密度矩阵重正化群的异构并行优化*
2019-06-29陈富州程晨罗洪刚
陈富州 程晨 2) 罗洪刚 2)†
1)(兰州大学物理科学与技术学院,兰州 730000)
2)(北京计算科学研究中心,北京 100084)
1 引 言
密度矩阵重正化群方法(DMRG)[1,2]是研究相互作用量子系统最重要的多体数值方法之一.众所周知,多体量子系统的复杂度随着系统尺寸指数增长,给数值计算带来了极大的困难.而DMRG给出了一种非常有效的截断希尔伯特空间的方法,保留有限个状态并通过扫描即可得到变分收敛的基态或低激发性质.应用于自旋1的海森伯链时,该方法仅保留数百状态并通过数次扫描即可得到相对误差 1 0-9左右的基态能量,而所需的计算量仅随格点尺寸线性增长[3,4].作为求解一维格点模型基态的成熟方法,DMRG也不断被应用于其他各类问题并取得了一定的成功,如动量空间中的哈密顿量[5]与量子化学问题[6-8]、量子系统的时间演化问题[9-11]、准二维以及二维量子格点模型[12-14]等.这些尝试极大扩展了DMRG的应用,但同时也对该数值算法的优化提出了更高的要求.以二维相互作用电子系统为例,该系统包含非常丰富的物理,例如高温超导条纹相[15-17]、量子自旋液体[18,19]等.然而,在面对二维或者准二维格点模型时,DMRG所需的保留状态数大致随格点宽度指数增长,得到收敛结果所需的扫描次数也大大增加.此时,DMRG所需的计算量和存储量较大,使用各种方法优化算法显得十分必要.
在实际应用中,对DMRG算法的优化与加速主要体现在两个方面.一方面,人们不断改进DMRG算法本身以减少计算量,包括使用各种好量子数对角化小的希尔伯特子空间[20,21],使用动态保留状态数节约计算资源[22,23],使用好的初始预测波函数减少对角化方法迭代次数[24],使用单格点DMRG方法减少计算量与内存[25,26]等.另一方面,人们结合DMRG算法的特性,发挥高性能计算机的并行计算能力进一步缩短计算时间,包括实空间并行[27]、共享存储的多核行[28]、分布式存储的多节点行[29]以及CPU-GPU异构并行[30]等.
相比CPU,GPU具有较高的浮点计算能力以及较大的存储带宽,因此在通用计算中得到了大量的应用.当前很多求解强关联格点模型的数值方法(比如:精确对角化方法[31]、量子蒙特卡罗方法[32]以及张量乘积态方法[33]等)都实现了基于GPU的并行优化.在CPU-GPU异构并行环境中,异构并行算法可以同时发挥CPU和GPU的计算性能,并且可以实现内存和GPU显存的分布式存储,在一定程度上减小了GPU显存容量对计算规模的限制.最近,Nemes 等[30]提出了DMRG方法的一种CPU-GPU异构并行实现,并将其应用到一维格点模型的基态能量计算.在保留状态较多时,最耗时的哈密顿量对角化部分在GPU中获得了接近峰值的运算性能.在对角化过程中,对占用存储空间较多的Davidson方法实现了内存和GPU显存的分布式存储,减小了GPU显存的容量限制.然而与此同时,Davidson方法在计算中内存和GPU显存之间需要通信向量数据,其性能会受到通信带宽的限制.另一方面,该方案中哈密顿量和波函数基于两子块表示,其子块算符需要的存储量大致相当于目前流行的四子块表示的d2倍(d为单格点希尔伯特空间维数),在实际应用中存在很大的局限性.
在前人工作的基础上,本文提出了一种新的CPU-GPU异构并行优化算法,并使用四子块表示的DMRG超块与波函数.为了说明该方法的有效性,将其应用到准二维模型的求解,获得了不同保留状态数下的基态能量及其性能基准.在Hubbard梯子模型的例子中,得到了非均匀的电荷密度分布,与高温超导铜氧面中观测到的条纹相定性一致.我们希望CPU-GPU异构并行算法能进一步推进DMRG在求解二维与准二维模型、时间演化、量子化学等问题中的应用,同时引起强关联领域对GPU算法的关注和重视.
