基于语义分析和神经网络的WebShell检测方法
2019-07-08张昊祎
张昊祎

摘 要:论文提出了一种语义分析和神经网络模型相结合的WebShell检测方法,通过对预编译后脚本文件进行语义分析,基于抽象语法树获取脚本文件的行为特征;基于BP神经网络对样本进行有监督学习,得到可用于未知样本的检测模型。不同于现有基于语义分析的检测方法,论文提出的方法无需人工定义恶意行为,从而有效屏蔽各类逃逸技术的干扰。实验证明,论文提出的WebShell检测方法具有较高的准确率和召回率。
关键词:BP神经网络;语义分析;WebShell;入侵检测;Web安全
中图分类号:TP309.5 文献标识码:A
A method for WebShell detection based on semantics analysis and neural network
Zhang Haoyi
(School of Electronics Engineering and Computer Science Peking University, Beijing 100871)
Abstract: This paper proposes a WebShell detection method combining semantic analysis and neural network. Through semantic analysis of pre-compiled script files, the behavior characteristics of script files are obtained based on abstract syntax tree. Classifier model can be trained based on back propagation neural network that can be used for unknown samples. Different from the existing detection methods based on semantic analysis, the proposed method does not need to manually define malicious behavior, thus effectively shielding the interference of various escaping technologies. The experiment proves that the WebShell detection method proposed in this paper has higher accuracy and recall rate.
Key words: BP neural network; semantic analysis; WebShell; intrusion detection; Web security
1 引言
随着Internet的迅速发展和Web技术在各行业的广泛应用,Web安全逐渐成为信息安全领域最重要的攻防战场之一。WebShell是一种常见的Web攻击技术,由攻击者通过文件上传、SQL注入等攻击手段植入Web应用内,常用于权限维持、数据窃取、内网探测等攻击目的。根据知道创宇于2019年上半年发布的《2018年度网络安全态势报告》,扫描器和网站后门(即WebShell)已成为攻击者最常用的Web攻击技术,共占比79%。因此,快速、准确地进行WebShell的检测在安全防守端尤为重要。
2 WebShell
WebShell是基于Web脚本语言开发的,可由Web服务器解析和执行的一类恶意脚本。通过植入WebShell,攻击者可以相对隐蔽地对服务器进行远程控制,对Web安全乃至内网安全都会造成极大威胁。WebShell的行为和目的主要包括四个方面。
信息嗅探:以嗅探Web运行环境信息、主机信息、数据库信息、IDC网络信息为目的,将收集到的各类信息回显在页面中或通过其它渠道反馈给攻击者,攻击者可以将收集到的信息用于下一步的入侵中。
权限维持:攻击者可以通过HTTP请求的参数(包括GET/POST参数、Cookie、Header等)传递命令,由WebShell以Web应用运行权限执行命令,是一种攻击成功后较隐蔽的权限维持手段。此外,攻击者还可以通过各种反弹Shell手法获取到交互式Shell,利用系统本地内核漏洞进行提权。
