结合域混淆与MK-MMD的深度适应网络
2019-07-09王翎,孙涵
王 翎,孙 涵
(南京航空航天大学 计算机科学与技术学院,南京 211106)
1 引 言
近年来,深度学习在大量机器学习和计算机视觉的任务上取得了巨大的成就,例如图像分类[1,2]、目标检测[3,4]、精细粒度分类[5,6]和语义分割[7,8]等.为了取得这些进步,使用大量的标记数据集进行训练是至关重要的.然而,在现实中为了一个特定应用场景标记数据的代价是非常昂贵,甚至是不现实的.例如摄像头(或监控)采集图片中的物体检测、车辆识别,会有相机角度、距离、光线等各种复杂变化,使用场景也是千变万化,对这些图片全部标记是不可能的.幸运的是,在公开的数据集中有大量的已标记数据,只是这些数据与我们需要的应用场景数据有着不同的特征空间或分布,直接使用这些数据训练基于卷积神经网络的分类器,在目标场景下应用是有困难的.比如车辆识别任务中,现有已标注数据集中车辆图片可能是从杂志或官网收集的并且具有专业的灯光和固定的拍摄角度,而监控应用中车辆图像是由道路上架设的交通监控摄像头采集的,光照条件和天气状况都有很大影响.
为了解决上述问题,域适应(Domain Adaptation,DA)[9]是一种非常有效的迁移学习方法,其目的是利用来自不同但相关的域(源域)中丰富的现有标记数据,将从源域中学习的预测模型推广到未标记(或少量标记)的目标域,尽管源域和目标域数据分布之间存在差异.
域适应方法的主流核心思想是减小域间差异,同时从数据中学习一个具有域不变特性的预测模型.目前,主流的域适应方法根据缩小域间差异策略的不同分为两类:
1)特征表示的迁移,其目的在于找到合适的特征表示,最小化域间差异和分类(或回归)模型的误差;
2)实例的迁移,这类方法重点在于对源域“好”样本数据重新加权,并在重新加权的数据集上进行训练,以达到最小化分布差异的目的.
在本文中,我们着重于特征表示的迁移这一类方法进行研究.在此类域适应方法中,基于最大均值误差(Maximum Mean Discrepancies,MMD)[10]的方法应用广泛.该类方法通过优化源域与目标域在再生核希尔伯特空间(Reproducing Kernel Hilbert Space,RKHS)[10]上的最大均值误差来缩小域间差异,学习具有域不变特性的特征表示,其中典型的方法就是深度适应网络(Deep Adaptation Network,DAN)[11],该方法提出了多核最大均值误差(Multi Kernel-Maximum Mean Discrepancies,MK-MMD),结合多核思想进一步对MMD进行优化.但是在DAN方法中,MK-MMD层对不同迁移场景的效果有差异,不同类型的迁移场景有不同的适应效果,且在特征表示迁移层面上,DAN方法并没有完全利用源域的信息,结果仍有提升空间.本文结合域混淆(Domain Confusion,DC)[12]思想,进一步对DAN方法进行改进提升,使得提取的特征表示对目标域适应效果更好.同时,本文针对DAN方法中不同场景MK-MMD适应效果差异的问题,从理论和实验上探究MK-MMD在不同场景下的适用权重.此外,本文将MK-MMD与域混淆进行结合,探究不同场景下两者最佳组合,进一步提升域适应的效果.本文在标准的Office-31数据集上进行实验,通过三方实验对比,验证了本文提出方法的有效性.
本文贡献如下:
1)结合DAN中MK-MMD与域混淆思想,进一步提高DAN方法精度;
2)针对DAN对不同情景域适应效果有差异问题,从实验与理论探究不同场景下MK-MMD度量的适用权重;
3)在标准数据集上通过实验得到MK-MMD与域混淆在不同场景下的最佳组合,提升两种方法融合的性能,结果达到组合最优.
本文的结构安排如下:第1节简单介绍研究目标与本文贡献;第2节介绍深度域适应领域的研究现状;第3节介绍本文使用的MK-MMD和域混淆方法的原理以及实现方式,同时给出本文研究使用的网络结构;第4节展示在标准数据集Office-31上的实验结果与对比分析;第5节探究不同场景下的MK-MMD的适用权重以及MK-MMD与域混淆的最佳组合方式;第6节总结全文.
