零膨胀模型在散装熟肉制品中单核细胞增生李斯特氏菌定量暴露评估中的应用
2019-07-01孙菀霞金玉琴戴颖秀肖建伟董庆利
孙菀霞,金玉琴,戴颖秀,肖建伟,王 翔,董庆利,*
(1.上海理工大学医疗器械与食品学院,上海 200093;2.上海市杨浦区疾病预防控制中心,上海 200090)
单核细胞增生李斯特氏菌(Listeria monocytogenes,以下简称单增李斯特菌)是一种能够引起人畜共患病的致病菌,广泛分布于自然界,如土壤、污水、人和动物粪便以及多种食品中。由单增李斯特菌导致的李斯特菌病通常发病率低但后果严重,该菌可穿透肠道、血脑和胎盘三大屏障,引起人类腹泻、脑膜炎、败血症等疾病[1-2],人类一旦感染死亡率高达20%~30%[3-4]。易感人群主要包括老年人、免疫功能缺陷者、孕妇及新生儿[5]。已有资料表明,单增李斯特菌的发病与即食食品有较大关系[6]。我国污染物监测网2010—2013年的资料[7-9]显示,我国的即食凉拌菜、熟肉制品、生食水产品和豆制品均受到单增李斯特菌不同程度的污染,在对上述各类即食食品中单增李斯特菌的暴露情况进行初步风险分级和比较之后,散装熟肉制品被认为可能是导致我国居民发生食源性李斯特菌病的主要食品类别之一。因此,对散装熟肉制品中单增李斯特菌进行定量风险评估对减少食源性李斯特菌病的发生、保障消费者健康以及减轻国家经济负担具有一定意义。
1999年食品法典委员会制定的《微生物风险评估原则和指导方针》将微生物定量风险评估分为危害识别、危害特征描述、暴露评估和风险特征描述4 个步骤[10]。暴露评估作为风险评估的核心内容,其主要作用是在统计分布的基础上对某个个体或群体暴露于致病菌的可能性及摄入的菌量进行估计[11-12]。进行暴露评估时,常用泊松分布描述菌落计数过程中的随机性,用对数正态分布描述致病菌的浓度[13-14]。当同时考虑计数随机性和污染水平变异性时,采用负二项分布或泊松对数正态分布进行描述[15-16]。在实际检测中,受检测方法所限,无法完全定量样品中已存在的微量致病菌,当致病菌的含量小于定量检测限(limit of quantification,LOQ)时就会产生左删失数据[17]。此类数据实际上是由“阴性样本”(真零值)和“假阴性样本”(非零值)两个部分共同构成,并通常均以“<LOQ”的形式表达。目前,在微生物定量暴露评估中,针对左删失数据的常用处理方法是将缺失的数据以某种特定分布的形式代替[18-20]。然而,对于散装熟肉制品中的单增李斯特菌而言,监测结果中的左删失数据通常占据较大比例,并且包含大量的真零值,数据呈现出零膨胀现象[21],超出了传统模型所能估计的范畴,造成实际数据与既定的传统模型之间可能存在较大偏离,导致暴露评估结果不准确。另外,在单增李斯特菌的监测结果中除了零膨胀现象外,还常常出现过度离散的现象。若忽视这一现象也将导致不准确的暴露评估结果。
因此,本研究以上海市某区散装熟肉制品中单增李斯特菌的定量检测结果为例,探究不同概率分布的选择对暴露评估结果的影响,以期提供较为理想的左删失数据处理方法,提高风险评估结果的准确性,同时为风险管理提供可靠的理论依据。
1 材料与方法
1.1 散装熟肉制品中单增李斯特菌的定量检测
2017年2—12月从上海市某区各大超市、农贸市场以及餐饮环节随机采集散装熟肉制品共254 份,每份样品250 g(表1)。根据GB 4789.30—2016《食品安全国家标准 食品微生物学检验 单核细胞增生李斯特氏菌检验》进行单增李斯特菌定量检测,并参照单增李斯特菌最可能数(most probable number,MPN)检索表获得单增李斯特菌浓度[22]。采集的样品均置于干冰贮存箱内转运至实验室进行检测,检测结果可近似认为是零售阶段散装熟肉制品中单增李斯特菌的污染水平。