数据窃取和篡改:嗅探到数据库连接方式等配置信息后,攻击者可以利用WebShell窃取或篡改数据库内的敏感信息。
网络代理:攻击者可以利用WebShell建立TCP/IP网络隧道,用于嗅探、扫描IDC网络和进一步的内网渗透,例如著名的reGeorg工具就利用了WebShell建立SOCKS5隧道。
3 WebShell检测逃逸技术
通过对大量WebShell样本进行分析,以及对黑客论坛中的WebShell逃逸技术进行总结,可以将WebShell逃逸技术进行分类。
3.1 字符串编码与构造
简单的WebShell静态检测技术的主要思路是关键函数关键词匹配,WebShell开发者可以通过对函数字符串中的敏感词进行编码,在运行时再进行解码,从而逃避关键词匹配检测。常见的编码方式为大多数语言内置支持的Base64、Rot13等编码。此外,还可对字符串进行混淆,包括乱序、移位、逻辑运算后,在运行时重新构造。
3.2 代码混淆
基于统计学的检测方法对脚本文件的统计指标进行提取,包括文件字符长度、信息熵、重合因子等。为了使WebShell的这些指标与正常页面文件保持一致,WebShell開发者常在脚本内加入大量看似正常的无效代码、HTML内容等进行混淆。
3.3 利用反射机制
绝大多数Web语言,包括ASP、PHP、JSP等均提供反射或序列化机制,WebShell开发者可以利用反射机制逃避关键类名/方法名/属性名等特征匹配,再配合上述字符串编码与构造技术,WebShell将在不出现任何关键词的情况下执行敏感操作。
3.4 文件包含
通过将WebShell拆分成多个较小的文本或图片文件,再通过文件包含进行汇总。将恶意执行的语句拆分到不同文件中,可以避免在一个WebShell文件中出现大量特征,从而干扰WebShell检测结果。
3.5 流量加密
基于流量的WebShell检测提取攻击者和WebShell通信时的流量特征,为了隐藏HTTP请求中下发的指令关键词,可以利用加密或编码技术对请求参数进行加密,从而逃避这类检测。而随着信息熵等指标在检测中的应用,流量加密的方式也在不断发生变化。
3.6 隐蔽通道
与流量加密类似的,为了逃逸基于流量的检测方法,攻击者可以通过隐蔽通道传递执行信息。例如,将指令隐藏在脚本文件名中,调用时并不直接传递指令,而在WebShell内根据脚本文件名执行指令。同时,还可以利用HTTP会话机制,将指令隐藏在会话属性中,从而实现指令下发的隐蔽通道。
4 相关研究
与其他安全防御领域类似,根据WebShell的检测和防御手段的介入阶段不同,可以分为事前预警、事中检测、事后追溯三种。对WebShell的检测防御思路主要分为基于文件的检测、基于流量的检测、基于行为的检测和基于日志的检测等。其中,基于文件的检测是在WebShell刚被植入时,通过对文件属性、内容、关键字等进行静态分析判断是否为WebShell,属于事前预警;基于流量的检测是从攻击者与WebShell的交互流量中提取特征并进行判断,基于行为的检测是在WebShell运行时对其异常行为进行分析,这两类均属于事中检测;而基于日志的检测是对Web日志进行全局分析,发现正常访问日志与WebShell访问日志的差异,从而判断是否已经遭受了WebShell攻击并定位WebShell,属于事后追溯。
基于文件的检测是利用WebShell与正常页面文件在哈希值、属性、文本关键词、统计指标等方面的差异,对WebShell进行静态检测的技术。一种思路是对所有流通的WebShell样本进行收集,计算文件哈希形成WebShell指纹库,如WebShell Detector工具,自称可以达到99%的识别率。这种方法需要长期的人工维护样本库,而且可以非常容易地进行绕过(增加任意无效代码即可)。孔德广等在[1]中提出基于局部敏感散列算法的检测方法,可以一定程度上避免局部修改和混淆造成的绕过情况。国内著名的WebShell检测工具D盾通过在文件内查找恶意函数等方式进行检测,这有可能被字符串编码构造等混淆技术绕过。针对常见WebShell检测逃逸技术,NeoPI[2]通过提取信息熵、最长单词、重合指数、压缩比等特征,可以有效判断出样本是否采用了混淆和逃逸。戴桦等在[3]中提出基于矩阵分解算法的检测方法,贾文超等在[4]中提出基于随机森林算法的检测方法,胡必伟等在[5]中提出基于朴素贝叶斯的检测方法,均采用了功能函数、重合指数、信息熵、最长单词、压缩比等文本特征和统计指标作为样本特征,取得了较好的检测效果。但由于上述方法样本特征需要人工参与设置和选择,对于0Day型的WebShell检测能力仍属未知。易楠等在[6]中提出了基于语义分析的WebShell检测方法,突破性地提出利用AST和人工定义风险特征库提取污点子树,计算文件危险程度,再通过人工设置阈值的方式进行定性判断。