本文的内容包括以下几部分:第2节回顾了有限DMRG算法,基于四个子块表示的DMRG实现,介绍了该工作采用的基准模型,并得到了在CPU执行时各个部分的计算时间占总时间的比例;第3节针对DMRG中最耗时的哈密顿量对角化部分给出了异构并行优化方法;第4节以计算4腿Hubbard模型基态为例,对比了异构并行优化方法与单个CPU中MKL并行的性能;最后给出本文的总结.
2 有限DMRG方法和基准模型
有限尺寸格点模型的DMRG计算分为两部分:首先执行无限DMRG方法,这可为后面的计算提供较好的初始波函数;然后执行有限DMRG扫描,其中每一步有限DMRG扫描会优化系统块的状态,直到收敛至基态.在准二维梯子模型的计算中,有限DMRG部分需要多次扫描,且保留很多的状态才能收敛,几乎占用整个DMRG计算的全部时间,因此本文主要考虑该部分的并行优化.有限DMRG计算中向左扫描和向右扫描非常相似,本文以向右扫描为例介绍有限DMRG方法.每一步优化的过程中整个格点系统由四个部分构成 (图 1):S,s1,e1 和E,其中S和s1 构成系统块,E和e1 构成环境块,系统块和环境块构成超块.基于四个子块,波函数有如下形式:
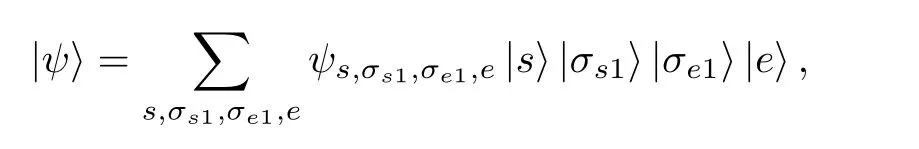
其中|s〉,|e〉,|σs1〉和|σe1〉分 别为子块S,E,s1 和e1上的状态.同样,基于四个子块,一般形式的哈密顿量H可以表示为
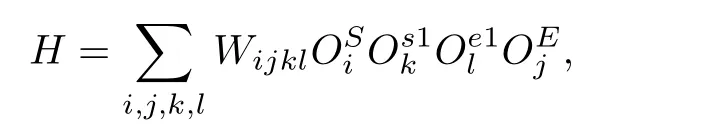
其中OS,OE,Os1和Oe1分别为子块S,E,s1 和e1上的算符.以求解系统的基态为例,给出基于四子块表示的DMRG一步优化过程,如算法1所示.重复执行DMRG的一步优化过程,进行多次实空间扫描,即可得到收敛的结果.在算法1中,对角化超块哈密顿量最为耗时,通常人们采用稀疏矩阵对角化方法(Lanczos方法、Davidson方法等).此时,不需要超块哈密顿量的矩阵表示,仅需要算符在四个子块中的矩阵表示,并迭代执行|φ〉=H|ψ〉,文献[4]中给出了该操作的高效算法,具体过程如算法2.在后面的描述中,我们称算法2中第2,5和8行对应的循环分别为step1,step2和step3.可以看到该算法(st)ep1和step3中为矩阵乘法,对应的计算量为OD3,其中D为DMRG保留状态(数.)step2中仅包含向量操作,对应的计算量为OD2.在保留状态较多时,哈密顿量作用在波函数的计算量主要由step1和step3决定.而对角化哈密顿量的总时间线性依赖于对角化方法的迭代次数,本文实现的有限DMRG中通过上一步优化波函数给出一个较好的初始迭代波函数,可以有效地加快对角化方法的收敛[24].
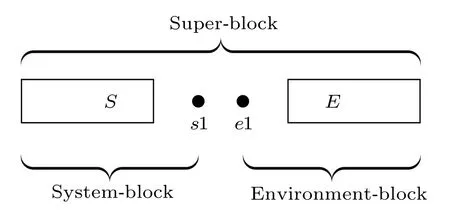
图1 超块中的四个子块Fig.1.4 Sub-blocks of super-block.

?

?
