基于深度学习的文本情感分析并行化算法
2019-07-11翟东海侯佳林刘月
翟东海 ,侯佳林 ,刘月
(西南交通大学信息科学与技术学院,四川 成都 611756)
文本情感分析是利用计算机技术对“人们关于产品、服务、事件等实体的评论”等文本进行分析处理以获得其表达的主观情感信息的过程.其主要包括:情感信息分类、情感信息抽取、情感分析技术应用等[1-3].传统的情感分析方法包括支持向量机、条件随机场、信息熵等,且均采用词袋模型.如文献[4]采用SVM (support vector machine)对句子进行情感识别及分类.但这种浅层模型在处理海量数据时通常存在着数据稀疏性以及数据维度高等问题.Geoffrey Hinton 等[5-6]于2006年提出的深度学习模型为解决这些问题提供了新思路.当前,在文本情感分析任务上应用较多的神经网络模型有卷积神经网络(CNN)、基于序列的模型(RNN)和树型结构模型(RAE)等.如文献[7]采用CNN 进行情感极性分类;文献[8]采用双向序列模型(BLSTM)进行中文文本分类研究.因树形结构模型(如深度学习中的递归自编码算法)在文本特征提取、情感分析中表现优异,受到了学者们的广泛关注,如文献[9-11]都是递归自编码算法的典型应用范例.
神经网络模型虽然能够极大程度地学习到文本内容所隐含的语义信息,显著提高分类的准确率,但深度神经网络在训练时耗时、收敛慢的问题也逐渐受到了研究者们的关注.文献[12]通过开发新的计算框架DistBelief 来实现大规模神经网络的训练;文献[13]中使用GPU 来训练深度玻尔兹曼机,但GPU因受内存所限,数据量大时效果也不太理想.
随着并行计算的兴起,在处理大规模数据、复杂计算时,研究人员往往向其寻求帮助.Berkeley AMP lab 的Spark[14]、谷歌的TensorFlow[15]、微软的Dryad[16]以及谷歌的MapReduce[17]都是该领域内的佼佼者.而MapReduce 框架以其较强的可扩展性、良好的可用性、较好的容错能力,成为研究者关注的热点[18].在诸多MapReduce 的实现中,Apache Hadoo 因良好的开源性深受业界青睐.因此,利用Apache Hadoop中的MapReduce 并行计算框架对神经网络进行优化加速也吸引了诸多学者的研究兴趣.神经网络的并行化加速是在分布式集群上,用多个集群节点同时对一个神经网络进行并行化处理,以提高此网络的训练速度.网络的并行化方式分为两种:节点并行化和数据并行化.但由于开发者对MapReduce 框架的底层实现并不清楚,因此开发者不能明确地将某项任务交由某个节点处理.且对海量数据集的节点并行化处理会使得I/O 开销过大.因此,在MapReduce 框架中采用的是数据并行方式来加速网络训练.文献[19-21]皆是基于Hadoop 中的MapReduce 所做的不同并行化处理的例子,证明了利用MapReduce可以有效加快网络训练速度,从而大大缩短神经网络的训练时间.
本文针对Socher 等提出的Semi-Supervised 文本情感分析算法[9],使用开源Hadoop 中的MapReduce并行框架提出并行优化策略,综合利用集群节点的计算资源,使其在处理大规模文本时更加高效.
1 相关工作
1.1 MapReduce
Google 提出的MapReduce 以其优越的整合计算节点的能力所著称,此处对其做简要介绍.MapReduce 采用“分而治之”的思想,通过主节点调度,将任务分配到其下的子节点中,并行处理后输出最终结果.总的来说,MapReduce 是通过用户编写Map 函数和Reduce 函数来实现结果计算的,用户只需关注这两个函数的编写,其他的问题,诸如容错、负载均衡、调度都交给框架处理.在MapReduce中,一个任务首先被分成许多输入键值对<kin,vin>,然后在Map 函数作用下生成中间结果<kmid,vmid>,这些中间结果存放于内存之中.接着,这些中间结果将作为Reduce 函数的输入,根据Reduce 中的用户逻辑输出最终结果<kout,vout>.其流程如图1所示,图中:M为数据存储数;m为中间结果键值对数目.