攻击者在与WebShell通信时的参数关键词、访问行为统计指标、信息熵、页面关联性等方面存在差异,基于流量的检测技术就是对这些差异进行分析,提取特征并通过一定算法进行分类。
基于行为的检测利用WebShell在活动时对系统执行的行为与正常页面文件的差异性进行检测。根据WebShell检测中对WebShell目的的分析,WebShell常会在运行时出现文件读写行为、网络监听行为、数据库连接行为等。采用Hook技术、RASP等可以对WebShell运行时的行为进行收集,并采用一定规则或算法进行检测。
基于日志的检测是从Web日志的文本特征、统计特征、响应页面特征等方面提取特征,对正常业务访问日志进行建模,从而利用无监督聚类等方式对WebShell访问请求进行检测。
当WebShell已经被攻击者访问时安全性将变得不可控,可能在一次请求后即建立了更为隐蔽的C&C连接或造成了一定的损失。本文认为安全防御应该尽可能早地介入攻击链条中,因此本文提出的检测方法属于事前预警类检测。在特征提取阶段即获得抽象层面的行为特征,对上述字符串编码与构造、代码混淆、利用反射机制、文件包含等形成降维打击,可以有效对抗已知的检测逃逸技术;采用BP神经网络建设WebShell检测分类模型。与[6]中提出的基于语义分析的检测方式不同,本文的检测方法并非只针对PHP语言,兼容性较强;且无需人工定义和维护风险特征库。
5 基于抽象语法树的特征提取
抽象语法树(Abstract Syntax Tree,AST)是编程语言的抽象语法结构的树状表现形式,作为编译器后端的输入,不依赖于具体的文法和语言的细节。通过对抽象语法树进行分析,可以获得对代码语义层面的理解。抽象语法树的生成过程包括词法分析和语法分析两个步骤,其中词法分析是将代码字符流转变为标记(Token)的过程,语法分析是根据标记集合构造抽象语法树的过程。
以Python为例,下面一段代碼与其生成的抽象语法树为:
import os;os.system(cmd)
Module(body=[
Import(names=[
alias(name='os', asname=None),
]),
Expr(value=Call(func=Attribute(value=Name(id='os', ctx=Load()), attr='system', ctx=Load()), args=[
Name(id='cmd', ctx=Load()),
], keywords=[], starargs=None, kwargs=None)),
])
由于WebShell的编写有很大的可变性,为了逃逸检测可以采取多种方式对代码本身进行混淆,如果仅在文本层面提取WebShell特征,则会陷入极大的被动,造成大量的漏报。因此,通过对WebShell文本进行语义分析,从语义角度获取代码行为意图,对各类逃逸技术进行降维打击,从而获得相对稳定的WebShell特征。
综合各种编程语言的抽象语法树定义,树节点主要包括声明(Statement)、表达式(Expression)、注释(Comment)、定义(Declaration)、类型(Type)等。为了最大程度地屏蔽代码混淆等对特征提取结果的影响,从提取WebShell实际行为的目的出发,本文认为只有函数调用表达式有实际意义,而外部库引用、变量定义、类/方法定义、注释等节点信息没有参考意义。函数调用表达式包括调用类、调用方法、调用参数三部分组成,其中调用类指函数调用主体类型,调用方法指调用的具体函数,调用参数指调用函数时传入的参数,如下所示:
os.system(cmd)
Expr(value=Call(func=Attribute(value=Name(id='os', ctx=Load()), attr='system', ctx=Load()), args=[