2 研究现状
对于深度域适应方法研究,基本准则是决定好自适应层后加入自适应度量,再对网络进行微调.2014年PRICAL会议上,DaNN[13]被提出.该网络仅有特征层和分类器层两层神经元,特色在于特征层之后的MMD适应层,计算源域与目标域之间在RKHS空间距离并优化其损失.但浅显的网络表征能力太差,解决问题能力差.后续研究多将该思想结合到深度网络中.文献[14]中提出的DDC方法,使用在ImageNet上训练好的AlexNet网络进行域适应学习,其主要思想是固定前七层,在分类器层前加入MMD度量,实现了深度网络的域适应.但是单层的域适应效果有限,文献[11]中提出的DAN网络采用了MK-MMD,结合多核思想,表征能力更强,同时加入了三个自适应层,在不增加训练时间的基础上,取得了更好的分类效果.在2017年ICML会议上,JAN[15]方法被提出,将对数据进行自适应的方式推广到对类别的自适应,提出了JMMD(Joint MMD)度量.此外,基于生成对抗网络GAN[16]的域适应方法研究也取得了一定的进展.域对抗神经网络DANN[17]将梯度反转层和标准结构结合,促进了对源域主要学习任务有区分力且对域间偏移不敏感的特征的出现.Bousmails等人在文献[18]中提出的模型利用GAN使用源域图片仿照生成目标域图片,并将生成图片加入训练集中一起训练,提升了域适应的效果.
基于MMD的方法是目前域适应中主流方法之一,DAN就是其中经典的深度域适应方法.然而使用MK-MMD的DAN方法在特征迁移层面上仍有提升空间,且该方法对不同情景下的域适应效果差异问题没有进行探讨.本文采用无监督域适应的方式,结合域混淆思想进一步利用源域信息,使得提取的特征对目标域表征能力更强,提升域适应效果.同时,探究不同场景下MK-MMD的适用权重以及两种方法融合的最佳组合方式.
3 改进的深度适应网络模型
3.1 MK-MMD
MK-MMD(Multi Kernel-Maximum Mean Discrepancies),多核最大均值误差,是MMD的延伸概念.MMD是最常用的衡量两个域数据集之间分布差异的非参数方法之一.其具体操作是将源域与目标域中的特征表示映射到再生核希尔伯特空间(RKHS)中,再计算两类数据均值的距离.给出两个域的数据分布s和t,通过使用函数φ(·),s和t之间的MMD计算方式为:
(1)
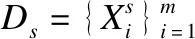
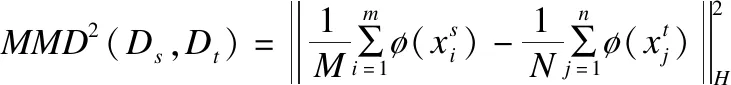
(2)
其中φ(·)代表与核映射k(xs,xt)=ø(xs),ø(xt)相关的特征映射.k(xs,xt)通常被定义为L个基础核kl(xs,xt)的凸组合:
(3)
但是现有的MMD方法是基于单一核变换的.多核MMD(MK-MMD)假设最优的核可以由多个核线性组合得到.其中最著名的使用MK-MMD的方法是DAN.
令Hk代表拥有特有核k的再生核希尔伯特空间(RKHS).分布p在Hk中的均值为一个独立的元素μk(p),则Ex~pf(x)=f(x),μk(p)Hk,其中f∈(Hk).概率分布p和q在RKHS中均值的距离表示为MK-MMDdk(p,q),其平方公式为:
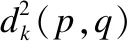
(4)
和MMD相同,特征映射ø与特有核(characteristic kernel)相关,k(xs,xt)=ø(xs),ø(xt),k(xs,xt)被定义为m个PSD核{ku}的一个凸组合:

(5)
其中系数{βu}的相关约束是为了保证产生的多核k是特有的.根据Gretton在文献[19]的理论分析,分布p和q计算均值时采用的核对减少分布差异的效果是至关重要的.多核k可以利用不同的核来加强MK-MMD的效果,最终达到一个最优的、合理的核选择.
3.2 域混淆Domain Confusion
为了减少两个域之间的边缘分布差异,最大化域混淆(Domain confusion,DC)是比较有效的方法.域混淆的示意图如图1所示.

