多源数据融合的民航发动机修后性能预测
2019-06-26谭治学钟诗胜林琳
谭治学,钟诗胜,林琳
(哈尔滨工业大学 机电工程学院,哈尔滨150001)
民航发动机属高价值复杂装备,通过维修活动难以将其性能恢复至全新状态。为了在保证发动机修后性能的同时控制其维修成本,需要根据发动机送修性能状态、使用时间、维修工作范围等多源异构数据预测发动机的修后性能,从而支持维修方案的优化。
目前,国内外关于航空发动机维修决策支持方面的研究大体可归结为可靠性分析[1-2]、仿真分析[3-8]及数据驱动类方法[9-11]。其中,数据驱动类方法不需大量测试信息和仿真计算的支持,具有良好的实用性和泛用性。然而,现有大多数数据驱动类方法研究仅挖掘了传感器观测参数与历史决策结果的关联关系,未能充分估计各种维修工作范围对发动机的性能恢复效果,从而限制了发动机维修智能决策方法的应用效能。发动机的送修性能状态由上次大修至本次维修的传感器测量参数所组成的多元参数序列所表征,由于其具有较高的参数维度和数据量,需要对其进行特征提取以进行数据压缩,其包含工况参数和状态参数,特征提取较为困难;同时,发动机使用时间由自新使用循环 tCSN、自新使用时间 tTSN、修后使用循环tCSR、修后使用时间 tTSR所表征;维修工作范围由部件拆解0-1判定矢量表征,此三类数据结构不同且采集时间不同步,为数据融合也带来了一定困难。
为解决上述问题,本文提出了卷积自编码器(Convolutional Auto-Encoder,CAE)与极端梯度提升(eXtreme Gradient Boosting,XGBoost)算法相结合的发动机修后性能预测方法。首先,分析多元参数序列中参数排序变化对卷积自编码器特征提取过程的影响,提出规整参数排序的有效指标;其次,采用CAE对顺序规整后的修前多元参数序列和维修工作范围数据分别进行处理,通过最小化重构误差提取出两部分数据的对应特征;最后,将多元参数序列特征、维修工作范围特征、使用时间特征组成合成特征,训练XGBoost模型以预测发动机的修后性能并分析各影响因素重要性,并将所提方法应用在发动机机队的修后性能预测中以测试其效果。
1 民航发动机修后性能预测问题分析
1.1 CAE和 XGBoost
CAE是将卷积神经网络的卷积和池化操作与自编码器的无监督学习原理相结合的特征提取算法,一般由编码网络和解码网络所组成,如图1所示。其中,编码网络通过将成组滤波器与原始信号X做卷积操作得到滤波信号,而后通过池化操作获取原始信号的压缩特征χ;解码网络则通过反卷积操作将特征还原为与原始信号具有相同大小的重构信号Xrec。CAE通过最小化Xrec与X之间的重构误差以确保特征χ能够有效表达原始信号X所包含的信息。
XGBoost算法[12]是陈天奇所开发的一种增强的梯度提升决策树算法。梯度提升决策树算法[13]利用决策树加法模型和前向分布算法实现对拟合残差的逐级缩减,而XGBoost在此基础上采用了二阶泰勒展开、L1和L2正则、权重缩减、列抽样、并行处理等方法进一步提升了梯度提升决策树算法的执行效率、预测精度和泛化能力,同时能够对各影响因素的重要程度进行评估。
1.2 问题分析
目前,国内外航空公司多采用排气温度裕度TEGTM来表征发动机的性能。TEGTM是保证发动机不超温的关键监测参数,且会随发动机性能的衰退缓慢下降,因而在此被当作表征发动机修后性能的待预测目标参数。图1给出了发动机修后性能预测整体流程。可以看出,本文方法首先利用CAE对多元参数序列Xobs进行数据压缩以得到有效特征χobs,而后利用CAE分别对发动机风扇(FAN)、核心机(CORE)、低压涡轮(LPT)单元体的维修工作范围数据 XFAN、XCORE、XLPT进行特征提取以得到特征 χFAN、χCORE、χLPT。
