基于Spark框架XGBoost的林业文本并行分类方法研究
2019-06-27崔晓晖师栋瑜陈志泊
崔晓晖 师栋瑜 陈志泊 许 福
(北京林业大学信息学院, 北京 100083)
0 引言
信息资源的开发利用是国家信息化的核心,随着我国信息化建设的深入,物联网、大数据等技术与林业快速融合,大量涉林的信息网站、数据库、林业监测与评估系统等涌现,从而积累了丰富的林业文本信息,亟待挖掘。但是,各系统间的信息缺乏规划与共享,导致林业文本的信息整合水平不足、利用率低下[1]。因此,对互联网中海量林业文本自动进行精准、快速的分类将有助于推进林业信息化进程,为林业信息的挖掘、热点提取、舆情分析、智能信息推送等研究提供科学的理论与技术支持。
文本分类[2]考虑的首要问题是如何准确判断未知样本的类别,常用于文本分类的算法包括K最近邻(K-nearest neighbor,KNN)[3]、朴素贝叶斯(Naive Bayesian,NB)[4]、最大熵[5]、支持向量机(Support vector machine,SVM)[6]、决策树[7]、深度神经网络[8]等。文献[9]将SVM算法应用于Web农业文本,依据数据采集源将文本分为8个产品类别,结果显示SVM分类性能优于NB、决策树等算法。
文本分类算法中的另一个问题是如何提高算法的执行效率,目前较可靠的优化方式是将算法并行化,而基于Spark环境实现算法的并行化是较为常见的解决方案[10]。
在林业文本分类领域,文献[11]提出使用TF-IDF方法结合差分演化算法对ELM极端学习机优化的分类算法,文献[12]则使用高斯混合的分类算法,文献[13]引入LM模糊神经网络优化的分类算法,三者以花、树、虫、土壤和水作为分类标签进行实验。实验结果证明,三者使用的算法在其数据集上的表现均较好。但其数据采集不够全面,标签设定不够科学,导致其分类模型无法适用于互联网中现有的林业文本的分类,且算法均在单机环境中实现,未考虑算法的并行性,难以应对大批量数据分类[14]。
由相关文献可知,林业文本分类的相关研究尚不成熟,其亟待解决的问题可概述为两点:① 分类标签设置不科学,其分类体系与林业结合程度低、领域覆盖面不足,无法直接应用于互联网中的涉林文本的分类。②分类算法多在单机环境下实现,缺乏算法并行方面的考虑,不具备应对实际大规模数据场景的能力。为解决上述林业文本分类问题,本文建立一套较为科学、完善的林业文本分类标签,提出一种Spark框架下的XGBoost算法的并行实现方式,基于该设计构建并行化分类器,衡量不同数据集下该算法的效率和准确率,探索其在海量林业文本分类问题上的有效性。
1 相关技术
1.1 文本预处理流程
预处理是文本分类中最为重要的步骤之一,其处理结果直接影响到后续的分类精度。预处理步骤可概括如下:
(1)采用爬虫技术获取相应的涉林文本,去除异常数据后进行内容解析,使用正则表达式对网页标签进行过滤,建立符合条件的标题与正文。
(2)引入开源工具ANSJ包进行中文分词。该分词工具基于n-Gram+CRF+HMM并使用Java实现,分词速度达到200万字/s,准确率可达到96%以上,适用于当前对分词效果要求较高的各类项目,其分词效果如图1所示。
(3)使用停用词集合过滤无用的词汇,构建文本的特征词集合。

图1 林业文本的分词结果Fig.1 Word segmentation result of forestry text
1.2 基于TF-IDF的特征工程
高维度和高稀疏的向量矩阵给计算机的计算量和学习训练过程增加机器负担,且会影响分类精度,为进一步实现特征矩阵降维,需要对文本特征进行特征选择。
向量空间模型(Vector space model,VSM)[15]是文本分类中最常见的特征标识形式。通过使用这种模型,每篇文档被表示为一组特征向量D={(w1,f1),(w2,f2),…,(wi,fi),…,(wn,fn)},其中wi表示在D中出现的特征词,fi是特征词wi的权值。其中,i的取值为1,2,…,n,wi经由特征词筛选得到,本文中的fi值将通过经典的词频-逆文件频率算法(Term frequency-inverse document frequency,TF-IDF)[16]进行计算。
TF-IDF是文本挖掘中常用的加权技术之一,用于衡量一个字或词在语料库中的重要程度,其计算公式为
VTF-IDF=VTFVIDF
(1)
式中VTF——特征词在文本中出现的频率
VIDF——特征词的逆向文档频率
1.3 XGBoost算法原理
XGBoost[17]是基于Gradient Boosting算法的一个优化版本,其通过将多个回归树模型集成在一起,形成一个强分类器,具有训练速度快、可并行处理和泛化能力强等优势。
该算法的基本思想[18-19]是选择部分样本和特征生成一个简单模型作为基本分类器,在生成新模型时,学习以前模型的残差,最小化目标函数并生成新模型,此过程重复执行,最终产生由成百上千的线性或树模型,组合为准确率很高的综合模型。它的目标函数Oobj经过泰勒公式展开后,最终化简为
(2)
式中γ——学习率λ——正则化参数
T——回归树的叶子数量
Gj——一阶导数Hj——二阶导数
其中,Oobj的大小依赖于Gj和Hj的值,Oobj值越小,XGBoost模型的预测和泛化能力就越强。
1.4 Spark框架
Apache Spark[20]是UC Berkeley开源、类Hadoop MapReduce的通用并行计算框架,不同的是,Spark的Job中间结果可以保存在内存中,而不需要读写HDFS,因此,Spark是基于内存的并行化计算框架,其执行效率较Hadoop快数十倍乃至百倍。Spark通过基于弹性分布式数据集(Resilient distributed dataset,RDD)的编程模式,使得大部分数据并行算法均可运行于Spark集群中。
