结合边缘检测与CNN 分类场景文本检测的研究
2019-06-27张哲汪毓铎
张哲,汪毓铎
(北京信息科技大学信息与通信工程学院,北京100101)
0 引言
移动互联网的高速发展以及智能手机、可穿戴设备等移动电子设备的普及,使得自然场景图像的获取和传输变得越来越便捷[1]。图像中场景文本的检测和识别是获取图像中语义信息的重要方法,其中场景文本的检测高成功率可以有效降低场景文本识别的复杂度。到目前为止,不同于传统的光学字符识别,场景文本检测存在照明、投影的可变性、失真、尺度、字体方向等问题[2]。当前许多应用程序中都有用到从场景图像中检测文本,例如身份证识别、名片识别、票据识别、车牌识别、视频字幕识别、Google 街景识别等。在当今的智能化环境下,快速高效文本检测可以有效提高文本识别的识别率,且整套的流程可以结合起来以便商用。因此面向场景文本图像检测方法的研究既有重要的理论研究意义,又有广阔的应用前景。
1 研究现状
目前,常用的场景文本检测方法主要有以下四类[3]:基于纹理特征的文字检测[4-8]、基于边缘的文字检测[9-12]、基于连通域的文字检测[13-18]以及基于深度学习的文字检测[19-24]。
Kumuda T 等人基于纹理特征使用一阶和二阶统计提取,先检测出文本区域,使用判别函数过滤掉非文本区域,再文本区域合并和定位[6]。Liu C 等人提出基于边缘特征的无监督分类的图像文本检测算法[10],它使用应用边缘检测来获得水平、垂直、左上和右上方向的四个边缘图,从四个边缘图中提取特征用来表示文本的纹理属性,再应用K 均值算法来检测文本候选区域,最后通过经验规则分析确定文本区域,主要针对图像和视频中的文本检测。Ma J 等人提出构造最大稳定极值区域(Maximally Stable Extremal Region,MSER)树,通过非最大抑制策略去除重叠MSER,根据节点特征修剪链接树[13]。Jiang Y 等人使用基于旋转区域CNN(R2CNN)的自然场景文本检测方法,使用区域建议网络生成轴对齐的边界框,再利用倾斜非最大值抑制策略得到最终检测结果[19]。
尽管许多学者对场景文本图像中的文本检测算法做了相应的研究,并取得了较好的研究成果。但在复杂背景情况下,很难达到满意的检测效果。因此,本文研究了结合边缘检测与CNN 分类剔除非文本区域的场景文本图像检测方法,减少了从颜色信息和边缘细节信息获取场景文本图像的限制,并提取文本区域。
2 场景文本检测
在本文中,场景文本检测分四步完成,其主要流程图如图1 所示。预处理模块的主要功能是将输入场景文本图像的文本信息进行增强处理。文本定位模块主要功能是通过边缘检测方法对预处理的文本图形进行初始文本定位。文本筛选模块主要功能是对初次定位完的文本信息进行筛选,利用CNN 分类剔除非文本信息。文本框融合模块的主要功能是按距离对过滤后的文本信息进行整合,并输出最终结果。
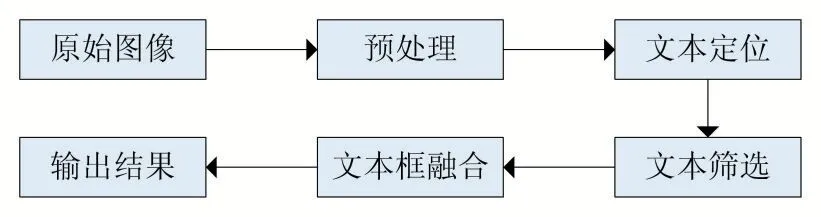
图1 场景文本检测流程图
2.1 预处理
在图像分析中,图像质量直接影响设计的准确性和识别算法的效果,因此在图像分析(特征提取、分割、匹配和识别等)之前需要进行预处理。图像预处理的主要目的是去除图像中与文字无关的背景信息,凸显真实有用的文字信息,提高有用文字信息的可检测性。从而,可以实现提高字符特征提取的目的以及文本图像分割,匹配和识别的可靠性。预处理流程如图2所示。

图2 预处理流程
(1)灰度图像
对于输入的颜色为RGB 的图像,它在每个颜色分量上分解并分别由R、G 和B 表示。灰度图像的灰度值表示如式(1)所示,其中Y 表示灰度值。灰度转换前的待测场景文本图像如图3(a)所示,转化后的场景文本图像如图3(b)所示。


