基于热点函数的代码体积优化
2019-07-08黄昕
黄昕
摘 要:为解决嵌入式系统存储受限的问题,编译器往往禁止一些会增大代码体积的优化,如循环展开、过程内联等,导致性能下降。大部分程序中存在占据程序90%以上执行时间的“热”代码,但其体积仅占程序代码小部分。利用该程序属性,提出基于热点代码的可执行代码体积优化方法,即通过程序执行剖视信息获取“热”、“冷”代码并采用不同优化方法。测试表明,与针对性能的优化相比,该方法典型测试程序代码体积平均下降15.2%,性能仅下降3.4%。
关键词:体积优化;编译;热点函数;嵌入式应用
DOI:10. 11907/rjdk. 182595
中图分类号:TP301
文献标识码:A文章编号:1672-7800(2019)006-0042-04
Abstract: Due to limit memory capacity of embedded systems, compilers often prohibit some of the optimization that will increase the size of the code, such as loop unroll, procedure inline, etc. This may cause the loss of performance too much. It is observed that in most of programs, the "hot" code consuming 90% or above time of program execution consists of a small part of the whole program. Based on this observation, the paper proposes an executable code optimization methods based on hot code. This idea is to use the program execution profile to discover "hot" and "code" codes of a program, and then employ different strategies to optimize these "hot" and "code" codes. The experiment shows that, compared to the existing performance optimization methods, the result by the proposed method can save 15.2% volume of the code with only 3.4% loss of performance on average.
Key Words: code size optimization; compile; hot function; embedded application
0 引言
存储受限是嵌入式领域面临的难题,随着嵌入式系统的发展,越来越复杂的软件运行在嵌入式系统中,使矛盾日益突出。第一,嵌入式系统本身资源有限,但软件越来越庞大复杂,要求更大的存储空间;第二,代码复杂庞大,使代码执行开销日益增加,但用户对性能的要求也日益提高。因此需要嵌入式软件既不能占用过多的内存,又要保证提供高效的程序性能。
在嵌入式领域,针对代码体积优化一般有3种方法[1-2]:
(1)处理器设计上,使用高密度的指令集。例如,Thumb指令集是ARM指令集的子集[3-4],支持压缩至16位宽的操作码,代码密度更高。ARM程序与Thumb程序可以相互调用,且状态切换的开销基本为0。用户可以根据实际环境切换指令模式生成16位或32位指令,或增加一些复杂指令,实现原来需要两条指令才能完成的功能。
(2)代码压缩技术[5]针对指令编码进行一系列变化,对可执行代码进行压缩,删除原文件中冗余的信息,减少代码大小。
(3)编译优化[6-9]。编译器在将源程序转换为可执行程序过程中,以优化代码体积为目标,执行各种转换,例如冗余代码删除、循环合并等。
与前两种方法相比,编译优化技术由于不需要对硬件进行修改,且操作灵活,已在商用与开源编译器中得到了广泛应用。例如Intel商用编译器与开源编译器GCC、LLVM均提供“Os”选项[6-9],指明进行针对代码体积的优化,生成的代码体积小于缺省的“O2”优化及针对性能的“O3”优化。但现有编译优化技术在缩小代码体积的同时,由于对一些会增大代码体积的优化进行限制,较大程度地影响了性能。
本文首先对在嵌入式领域中应用广泛的GCC编译器现有代码体积优化进行分析、评测,在此基础上提出基于热代码的代码体积优化技术,通过性能分析工具中找出程序中的“冷”、“热”代码,进行分别优化,从而在代码体积优化的同时尽可能减少对性能的影响,利用Python语言[10]实现自动工具。测试结果证明了该技术的有效性。
1 面向代码体积的编译优化
1.1 代码体积优化技术
无论是Intel商用编译器,还是开源编译器GCC、LLVM[6-9],编译器针对代码体积的优化一般包括两类:
(1)采用删除冗余代码、向量化等方法减少代码体积。冗余代碼删除指通过删除程序不必要的计算,减少可执行代码体积[11]。常用冗余代码删除优化方法包括:死代码删除、公共表达式删除、循环不变量外提、常数传播、复制传播、代码提升、值编号、部分冗余删除等[12-13]。例如在GCC中, GIMPLE语法树和RTL[14]中间语言均执行了多种冗余删除优化。向量执行是目前处理器提高性能的主要途径之一[15]。编译向量化指利用处理器提供的向量功能部件,包括向量寄存器、向量执行部件,生成可以并发执行的向量指令。一条向量指令同时可以处理多个数据。因此,向量化能够减少可执行代码体积。循环合并[16]把多个相邻且具有相同迭代空间的循环合并成一个循环,一方面增加单个循环体积,为指令调度、冗余删除等优化提供更多的机会;另一方面,合并循环也删除了重复的循环判断、控制变量修改等操作。
以上优化方法通常在减少可执行代码体积的同时也提升了程序性能。
(2)禁止增大代码体积的编译优化。为减少生成的可执行代码大小,编译器会禁止一些增大代码体积的优化。例如,在GCC编译器[7-8]中,禁止循环展开、基本块重排与分布、循环分布、插入预取指令等优化。具体指除了禁止循环展开、过程内联、循环分布等,Os选项会關闭以下优化选项:①align-functions :函数对齐。align-functions=N 将所有函数起始地址在N(N=1,2,4,8,16…)的边界上对齐,默认为机器自身默认值,指定为1表示禁止对齐;②align-jumps:跳转对齐。align-jumps=N 将分支目标在N(N=1,2,4,8,16…)的边界上对齐,默认为机器自身默认值,指定为1表示禁止对齐;③align-loops :循环对齐,确保不会在分支目标前插入多余的空指令;④falign-labels :标号对齐,确保不与falign-jumps产生冲突。对齐优化通常用于提高Cache利用率,为保证对齐,编译器会进行空指令插入、数据垫塞等,从而增大可执行代码体积;⑤reorder-blocks/ reorder-blocks-and-partition:基本块重排和基本块重排与划分。通过基本块重排可提升指令Cache的利用率,但是可能会插入较长的跳转指令;⑥prefetch- loop-arrays:插入数据预取取指令,以隐藏访存延迟。
1.2 GCC针对代码体积的优化评测
对GCC针对可执行代码体积的优化能力进行测试,测试分为两个方面:一是使用了Os后代码体积的减少;二是使用Os对代码性能的影响。测试在lenoveEdge531机器上进行,测试环境为Linux 内核3.14、gcc 7.2.0编译器,测试程序选用通用的NPB 3.3-SER[17]基准测试集。
首先对比测试可执行代码的体积,结果如图1所示。
显然,与O3相比,针对代码体积的Os优化取得了良好效果,可执行代码体积平均下降了30.5%,尤其是BT、LU和SP,体积下降超过40%。程序EP由于自身代码量小,去掉注释仅约230行,因此效果不明显。代码体积减少主要得益于Os禁止了会显著增大代码体积的优化,但是对性能会产生较大的负面影响,使用Os与O3时性能对比如图2所示。
与O3相比,采用Os选项,NPB平均执行时间增加了18.3%,尤其是LU与MG程序,执行时间分别上升了59%与43%。
因此目前通过编译器进行针对代码体积的优化,最大问题在于对性能的影响,即减小了代码体积的同时,性能也明显下降。
2 基于热点函数的代码体积优化
2.1 热点函数
几乎所有软件皆存在“热点”。热点是指占据程序绝大多数运行时间的代码。该部分代码往往仅占程序一小部分。例如,为保证程序正确性、鲁棒性,程序中许多代码用于边界及错误处理,在程序正常运行时通常不被调用或者极少被调用,但代码量巨大。通过性能分析工具[18-19],可快速获得程序热点函数。以NPB为例,程序热点函数及热点函数占据的代码比例如表1所示,多数程序占据程序执行时间90%以上的热点函数,代码量仅为总代码量的30%。
2.2 可执行代码体积优化
利用程序“热点”函数属性,可通过对“热”、“冷”代码区别对待,在降低对程序性能影响前提下,尽可能优化可执行代码体积,即针对占据程序大部分执行时间的“热点”函数,进行代码性能优化;针对占据程序大部分代码体积的“冷”代码,进行代码体积优化。算法流程如图3所示。
优化主要分为3步:①获取热点函数;②设置热点函数标记位,在编译该函数时,采用性能优先的优化方法;③使用带按摩大小有限的编译选项Os,生成编译命令。利用代码运行时获取的性能信息(运行剖视profile文件)[18-19],可较为精确地获取程序热点代码。在没有运行剖视文件的情况下,利用编译基于启发信息的静态分析,也可大致获取热点函数。编译器编译时通常以函数为单位,设置热点函数标记位,编译到该函数时,修改选项为性能优先。其它函数均使用代码大小优先的选项进行编译,保证频繁执行的热点函数执行时间不发生大幅下降。其它程序部分进行针对代码大小的优化,减少可执行代码体积。
3 测试
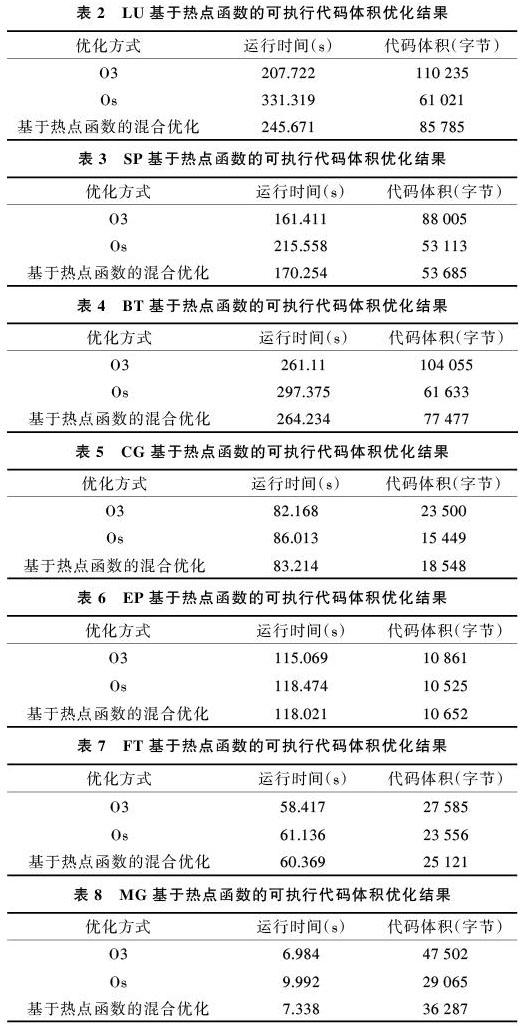
测试在lenoveEdge531机器上进行。对于热点函数采用O3优化,其它函数采用Os优化。优化后的结果对比如表2-表8所示。
从测试结果可以看出,基于热点函数的可执行代码体积优化取得了较理想结果:①和O3相比,性能最多仅下降15.5%(LU),平均下降3.4%,但是代码积平均下降15.2%;②和Os相比,代码体积平均仅增加8.3%,但是性能提高了7.5%。
4 结语