2 Spark下林业文本分类算法的并行化
2.1 林业分类标签的设定
文献[21]经调研将林业信息中各个类别的内容具体化,设计出科技、生产资料、市场、花卉、政策等类别,经过对爬虫获取数据的相似性比对,生产资料类与市场类文本存在大量的信息重叠,故将两者合并为林业市场与产业类。根据文献[22]提出林业科技类成果所具有的特点,将科技类报道与技术类成果组合为林业科学与技术类(包含林业论文、林业专利和科学类新闻等)。文献[23]指出林业资源监管中主要包含森林资源、湿地资源以及生物多样性资源等,而花卉植被属植物类,占生物多样性较大比重,因此,将生物多样性资源分类为动物类与植物类。至此,在总结前人研究的基础上,将整体样本分为林业新闻与政策类(A类)、林业科学与技术类(B类)、林业市场与产业类(C类)以及林业资源类(D类)4类,并将采集到样本量最多的林业资源类文本分成4个子类,即森林类(D1类)、植物类(D2类)、动物类(D3类)、湿地类(D4类)。相较以往分类体系,该体系分类标签设定更为科学、全面,使得分类模型与林业领域结合更为紧密,也有利于未来更细层面的林业文本分类研究。
根据文献[24]提供的爬虫思路,从互联网中采集原始数据,爬虫语料中约75%的文本来源于中国林业新闻网、中国林业政府网、林业信息网、林业产业网等林业相关网站,其余约25%来源于新闻刊物,如新华网、绿色时报、百度新闻等综合型新闻网站。随后,从每类中提取3 000篇文章,即所有实验样本数为21 000,将数据按各自标签存入Hadoop Hive数据仓库作林业语料。
2.2 基于Spark文本分类的并行化设计
基于Spark的林业文本分类流程主要分为预处理过程、训练与测试过程。其中,文本预处理中的预处理、特征值计算以及特征词的选取均基于RDD并行化实现(图2)。该预处理程序由Driver模块、Mapper模块以及Reducer模块组成。Driver用于与底层沟通,初始化集群组件;Mapper模块用于将包含原始文本的RDD_data进行去噪、分词形成新的RDD_words,随后执行Reducer模块,基于CHI值进行筛选并使用TD-IDF进行各个特征词的权重计算,随后生成词向量形式的RDD_vec。
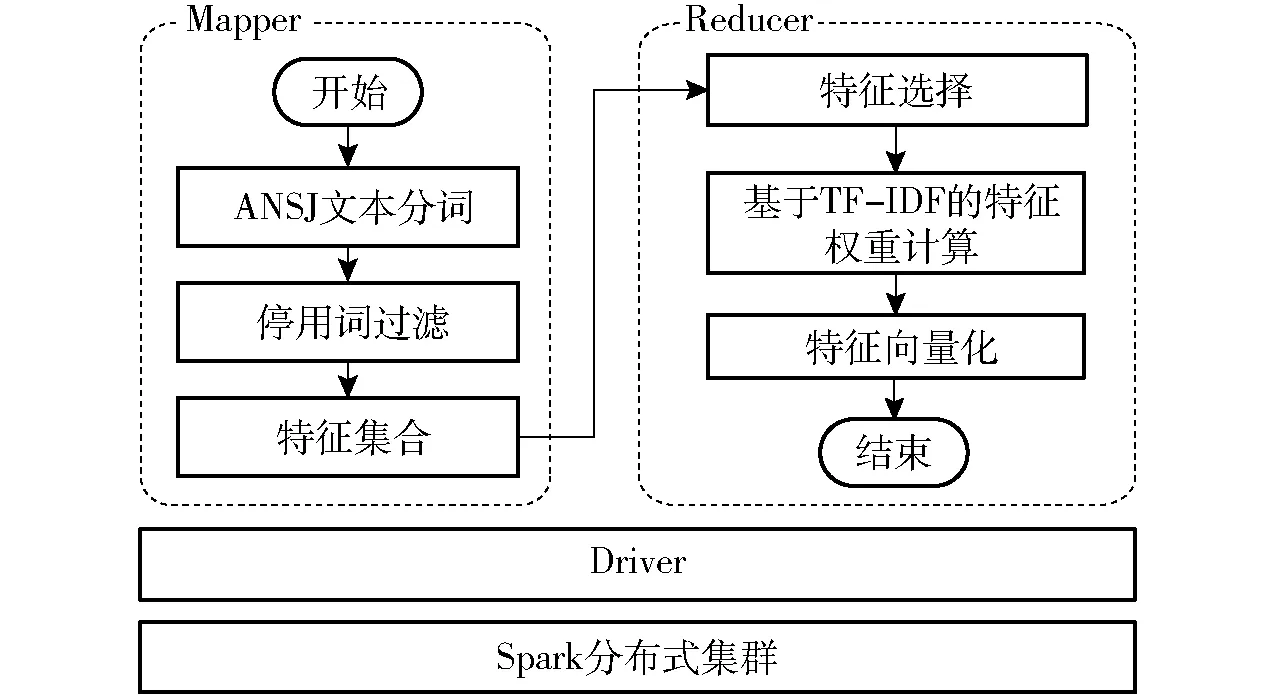
图2 文本预处理的并行化实现Fig.2 Parallelization of text preprocessing