图1 MapReduce 工作流程Fig.1 Workflow chart of MapReduce
1.2 Semi-Supervised RAE 文本情感分析
1.2.1 用词向量表示词语
不同于以往的词袋模型[22],Semi-Supervised RAE用词向量表示词语并作为神经网络的输入,如(0,1,0,0)表示“大学生”,(1,1,0,1)表示“教师”.若一个句子x含m个词,则第k个词为xk,1 ≤k≤m.将词xk以标准正态分布的形式映射到n维实向量空间上,可表示为xk∈Rn.所有词的词向量存储在一个词嵌入矩阵L∈Rn×|V|中,V为词汇表的大小.则xk的向量表示为

式中:bk为一个维度为词表大小、值为0 或1 的二值向量,除了第k个索引之外的所有位置都是0.
1.2.2 有监督递归自编码
在获取句子的低维向量表示时,传统的自编码方法需要将句子的树形结构作为先验知识,这种编码方法称为有监督递归自编码.假设一个句子用向量表示为x= (x1,x2,···,xm),已知子节点c1、c2的输入词向量为x1、x2,则父节点pi的计算方法为

式中:i=1 ,2,···;C= [c1;c2]表示c1、c2的词向量拼接矩阵;f(·)为 网络的激活函数;wfi和bfi分别为计算父节点时的权重和偏置参数.
为了测试父节点对子节点的表示能力,在各父节点上添加其对应子节点的重构层(图2),根据原始节点与重构节点的差值来表示误差.
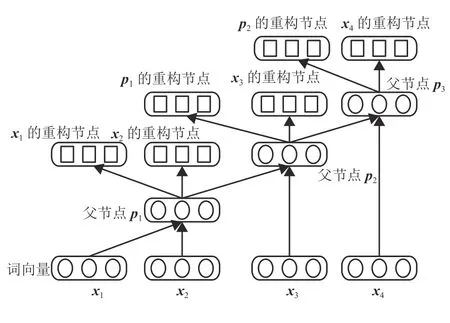
图2 有监督递归自编码结构Fig.2 Structure of supervised RAE
重构节点计算方法为

式中:j=1 ,2,···;C′=[c′1;c′2]为c1、c2的重构节点c′1、c′2的词向量拼接矩阵;brj为偏置项;wrj为权重参数矩阵.
词向量采用欧式距离计算重构误差,即
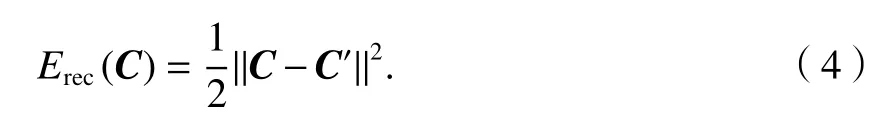
1.2.3 无监督递归自编码
通常情况下,句子的树形结构往往未知,这种需要自主学习树形结构的自编码方法称为无监督递归自编码.树形结构预测过程的优化目标函数为
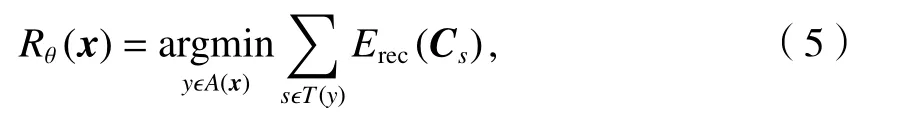
式中:Rθ(x)为句子x的最优树型结构模型,θ为参数集;集合A(x)为句子x所有可能的树形结构集合;y为其中的一种结构;s为计算过程中非终端节点的三元结构(由2 个子节点cs1、cs2和1 个父节点Ps组成);Cs=[cs1,cs2];T(y)为这种三元结构的检索函数.
不同词语对句子整体含义的贡献度不同,为了体现这种差异在计算重构误差时给不同的词语赋予不同的权重,
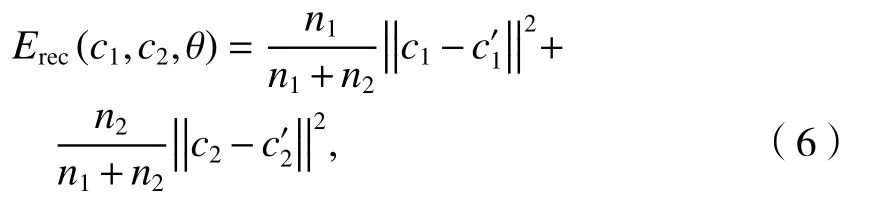
式中:n1、n2为当前子节点c1、c2下面的词数.
为了防止递归自编码算法在不断迭代减小重构误差时计算出的父节点过小,为后续计算造成不必要的麻烦,此处对式(2)进行归一化处理:

1.2.4 半监督递归自编码
得到句子的向量表示后,为计算整体语句的情感倾向,在网络结构上增加softmax(·)分类器:

式中:l为当前的情感种类;wl为参数矩阵.
若有K种情感,则d∈RK,且分类层交叉熵误差计算方法为

式中:t为标签的分布;tk为第k种情感的标签分布;dk为条件概率,且

因此,半监督递归自编码在数据集上的优化目标函数为
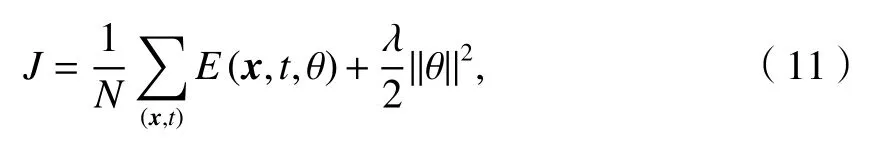
式中:N为训练数据集大小;λ为L2正则项系数;

并且,此时每个非终端节点的误差变为重构误差与交叉熵误差的加权和为

式中:α为权衡重构误差和交叉熵误差的调节参数.
采用L-BFGS (limited-memory Broyden-Fletcher-Goldfarb-Shanno)算法求解优化目标函数式(11)的最优解,其中所用的梯度为