存储受限是嵌入领域面临的主要问题之一。目前针对代码体积的编译优化对性能有较大影响,本文提出基于热点代码的可执行代码体积优化,在尽可能不影响性能的前提下,减少程序可执行代码体积。利用NPB测试程序验证了方法及工具的效果,下一步研究将使用典型嵌入式程序,例如Arduino智能小车[20],对方法进行验证;同时将自动工具与程序Makefile等结合,进一步实现优化过程的完全自动化。
参考文献:
[1] BESAEDES A,FERENC R,GYIMóTHY T,et al. Survey of code-size reduction methods[J]. ACM Computing Surveys,2003,35(3):223-267.
[2] 廉玉龙.面向嵌入式处理器的编译优化技术研究[D]. 杭州:浙江大学, 2016.
[3] ARM Ltd. Thumb? 16-bit Instruction Set[R/OL] http://infocenter.arm.com/help/topic/com.arm.doc.qrc0001l/QRC0001_UAL.pdf.Accessed:2018-10-02.
[4] ARM Ltd. ARMv7-M Architecture Reference Manual[R/OL]. https://static.docs.arm.com/ddi0403/e/DDI0403E_B_armv7m_arm.pdf.
[5] SUTTER B and BOSSCHERE K. Software techniques for program compaction[J]. Communications of the ACM, 2003, 46(8):33-34.
[6] INTEL Corp. Intel? Parallel Studio XE 2018[R/OL]. https://software.intel.com/en-us/parallel-studio-xe, 2018.
[7] BESZéDES A,GERGELY T,GYIMOTHY T,et al. Optimizing for space : measurements and possibilities for improvement[C]. Proceedings of the 2003 GCC Developers' Summit, 2003:7-20.
[8] ANORMITY. Using the GNU compiler collection(GCC)[EB/OL]. http://gcc.gnu.org/onlinedocs/gcc-8.2.0/gcc.
[9] ANORMITY. LLVM user guides[EB/OL]. http:// https://llvm.org/docs/GettingStarted.html.2018.
[10] BEAZLEY D & JONES B K. Python cookbook. [M]. 3rd Edition. Sebastopol :ORelly Media. Inc,2013.
[11] STEVEN M. Advanced compiler design and implementation[M]. San Francisco:? Morgan Kaufmann, 1997.
[12] BRIGGS P, COOPER K D, SIMPSON L T. Value numbering[J]. Software-Practice and Experience, 1997,17(6):701-724.
[13] XUE J ,CAI Q. A life optimal algorithm for speculative PRE[J]. ACM Transactions on Architecture and Code Optimizaion, 2006, 3(3): 115-155.
[14] ANORMITY. GNU compiler collection (GCC) internals. [EB/OL], https://gcc.gnu.org/onlinedocs/gccint/index.html. 2018
[15] 高偉,赵荣彩,韩林,等. SIMD自动向量化编译优化概述[J]. 软件学报,2015,25(6):1265-1284.
[16] KENNEDY K, RANDY A. Optimizing compilers for modern architectures: a dependence-based approach[M]. San Francisco:Morgan Kaufmann. 2001.
[17] NASA. NPS parallel benchmarks[R/OL]. http://nas.nasa.gov/Software/NPB.
[18] GNU Gprof. [EB/OL]. http://sourceware.org/binutils/docs/gprof/index.html. 2018.
[19] INTEL Corp. Intel Vtune Amplifier[R/OL]. https://software.intel.com/en-us/intel-vtune-amplifier-xe/.
[20] ANOMITY. Adruino smart car[EB/OL]. https://create.arduino.cc.
(责任编辑:江 艳)