图1 域混淆示意图Fig.1 Definition of domain confusion
为了实现最大化域混淆,本文的添加一个域分类层fDC,该层的主要作用是通过训练样本的特征表示判断该样本是否属于源域或目标域.从直观的角度看,提取的特征越是特定于域,域分类效果越好;提取的特征越是体现两域之间的共性,域混淆的效果越好.当由一种特征表示训练得到的分类器无法区别源域与目标域种的样本时,我们可以称该特征表示具有域不变特性.本文使用一种域混淆损失,该损失的优化是为了保证获得具有域不变特性的特征表示.
对于一个特征表示θrepr,我们通过学习在该表示上效果最好的域分类器来衡量其域不变特性,θD是待学习的域分类器参数.通过最优化下列损失函数,可以学习得到效果最优的域分类器:
(6)
其中,yD代表样本所属的域,q代表域分类器的softmax值:q=softmax(θDf(x;θrepr)).
此外,对于一个域分类器,我们引入域混淆损失,计算输出预测到的域标签与均匀域标签分布之间的交叉熵,以达到最大化混淆两个域、减少域之间分布差异的目的.域混淆损失函数表示如下:
(7)
上述域混淆损失的优化是为了找到一种具有域不变特性特征表示,在该特征表示的情况下,最好的域分类器无法取得良好的效果.理想状态下,我们想要在训练过程中同时优化上述两种损失.但是域分类与域混淆是两个矛盾的存在:学习到一个好的域分类器意味着域混淆的效果很差,不具有域不变的特性;达到好的域混淆效果则表示域分类器的分类效果很差.因此,域分类层fDC的两种损失需要联合优化以达到一个折中的、合理的优化结果.
3.3 网络结构与模型优化
3.3.1 网络结构
本文采用的网络结构与DAN类似,采用其多层MK-MMD的方法设计网络,同时添加域分类层fDC,通过多层MK-MMD损失、fDC层损失与总体网络的最终分类损失这三种损失函数的联合优化,达到好的无监督域适应效果.网络结构如图2所示.
3.3.2 损失函数
2.1 急诊专科护士主观幸福感得分 128名急诊专科护士主观幸福感得分总分为(70.38±11.86)分,与全国女性常模(71.0±18.0)分比较差异无统计学意义(t=0.596,P>0.05)。各维度得分:对健康的担心(7.25±2.83)分,精力(17.73±3.41)分,生活的满足和兴趣(3.27±1.17)分,忧郁或愉快的心境(17.05±2.92)分,对情感和行为的控制(12.41±2.37)分,松弛和紧张(15.25±3.99)分。
(8)
其中J是交叉熵损失函数,θrepr(xi)表示网络给样本xi附上标签yi的条件概率.
由于在标准卷积神经网络中,层数由低到高,深度特征也是由一般化到特殊化,网络层数越高,源域与目标域之间的域差异就越大,只通过微调无法弥补这种巨大的分布差异.因此,一般需要考虑对全连接层而不是卷积层进行迁移.
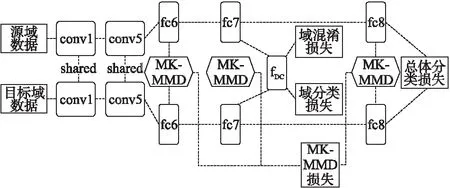
图2 网络结构图Fig.2 Structure of network
本文在全连接层实现域适应,缩小域分布差异的方式有两种:
1)添加基于MK-MMD的多层适应;
2)添加域分类层fDC.相应的损失函数也添加两种,整个网络的损失函数如下:
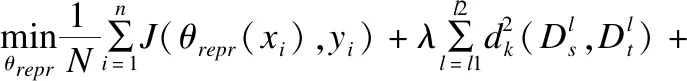
(9)
其中,λ和γ分别是MK-MMD和域混淆的平衡权重.
3.3.3 参数优化过程
对于不同的域适应场景,损失函数的权重应有差异,本文在将MK-MMD与域混淆结合的同时,通过实验探究不同域适应度量对于不同的域适应场景的贡献差异,以及两种方法的合理组合方式,该部分内容将在第5节具体阐述.
4 实验过程与结果
4.1 数据集与实验过程
本文实验使用的数据集是Office-31,该数据集是域适应研究领域的标准基准数据集.Office-31数据集中有31类、共4652张图片,这些图片是从三个独立域中收集得到的,分别是:(1)Amazon(A),从amazon.com下载的图片数据;(2)Webcam(W),由网络摄像头采集的图片数据;(3)DSLR(D),由数字SLR相机采集的图片数据.示例图片如图3所示.对于这三个域的数据,可以有六种迁移方式:A→W,D→W,W→D,A→D,D→A和W→A.本文将进行这六种域适应任务的实验与对比分析.