为了获得异构并行优化方法的性能基准,选取4腿梯子上的Hubbard模型为例子,并利用DMRG求解其基态.具体地,系统哈密顿量为

这里t为两个格点之间的电子跃迁能,U为单个格点上的电子在位库仑排斥能,为格点i上自旋σ的费米子产生(湮灭)算符,为自旋σ的粒子数算符,其中σ∈{↑,↓}.在梯子模型中,格点i包含x,y两个方向的分量,以x标记梯子长边坐标,y标记梯子短边坐标.在后面的测试计算中,选取t=1 为能量单位,沿着长边和短边方向分别使用开边界和周期边界条件,梯子长度为16.对于其他参数,取相互作用U=8,总电荷密度0.875,即 1 /8 空穴掺杂,这是在其他数值工作中观测到条纹相的典型参数[13,34].另外本文的实现利用了该模型的总粒子数和总自旋在z方向投影两个好量子数,每个子块的希尔伯特空间可以被划分为多个子空间,每个子空间中的状态对应于相同的量子数.此时模型(1)中算符的矩阵表示为分块矩阵,相应地,超块的希尔伯特空间可以用其四个子块的好量子数划分为多个子空间.
模型(1)哈密顿量的矩阵表示为实对称矩阵,本文使用Davidson方法[35,36]对角化该哈密顿量.Davidson方法是一种使用预条件技术的子空间迭代方法,算法3给出了该方法每一步迭代的具体操作.可以看到,每一步迭代都需要作用哈密顿量到波函数,并且包含多个向量操作.其中向量操作的计算量和存储量均线性依赖于Davidson方法子空间中向量的个数和向量的维数.在性能测试中,使用7次有限DMRG扫描收敛到基态,Davidson方法子空间中向量个数最大为11.

?
本文所有计算使用的异构并行环境包含1个CPU (Intel Xeon E5-2650 v3,10核,主频2.3 GHz)和Nvidia Tesla K80卡中的1个GPU (含12 GB显存).程序的实现基于CUDA环境,CPU和GPU中的矩阵向量操作分别调用了Intel MKL和CUBLAS中的子程序.为了描述矩阵操作的性能,估计了单位时间内处理器执行的浮点操作的次数,其中总的浮点操作次数在保留状态数较大时可以由所有矩阵乘法中浮点操作次数之和近似.为获取异构并行的优化表现,需要给出CPU上的并行性能作为基准.哈密顿量对角化中包含大量矩阵乘法,这里首先测试了随机方阵乘法的性能,结果见图2(a).可以看出,当矩阵尺寸较大(大于400)时,矩阵乘法的性能较高,并随着矩阵尺寸增大而增大.对于DMRG算法,图2(b)中的结果表明,保留状态数越大并行计算性能越高,并逐渐接近峰值性能.另外也测试了对角化哈密顿量以及哈密顿量作用于波函数部分占总计算时间的比例,如图3 所示.在我们所关心的保留状态数范围内,对角化哈密顿量的耗时比例超过总计算时间的90%,其中作用哈密顿量到波函数占总时间比例超过80%.因此,我们的工作主要针对该部分进行异构并行优化.
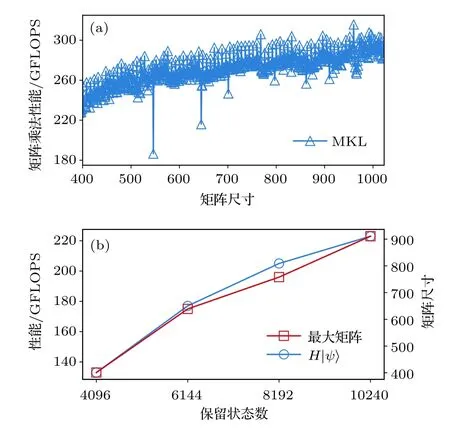
图2 CPU中作用哈密顿量在波函数上的性能 (a)矩阵乘法的浮点性能;(b)作用哈密顿量于波函数的性能,及矩阵乘法中的最大矩阵尺寸Fig.2.Performance of acting the Hamiltonian on the wave function in CPU:(a)The matrix multiplication performance;(b)the performance of acting the Hamiltonian on the wave function,and the maximum matrix size of the matrix multiplications.