表1 2017年上海市某区不同时间散装熟肉制品的采样地点、采样量及单增李斯特菌定量检测结果Table 1 Sampling locations, number of samples and number of samples positive for L. monocytogenes in bulk cooked meat products in a certain district of Shanghai in 2017
1.2 模型构建
根据254 份样品中单增李斯特菌的定量检测结果,分别选用泊松分布、负二项分布、对数正态分布、泊松对数正态分布及其零膨胀形式进行拟合,从而定量描述零售阶段散装熟肉制品中单增李斯特菌的污染水平。
1.2.1 标准统计分布
1.2.1.1 泊松分布
假设254 份散装熟肉制品中单增李斯特菌的数量服从泊松分布(平均值等于方差),则其概率质量函数如式(1)[23]所示。

式中:Yi表示散装熟肉制品中单增李斯特菌的定量检测结果;λ表示样本数据的平均值;Pr(Yi)为单增李斯特菌的概率质量。
1.2.1.2 负二项分布
当单增李斯特菌的检测结果出现过度离散现象时,常用负二项分布取代泊松分布进行描述,其概率质量函数如式(2)[23]所示。

式中:α表示离散参数;Yi表示单增李斯特菌的定量检测结果;Γ表示伽马函数,即Γ(α)=∫∞0e-ttα-1dt;Pr(Yi)为单增李斯特菌的概率质量。
1.2.1.3 对数正态分布
对数正态分布作为一种连续型分布,可以对单增李斯特菌的浓度结果进行描述。当零膨胀数据过多时,该分布的估计值与实际值之间可能有较大偏离,其概率密度如式(3)所示。

式中:Yi表示单增李斯特菌的污染浓度;μ和σ分别为定量检测结果的对数平均值和对数方差;Pr(Yi)为单增李斯特菌的概率密度。
1.2.1.4 泊松对数正态分布
统计学上,针对过度离散现象常用的处理方法是进行对数转换。本研究选择泊松对数正态分布描述不同样本之间单增李斯特菌数量的变异性和不确定性,其概率质量函数如式(4)所示。