基于Spark框架下XGBoost的并行化思想是通过RDD算子与框架的内存迭代机制提高算法的执行效率来实现的。其中,Spark集群各节点读取训练数据RDD_vec存于内存中。Mapper部分主要完成决策树的学习过程:在选取分裂节点时,并行计算各个特征的增益,选取增益最大的特征进行分裂以进行树的构建;树的各分支的节点选取都通过并行化进行训练,在达到建树的最大深度或分类增益小于设定阈值后停止建树,从而完成一次算法中的多个树模型的生成工作;随后由Reducer比较并构建准确率相对更高的树模型,输出一轮迭代的结果,随后将迭代结果输入到下次迭代中,直到选取出最优模型。
林业文本的训练与测试过程主要分为如下步骤(图3):
(1)对语料中的文本进行自动分词,去除低频词与停用词,构建为〈标签,(文本,特征词集)〉的键值对形式,存入RDD_data。
(2)通过利用TF-IDF进行特征词的权重计算并进行特征向量化,形成〈标签,(文本,特征词集,TF-IDF权值)〉键值对形式的RDD_vec。
(3)提取RDD_vec中的〈标签,(特征词集,TF-IDF权值)〉,通过Spark提供的转换算子与执行算子构造XGBoost与其他4种算法的并行分类器。
(4)以随机选取的方式将90%的键值对作为训练集RDD_train传入分类器,分类器进行迭代训练,并将结果与模型保存。
(5)将余下10%的键值对作为测试集RDD_test对保存模型的精准率进行验证。
(6)重复步骤(4)~(5),选取最优参数组合,将最优模型保存在Hive数据仓库中;基于此,模型将不断进行新数据的训练,从而积累较为科学的林业语料。

图3 基于Spark的文本分类处理流程图Fig.3 Process of forestry text classification based on Spark
3 实验与结果分析
3.1 实验环境与评价指标
采用的硬件环境是Centos7、Hadoop 2.7.0、Spark 2.2.0、Hive 2.1.1构成的仿真平台。实验环境共由5台主机构成Spark计算集群,其中1台为Master 节点,其余4台为 Slave节点,各工作节点的运行内存为4 GB。
对分类效果的评价采用精准率P(precision)、召回率R(recall)、综合评价指标F1(F1-measure)、准确率A(accuracy)等指标,其计算公式为[25]
(3)
(4)
(5)
(6)
式中TP——将正类预测为正类的样本数
TN——将正类预测为负类的样本数
FP——将负类预测为正类的样本数
FN——将负类预测为负类的样本数
精准率衡量类别的查准率,召回率衡量类别的查全率,F1则综合了P和R的结果,所以F1越高则说明实验方法越有效,分类器的分类性能越好。
3.2 语料的特征词分析
对预处理后的21 000个林业文本语料进行分词统计,共计4 402 145个有用词条,无重复词集共计264 423个,平均一篇文章中影响分类的词数约为209个;篇幅最长的样本包含词数为11 806个,最短一篇包含词数为34个。现分别为每个类别计算候选词的TF-IDF值,并选取每个类别的前10个特征词,如表1所示。