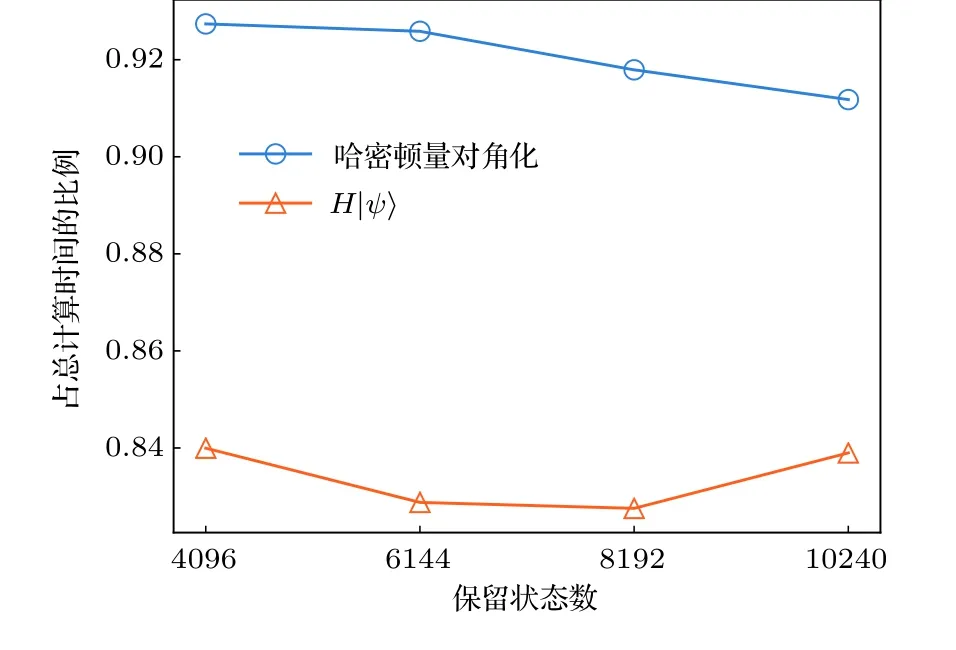
图3 对角化哈密顿量和作用哈密顿量到波函数操作占总计算时间的比例Fig.3.Time ratio of diagonalization of the Hamiltonian and acting the Hamiltonian on the wave function to the total time cost.
3 DMRG的异构并行实现
主要考虑DMRG方法在准二维模型中的应用,并且针对有限DMRG中计算量较大的哈密顿量对角化部分进行并行优化.对于准二维问题,DMRG方法达到较高精度通常需要保留较多的状态,相应地,对角化哈密顿量时会执行一些大尺寸矩阵操作.类似于CPU,矩阵乘法的性能在GPU中随着矩阵尺寸增大而增大;同时,GPU的浮点运算能力一般远大于单个CPU.因此,在异构并行优化中,我们倾向于尽可能在GPU中执行大尺寸的矩阵操作.从存储方面考虑,为了避免GPU显存和内存之间频繁的数据通信,多次参与GPU计算的数据需要存储在GPU显存中,主要包括Davidson方法中的向量、算符数据和临时数据(算法2中但同时,保留较多的状态也导致计算中需要的存储容量较大;考虑到当前GPU显存容量较小,在异构并行方法中需要合理分配各个部分的存储利用.
首先考虑Davidson方法的异构并行实现,如算法3所示,Davidson方法中主要执行各种向量操作,相对而言运算量较小,因此应尽可能充分发挥内存和GPU显存的存储带宽.具体地,我们将所有向量以相同的方式按行划分为两部分,使得一部分波函数基矢对应的分量存储在GPU显存中,另一部分存储在内存中.这样任一向量的操作将由CPU和GPU共同完成,并且不需要向量数据的通信.当GPU显存足够时(通常内存容量远大于GPU显存),内存和GPU显存中向量行数的比值为两者存储带宽的比值,理论上此时可以获得最高的性能.由于Davidson方法的存储量线性依赖于子空间中向量的个数和超块希尔伯特空间的维数,当向量个数或者DMRG保留状态较大时,GPU显存中的向量数据会受到GPU显存容量的限制.这会导致较多向量操作在CPU中执行,此时Davidson方法获得的性能较低.