式中:θ= {wfi,bfi,wrj,brj,wl,L}.
2 Semi-Supervised RAE 模型的并行化
在使用Semi-Supervised RAE 算法进行文本情感分析时,往往需要先根据训练数据集,训练出较好的模型,然后再将此模型应用于情感分析.因此,针对Semi-Supervised RAE 模型的并行化也将分为两步:首先是针对大量训练数据集的并行化研究,当模型训练好后,利用其并调用相应的并行化算法,进行测试数据集的文本情感分析.
2.1 大量训练数据集情况下
在Semi-Supervised RAE 的训练阶段,通过贪心算法构建句子的最优树结构以获得该语句的向量编码,接着通过优化目标函数式(11)迭代得到最优的参数集,为获得最佳文本情感分析结果做好准备.
本文采用MapReduce 并行框架来加快训练速度以便解决原模型在大数据量的情况下训练时间过长的问题.首先对总的训练数据集进行分块,并将每一个数据块分派给不同的Map 节点.利用这些数据块,Map 节点依次计算相应数据块中每一个句子x的最优树结构,并计算相应句子的误差,直至数据块中所有语句误差计算完毕并暂存在缓冲区.Reduce阶段,节点累加缓冲区的块误差来计算得到这个数据集的误差和并利用L-BFGS 算法求出最优参数集.算法整体流程如图3所示.该算法的主要计算量集中于Map 阶段,为了克服并行化后神经网络出现弱化现象[19],集群只设置了一个Reduce 节点如图3所示,图中Nt为训练数据集合块数.
2.2 大量测试数据集情况下
