一种用户连续查询中隐私风险评估的方法
2019-07-01马永东王文涛王银款
马永东 王文涛 王银款

摘 要:用户在线查询服务中的隐私风险评估与隐私保护有着等同的重要性。关于用户查询隐私保护的研究引起了广泛关注,而对于用户查询隐私风险评估的研究较少。其中,连续查询作为查询一种重要表现,合理地对用户连续查询进行隐私风险评估,能够有效抵抗用户查询中隐私泄露。因此,本文基于隐马尔可夫模型(Hidden Markov Model,HMM)首次提出了一种能够动态评估用户连续查询隐私风险的方法,通过分析用户连续查询时存在的重要特征,以概率的方式评估用户每次查询时的隐私风险大小。最后,为了验证该方法的有效性,采用美国在线(AOL)真实的用户查询日志数据进行分析和证明,实验结果表明该方法具有较高的风险评估准确率,同时评估时间符合实际的用户查询需求。
关键词: 用户连续查询;查询隐私风险;HMM模型;动态评估文章编号: 2095-2163(2019)03-0049-05 中图分类号: TP309 文献标志码: A
0 引 言
近年来,在线查询极大提高工作及学习效率,但也随之带来了各种隐私泄露问题[1-4]。面对这一状况,国内外众多学者提出了不同的解决方法,如匿名查询[3]、覆盖查询[4]、安全通信[5]、数据混淆[6]等。以上方法在一定程度上实现了隐私保护,但对隐私保护成本以及隐私保护合理性却未能给予适当关注。其主要原因是用户的每次查询中隐私风险是不同的。特别是在用户连续查询的场景下,如在查询一个复杂的医学问题时,需要用户多次查询或进行更长时间的查询。若采用现有的查询隐私保护方法,很容易造成隐私保护强度过高,如文献[7]中假设用户的每次查询都是高风险查询,对用户的每次查询采用相同的隐私保护方法进行保护,但这却会影响用户实际的查询精确度和查询时间效率。而查询风险评估与隐私保护是同等重要的[8],目前仅有部分工作考虑了对用户查询时隐私泄露的风险评估[9-10]。
针对上述问题,本文结合实际查询场景,通过对用户在连续查询时存在的两大重要特性,即:递进关系(Progressive Relationship, PR)和共现关系(Co-occurrence Relationship, CR)进行分析。其中,PR是指用户对当前的查询结果不满意时,将另外补充新词来缩小查询范围,进行再次查询。CR是指当用户的2个或2个以上的查询频繁在同一个Session中共现时,则可以认为此时的查询之间存在共现关系,且该查询间有着紧密的相关关系。采用HMM建立用户查询动态风险评估方案,对用户的每次查询进行风险大小评估,就可以根据用户查询风险进行合理的隐私保护,实现隐私保护的同时,在很大程度上也节省了隐私保护成本。
1 相关工作
本节主要对现有用户查询隐私保护技术和查询风险评估两个方面给出优缺点分析。对此可做研究阐述如下。
在查询隐私保护技术中,Roger[5]提出了一种在查询时隐藏用户身份与第三方监控的方法。文献[11-12]在此基础上提出了协作方案,以便让每个用户提交由其他用户生成的查询,使得用户隐藏在各自的用户组内。然而,该解决方案的响应时间比较慢,严重依赖后端系统的可用性,因此该方法无法得到广泛的应用。Balsa等人[13]提出了一种混淆的私有Web搜索(OB-PWS)方案,通过将生成的虚拟查询和用户的真实查询一同发送到搜索引擎,以防止对搜索概要文件的准确推断,并提供查询可拒绝性。