接下来给出哈密顿量作用于波函数(即算法2)部分的异构并行实现,首先将其中的操作合理划分到CPU和GPU中.将算法2中所有操作按照子块S中的好量子数分为多个组,此时各个组中的运算可以独立进行,仅在求和计算(即算法2中step3)时需要通信.此时波函数〉也 按S中好量子数划分为两个部分,其中一部分仅在GPU中计算(记为另一部分仅在CPU中计算(记为
算法2中耗时较多的运算为一系列矩阵乘法,且S中每个好量子数对应分组的计算量在执行运算前可以比较准确地估计.通常,GPU的浮点运算能力强于CPU,适合处理大尺寸矩阵乘法运算,因此在这一步尽量将大矩阵运算分配至GPU,将相对较小的矩阵运算分配至CPU执行.为了实现这一目标,在具体操作中,我们将矩阵乘法平均运算量较大的组分配到GPU中执行,这里平均运算量为组内矩阵乘法总计算量与矩阵乘法个数的比值.进一步,可根据GPU中计算量占的比例PGPU将相互独立的分组计算分配给GPU,剩余组的计算分配给CPU执行.
为了获得较高的异构并行效率,在执行Davidson对角化方法时动态调整PGPU以尽可能实现负载均衡.在具体操(作中,将)每一步迭代优化比例所处的区间记为P0,P1.设定初始区间P0=0,P1=1,然后进入Davidson(方法迭代)过程.令GPU中计算量比例PGPU=P0+P1/2,执行一步Davidison迭代,可以获得此时作用哈密顿量到波函数的CPU和GPU计算时间,分别记为TCPU和TGPU.以此为依据更新下一步迭代区间,使得

并开始下一步Davidson迭代.如此按照类似二分法的收敛思路,通过少数几步迭代就可以收敛到优化比例,之后的大部分迭代运算都趋于负载均衡.
本文主要针对保留状态数较大的问题进行优化,此时涉及到的矩阵较大,GPU中矩阵运算的并行效率较高.同时,考虑到GPU显存的限制,为了减小临时数据的存储量,根据子块S分组后各个组的操作依次执行.这种情况下,仅需要分配一段存储空间,使其同时满足任意一个组中的所有操作即可.在图4中,给出了对角化哈密顿量部分运算的存储需求,并给出了与两子块表示所需存储的对比.可以明显看出其总体的显存需求远远小于两子块表示.因此,相比于参考文献[30]中的异构并行,本文方案可以处理需要更大DMRG保留状态数的问题.
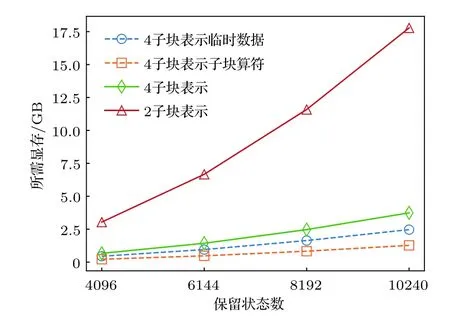
图4 存储临时数据,子块算符需要的GPU显存Fig.4.The GPU memory cost of temporary data and subblock operators.
4 数值结果
为了说明本文优化方法的有效性,我们分别保留4096,6144,8192,10240个状态计算4腿Hubbard梯子的基态能量,并得到了相应的性能基准.图5(a)给出了DMRG优化中各个部分相对于单个CPU的加速比(单个CPU计算时间与单个GPU计算时间的比值),可以看到作用哈密顿量在波函数部分获得加速比最大,其加速比在保留状态数大于4096后较为接近(不低于3.8).当保留状态数较大时,由于GPU显存总量的限制(如图5(b)所示),大部分向量操作由CPU完成,这导致Davidson方法的加速比在保留状态数较大时有所下降.然而,Davidson方法中向量操作占哈密顿量对角化的时间比例较少,因此对哈密顿量对角化部分加速比影响较小(不低于3.5).本文哈密顿量对角化之外的其他操作计算时间占总时间比例约10% (如图3),该部分的GPU并行优化还没有被考虑,因此总并行加速比低于哈密顿量对角化部分的加速比,这里保留最大10240个状态获得的加速比为2.85.图5(c)中给出了异构并行实现中CPU和GPU分别贡献的浮点性能,可以看到随着保留状态数的增大,CPU和GPU中执行的大尺寸矩阵增多,两者贡献的浮点性能随之增大.虽然本文数值计算保留状态数较大,但是其中矩阵尺寸为两子块表示时的 1 /d(Hubbard模型中d=4),目前获得的性能仍明显小于GPU可以达到的峰值性能(1200 GFLOPS).对 1 6×4 的梯子,根据不同保留状态数(4096,6144,8192,10240)得到的基态能量外推得到模型(1)在U=8.0 时的格点平均能量Eg=-0.75114(2),与文献[34]结果一致,见图6.进一步给出基态的电荷密度分布,如图7所示,可以观察到明显的电荷密度条纹,这是铜氧化物高温超导体中经常被观测到的现象之一[13,14,37,38].