当模型训练好后,本文针对测试数据集较大情况下测试结果输出慢的特点,也设计了相应的并行化算法.首先,将测试数据集分块,用训练阶段得到的最优参数集来初始化节点.在Map 阶段,求出每条语句的向量表示,并输出到缓冲区.在Reduce 阶段,softmax(·)分类器利用每条语句的向量表示输出句子ID 及其情感标签,算法流程如图4所示,图中,Nc为测试数据集合块数.
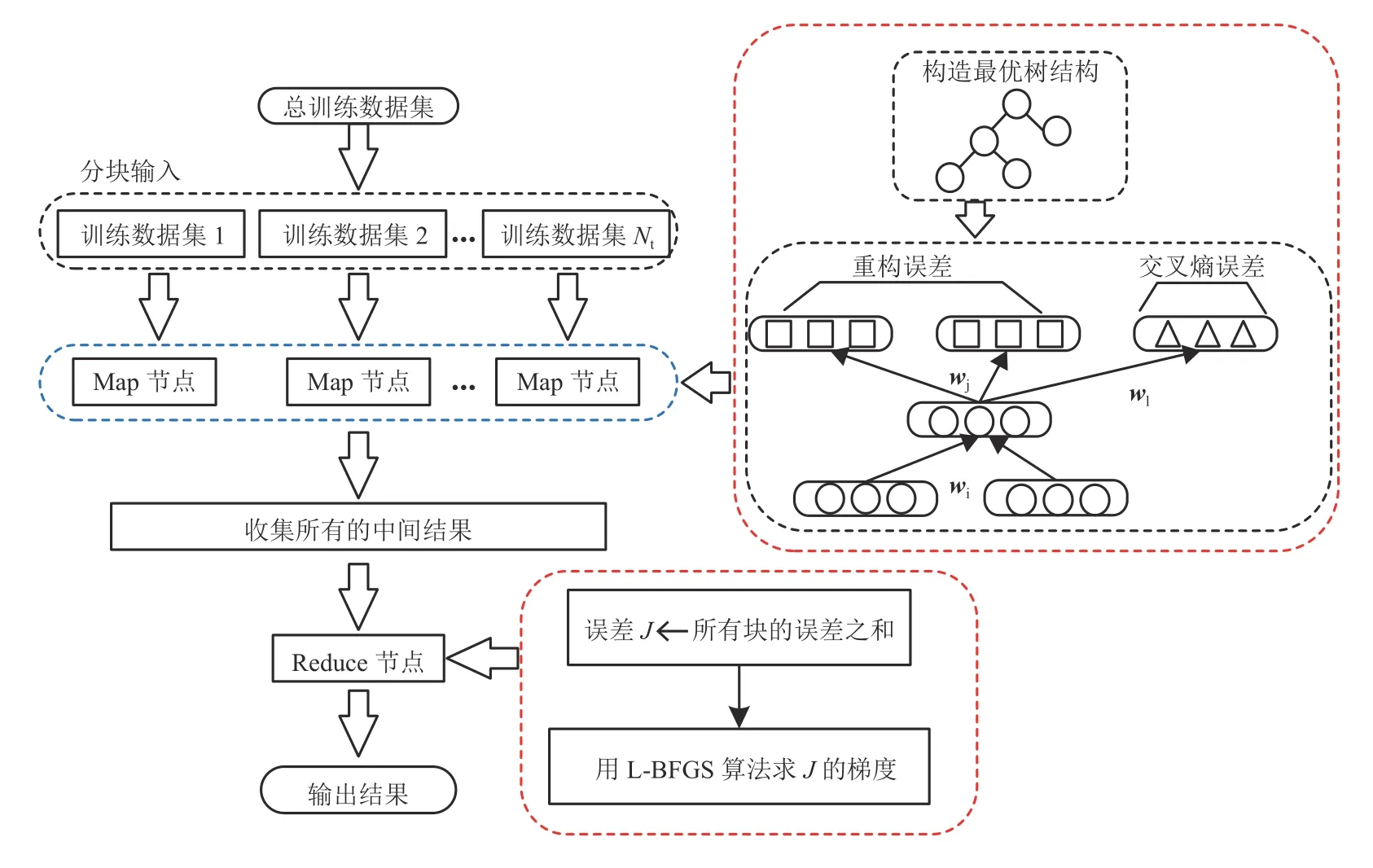
图3 大量训练集并行化算法Fig.3 Parallel Computing based on a big training dataset
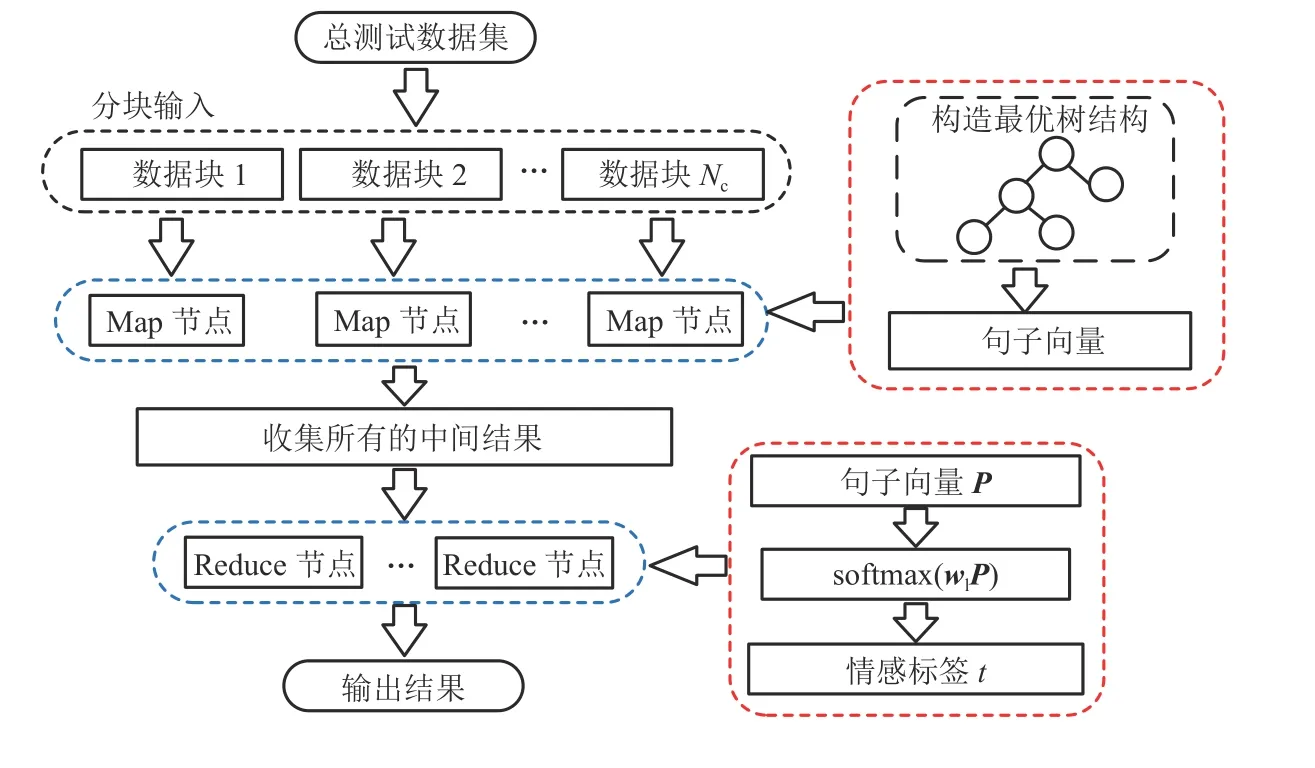
图4 大量测试集并行化算法Fig.4 Parallel Computing based on a big test datasets
3 实验结果与分析
实验中用到的节点皆为AMD 双核2.5 GHz 处理器,内存4 GB.节点操作系统为Ubuntu14.04,Hadoop版本为1.0.2,Java 版本为1.6.0_33.此次实验中,词向量选用100 维,算法最大迭代次数为1 000,权衡重构误差和交叉熵误差的调节参数α设为0.2.
为了克服现有的情感分析语料库数据量较小[23-24]的问题,本文采用爬虫程序从美国亚马逊购物网站上抓取了12 万条商品评论数据,构建了两个语料库AmazonCorpus2 和AmazonCorpus10,用以测试并行化后的加速效果.此外,Movie Reviews(MR)[25]数据集也用于本文实例验证中,以分析算法分类准确率时与原算法作对比(如表1所示).