Name(id='cmd', ctx=Load()),
], keywords=[], starargs=None, kwargs=None)
由于WebShell可以對语言内置类和方法进行重新封装和重载,为了获取实际调用类和方法,在抽象语法树遍历节点时对内部或外部引用的自定义类型和方法的调用进行递归追溯,最大程度上保证函数调用特征提取的完整性和一致性。由于WebShell编写和逃逸技术应用不尽相同,安全函数调用和危险函数调用的次数和顺序与WebShell实际行为没有必然联系,因此本文认为在抽象语法树遍历时,同一类方法的调用次数不影响该函数调用的权重;不同类方法的调用顺序与其实际语义无关。此外,类名、变量名等应解析为对应的全限定名(Fully Qualified Name,FQN),以获取其明确唯一的类型表示。通过抽象语法树的生成和遍历解析,可以得到该脚本文件内的函数调用的无序不重复的函数调用集合。以JSP语言为例,抽取的函数调用集合如图1所示。
采用词集模型(Set of Words)对提取出来的函数调用集合进行向量化,获取函数调用字典及样本的向量化表示。给定样本集,将其中所有出现过的函数调用整合为一个词汇表L(Lexicon),对于任意样本,的函数调用集为,那么该样本向量化表示为。如果词汇表中第个词出现在中,那么该样本此处的向量分量就为1,否则就为0,即:
,
至此,已通过解析抽象语法树得到样本集的特征向量化表示。
6 BP神经网络
误差反向传播(Back-Propagation,BP)神经网络是一种有监督的,使用误差反向传播算法(BP Algorithm)迭代训练的多层前馈神经网络。各个特征分量之间存在无法预知的相互关联,与WebShell检测结果间存在一定的非线性对应关系,鉴于BP神经网络具体较强的非线性映射能力和泛化性能,本文采用BP神经网络来逼近这一对应关系,从而获得更好的WebShell检测效果。
BP神经网络由输入层、多个隐含层和输出层组成,各层包含多个神经元,相邻层神经元之间全部相互连接;每层神经元接收上一层所有神经元的输出,使用连接系数和偏置量计算得到该神经元的输出结果。BP神经网络训练包括正向传播过程和误差反向传播过程:通过正向传播过程,在输入层输入的特征向量经过多个隐含层转换,最终从输出层获得输出结果,如果输出与实际标签结果误差不满足期望,则进入误差反向传播过程;误差反向传播过程中,利用梯度下降法由输出层到输入层的方向逐层调整各层神经元的连接系数和偏置量等参数,然后进入下一次迭代。通过正向传播和反向传播过程的不断迭代,调整网络参数达到期望的输出误差。
为实现非线性映射的表达能力,在每个神经元使用输入、连接系数和偏置计算后,使用激活函数(Activation Function)对计算结果进行非线性变换,常用的激活函数包括Sigmoid、Tanh、ReLU等。为量化评估神经网络的输出与实际标记之间的差距,使用损失函数(Loss Function)对输出结果进行计算。WebShell检测的应用场景属于典型的二分类问题,常用的分类问题损失函数包括均方误差(Mean Squared Error,MSE)损失函数、交叉熵(Cross Entropy)损失函数等。
7 WebShell检测系统设计
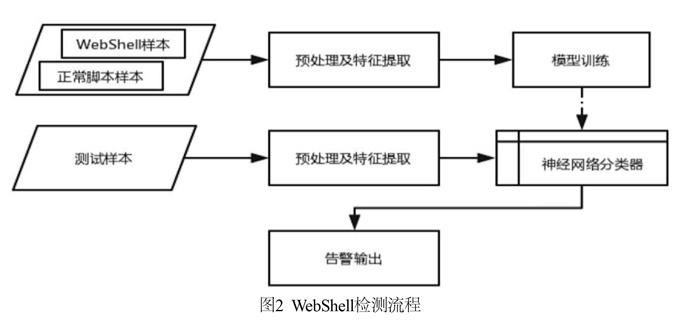
基于BP神经网络的WebShell检测为标准的有监督学习的二分类任务,结合抽象语法树的提取过程,系统模型包括预处理模块及特征提取模块、模型训练模块、WebShell检测及告警输出模块三个基本模块。检测流程如图2所示。
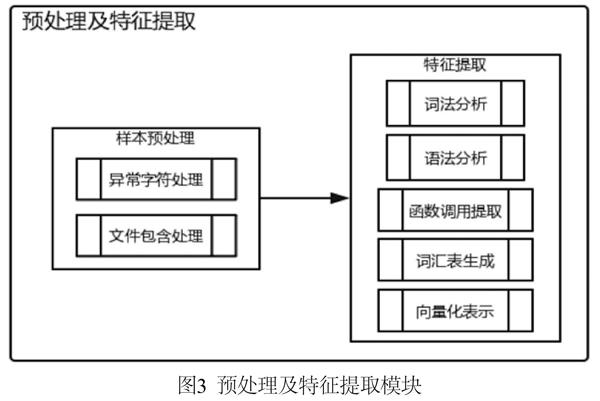
其中,预处理及特征提取模块包含样本预处理和特征提取两个子模块。样本预处理子模块用于对样本中的异常字符进行处理,防止样本格式不规范对特征提取造成影响。此外,在样本预处理子模块中处理脚本文件的文件包含处理,将被包含的文件内容整合在一个文件中,从而提取样本最完整的特征,防止WebShell通过拆分成多个文件逃逸检测。特征提取子模块包括词法分析、语法分析、函数调用提取、词汇表生成及特征的向量化表示等处理过程。预处理及特征提取模块工作流程如图3所示。
告警输出模块采用高可读性的方式对WebShell检测结果进行输出。
8 实验与分析
8.1实验数据集