由表1可见,语料中各类别中最为靠前的10个特征词频中,仅存在少量交集,且与该标签对应的林业专题动态信息的主题相符,“改革”与“林权”等词汇高频出现与国家推动林业改革的情形相符,说明该分类体系可用于进一步提取林业领域的“热词”;而科学与技术类、市场与产业类以及植物类的高频词汇,一定程度上反映出林业研究多集中于花卉、林木,出现这些词频的样本在结合“花瓣”、“花种”等领域专属名词集合时,即可为挖掘文章主题、提取信息主干等研究提供新思路。因此,本文设计的分类标签相比原有分类标签更为科学,且有益于林业文本的拓展研究。
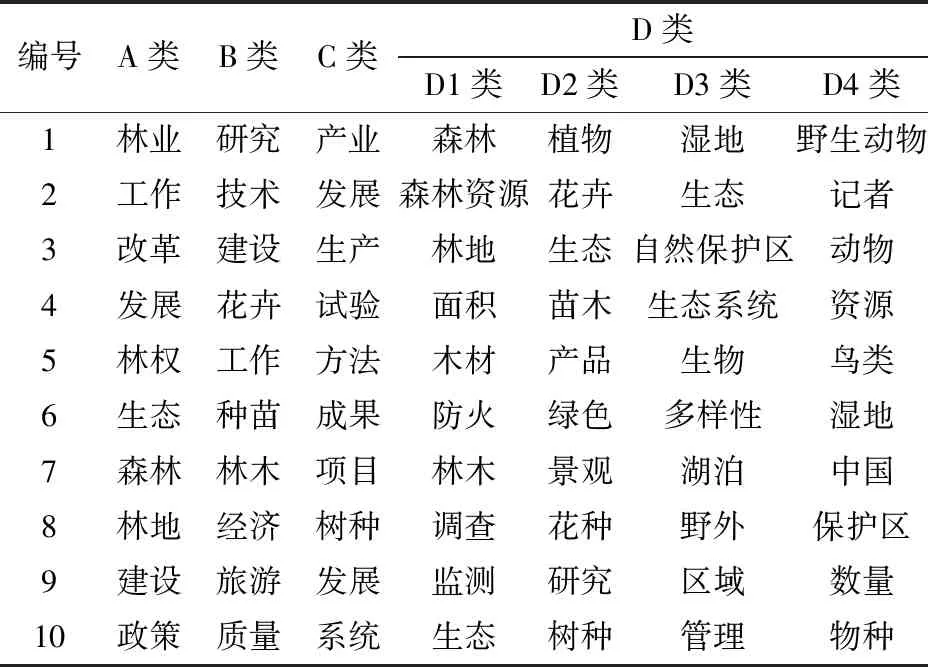
表1 各类别林业文本的前10个特征词Tab.1 Top 10 characteristic entries of each category
3.3 各并行算法评价指标的对比
使用前文中叙述的分类实验方法,从Hive数据仓库中,每类调取3 000个样本作为实验数据,随机选取其中90%样本为训练集,其余10%的样本为测试集。为验证并行化环境下,XGBoost与传统机器学习算法、基于神经网络的算法的性能,实验选取了NB、GBDT决策树代表传统机器学习,选用ELM极端学习机和BP神经网络(Back propagation neural network,BPNN)作为神经网络算法的代表,将经过网格搜索获取其最优参数的5种并行化算法测试结果的F1记录为表2。

图4 各算法的准确率与训练时间对比Fig.4 Comparison of accuracy value and training time of each parallel algorithm on 100% data
由表2可知,在100%的数据集下,XGBoost在每个类别上的F1均高于其他4种机器学习算法。模型训练过程与XGBoost相似的GBDT的性能仅次于XGBoost算法。在面对海量文本的分类场景中,两种基于神经网络的算法ELM与BPNN整体分类效果不如其他3种算法。
XGBoost算法在A、C、D4这3类上的F1分别为0.998 4、0.982 9和0.945 6,尤其A类与C类的F1几乎达到1.0,说明林业新闻与政策类和林业市场与产业类的文本较其他5个类别更易被区分,其次更易被分类的是动物类文本,而在B、D1、D2、D3类别上的表现并不突出,其值均在0.85~0.9之间,即科学与技术类、森林类、植物类、湿地类文章的部分样本具有相似性,这也与实际情况相符,林业的研究多集中于森林与湿地两大生态系统,并以林木花草等为研究主体,而在表1中也可以明显看到,“花卉”、“林木”、“研究”等词在类别中有交叉,与当前的实验结果相吻合。