式中:Yi表示单增李斯特菌定量检测结果的对数值;λ服从对数正态分布,即λ~Lognormal(μ,σ);Pr(Yi)为单增李斯特菌的概率质量。
1.2.2 零膨胀统计分布
零膨胀分布中小于LOQ的数值来源于两种不同的过程:一种是由于样本未被污染而表现出的真零值,其真零值的待估计概率用p0表示;另一种是由于检测方法所限导致未检出的数值。
1.2.2.1 零膨胀泊松分布
若散装熟肉制品中单增李斯特菌的定量检测结果出现零膨胀现象,且阳性数据服从泊松分布,则可采用零膨胀泊松分布进行描述,具体如式(5)所示。
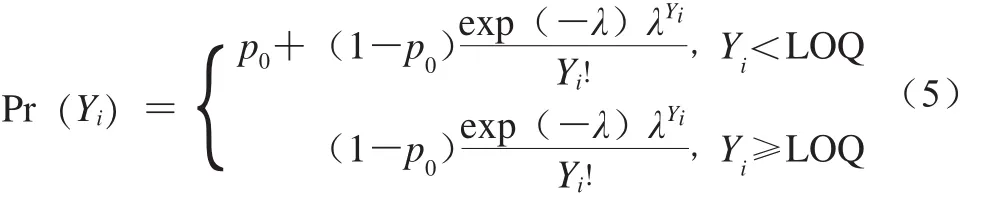
式中:p0为“零膨胀参数”,表示真零值的概率;Yi表示单增李斯特菌的定量检测结果;λ表示样本数据的平均值;Pr(Yi)为单增李斯特菌的概率质量。
1.2.2.2 零膨胀负二项分布
若单增李斯特菌的阳性检测结果出现偏大离差(方差大于期望),则需要将零膨胀泊松分布扩展到零膨胀负二项分布,其概率质量函数如式(6)所示。
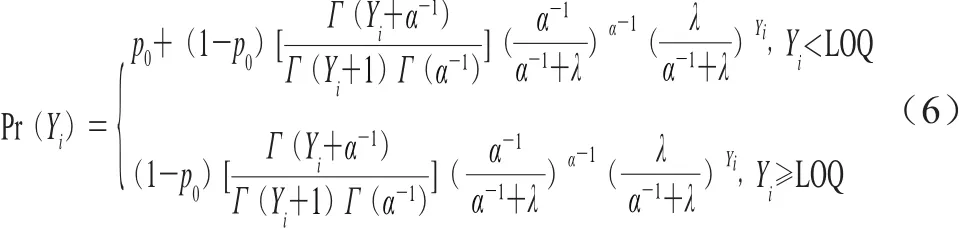
式中:p0为阴性样本的待估计概率;α表示离散参数;Yi表示单增李斯特菌的定量检测结果;Pr(Yi)为单增李斯特菌的概率质量。
1.2.2.3 零膨胀对数正态分布
零膨胀对数正态分布概率密度函数如式(7)所示。
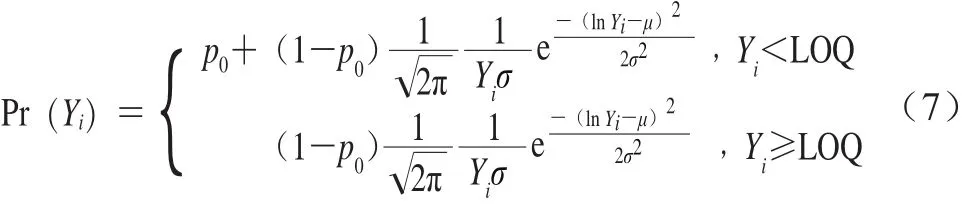
式中:p0为阴性样本所占的比例;Yi表示单增李斯特菌的污染浓度;μ和σ分别为定量检测结果的对数平均值和对数方差;Pr(Yi)为单增李斯特菌的概率密度。
1.2.2.4 零膨胀泊松对数正态分布
为尽可能缩小样本检测结果的离散程度,本研究选择采用泊松对数正态分布描述阳性样本间的变异性和不确定性,其零膨胀形式的概率质量函数如式(8)所示。
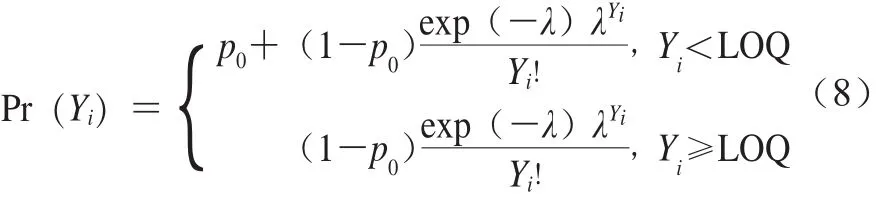
式中:p0为阴性样本的检出率;Yi表示单增李斯特菌的定量检测结果的对数值;λ服从对数正态分布;Pr(Yi)为单增李斯特菌的概率质量。
1.3 参数估计
标准统计分布与零膨胀分布的参数估计均可采用最大似然估计的方法。在进行参数估计时,泊松分布与泊松对数正态分布的差异在于是否进行模型参数λ的对数转换,即λ的数值不同,因此本研究只给出泊松分布和零膨胀泊松分布似然函数的显式。本节模型中模型参数的意义与1.2节相同。泊松分布、负二项分布、对数正态分布及其零膨胀模型的对数似然函数分别如式(9)~(14)所示。
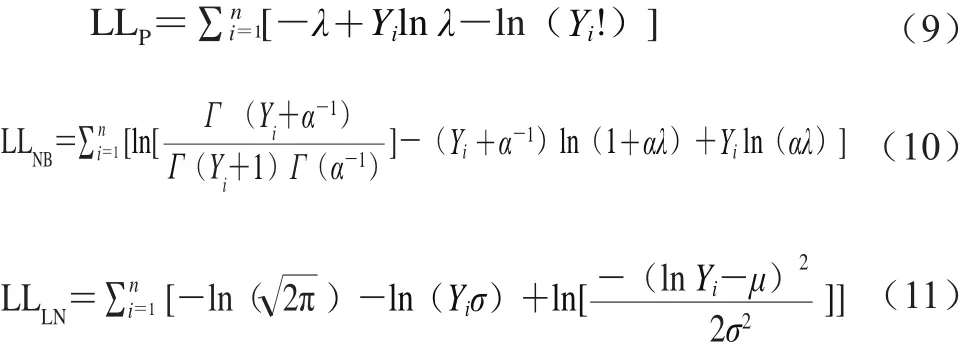
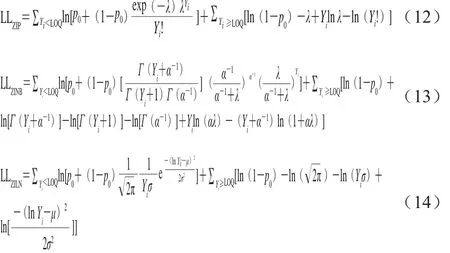
式中:LLP、LLNB和LLLN分别为泊松分布、负二项分布和对数正态分布的对数似然函数;LLZIP、LLZINB和LLZILN别为零膨胀泊松分布、零膨胀负二项分布和零膨胀对数正态分布的对数似然函数。
1.4 模型选择
在不考虑模型间关系的前提下,通过信息准则指标进行模型的选择与比较。本研究选用被广泛用于判断模型优劣的赤池信息准则(Akaike information criterion,AIC)、贝叶斯信息准则(Bayesian information criterion,BIC)[24]。通过对每个模型计算AIC、BIC值并比较其大小,从而完成对模型的选择。模型评价参数公式如式(15)、(16)[25]所示。

