基于NAO 机器人的目标跟踪和人脸识别研究
2019-06-27马迎杰王佳斌
马迎杰,王佳斌
(工业智能化与系统福建省高校工程研究中心,泉州362021)
0 引言
在日常生活中与人类互动和支持的辅助和社交机器人是一个在研究和工业社区中获得一致兴趣的领域。常见的应用领域包括通知商业和展览场所的客户,博物馆的访客指导以及大型超市的购物指导。已经有许多供应商提供机器人解决方案,其功能可以基本满足上述应用。然而,虽然机器人平台种类繁多,但根据客户要求,适应和快速调整辅助机器人从一种情况到另一种情况的行为仍然是一项挑战。
NAO 机器人它是第一台专门设计用于与人类互动的机器人机器之一,具有非常友好可爱的外观。与机器人的交互可以通过语音,手势或触摸完成,并且可以通过说话或使用平板电脑上显示的视觉信息进行回复。Nao 处理的功能已经允许在日常环境(例如公共办公室或商店)中成功部署演示,以及实施教育应用。
然而,我们设想的应用场景的规范(例如,商城用户协助)要求机器人能够在更严重的部分遮挡条件下以更高的准确度检测、跟踪和识别更远距离的人。该场景考虑先前未映射的封闭空间的情况,其中机器人执行随机搜索以寻找感兴趣的用户。在检测到人时,机器人需要跟踪并移近检测到的用户以便执行面部识别。机器人重复一个检测周期-跟踪-识别,直到它能够找到并识别需要通知待处理通知的人。本文也是致力于服务机器人的研究与开发,作者也是众多研究者中的一员。从国外的最新服务机器人进展来看,未来人们对服务机器人的研究肯定一步一步地深入,说明笔者所做的研究是有意义的。
1 硬件系统与软件系统
本文采用的智能机器人平台为NAO 仿人机器人。其中系统所需要的硬件系统包括摄像头、CPU、语音合成器、扬声器等。由于识别算法运算量大,而其CPU 运算能力较差,同时需要担负NAO 系统的运行,因此难以支撑识别算法的实时运算。因此采用通过机器人进行图像采集,并将图像通过网络传输到上位机进行处理,再将识别结果返回到机器人上进行跟踪识别。在软件层面,系统是在NAOqi 框架[6]之上开发的,这是机器人的默认环境。
2 计算机视觉框架描述
机器人具有称为自主生命的默认操作模式,使其能够活跃并与用户交互。这种操作模式使机器人一旦接近足以吸引机器人的注意力就能与人接触。然而,我们提出的方案要求机器人能够主动检测并移动到超出其默认交互距离范围的人。此外,人们的检测和识别需要处理目标用户的部分遮挡的情况,以及不同的照明水平。这促使我们利用外部计算机视觉框架进行物体检测和人脸识别。在这项研究中,我们使用YOLO进行物体检测,使用FaceNet 进行人脸识别。YOLO 是一种在图像中进行物体检测的方法,该方法可以通过卷积神经网络实时地在图像上的一次通过中检测来自定义的类别列表的所有对象实例。YOLO 只用一个神经网络和一次评价,就直接从输入的整幅图像预测边框和类别概率。正因为整个检测流程是一个网络,所以它可以直接进行端到端的优化。作为一种统一结构,YOLO 的运行速度非常快。基准YOLO 模型每秒可以实时处理45 帧图像,同时保持较高的目标检测平均准确率(mAP),而且应用于训练领域外的图像时泛化能力也较强。因此,这种方法足以实现我们的目标,实现物体的实时检测。
FaceNet 在考虑人脸识别任务时给出了最佳结果。对于图像中的每个面,FaceNet 提供了128 个元素的嵌入,这是通过将图像传递到深度神经网络而产生的。从相似面部获得的两个矢量具有彼此更接近的特性。通过这种方式,可以导出相似性度量,并且可以使用支持向量机对面部进行分类,或者使用k 均值方法进行聚类。
FaceNet 使用的监督培训方法使用大量标记图像,可以在我们遇到不同面部位置和方向,不同光度或图像质量的真实条件下获得更好的结果.
3 架构实施
本文拟议的系统有几个组成部分。机器人平台使用来自内部和外部处理的数据。内部处理是指传感器、照相机和移动,而外部处理是指用于获得所需信息(即人的检测和识别)的图像处理。
图1 显示了系统架构。图像处理任务在远程服务器上实现,结果随后传递给机器人。对外部处理的需求是由于机器人的有限计算能力,其无法达到具有实时结果的良好技术水平。
人物检测模块将检测到的人的边界框(bbox)信息与深度信息一起转发给人物跟踪模块。该模块将当前检测与先前检测相关联。此步骤是必需的,因为机器人必须一次跟踪一个人。在并行处理管道中,RGB 图像被传递到面部检测和识别模块,该模块能够提取关于面部位置和其识别的人的信息。然后通过TCP 连接将提取的信息(检测到的人的边界框,跟踪会话的id,深度信息和名称)传递回机器人。

图1 系统架构概述
3.1 人员检测模块
系统最重要的组成部分之一是用于人员检测的模块,必须以准确的结果实时进行检测,以便跟踪一致,没有错误。如前所述,对于此任务,我们使用YOLO 网络,因为它很适合我们的系统,能够处理大约每秒40 帧。
机器人产生的图像流和YOLO 之间的集成在服务器上运行,具有高计算能力。我们使用来自NAOqi 框架的ALVideoDevice 模块来访问两种已经相关的图像流、RGB 和深度。
我们使用预先训练的YOLO 网络进行快速检测。
图像的网络结果是一组边界框以及相应的置信度,其中每个边界框表示人在图像像素中的位置。检测限于顶部正方形,顶部正方形由检测宽度定义。此更改对于跟踪部件非常有用,因此机器人可以将其头部位置对准检测到的人的上半身。
3.2 人员跟踪模块
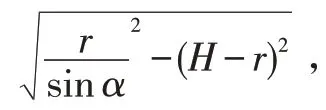