Howe等人[14]提出了一种随机发布虚拟查询方法,在程序生成的诱饵流中混淆用户的查询来实现Web搜索中的隐私保护方法。Domingo等人[12]提出并验证了一套保证用户查询隐私的方法和协议。但是以上方法在查询效率方面无法满足用户需求。此外,Arampatzis等人[15]还提出一种使用模糊或混乱的查询来替换私有用户查询,从而近似于目标搜索结果。接下来,经过排序的查询结果用于覆盖私有用户感兴趣的内容。但只能落入预定义字典的查询中,极大地限制了用户灵活性。后续工作中进一步考虑了生成的查询与真实查询之间的语义相关性[16],注入与原始查询术语具有相似特异性的诱饵术语[17]来维护用户查询的匿名性和通用性。以上方法中均沒有解决用户每次查询时的风险高低的问题。
查询风险评估与隐私保护起着同等重要的作用[17]。然而,只有有限的工作考虑了对用户查询时隐私泄露的风险评估。Peddinti等人[9]基于机器学习分类器对TMN(TrackMeNot)提供的隐私保障进行了评估。Gervais等人[10]通过机器学习算法学习用户的原始查询和假查询之间的可链接性,对TMN和假查询生成等查询混淆技术进行了评价。Howe等人[14]通过对现有6种混淆技术的隐私特性进行定性分析,却没有对这些技术做出定量的分析和比较。Chow等人[18]提出了2个可以用来区分TMN虚拟查询和实际用户查询的方法。然而,现有研究很少对用户在线查询进行动态隐私泄露风险评估,但是这对隐私保护却至关重要。因此,本文针对用户连续查询提出一种动态风险评估的方法,为用户查询隐私保护提供一个较好的解决思路。
2 基于动态风险评估模型
2.1 预备知识
隐马尔可夫模型(Hidden Markov Model,HMM)是一种统计模型,用来描述一个含有隐含未知参数的马尔可夫过程,已广泛应用于模式识别、词性标注和信息提取方面[19]。
HMM是根据可观察的参数确定该过程的隐含参数,继而利用这些参数展开后续分析。在HMM中,输出状态并不是直接可见的,每一个状态在可能输出的符号上都有一概率分布。因此输出符号的序列能够透露出状态序列的一些信息。为更清晰描述整个HMM过程,设用户查询序列为X=x1,x2,…,xn,其中xi代表每一个节点,且每个节点xi都存在着一个转移概率P,那么,在一个隐马尔可夫模型M上,一个查询序列X被观测的概率为在所有可能路径上的概率之和。这里可将其写作如下数学形式:
2.2 参数确定
在建立HMM模型时,结合用户的PR和CR查询特征,从转移概率和观测概率角度进行分析。研究可得阐释分述如下。
(1)转移概率。是指用户给出先前查询数据序列后,再经过若干时间后得到用户的另一查询数据的条件概率。如相连的两节点q1,q2之间存在着一个转移概率Pq1→q2,由于用户在连续查询场景下,用户查询数据可区分的风险取决于用户之前的查询数据,如果考虑同一主题中的先前数据,则该数据的信息增益会变高。设Xt为HMM中个人可识别敏感信息或者是敏感主题,则Xt节点之间的转移概率为pXt|Xt-1,可以对节点之间已发生的转换次数进行加权计算,研究可推得其数学公式如下:
(2)观测概率。是指某个节点可能发生的查询行为,如用户ui经过q查询了e的概率为Pe|q。该值基于用户的历史查询数据进行分析和计算获得,每个节点包含一组具有观测概率的观测值,将这些观测概率建模为不同用户在先前数据pui|Xt中找到的给定数据Xt的概率。用户查询特定主题的数据越多,则对用户兴趣数据的推断精确度越高,该查询风险也越高。同理,采用加权计数的方式确定查询风险,研究可推得其数学公式如下:
2.3 查询动态风险评估
在用户连续查询场景中,假设用户当前的查询为XT,只与前一查询XT-1相关。例如用户在查询一个复杂问题(医学知识等)时,当前的查询结果不满足用户的查询需求时,用户会添加或删除前一次的查询内容,而修改后的查询与修改前的查询之间有密切的联系,所以是满足一阶马尔可夫性质。
已知用户查询时的转移概率和观察概率,通过多属性效用理论对用户的查询进行风险等级划分,本文将用户的查询风险一共划分为5个等级。等级越高则查询风险越高,在隐私保护时需要增加隐私保护强度;查询风险等级越低,则用户查询内容中涉及的用户隐私较少,因此,在隐私保护时无需采用高强度的隐私保护方法。本文的查询风险等级划分符合“GB/T 33132-2016信息安全技術、信息安全风险处理实施指南”和“GB/T 31722-2015信息技术、安全技术、信息安全风险管理”的需求[20]。在本文研究中设定的查询风险等级见表1。
表1中不同的风险等级所代表的隐私风险高低是不同的。当用户查询中没有包含新的查询时,HMM模型会根据用户历史查询对用户进行风险评估。一旦出现新的查询时,首先会进行模型训练,然后对用户查询进行评估。且本文中的风险评估是动态的,会随着时间的推移和用户的查询数据的积累,HMM模型对用户查询隐私风险评估也在动态地变动与调整。
3 实验分析与评估
本文的实验分析环境为Intel(R) Core(TM) i5-3337U CPU @ 1.80 GHz, RAM为8 G,系统类型为Windows10,所有的算法和仿真实验均通过python而得到设计完成。
3.1 数据预处理
研究采用的实验数据为2006年AOL公布了3个月的用户真实查询日志,提供了超过65万用户的2 000万个用户搜索查询。每一条AOL查询日志数据由5部分组成,分别是:用户ID、查询字符串、查询时间、查询内容的排名以及查询内容的URL。实验数据集明细详见表2。
在实验评估前,首先对AOL数据集进行预处理,对无效查询、空查询等施以过滤处理。然后将清洗后的数据集按80%,20%比例进行划分,其中80%用于模型训练,20%用于结果测试。此外,为了提高模型训练效率,采用了k均值聚类方法将训练数据分割成k个聚类,使用并行处理技术同时训练k个数据集,这样极大地提高了数据训练效率。
在高风险查询评估中,本文设定癌症、怀孕和酒精三个主题作为高风险查询主题。为了提取包含以上3个主题的查询,使用了自然语言处理包NLTK[21]和Gensim[22]进行主题建模和提取相关查询主题,对每个高风险主题识别一些同义单词。本文使用了WordStream提供的免费关键字工具,该工具利用最新的Google关键字API寻获了数百个相关的关键字结果[23]。然后对这些关键词进行主题建模,得到与主题相关的关键词。如对“癌症”敏感主题、应用主题建模后可得相关度高的单词为肿瘤、乳腺癌、甲状腺、白血病、胰腺等。
3.2 实验评估
3.2.1 查询风险分析
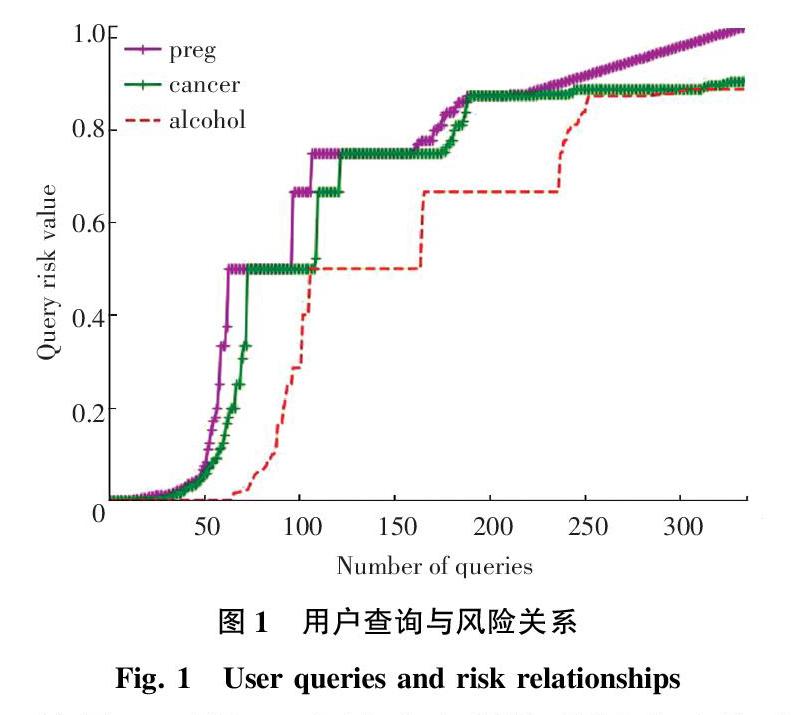
在数据预处理部分,本文从AOL数据中提取了“癌症、怀孕和酒精”作为高风险查询内容进行研究。如图1所示。图1中,preg表示用户查询中包含“怀孕”的信息,随着查询次数的增多,其隐私风险也在增加。cancer表示用户查询中包含“癌症”的信息,而且随着用户查询次数的增多,其隐私风险也在增加。同理,alcohol也是如此。