表2 各文本分类算法的F1对比Tab.2 Comparison of F1 values of each text classification parallel algorithm
在其他4种算法的结果中,GBDT在A和C类的F1高于0.9,但在D1类低于0.7;NB算法在A、D2、D4类上的F1达到0.8以上;ELM与BPNN在各类别上的精度略有差距,两者整体的分类精度不高,说明在应对海量数据的分类场景时,两分类算法需进一步优化。
显然,XGBoost算法在各个类别数据上的精准度、召回率以及F1上有明显的优势,在优势类别中的文本分类精度极高,且该算法训练的模型更符合实际场景,从而验证了XGBoost在海量林业文本分类问题上的有效性。
图4是基于Spark并行环境下的各分类算法的准确率与执行效率的对比,其准确率与表2中F1的分布一致:XGBoost算法的分类准确率最高,为0.923 4。从图4b可看出,BP神经网络的训练时间最长,为2 182 s,其次是ELM算法,这与神经网络算法的执行时间常高于传统机器学习算法的情形相符。因此,XGBoost在保持极高准确率的情况下,时间执行效率方面远优于两种神经网络算法,略慢于传统机器学习算法。
3.4 不同训练集对分类结果的影响
依照林业文本分类流程,从语料的各个类别中分别随机取数量为90、150、300、600、1 200、1 800、2 400、2 700、3 000的样本构成信息量不同的实验数据集;其中,90%用于模型训练,10%用于测试,由交叉验证求取不同训练集下XGBoost最优分类结果如表3所示,并以同样流程求取其他算法的分类结果进行对比分析,对比结果如图5所示。
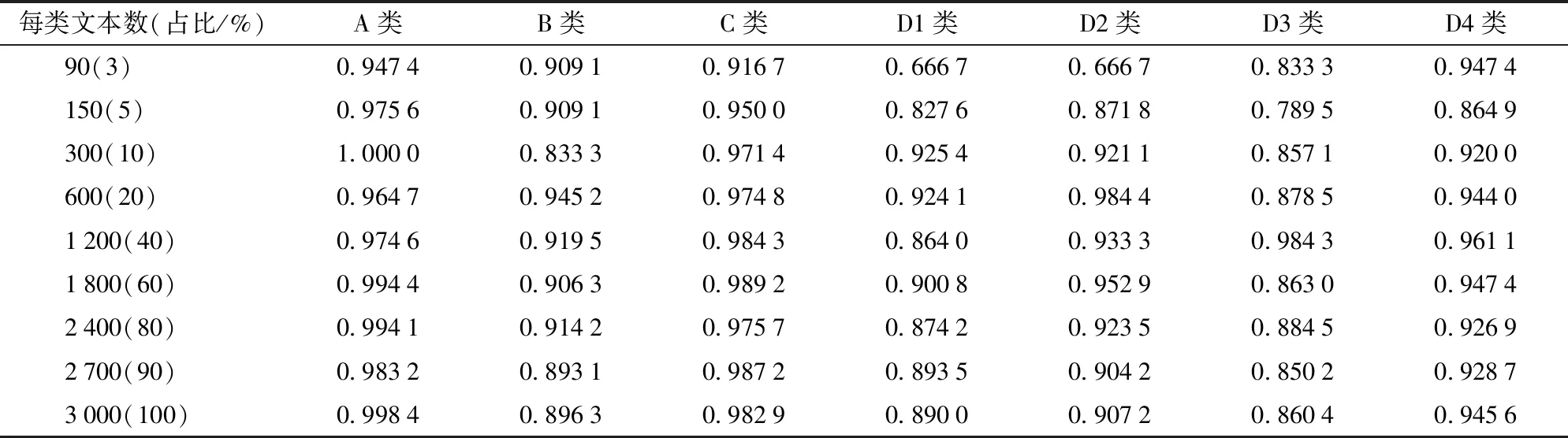
表3 训练样本量对XGBoost算法F1的影响Tab.3 Influence of number of training samples on XGBoost classification F1 value

图5 训练数量对各并行算法分类结果的影响Fig.5 Influence of number of training samples on results of each parallel algorithm
由表3与图5可以看出,样本数量对分类算法的精准率影响较大,在低于600(20%)个训练样本下,各算法分类精度均不稳定,某些类别上的分类精准率会低于0.7。随着训练样本数量的增加,XGBoost精度稳定提升,而两类神经网络算法对新数据的支持能力较差,导致其精度不稳定。当样本文本数量增加到约2 400(80%)个后,继续增加样本文本的数量,XGBoost分类精准率提升缓慢直至趋于稳定;而GBDT和NB在多数类别上逐渐趋于稳定,少数类别伴随有轻微下减的趋势。由图5h可见,随着样本的继续增加,XGBoost算法的准确率扔保持缓慢上升的趋势。