图2 人物跟踪图像表示以及角度计算
其中h 为机器人站立时颈部到脚底的高度,h=459.59mm,α为HeadPitch 关节当前偏移角,即垂直偏移角,可由系统函数获得;角度β为NAO 机器人嘴部摄像头硬件位置与水平线的夹角,查表可得β=39.74。将相关数据带入公式可得
在跟踪过程中如果要求机器人与目标保持1 米的对话距离,则每次只需要移动S-1 米的距离即可。
在最小深度范围内跟踪。当一个人离机器人比深度范围更近时,机器人将要求该人转身并面对它以便被人脸识别模块识别。
3.3 人脸识别模块
如前面所述,用于面部检测和识别的网络是FaceNet。使用NAOqi 框架拍摄RGB 图像,然后将其传递到外部服务器到面部检测和识别模块,在该模块中网络获得检测。该应用程序仅考虑有人情况下检测到面部。该检查基于边界框完成:如果检测到的面部的边界框在检测到的人的边界框内,则关于面部的信息与该检测到的人相关联;否则面部会被忽略,因为我们没有检测到人物。第二种情况一般不会在实践中发生,因为YOLO 网络在人员检测方面给出了非常好的结果,特别是在某人的面部是可见的情况下。
3.4 用户交互模块
目前,该模块是针对我们一开始所呈现的场景实现的,即向所识别的人发出关于个人消费或购买问题的声音和视觉通知,并等待该人的确认。
当机器人到达人时,基于面部识别信息,它知道它是否到达了它正在寻找的人。如果它看不到前面的人的脸,它会通过声音提醒人(例如“你好,请看我!”)。
使用NAOqi 框架模块实现与用户的交互。机器人从外部服务器接收人员的通知,并使用TextToSpeech模块逐个开始说明。它使用TabletService 创建一个视图,该视图还在平板电脑上显示通知,以便用户可以将其标记为已读,或者可以向前或向后浏览它们。机器人解释的声音命令用于确认提醒或关闭显示。它们使用语音识别模块进行解释。
4 实验
4.1 系统实现
该系统在具有不同人员的实验室环境中进行了实验测试。建议的测试场景意味着机器人从随机位置开始,并开始寻找特定的人来提供通知。机器人不停地环顾四周,如果它检测到一个人,它就会向它们移动;这个人可以站立或坐着,它可以被展示的商品等完全可见或部分遮挡。如果检测到的人是正确的,那么NAO 将读出待处理的通知,否则它将继续搜索。
机器人位于初始位置并开始旋转,首先是头部,然后是整个身体。头部从右上角到左上角,然后从左下角到右下角进行圆周旋转。我们选择这种行动来检查机器人当前位置的视野中的所有可能位置。如果没有人检测到,那么它将以120°旋转整个身体。当检测到人时,头部和身体旋转都停止,并且下一个模块被激活,更准确地说,是并行运行的跟踪和面部识别。
机器人将跟踪检测到的人并且将越来越近,直到达到预定义的距离阈值。如果机器人到达目标,但没有检测到人的面部,它将要求该人直视它以识别它们。如果此人被识别为目标人,NAO 将读出待处理的通知。如果没有,它将继续搜索。
4.2 系统性能测试
我们对人物检测和人脸识别模块进行了定性评估。目标检测结果如表1 所示。

表1 YOLO 与传统方法比较
从实验结果中可以得出:NAO 目标检测系统实时识别效果与速度满足实用要求。
对于常见视频320×240 像素大小的图片,需要耗时56ms 左右,常见视频的帧率为24-30 帧/s,也就是说每帧时长为33-42ms,如果要做到实时的人脸检测,算法耗时最好少于20ms,以此为系统的后续处理留下足够的处理时间。为此我们进行了图像大小的耗时测试,如表2 所示。
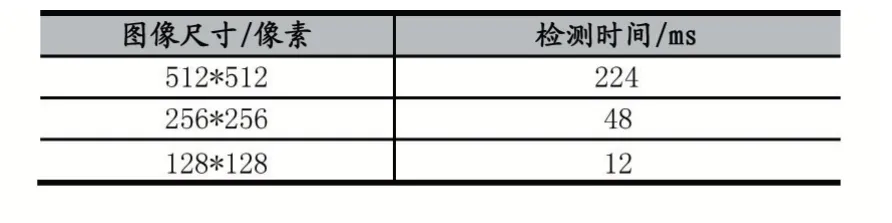
表2 相同图像内容、不同图像大小耗时
从实验结果中可以得出:选取128×128 大小的图片满足实用条件的要求。
5 结语
在这项工作中,我们使用NAO 机器人的传感器,实现了在不受控制的封闭环境中检测、跟踪和识别人员的目的,证实了所提出的方法具有有效性。虽然机器人已经能够在室内光照条件不佳的情况下实现快速、准确、鲁棒的目标识别跟踪和人脸识别,但由于实际的超市环境可能更为复杂、干扰因素更多,NAO 机器人的跟踪以及识别算法有待进一步的完善。
在未来的工作中,我们计划解决机器人真正接近用户时遇到的运动规划问题,我们可以通过使用SLAM技术或通过提供先前生成的地图来扩展工作,其中机器人可以跟踪已经访问过的位置并将所识别的人的位置保存地图上。除了改善NAO 的检测和用户跟踪功能外,我们的解决方案还具有可以移植到具有类似传感器和语音交互设施的其他机器人平台上的优势。