从图1可得,3个敏感主题均是随着查询次数的增多,查询隐私风险在逐步上升。结合表1中等级划分,当用户查询超过50次左右时,用户的查询风险等级为2级,表明实验结果符合风险等级的设定。
3.2.2 时间开销
时间开销主要是指当用户进行查询时,对用户的查询进行风险评估所花费的时间开销。
如图2所示,用户查询中80%的查询时间开销低于0.5 s,可得本文的评估时间在用户实际查询场景中是允许的。但在用户最初的查询中,查询时间偏高,其主要原因是刚开始需要模型训练,因此初始查询时间花费较多,随着用户查询次数的增多,用户的查询时间也会随之稳定、且时间逐渐变小。但是仍有一些查询时间高于0.5 s,当用户查询中出现新的查询时,HMM模型需要对数据重新训练,故而所需时间要长于一般查询时间,但整体查询时间是可以接受的。
最后,研究得到不同用户查询风险变化趋势如图3所示。随着有效查询时间的增长,不同用户每次查询隐私风险不同。这是由于用户的查询内容不同,所包含的隐私信息是不同的,因此,用户查询风险也在动态变化。
4 結束语
用户查询风险评估对用户查询隐私保护起到非常重要的作用。本文提出了一种可以动态评估用户查询隐私风险的方法,对区分内容隐私风险高低具有良好的借鉴价值。最后从时间开销、风险大小和动态评估效果三个方面进行了仿真实验验证,实验结果表明,本文方案是高效、且可行的。未来研究将对该评估方法与隐私保护算法相结合,提出一种基于动态评估用户查询风险的隐私保护方案,为用户查询隐私保护提供一种有益的解决思路和方法。
参考文献
[1]CHAIRUNNANDA P , PHAM N , HENGARTNER U . Privacy: Gone with the typing! Identifying Web users by their typing patterns[C]// 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust (PASSAT) and 2011 IEEE Third International Confernece on Social Computing (SocialCom). Boston, MA, USA: IEEE, 2011:974-980.
[2] HANSELL S. AOL removes search data on vast group of Web users[N]. The New York Times,2006-08-08( C4).
[3] SU J , SHUKLA A , GOEL S, et al. De-anonymizing Web browsing data with social networks[C]// Proceedings of the 26th International Conference on World Wide Web.Perth, Australia: ACM, 2017:1261-1269.
[4] TOCH E, WANG Yang, CRANOR L F. Personalization and privacy: A survey of privacy risks and remedies in personalization-based systems[J]. User Modeling and User-Adapted Interaction, 2012,22(1-2):203-220.
