V-随机森林算法在微博无效评论识别中的应用
2019-07-08刘同娟姜珊
刘同娟 姜珊


摘要:随着互联网的普及,人们利用网络自由地发表言论。面对海量增长的网络评论,有效、准确地对其分类具有重要的实际意义。在随机森林基于决策树进行分类的基础上,在分类、迭代、投票过程中引进误差函数。误差函数在全局判断过程中的作用是增加单个决策树在分类过程中的受重视度,提升整个随机森林模型的准确性,有效降低误差。
关键词:随机森林;决策树;误差函数;全局判断
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2019)13-0023-03
Abstract: With the popularity of the Internet, people use the Internet to express their opinions freely. Faced with massive growth of Internet comment, it is of great practical significance to classify them effectively and accurately. In this paper, error function is introduced in the process of classification, iteration and voting based on decision tree classification of stochastic forests. The function of error function in the process of global judgment is to increase the importance of a single decision tree in the process of classification, improve the accuracy of the whole Stochastic Forest model, and effectively reduce the error.
Key words: random forest; decision tree; error function; global judgment
随着互联网的迅速普及和发展,出现了越来越多的网上用户。人们利用网络自由地发表言论。网络上的言论内容复杂、多样,数量庞大。不少非法分子利用网络监管的漏洞,发布大量广告信息、诈骗信息、色情迷信、黄色暴力等不健康的言论 [1] 。本文将上述类别的评论统称为无效评论。
由于网络环境的复杂性,不法分子常利用网络监管的漏洞发布无效评论引导舆情走向、传递错误的价值观[2]。唯有从根源入手,抑制无效评论的发布,才是解决问题的最好办法。唯有此,才能帮助用户更好地实现言论自由,维护网络的正常运营,营造安全的网络空间。
本文以微博评论文本作为主要研究对象,在随机森林分类方法对短文本进行识别和分类的基础上,主要利用改进后的V-随机森林算法对其进行识别判断。本文中提到的V-随机森林算法,弥补了单一分类器结果的单一性和多分类器对结果的误导影响,可以充分发挥各分类器的优势。
1 理论研究
1.1 Bagging方法
Bagging方法[3],又称自助聚集方法、套袋法,是一种从训练集中随机抽取部分样本生成决策树的方法。Bagging将决策树组装形成随机森林,是将已有的分类或者回归算法通过一定方式组合起来,形成一个性能更加强大的分类器。通过组合可以将弱分类器转变形成强分类器,更准确地说这是一种分类算法的组装方法。
Bagging算法的过程如下:
1) 从原始样本集中抽取训练集。每轮从原始样本集中使用bootstrap[4]重采样的方法,抽取n个训练样本,共进行k轮抽取,得到k个训练集,训练集间相互独立。
2) 建立模型。根据需要分析的问题,选择合适的算法模型(例如决策树、感知器、回归法等),每一个训练集得到一个模型,共有k个训练集,获得k个模型。
3) 获取结果。根据解决问题的不同有不同获取结果的方式。对于分类问题,将获得到的k个模型采用投票的方式得到分类结果;对于回归问题,计算上述模型的均值作为最后的结果。
1.2 随机森林
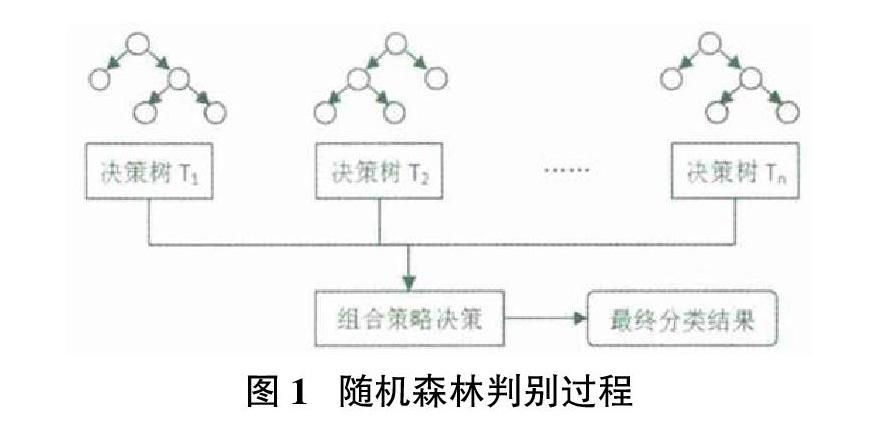
随机森林(Random Forest,RF)[5]是以决策树为基础分类器的集成分类算法,是目前较为流行的数据分析工具。其可分析的领域较为广泛,其中包括脑磁共振图像分类[6]、电力系统短期负荷预测[7] 、洪水风险评价[8]等。
用随机森林模型识别无效评论时,其结果是由n棵决策树的分类结果以简单投票的方法共同进行表决决定的,以“少数服从多数”的原则表决得到最终的分类结果。这样获取到的分类判别结果不只是单纯依赖于某一棵分类树。基于此,随机森林比单纯决策树的识别准确性要高。