图3 Office-31 数据集示例Fig.3 Examples of the Office-31 dataset
除了本提出的结合域混淆与MK-MMD的改进深度适应网络方法以外,本文实验还将和传统的CNN方法、使用MK-MMD度量的DAN方法进行实验对比.同时为了研究域混淆的应用价值和适用条件,分别对fc6与fc7进行改进实验并进行对比分析.
实验过程:
本文使用caffe开源架构进行网络的研究训练,采用的网络架构为5+3经典卷积神经网络架构.与DAN方法相同,在三层全连接层后分别加上对应的MK-MMD层,计算源域与目标域特征表示在希尔伯特空间上的多核最大均值误差.同时,在第七层全连接层之后添加应用域混淆思想的域分类层fDC,并计算该域分类层的分类损失与域混淆损失.为了实现该层功能,需在模型文件中为源域与目标域数据添加相应域标签0和1,该层输入参数为第七层全连接层得到的特征表示与两个域的标签连接.我们采用微调的方法进行模型的训练,但是考虑到训练集数据量的问题,训练的过程中从预训练模型中获取前三层卷积层参数并固定,对后续的卷积层与全连接层通过反向传播的方式进行微调.实验采用随机梯度下降法,参数为0.9,学习率采用“inv”的方式,参数为0.75,初始学习率为0.01.
4.2 实验结果与对比分析
本实验实现了结合域混淆与MK-MMD的改进深度适应网络在Office-31数据集上的无监督域适应,并与普通卷积神经网络CNN(Baseline),深度适应网络DAN进行实验对比.为了对比实验的合理性,所有方法在同等条件下进行对比实验.实验结果如表1所示.其中Baseline和DAN结果是按照文献[11]中模型与训练方式重新训练得到的.
表1 基于Office-31数据集的无监督域适应实验结果
Table 1 Result of unsupervised domain adaptation experiment in Office-31 dataset

A-WD-WW-DA-DD-AW-AAverageBaseline 60.6(~0.6)95.0(~0.5)99.1(~0.2)59.0(~0.7)49.7(~0.3)46.2(~0.5)68.2DAN 66.9(~0.6)96.3(~0.4)99.3(~0.2)66.3(~0.5)52.2(~0.3)49.4(~0.4)71.6DAN+DC(fc6)67.3(~0.6)96.0(~0.3)99.1(~0.2)66.0(~0.751.5(~0.3)49.6(~0.5)71.5DAN+DC(fc7)69.0(~0.7)96.2(~0.4)99.5(~0.2)67.0(~0.6)52.5(~0.5)50.2(~0.5)72.5
4.2.1 DAN方法与CNN方法对比分析
本文首先在Office-31上使用普通的卷积神经网络CNN,采用微调的方式进行源域到目标域的域适应,以此作为实验结果对比的Baseline.在三个数据集的六种迁移情况下,平均检测精度为68.2%.其中,D与W的互相迁移正确率很高,这是因为网络摄像头和数字SLR相机采集的图片数据相似度很高,无需额外的域适应操作就能达到很好的检测效果.但是网络图片与真实采集图片之间差异较大,故相互迁移的正确率都不高,尤其是从真实采集图片数据集D和W向网络图片数据集迁移A的时候,效果尤其差.
其次,本文采用多层MK-MMD的方法进行域适应(DAN方法).得到的结果如表1中第二行所示.对于不同的数据集迁移情况,采用的权重参数λ有所不同,具体选择参数值与原因分析将在第5节中给出.表中所展示结果皆为当前迁移情景下最好的检测结果.我们在不同方法之间进行纵向对比.
从结果中可以看出,采用多层MK-MMD域适应的DAN方法,六种迁移情景的准确度均值为71.6%,相比较于Baseline提高了超过3%,有显著提升,这证明了该域适应方法的有效性.对于不同域适应情景,DAN的方法提升的效果也有差异.首先,对于D与W的域间迁移,效果提升不明显,这是由于两个域的数据集相似度很高,基础CNN网络也能在源域学习到对目标域有很好表征能力的特征,所以域适应方法效果一般.对于域A到域D或者W的迁移,此方法提升了7%左右,优化明显.从域D或W向域A迁移时,准确度提升了3%左右,效果也有明显提升,但是由于D和W的数据量问题以及现实采集图片提取特征的困难性问题,训练时学习到的特征对目标域A表征效果略差,所以提升程度相对较低.总体上,只采用多层MK-MMD的DAN方法进行域适应,取得了好的实验精度与优化效果,但是仍有提升空间.