图3 场景文本颜色转换图像
(2)中值滤波
中值滤波是一种用于对图像进行非线性降噪的过程。中值滤波的原理是:首先选取一个像素中心点,可以为当前像素,然后在中心点周围设置邻域窗口,并将该邻域范围内的所有像素的灰度值进行排序,有序数列的中值将被视为中心点新的像素值。在中值滤波之后,可以有效平滑灰度文本图像。
(3)图像二值化
图像二值化是将中值滤波后的图像转化成一个非黑即白二值图像的过程。中值滤波图像包含要测试的文本和相应的背景噪声。它的像素值在0 到255 之间,而二值图像的像素值只有0 和255。要从多色值图像中提取目标文本,可使用设置阈值P 的方法。当中值滤波图像中的任何点的像素值大于阈值P 时,其像素值被设置为255。反之,当像素值小于阈值P 时,将其设置为0。当中值滤波图像中的像素等于阈值P时,其像素值可以设置为0 或255 中的任一值。在本文中,中值滤波文本图像通过进行二值处理后,结果如图4 所示。

图4 场景文本二值图像
2.2 边缘检测
由于文本由一系列带边的笔划组成,因此图像中的文本和背景被文本的边分割。本文使用的边缘检测就是利用文字的边缘与背景图像的颜色差来定位文本,其主要流程是对二值图像进行扩展、腐蚀再取两者差值确定文本的边缘。具体步骤为:
(1)设定扩展核函数,对二值图像进行边缘细节扩展处理,结果如图5(a)所示;
(2)设定腐蚀核函数,对二值图像进行边缘细节腐蚀处理,结果如图5(b)所示;
(3)对图5(a)和图5(b)的两幅图像像素值作异或处理,得到文本边界,结果如图5(c)所示;
(4)再次设定扩展核函数,对图5(c)进行边缘细节扩展处理,结果如图5(d)所示。
设置扩展的目的是让轮廓更加突出,设置腐蚀的目的是去掉一些细节线,如表格线等。第二次异或后的图像进行扩展是为了让边缘线轮廓更明显一些。

图5 场景文本边缘检测图像
2.3 CNN分类
CNN 分类器的功能主要是过滤边缘检测结果并消除非文本区域。为了能够训练出一个准确率比较高的分类器,需要准备大量的训练数据,使用了5000 张训练图像,大小统一,其中包括正样本和负样本图像。正样本图像是多个场景图像中截取的字体多样、方向各异、大小不同的文字区域图像。负样本图像是文本图像的干扰项,如楼梯、树木、汽车、街道、房屋,等等。
在短文本分析任务中,由于句子长度有限,结构紧凑,意思可以独立表达,使用CNN 来处理这类问题是十分可行的。CNN 分类器结构包含两层卷积层、一层池化层、一层全连接层。卷积核大小为5×5。训练样本数据如图6 所示,其中图(a)是正样本数据,图(b)是负样本数据。

图6 训练样本数据
2.4 文本框融合
经过分类器后,图像中的文本区域可被标识出来,文本框的位置、高度、宽度、中心点等数据也会被相应记录。文本框融合的目的是将相邻字符,如同一个单词的多个字母、包含同一个字符的多个文本框等可被合并的文本框融合为一个大的文本框,具体实现方法如下:
(1)对所有N 个文本框进行标记,编号为1,2,…,N,生成大小为N×N 的文本区域矩阵;
(2)根据文本区域的矩阵,计算个文本框之间的距离,并存储在新的距离矩阵D 中,其中Dij表示第i 个区域与第j 个区域中心点间的欧氏距离,计算Dij的均值d;
(3)生成新的标记矩阵T,初始值为0,大小为N×N。遍历矩阵D,寻找小于特定门限(可设置为1.5d)的Dij,则认为第i 个区域与第j 个区域可聚类为同一个区域,将Tij设置为与Tii相同的值,同时设置T(i+1,i+1)=T(i,i)+1;
(4)遍历矩阵T,按行或按列寻找与Tii相同的Tij或Tji,连通对应的第i 个区域与第j 个区域,生成新的矩形框;
(5)更新文本框。
经过融合后的文本框不仅可以起到去重的作用,还可以为之后的文本识别奠定基础。
3 可行性分析
输入包含文本的自然场景图像,使用上述方法进行文本检测,测试结果如图7(a)所示。将检测到的文本矩形框按距离进行融合,得到如图7(b)所示的最终结果。

图7 检测结果
4 结语
本文研究了场景文本检测方法,充分利用了场景文本图像的颜色信息和边缘信息,并使用了深度学习模型做分类。首先对获取的场景图像执行预处理,对预处理后的图像执行边缘检测,并获得候选字符区域,将其输入到CNN 模型中以进行分类和筛选,以确定它是否为文本图像,并保留所需的文本区域。从而实现文本字符的检测提取。实验结果表明,本文的方法可以有效应用于场景文本图像的文本检测,具有较好的文本区域提取能力。