对于给定的数据集M,假设需要迭代的次数为N,随机森林的算法步骤如下:
1.3 V-随机森林
虽然随机森林具有消除了过度拟合、分类性能好、分类性能好、应用广泛的优点。但是面对像微博评论这样,正负数据不平衡、数据噪声大的问题,随机森林的分类效果明也存在两重随机性,从而影响分类性能和准确性。针对正负数据不平衡的问题,改进后的随机森林算法(V-随机森林算法)的解决办法是影响训练数据集的分布抽取。即在训練集阶段赋予其一定的权值,在训练集迭代生成决策树阶段,不断更新训练样本的权值,权值代表样本数据受重视的程度。不断加大被错分样本的权值,使被错分的样本在下一轮迭代中具备更高的关注度。在投票阶段,样本的最终的分类结果由各分类器加权投票结果决定。这样在一定程度上避免了训练集样本不平衡带来的影响,提升准确率。
2 微博无效评论识别过程
2.1 预处理
微博评论数据本身是来自于网络,故文本数据存在不规范性、用词偏于口语化、内容表达不完善、错别字、用词网络化等问题。上述问题都导致数据噪声大,从而影响模型的识别准确率。
对微博评论进行预处理,在一定程度上规范文本数据的规范性,从而降低数据噪音。预处理主要包括错别字纠正、字母大小写统一转换、繁体字转为简体、去除无效符号。
2.2 特征值提取
微博评论在内容方面提取的特征值主要包括:“评论长度”“电话号码、网址、价格、日期类信息”“特殊符号比例”“无效关键词”。
一条微博评论的文字一般在50个词左右,无效评论的传播者为了达到传播某些内容的目的,字数上会尽可能得多。因此,无效评论长度一般较长,有效提取评论的长度有助于提升无效评论的识别。
广告推销类、色情服务类、诈骗类的评论中一般都具有某些特定性、显著性的特征,如联系方式、网址链接、商品价格、银行账号、日期等特殊信息。
部分无效评论为了可以不被系统识别出来,从而避免被过滤掉,会增加大量无效的符号。在识别无效评论中,其是具备明显特征的。
无效评论主要包括广告营销、诈骗信息、色情迷信、黄色暴力等方面。在分类过程中,将无效评论划分成不同类别,根据每个类别提取相应的特征值作为无效关键词。
2.3 识别过程
基于V-随机森林算法的微博无效评论分类模型如图(2)。
3 总结
传统的随机森林是由若干个独立同分布的决策树构成的,结果是由决策树简单投票表决的。但是由于每棵决策树的分类能力和准确率不同,会导致该分类器的性能下降。本文在原有随机森林的基础上,改进的V-随机森林算法通过设置权重,在迭代过程中不断更新,且最后的投票结果也是由加权投票决定的。改进的V-随机森林算法在理论上具备更好的识别率和分类性能,该算法具有一定的研究和实用价值。
参考文献:
[1] 许鑫,章成志,李雯静.国内网络舆情研究的回顾与展望[J]. 情报理论与实践, 2009, 32(3): 115-120.
[2] 彭辉, 姚颉靖.我国政府应对网络舆情的现状及对策研究——基于33件网络舆情典型案例分析 [J]. 北京交通大学学报(社会科学版), 2014, 13(3): 102-109.
[3] Breiman L, Friedman J, Olshen R, al et. Classification and RegressionTrees [M]. New York : Chapman&Hall, 1984.
[4] Efron B, Tibshirani R J. An introductin to the bootstrap[J]. Journal of Great Lakes Research, 1993, 20(1):1-6.
[5] Thongkam J, Xu G, Zhang Y. AdaBoost algorithm with random forests for predicting breast cancer survivability[C]. In:IEEE International Joint Conference on Neural Networks. IEEE, 2008:3062-3069
[6] 詹曙,姚堯,高贺. 基于随机森林的脑磁共振图像分类[J].电子测量与仪器学报,2013,27(11):1067-1072.
[7] 吴潇雨,和敬涵,张沛,等.基于灰色投影改进随机森林算法的电力系统短期负荷预测[J].电力系统自动化,2015,39(12):50-55.
[8] 赖成光,陈晓宏,赵仕威,王兆礼,吴旭树.基于随机森林的洪灾风险评价模型及其应用[J].水利学报,2015,46(1):58-66.
[9] 尚文倩,黄厚宽,刘玉玲,等. 文本分类中基于基尼指数的特征选择算法研究[J]. 机器学习和数据挖掘,2006,43(10): 1688-1694.
【通联编辑:李雅琪】