4.2.2 DAN+DC(fc7)方法与DAN方法对比分析
本文在上文实验基础上,进一步结合域混淆的思想,添加判断样本归属域的域分类层fDC进行实验,并与上文采用的DAN方法进行实验对比.不同迁移情景的fDC层权重参数γ不同,参数的选取和原因将于第5节给出.同样的,本方法实验对比为纵向对比,实验结果如表1第4行所示.
由数据可以看出,最终平均准确度为72.5%,对于只使用MK-MMD的DAN方法,结合域混淆和MK-MMD的方法将六种迁移情景的平均精度又提升了1%.这是本文贡献之一.从不同迁移情景来看,域A到域W的迁移效果最好,提升了超过2%,实验过程中的精度对比见图4(a).域A到域D的效果提升了接近1%,源域与目标域的分布差异较大,所以结合域混淆与MK-MMD的方法使得从源域获得的特征更具有表征目标域样本的能力,进一步缩小了域分布差异,效果能得到明显提升,这与上文中实验的原理是一致的.同时,域D的样本数量较小,能够贡献的有效信息少,所以域A到域W的迁移效果优于域A到域D.对于相似的域D与域W的相互迁移,由于fDC层的实现思路是使提取到的特征无法判别样本所属域,而此情景下,源域与目标域的相似度很高,本身无法判别的程度就比较高,所以结合域混淆的实验效果提升不明显.对于域W或D向域A的迁移情景,结合域混淆的方法也将实验结果提升了接近1%,其中,W到A的实验过程精度对比见图4(b).同样的,由于源域数据量小,且现实采集图片提取到的特征表征能力较差,所以对比于从信息丰富的网络图片A向现实图片D或W迁移,该情景效果提升不明显,且由于W与D数据量的差异,本方法从域W迁移的效果提升程度高于从域D迁移的效果.
综上,在Office-31的六种迁移情景下,结合域混淆与MK-MMD的深度适应网络的实验结果总体优于文献[11]单一的DAN方法,证明了本方法在域适应问题上的有效性.
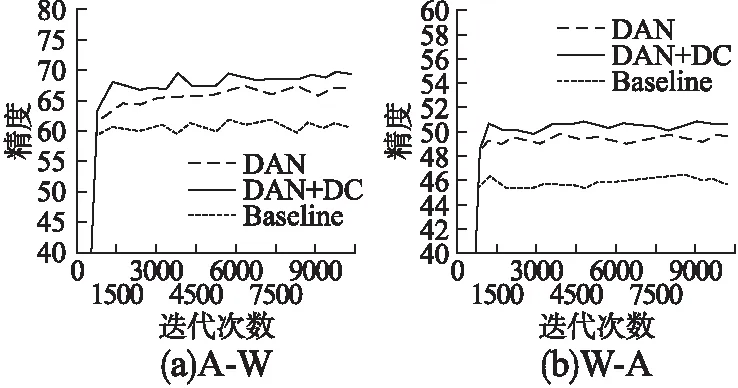
图4 不同方法迭代次数精度对比图Fig.4 Accuracy of different iterations using different methods
4.2.3 DAN+DC(fc6)方法与DAN+DC(fc7)方法对比分析
本文采用的代表域混淆的fDC层接在第7层全连接层之后,选择该位置的原因如下:首先网络第8层的输出结果用于分类,不作考虑,所以本文在第6层和第7层全连接层之后分别加上fDC层进行实验对比(下文简称为DC6,DC7),具体结果如表1中第三、四行所示.
从实验结果上看,结合DC6的方法得到的平均准确率为71.5%,效果不如只使用MK-MMD的DAN方法和结合DC7的方法.从数据上看,在第6层全连接层之后使用域混淆无法进一步提升域适应的效果,甚至有所下降.从理论上看,一方面随着层数的增高,卷积神经网络每一层提取的特征从泛化往特殊化转变,层数越高,特征表述越细,越特定于任务.因此,除第8层结果用于分类以外,源域与目标域在第7层全连接层提取的特征差异最大,在此处进行域混淆,缩小两个域分布差异的效果最好.另一方面,体现域混淆思想的fDC层的目标函数分为域分类与域混淆两部分,最终的结果是要使得最好的域分类器达到最大的域混淆,因此,该层输入的特征表征能力越强越好,在这种情况下再进行域混淆,域适应的效果最优.