图5 异构并行的性能 (a)加速比;(b)Davidson方法中的向量占用GPU显存;(c)作用哈密顿量到波函数部分的性能Fig.5.Performance of hybrid parallel strategy:(a)The speedup;(b)the GPU memory cost of vectors in Davidson;(c)the performance ofH|ψ〉.
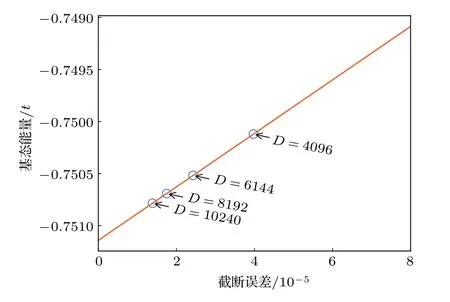
图6 基态能量关于截断误差的函数(直线表示对基态能量的线性外推,直至截断误差为0)Fig.6.Groundstate energy as a function of truncation error.The straight line gives a linear extrapolation of the ground energy until 0 truncation-error.
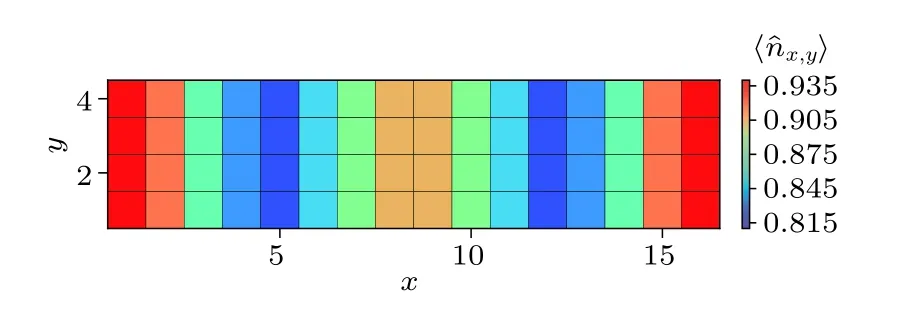
图7 对于16×4 Hubbard模型,U=8.0时的基态电荷密度分布(可以观察到明显的电荷密度条纹)Fig.7.Ground state density profile for the 16×4 Hubbard ladder withU=8.0.Charge density stripes can be clearly observed.
5 结 论
本文主要考虑DMRG方法在准二维格点模型中的应用,针对其中最耗时的哈密顿量对角化部分实现了CPU-GPU异构并行优化,并且给出了负载平衡方法.为了减小准二维格点模型计算中GPU显存的限制,本文的实现中哈密顿量与波函数基于四子块表示,其对角化时需要的GPU显存占用远小于两子块表示,使得本文的异构并行方法可以应用于更多模型、更多问题的研究.将该方法应用到4腿Hubbard梯子模型的求解中,得到了不同保留状态数时DMRG中各个部分的加速比.数值结果表明,本文的异构并行方法适用于保留状态数较大的准二维模型计算,并且总性能随着保留状态数增大而增大.目前,强关联物理问题很大程度上依赖于多体数值计算,一些复杂问题通常进一步受制于计算方法的计算量与计算时间.在多体算法本身出现革命性发展之前,合理利用计算机技术的发展提升算法的效率能为研究强关联系统提供很大的帮助.我们希望该并行方法可以在更多的复杂格点模型、更多问题中得到应用,并能够进一步引起强关联领域对于以GPU为代表的新技术的关注和重视.