表1 语料库信息Tab.1 Corpus information
根据商品质量的优劣,美国亚马逊购物网站将用户对商品的评分设置为1~5 级.为了便于情感分析与模型训练,在本文制作的语料库中将1~5 级转化为负面、中性、正面3 类评价,转换规则如下:1~2 级评分为负面评价记为-1,3 级评分为中性评价记为0,4~5 级评分为正面评价记为1.
MR 数据集仅被分为两类,即正面评价记为1,和负面评价记为 -1.详情如表2、3 所示.

表2 AmazonCorpus 语料库样例Tab.2 Samples of the AmazonCorpus

表3 MR 语料库样例Tab.3 Samples of the MR corpus
3.1 算法分类精确度分析
此处选用MR 和AmazonCorpus2 两个语料库,将并行化算法与原始模型及两个在情感分析任务上应用较为广泛的baseline 模型——CNN 和BLSTM做精确度对比试验.试验时,并行化训练算法的Map节点设为3,Reduce 节点为1,试验结果如表4所示.从表4中可看出,并行化算法和原始算法拥有几乎相同的精确度(精确度 = 预测正确样本量/样本总量),均高于CNN 和BLSTM 模型,但并行化算法训练时间远小于其它算法的训练时间.这是因为CNN虽然具有较强的捕获局部特征的能力,但它忽略了文本的上下文语义及结构特征,使得模型的训练效果容易收敛到局部最小值而非全局最小值.而BLSTM通过一个正向LSTM 和一个反向LSTM 来学习文本的上下文语义特征的同时引入了较多的冗余特征信息,这些冗余信息会影响模型的精确度;且LSTM 内部的门结构和记忆单元使得模型的时间复杂度较大.
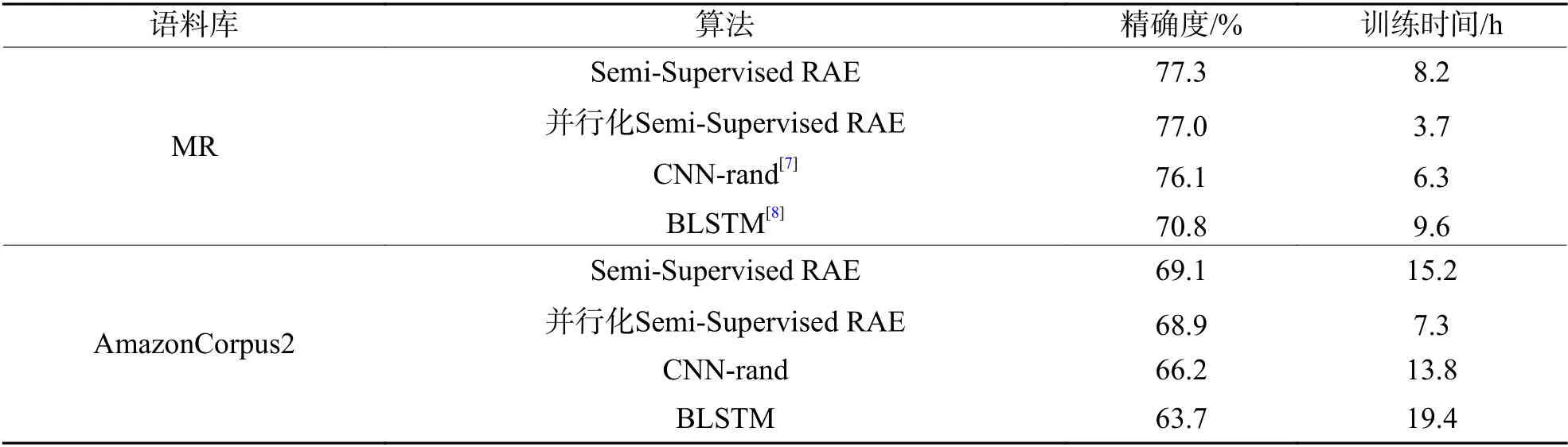
表4 算法精确度对比表Tab.4 Accuracy comparison of algorithms
3.2 算法执行效率分析
对于并行化算法的执行效率,此处分别针对并行化训练算法和并行化测试算法进行分析.首先,用AmazonCorpus10 语料库进行并行化训练算法的仿真.集群节点个数分别为1、2 (1 个Mapper,1 个Reducer)、3 (2 个Mapper,1 个Reducer)、5 (4 个Mapper,1 个Reducer)、9 (8 个Mapper,1 个Reducer)、17(16 个Mapper,1 个Reducer),33 (32 个Mapper,1 个Reducer),节点个数为1 时,表示原始算法的训练;其余集群中Reduce 节点个数均为1.实验结果如图5所示.