从理论上看,结合DC7比结合DC6的域适应效果更优,实验数据也验证了这一理论.
综合上文分析,结合域混淆与MK-MMD的方法进一步提升了域适应的效果,从理论与实践上都证明了本文所提出方法的有效性.且对于从信息丰富的网络图片数据集向复杂的真实采集图片数据集迁移,本文方法更加适用,提升效果更明显.
5 参数选取与分析
本文对目标函数中两种域适应损失的权重参数λ、γ进行选取与分析.MK-MMD的权重参数λ取值范围为{0.1,0.4,0.7,1,1,1,1.4,1.7,2},域混淆权重参数γ取值范围为{0.01,0.05,0.1,0.15,0.2},在不同的域适应情景下,选取合适的参数以及合理组合参数是有必要的.
对于MK-MMD的权重参数λ,文献[11]表明,在Office-31数据集中,从域A(包含丰富信息的网络图片)往域W或D(复杂的网络摄像头采集图片)迁移时,λ取1时达到最好实验效果,如图5(a)所示.但是对于源域是W或D时,这个结论并不适用.例如从W往A的迁移情景,在不同权重下的效果对比如图5(a)所示.实验证明,在这种情景下,随着λ取值的增加,域适应的效果反而逐渐变差,在λ取0.1时,效果最优,这与从域A往其他域迁移的情况是完全不同的.因此,实际操作时,对于源域信息量很丰富的情况如网络图片,MK-MMD的权重λ的取值为1,对于源域信息量较少或采集环境复杂的情况如摄像头采集图片,MK-MMD的权重λ的取值应取小值0.1.
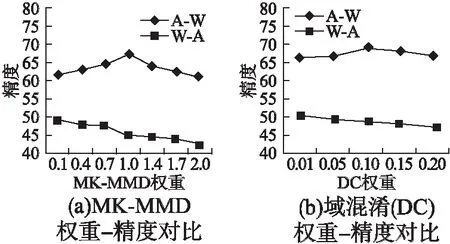
图5 不同权重精度对比图Fig.5 Comparison charts of different weights
对于体现域混淆思想的fDC层的权重参数γ,考虑到需要达到两种参数的组合最优状态,本文对每种迁移情景,在最优的λ取值下进行参数γ的实验分析.当源域为A,λ取1时,γ取0.1达到最优效果,其中域A到域W的不同权重效果对比如图5(b)所示.当源域为W或D,λ取0.1时,γ取0.01达到最优效果,其中域W到域A的不同权重效果对比如图5(b)所示.
从实验结果上看,域混淆作为一种域适应度量,其损失权重在MK-MMD的十分之一比较合适.从理论上看,域混淆作用是使得域分类效果最好的特征表示分类效果最差,如果比重过高,在训练的一开始,训练便会偏向域混淆这一边,而来不及学习到表征能力强的特征,所以域混淆的权重取较小值.同时,域适应的根本目的是获得具有域不变特性的特征表示,从这个层面来看,MK-MMD是通过缩小特征表示在映射后空间内的距离来缩小分布差异以获得域不变特性,而域混淆只是判断域混淆程度并通过优化其损失来提升特征的域不变特性,可以说MK-MMD是主动获得域不变特性,而域混淆是被动验证提升域不变特性,MK-MMD的作用更强,域混淆在这个层面上进一步提升域适应效果.因此,域混淆损失占总体损失函数比重小于MK-MMD的损失比重.
综上所述,当从信息丰富数据集(如网络图片)往采集环境复杂信息量较少数据集(如摄像头采集图片)进行域适应时,MK-MMD的权重取1,域混淆的权重取0.1;反向域适应时,MK-MMD权重取0.1,域混淆的权重取0.01.上述权重组合使得MK-MMD与域混淆的组合更合理,结果更优.
6 总 结
本文在使用MK-MMD的DAN方法基础上,结合域混淆思想进行改进并提升了域适应效果.同时,本文针对MK-MMD对不同迁移场景的作用差异,探究不同场景下该度量的适用权重,并通过实验与理论分析得出MK-MMD与域混淆的合理组合,使得改进方法的结果更优.本文提出的方法是在特征迁移层面的改进与验证,后续中将结合实例迁移层面进行进一步研究.