式中:LL表示模型对数似然函数的最大值;k1和k2分别为模型种参数的个数;n为样本量。AIC和BIC值遵循取值越小模型越优的原则。
X2统计量是对于数据的分布与预期(或假设)分布之间差异的度量,因此,利用卡方统计量比较各个模型的优劣,如公式(17)[25]所示。

式中:k为总体被分成数据段的个数;Ni为第i个数据段中观测的样本数;Ei为第i个数据段中期望的样本数。
2 结果与分析
2.1 散装熟肉制品中单增李斯特菌的定量检测结果
采集254 份散装熟肉制品进行单增李斯特菌定量检测,阳性样品的检出时间及检出地点如表1所示。40 份大型超市散装熟肉样品中均未出现单增李斯特菌阳性检测结果。农贸市场和餐饮环节共检出4 份阳性样品。总体阳性检出率为1.57%,由此可见,小于LOQ的样本量占据较大比例,出现了零膨胀现象。
由表2可知,4 份阳性样品中单增李斯特菌浓度的最小值和最大值分别为3.6 MPN/g和75.0 MPN/g,平均值为22.85 MPN/g,方差为1 215.69,单增李斯特菌阳性检出结果出现偏大离差现象。

表2 2017年上海市某区散装熟肉制品中单增李斯特菌抽样调查的阳性检测结果Table 2 Quantification of L. monocytogenes in bulk cooked meat samples in a certain district of Shanghai in 2017
2.2 零售阶段散装熟肉制品中单增李斯特菌的污染水平
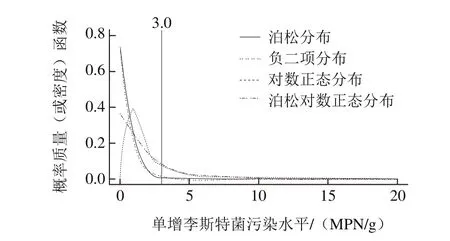
图1 泊松分布、负二项分布、对数正态分布和泊松对数正态分布拟合单增李斯特菌定量检测数据的概率质量(或密度)Fig. 1 Predictive distribution of the L. monocytogenes contamination level as modeled by the Poisson, Negative Binomial, Lognormal and Poisson Lognormal models
如图1所示,与对数正态分布和泊松对数正态分布相比,泊松分布和负二项分布有较高的预测零值。进行了对数转换的标准统计分布所估计的阳性样本污染浓度较高,且阳性率的估计值也高于泊松分布和负二项分布。
对单增李斯特菌污染水平进行拟合时,由于对数正态分布在零处无意义,因此,与其他标准统计分布估计的零值概率产生较大差异。由此可见,标准对数正态分布不适于估计低菌量条件下的污染水平。Gonzales-Barron等[26]利用对数转换方法对牛胴体表面的大肠杆菌进行浓度估计时也得到相似的结论。

