[5];随机森林算法擅长处理高维数据,泛化能力强,但是存在过拟合问题[6];SVM算法对小样本数据的测试环境适应能力强,分类精度高,但是单一的SVM算法复杂度高[7]。随着电信业务的不断扩大,使得电信数据量增加,维度变高,导致上述几种分类算法在预测电信客户离网时出现过拟合现象,不能高效、准确地预测出电信客户离网情况。
针对数据挖掘算法在预测电信客户离网时存在的过拟合问题,提出一种基于特征选择和支持向量机(feature selection and support vector machine,FSSVM)的电信客户离网预测算法。将预处理后的电信数据进行特征选择,找出影响电信客户离网的主要因素,去除不相关或冗余特征,降低数据维度,防止过拟合;然后将处理后的数据作为SVM算法的输入数据,对客户是否离网进行分类,预测客户是否存在离网行为。
1 电信数据预处理
电信运营商数据由数值属性和非数值属性两个部分组成。数值属性可以直接使用,但是非数值属性需通过整数编码后才能使用。在预测电信客户离网时,原始数据集存在4个方面问题:数据缺失,如某些数据没有记录;数据冗余,如所在城市的编码和城市的名称是对同一特征的不同表现形式;数据非结构化,如是否贵宾(very important people VIP)、是否欠费、是否离网等特征,这类特征存在“是”和“否”两种非结构化属性;数据不规范,如欠费和通话时长具有不同的量纲。问题的存在,严重影响预测离网客户的精度,因此,在对原始数据进行离网预测前,需对数据进行预处理,消除这些问题的影响。电信数据预处理流程如图1所示。

图1 数据预处理流程
(1) 填充缺失值
根据数据本身的特点,通过删除部分数据、搁置缺失数据或者对缺失数据进行插补等方法填充不足的内容。当原始数据集数据较大时,可以采取删除少量的缺失样本使数据集完整;若原始数据有较高的完备性,或者没有明确要求必须填充缺失的内容,则可以不对原始数据进行处理;为了尽可能减少数据缺失的信息,可以通过样本的中值、中位数或者是固定的值进行数据的填充。
(2) 去除冗余特征
通过检索原数据集中多次出现的同一属性,以及不同表现形式的同一个属性去掉冗余特征。
(3) 数据结构化
在电信数据中,非数值属性是通过文字的方式进行描述,不能直接使用,需要进行整数编码。如是否为VIP、是否离网等属性,可以将“是”编码为“1”,“否”编码为“0”,使非结构化数据转变成结构化数据。
(4) 数据归一化
原始数据中某些属性量钢不统一,影响特征选择。如通话费用、短信发送量、月通话时长等单位。利用数据归一化可消除量钢差异,其归一化属性的数值计算表达式[8]为
(1)

2 信息增益
在特征工程当中,通过特征选择[9-10]过程,去除不相关或者相关性较小的特征,将更少的特征应用于机器学习流程。信息增益[11]反映某个特征对分类的影响程度,在进行特征选择时,只需选择信息增益值大的特征即可[12]。在预测电信客户离网时,利用信息增益进行特征选择。
设预处理后的电信数据训练集为D,其特征A的信息增益值[13]为
g(D|A)=H(D)-H(D|A),
(2)
式中H(D)为集合D的熵,H(D|A)是特征A给定条件下D的条件熵。
将电信数据分为训练集Dtrain和测试集Dtest,将Dtrain中的特征依次代入式(2),计算每个特征的信息增益值,并将其从大到小进行排序。根据电信数据本身的特点,设定阈值,去除信息增益值小于阈值的特征,剩余的特征即是影响电信客户离网的主要因素。
3 FSSVM算法
在训练数据集上运用SVM算法,找到分类最大间隔分离超平面[14],将正、负例样本点准确分类。如图2所示,实圈代表正例,空圈代表负例,H为超平面,H1和H2分别表示正例和负例中离超平面最近且相互平行的平面,H1和H2之间的间距2/‖w‖为分类间隔。

图2 最大间隔分离超平面
以二类分类为例,假设输入的训练数据集为Dtrain={(x1,y1),(x2,y2),…,(xN,yN)},xi∈N代表N维样本,yi∈{+1,-1},(i=1,2,…,N)代表样本类别标签。通过映射函数Φ(x),将输入的训练集Dtrain映射到某个高维度的线性空间中,在映射后的空间中求解最优分类平面wΦ(x)+b=0,其中w为分类平面的法向量,b为分类平面的截距。为寻求最大间隔分离超平面,优化目标函数[15]