[5] ROGER D. Tor and circumvention: Lessons learned[C]//Advances in Cryptology-CRYPTO 2011. Berlin/Heidelberg:Springer,2011: 485-486.
[6] TEJA S, SAXENA N. On the effectiveness of anonymizing networks for Web search privacy[C]//Proceedings of the 6th ACM Symposium on Information, Computer and Communications Security, ASIACCS 2011. Hong Kong, China:ACM, 2011:483-489.
[7] AHMAD W U, CHANG Kaiwei, WANG Hongning. Intent-aware query obfuscation for privacy protection in personalized Web search[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. Ann Arbor, MI, USA:ACM, 2018:285-294.
[8] AHMAD W U , RAHMAN M M , WANG Hongning. Topic model based privacy protection in personalized Web search[C]// Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval. Pisa,Italy:ACM, 2016:1025-1028.
[9] PEDDINTI S T, SAXENA N. On the privacy of Web search based on query obfuscation: A case study of trackmenot[M]//ATALLAH M J, HOPPER N J. Privacy Enhancing Technologies. PETS 2010. Lecture Notes in Computer Science. Berlin/Heidelberg:Springer,2010,6205: 19-37.
[10]GERVAIS A, SHOKRI R, SINGLA A, et al. Quantifying Web-search privacy[C]// Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security (CCS '14). Scottsdale, Arizona, USA:ACM, 2014: 966-977.
[11]CASTELL-ROCA J, VIEJO A, HERRERA-JOANCOMART J. Preserving users privacy in Web search engines[J]. Computer Communications, 2009,32 (13-14): 1541-1551.
[12]DOMINGO-FERRER J , BRAS-AMORS M, WU Qianhong, et al. User-private information retrieval based on a peer-to-peer community[J]. Data & Knowledge Engineering, 2009, 68(11):1237-1252.
[13]BALSA E, TRONCOSO C, DIAZ C. OB-PWS: Obfuscation-based private Web search[C]//2012 IEEE Symposium on Security and Privacy (SP). San Francisco, CA, USA:IEEE,2012: 491-505.
[14]HOWE D C, NISSENBAUM H. TrackMeNot: Resisting surveillance in Web search[C]//Lessons from the Identity Trail: Anonymity, Privacy, and Identity in a Networked Society. Oxford: Oxford University Press, 2009: 417-436.
[15]ARAMPATZIS A , DROSATOS G , EFRAIMIDIS P. Versatile query scrambling for private Web search[J]. Information Retrieval, 2015, 18(4):331-358.
[16] SNCHEZ D, CASTELL-ROCA J, VIEJ O A. Knowledge-based scheme to create privacy-preserving but semantically-related queries for Web search engines[J]. Information Sciences, 2013, 218: 17-30.
[17]PANG H H, DING Xuhua, XIAO Xiaokui. Embellishing text search queries to protect user privacy[J]. Proceedings of the VLDB Endowment ,2010,3(1):598-607.
[18]CHOW R, GOLLE P. Faking contextual data for fun, profit, and privacy[C]// Proceedings of the 2009 ACM Workshop on Privacy in the Electronic Society, WPES 2009. Chicago, Illinois, USA:ACM, 2009: 105-108.
[19]RABINER L, JUANG B. An introduction to hidden Markov models[J]. IEEE ASSP Magazine, 1986,3(1):4-16.
[20]國家市场监督管理总局国家标准技术审评中心 . 全国标准信息公共服务平台[EB/OL].http://www.std.gov.cn/gb/gbQuery.
[21]NLTK project. NLTK 3.4 documentation [EB/OL]. [2018-11-17].http://www.nltk.org/.
[22]gensim[EB/OL]. [2019-01-31]. https://radimrehurek.com/gensim/.
[23]Bryant B D, Miikkulainen R. From word stream to gestalt: A direct semantic parse for complex sentences [R]. Austin, TX: University of Texas, 2001.