图2 零膨胀模型拟合单增李斯特菌浓度的累积概率Fig. 2 Cumulative probability of L. monocytogenes MPN results as fitted by zero-inflated distribution
图2描述了4 种零膨胀模型的累积概率,结果表明零膨胀模型比标准统计分布有更高的预测零值。零膨胀对数正态分布克服了其标准形式的不足,与带有层次结构的零膨胀泊松对数正态分布得到的拟合结果相似。相比于零膨胀对数正态分布和零膨胀泊松对数正态分布,零膨胀负二项分布在一定程度上低估了单增李斯特菌的污染水平。
零膨胀泊松分布与其他零膨胀模型的累积概率产生较大差异,主要是因为该组数据的阳性检测结果有偏大离差现象,而泊松分布只适用于拟合平均值等于方差的数据[27]。根据模型拟合结果可以推断,4 种零膨胀模型均可以对左删失数据的零膨胀现象进行准确的估计。
2.3 模型参数与模型比较
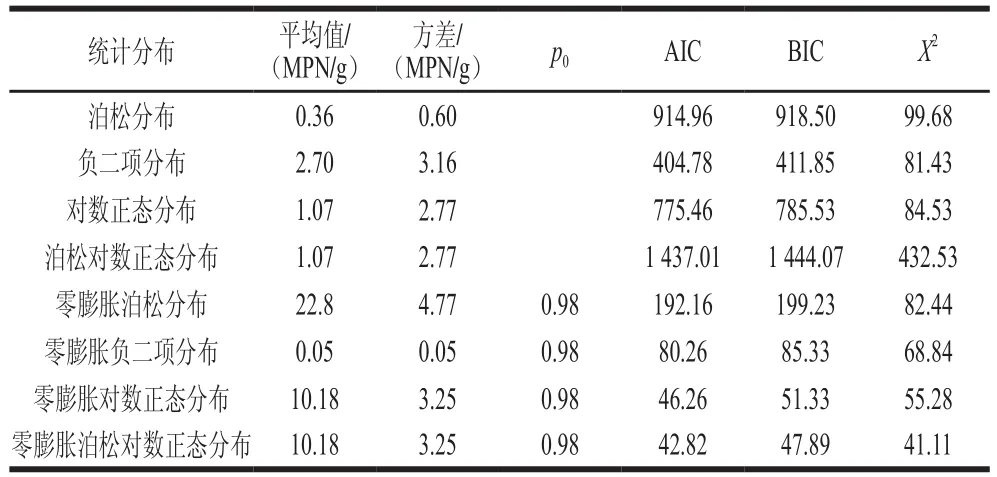
表3 基于散装熟肉制品中单增李斯特菌定量检测数据的参数估计Table 3 Model parameter estimates based on quantitative detection of L. monocytogenes in bulk cooked meat products
泊松分布、负二项分布、对数正态分布、泊松对数正态分布及其零膨胀模型的参数估计及拟合效果见表3。零膨胀参数p0显著不为零,这进一步说明散装熟肉制品中单增李斯特菌呈现零膨胀现象,同时也表明标准统计分布均不适合描述该组数据。另外,由模型评价结果可知,零膨胀泊松对数正态分布比其他零膨胀模型更适合拟合该组数据,说明单增李斯特菌的阳性污染水平出现偏大离差。
参照GB 29921—2013《食品安全国家标准 食品中致病菌限量》[28]规定的预包装熟肉制品中单增李斯特菌限量标准,同时出于保护消费者健康的角度考虑,本研究将散装熟肉制品中单增李斯特菌的风险阈值设定为不得检出(每份样品25 g)。由表3可以看出,零膨胀模型所估计的总体阳性检出率均为2%,这与实际监测的阳性率(1.57%)接近。
3 讨 论
本研究基于散装熟肉制品中单增李斯特菌的定量检测结果构建零膨胀模型,并与传统模型进行比较,将拟合结果应用于单增李斯特菌的暴露评估中,为食源性致病菌检测数据中出现的零膨胀和过度离散现象提供方法学支持。
研究发现,尽管泊松分布常作为描述食源性致病菌污染水平的假设统计分布之一,但是它对数据有着严格的要求[29-30],因此并不能较好地处理检测结果之间的变异性。一般来说,当单增李斯特菌的检测结果出现由较大变异性所导致的过度离散现象时,通常可以采用负二项分布和对数正态分布分别对菌落计数和污染浓度进行拟合[31]。然而,当数据中存在由零膨胀现象导致的过度离散现象时,则需要采用能够准确描述阳性样本变异性的零膨胀模型进行拟合。此时若依然选择标准统计分布进行单增李斯特菌的定量暴露评估,不但会低估真实零值的概率,而且对于阳性样本污染浓度较高的情况也无法作出准确估计。
通过分析不同模型对散装熟肉制品中单增李斯特菌暴露水平的描述情况,可以看出:1)零膨胀模型处理左删失数据的能力明显优于标准统计分布;2)零膨胀模型可以同时估计阳性率和阳性样本的污染水平;3)零膨胀模型污染浓度的参数估计值受LOQ影响小。因此,在进行暴露评估时,建议优先选择零膨胀模型。另外,本研究无法区分零膨胀对数正态分布与零膨胀泊松对数正态分布的优劣。本研究中的拟合优度指标虽然显示零膨胀泊松对数正态分布优于零膨胀对数正态分布,但是二者之间的差距不大。因此,在进行模型选择时需更注重数据类型(离散变量或连续变量)及数据结构(零值的比例及来源)。