(3)
式中,ξi为松弛变量,C为惩罚因子,用于平衡结构风险和经验风险。在保证错分样本尽可能少的前提下,C值越大,预测电信客户离网分类效果越好。
上述问题(3)为求解凸二次规划[16]问题,利用拉格朗日对偶性,可将原始问题转化成对偶问题,求得最优解的表达式[17]为

(4)
其中α=(α1,α2,…,αN)T为拉格朗日乘子向量。由式(4)可得
(5)
则分类决策函数[18]可表示为
(6)
通过式(6)便可以将正负例样本分到超平面的两端。根据电信数据特点,选取高斯径向基核函数[19],K(x,xi)=e-σ‖x-xi‖2。其中σ为核函数宽度,xi为Dtrain中的样本。
FSSVM算法去除了对电信客户离网预测相关性小或者不相关的特征,降低了数据维度,改善了SVM算法复杂度高、容易过拟合的问题,提高了算法的预测速度。FSSVM算法具体步骤如下。
步骤1将原始数据进行数据缺失值填充、去除噪声点、数据冗余识别、数据结构化和归一化等预处理。
步骤2随机选取80%数据作为训练集Dtrain,其中20%数据作为测试集Dtest。
步骤3通过式(2)计算Dtrain中每个特征的信息增益值,并将其从大到小进行排序。根据设定的阈值,去除不相关或者相关性较小的特征,降低数据维度,防止过拟合。
步骤4根据式(6)判断xi的分类类别。当f(xi)≥1时判断客户离网,当f(xi)≤-1时判断客户没有离网。调整惩罚因子C的值,直至xi的分类效果达到最优。
步骤5去除Dtest中和Dtrain中不一样的特征。将Dtest中样本xi作为输入数据,对客户是否离网进行分类,预测客户离网行为。
4 测试结果及分析
将某电信运营商数据集中的3 250条数据作为实测数据,随机选取80%即2 600条数据作为训练集,剩余20%即650条数据作为测试集。数据的基本属性包括是否VIP、客户属性、是否离网、是否主动离网等,其中非数值属性需经过整数编码后使用。
为了验证算法的有效性,根据预测电信客户离网分类效果评价指标[20-21], FSSVM算法与KNN、随机森林、逻辑回归、Adaboost和SVM算法的预测结果如表1所示。
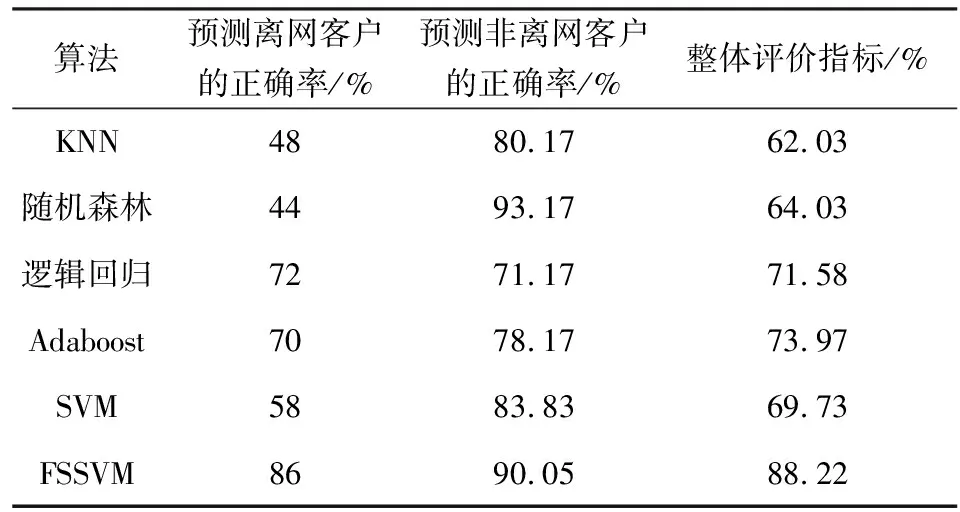
表1 电信客户离网预测结果
由表1可以看出,在预测电信客户是否离网时,FSSVM算法预测离网客户时的正确率为86%,预测非离网客户的正确率为90.05%,整体评价指标为88.22%,优于KNN、随机森林、逻辑回归、Adaboost和SVM等算法,提升了离网客户预测准确率。
5 结语
FSSVM算法将原始电信数据进行预处理后,利用信息增益的方法进行特征选择,去除了对电信客户离网预测相关性小或者不相关的特征,降低了数据维度,防止过拟合现象发生。测试结果表明,该算法预测离网客户的正确率为86%,比其他预测客户离网算法的准确率更高,提升了离网客户预测准确率。