本文提出的检测方法对各类语言开发的WebShell均适用。采用JSP语言编写的WebShell样本作为实验数据集,WebShell样本来源为Github中WebShell收集比较全面的项目,共收集232个WebShell样本;正常脚本样本收集来源为开源的CMS Web项目,包括Jeewx、Tianti、Infoglue、Jeesite等,以及Github随机爬取的JSP/JSPX,共收集415个正常脚本样本。
8.2 效果评估
WebShell检测属于典型的二分类问题,对于这类问题,检测结果可以表示为如表1所示的混淆矩阵。
WebShell检测的准确率,召回率。由于准确率和召回率属于互相矛盾的度量指标,为均衡表示WebShell检测模型的效果,使用度量表示模型的综合性能,其中。对样本进行随机取样,取十次实验结果的平均值。
8.3 实验结果
通过本文所述方式对所有JSP/JSPX文件进行语法分析和特征提取,首先利用org.apache.jasper.Jsp库对样本文件进行预编译,获得等价的Java脚本;再利用com.github.javaparser相关库进行语法分析从而获取抽象语法树;对抽象语法树进行解析,获取函数调用序列,并利用词集模型进行特征向量化,得到1418维特征向量。通过主成分分析(Principal Component Analysis,PCA)处理后,样本的分布圖如图4所示。
从图4中可以看到,通过语法分析特征提取,WebShell可以相对明显地区分于正常样本。采用包含2个隐藏层的BP神经网络模型,隐藏层神经元个数分别为200、50,损失函数为交叉熵(Cross Entropy)损失函数,每一层之后使用线性整流单元(Rectified Linear Unit,ReLU)作为激活函数。实验结果平均模型准确率为0.9909,召回率为0.9869,模型的综合性能F1为0.9858。
基于神经网络分类器的实验指标与其他WebShell检测文献的实验结果进行对比,如表2所示。
从表2中可以看出,得益于基于语法分析的特征提取的完整性及BP神经网络较强的非线性映射能力,本文提出的WebShell检测方法具有较高的准确率和召回率。
9 结束语
本文对WebShell的行为目的和常见逃逸技术进行了分析和阐述,为对抗WebShell逃逸技术对WebShell检测造成的影响,提出基于抽象语法树的WebShell特征提取方法;基于BP神经网络训练得到表达能力和泛化性能较佳的分类模型。区别于其它基于语义分析的WebShell检测方法,本文提出的检测方法无需人工定义风险特征库和设置判定阈值。实验结果表明,本文提出的WebShell检测方法具有较高的准确率和召回率。
本文提出的WebShell检测方法仍存在一些优化点:可基于抽象语法树细化样本特征,基于数据流的方式提取函数调用序列,从而利用卷积神经网络(Convolutional Neural Network,CNN)、注意力模型(Attention Model)等对WebShell的行为目的进行更深入的建模;可以结合基于流量或基于行为的WebShell检测技术,将静态分析结果与动态执行监控结合起来,进一步完善WebShell的特征,提高分类器的性能。
参考文献
[1] 孔德广,蒋朝惠,郭春,等.基于Simhash算法的Webshell检测方法[J].通信技术,2018.
[2] Tu T D,Guang C,Xiaojun G,et al.Webshell detection techniques in web applications[C]// 2014 5th International Conference on Computing, Communication and Networking Technologies (ICCCNT). IEEE Computer Society,2014.
[3] 戴桦,李景,卢新岱,等.智能检测WebShell的机器学习算法[J].网络与信息安全学报, 2017(4):55-61.
[4] 贾文超,戚兰兰,施凡,等.采用随机森林改进算法的WebShell检测方法[J].计算机应用研究,2018, 35(5).
[5] 胡必伟.基于贝叶斯理论的Webshell检测方法研究[J].科技广场,2016(6):66-70.
[6] 易楠,方勇,黄诚,等.基于语义分析的Webshell检测技术研究[J].信息安全研究,2017(2).