图5 不同节点并行化训练时间对比Fig.5 Parallel training time comparison among different nodes
从图5可得,当集群中节点个数为2 时,并行化算法没有原始算法效率高,其原因主要是节点初始化、任务调度及算法迭代时更新参数集均需要消耗一定量的时间.但随着节点逐渐增多,耗时量几乎线性下降,说明并行化算法效果良好.当节点增加到9 个以后,耗时量下降变缓,说明训练时间受节点数量的制约开始减弱,此时算法瓶颈已不再为Map 节点个数.
其次,利用上述AmazonCorpus10 语料库的训练得到的参数集来初始化“并行化测试算法”.测试集是在AmazonCorpus2 语料库的基础上,对其数据量作20、40、80、160 倍扩展的大数据集,即本次测试的数据量为40、80、160、320 万条语句.针对这些数据,分别选择1、3、4、6、10、18,34 个节点对其做并行化,其中节点个数为1 表示原始算法,其余集群中Reduce 节点个数均为2,实验结果如图6所示.
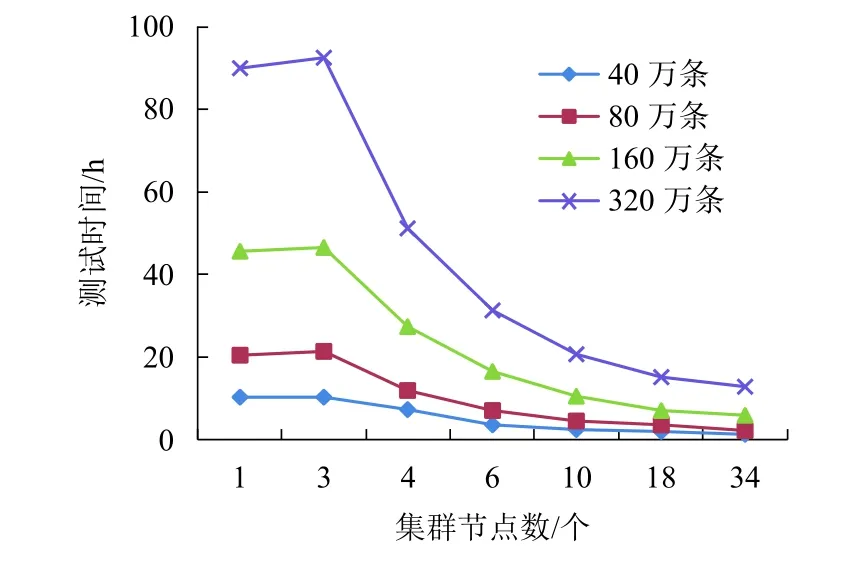
图6 不同数据量测试时间对比Fig.6 Test time comparison among different data volumes
从图6可得出,当数据量增大时,并行化测试算法可大大缩短数据集的执行时间,如在语句数据量为40 万条时,34 个节点所需执行时间约是原始算法的1/10.但数据量较大时,增加Map 节点个数,算法加速效果逐渐变弱,这种情况在语句数据量为320 万条时较为明显.通过对集群节点计算量分析可知,此时影响算法效率的主要因素是Reduce 节点个数.
为了进一步探索Reduce 节点个数对加速效果的影响,此次在Map 节点为8、16、32 个时,通过增加Reduce 节点个数,分别测量语句数据量为320、640、1 280 万 条(AmazonCorpus2 语 料 库 作160、320、640 倍扩展)时的并行化算法加速效果.实验结果如图7所示.
从图7、8、9 中可明显得出,当Map 节点达到一定量后,增加Reduce 节点个数,可显著提高算法执行效率.如图7中Map 节点为32 时,相同语句数据量Reduce 节点个数为5 时的测试时间约是2 时的一半,可见当Map 节点足够多时,适当增加Reduce节点个数可以提高算法的执行效率.

图8 640 万条语句数据量加速效果对比Fig.8 Acceleration effect comparison on 6.4 million data

图9 1 280 万条语句数据量加速效果对比Fig.9 Acceleration effect comparison on 12.8 million data
4 结束语
本文基于MapReduce 并行化可扩展计算框架提出了半监督递归自编码文本情感分析模型的优化算法:针对模型在大训练数据集上收敛速度缓慢的问题,本文优化算法首先采用“分而治之”的思想对数据集做分块处理后输入Map 节点计算块误差,接着将块误差输出到缓冲区中汇总,而Reduce 节点先利用块误差计算出优化目标函数,然后调用LBFGS 算法更新模型参数集,迭代上述训练过程直至目标函数收敛,从而得到模型最优参数集;针对模型在大测试数据集上测试结果输出缓慢的问题,本文优化算法在利用最优参数集初始化模型后,在Map 节点中计算出各句子的向量表示,并存储于缓冲区中.然后Reduce 节点中的分类器利用缓冲区中的向量表示计算各语句的情感标签.从实验结果可得出,本文算法明显提高了原始算法的运行效率.然而本文算法也有不足之处,如在训练阶段,并行化算法中Reduce 节点一次最多只能运行一个,这将成为大规模并行训练时算法的瓶颈;在测试阶段,当数据量大时Reduce 节点个数的选择也直接影响了算法的效率,此时急需一种有效的调节机制,能够均衡当前集群中的Reduce 节点个数,以上这些都将成为今后进一步研究的重点.