最后,为验证XGBoost算法模型的实用性,选取中国林业网的20条最新新闻进行模型验证,验证集的准确率为0.95,说明该分类器在实际场景下的林业文本分类应用性好,可直接用于互联网中的涉林文本的分类。
3.5 加速比
加速比通常用于衡量平台的计算节点数量对算法并行效率的影响。实验将计算节点数由单机模式逐渐增加工作节点到4个,将2.1万条、4.2万条、8.4万条训练集下的实验结果记录为表4。
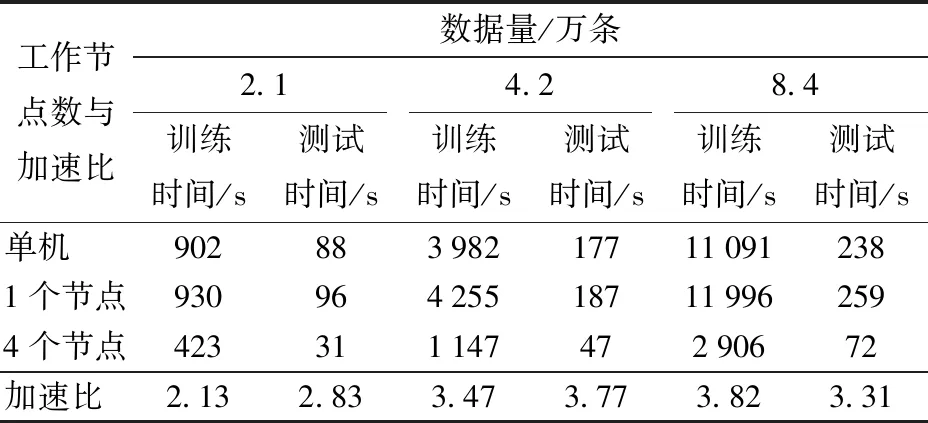
表4 Spark集群不同节点数对加速比的影响Tab.4 Effect of number of distributed nodes on speedup ratio
由表4可以看出,在仅有一个工作节点的集群模式下,Spark集群运行效率不及单机算法,原因在于Spark本身的资源调度需占用一部分资源和时间。在数据集仅有2.1万条时,加速比仅为2.13,并不够明显;而增加1倍数据时,加速比提升至3.47;增加至4倍时,加速比提升为3.82。其中,当数据为2.1万条时,从单机至4个节点的运行时间分别为902、930、423 s。可以看出,随着节点数的增加,实验所需要的训练时间呈下降趋势。
综上,该并行算法较单机版本效率提升明显,且数据量越大,该算法的并行效率越高。
4 结论
(1)针对现有林业分类研究中暴露出的分类标签设定不科学、实验训练产出的模型不具有实用性的问题,借鉴林业专家提出的林业主题信息种类,重新进行分类标签的设定;基于林业爬虫技术采集涉林文本,从林业需求出发,设计出分类粒度更细致的分类体系,使得分类模型可直接用于互联网中的海量涉林文本分类;将分类后的样本以统一的格式保存后,可逐渐积累林业语料,为后续层次更为细致的林业文本分类研究做铺垫。
(2)针对传统林业文本分类中执行效率低、精准度不高的问题,提出一种基于Spark计算环境的XGBoost并行化方法。各算法的对比结果表明,在包含不同比例的数据集上,该并行设计XGBoost算法较其他算法的优势表现在3个方面:① 各个类别的精度均高于其他算法,在优势类别上的F1可达到0.998 4。② 模型通过训练达到精度峰值所需的样本量较其他算法相对更少。③ 模型的精准率趋于稳定后,随着样本的增加,其精准率保持稳定缓慢增长,并未呈现出明显的下降趋势,适用于未来更多新语料加入模型进行训练的场景。此外,由加速比实验可以看出,该并行化算法较单机算法提升明显,且数据量越大,并行效率越高。综上,并行XGBoost算法可有效解决海量林业文本的高效、精准分类问题。
(3)本文的分类结果并未达到完全正确的水平,除受算法本身的限制外,类别之间的少量样本存在交叉现象也是原因之一。因此,本文建立的分类体系仍可以从细化分类粒度的层面加以改进。