单元体维修工作范围数据结构如图2所示。
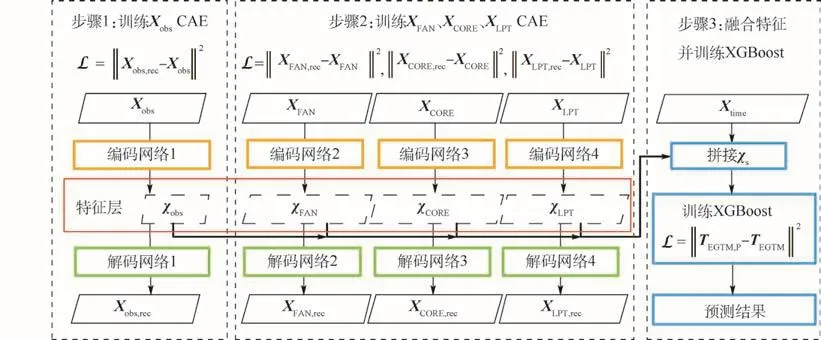
图1 发动机修后性能预测整体流程Fig.1 Overall flowchart of engine post-repairing performance prediction
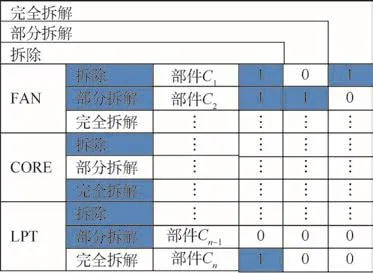
图2 单元体维修工作范围数据结构示意图Fig.2 Schematic of data structure of component maintenance workscope
根据对发动机的维修经验及维修手册可知,发动机单元体及部件的拆解情况能够近似等价地表达其具体执行的维修工作范围。该拆解情况按照单元体/部件两层结构划分,具有0-1判定矢量的数据形式。图中灰色/无色色块表示各单元体及下属部件的拆解选项(拆除、部分拆解、完全拆解)的选定/未选定情况。其中部分拆解与完全拆解选项具有互斥关系。
上述步骤所获取的 χobs、χFAN、χCORE、χLPT最终与使用时间矢量Xtime所包含的特征χtime进行矢量串联以得到合成特征 χs,训练 XGBoost模型并预测发动机修后 TEGTM。其中,χs=[χtime,χFAN,χCORE,χLPT,χobs],χtime为 Xtime进行归一化后所得到的特征矢量,Xtime=[tTSN,tCSN,tTSR,tCSR],其中,下标TSN表示自新使用时间,CSN表示自新使用循环,TSR表示自修使用时间,CSR表示自修使用循环。
鉴于业内通常采用排气温度裕度TEGTM评估发动机性能,同时由于TEGTM换算模型因为自身精度及机体模型漂移的作用会受到工况因素(低压转子转速N1、进口总温 T1、飞行高度ZALT、高压转子转速 N2)的影响,本文采用包含 N1、T1、ZALT、N2、TEGTM的多元参数序列表征发动机送修性能状态,并采用具有二维结构的CAE对其进行特征提取。经大量实验验证,二维卷积结构比一维卷积结构对多元时间序列的处理精度更高[14],且序列中参数的排序对特征提取结果的优劣具有较为明显的影响[15]。而若采用穷举方式进行参数排序规整,则对于M维序列需要进行M!次全流程运算,计算量显然不可接受。为此,提出采用条件熵增长因子作为参数排序的规整指标。
2 基于条件熵增长因子的参数排序规整
从算法结构上来看,二维CAE的高效图像处理能力得益于其采用卷积操作对近邻像素间关联分布特性进行提取,这与从多元参数序列中相邻参数之间的联合分布特性变化模式中提取发动机衰退模式信息的过程相类似。因此,可借鉴条件熵和交叉熵公式来构建参数排序规整指标。其中,基于任意2个参数X、Y的联合概率分布表达式为
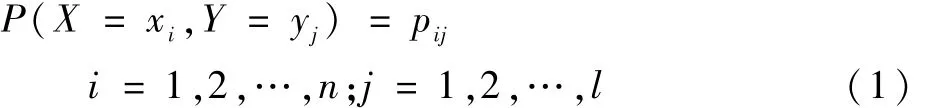
定义参数Y与X之间的条件熵为
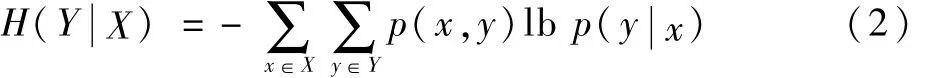
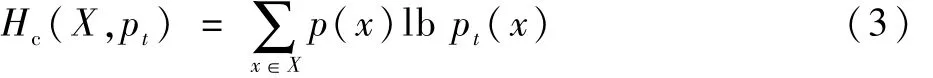
式中:Hc(X,pt)为交叉熵;p(x)为 X的初始分布;pt(x)为第t个发动机使用循环后X的分布。
将式(2)与式(3)相结合,得
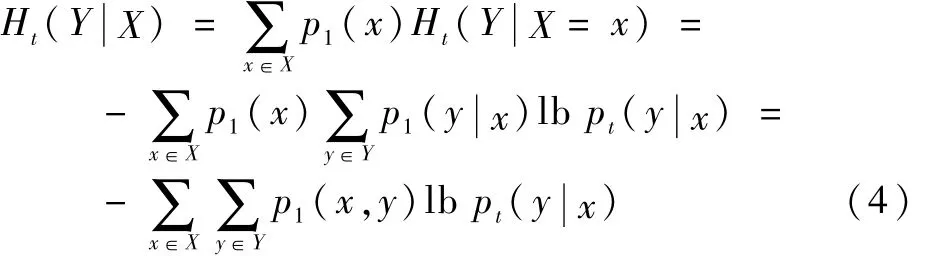
式中:p1(x,y)为参数 X、Y在[1,τ]时段内的联合概率密度分布函数,τ为一次采样中所包含的时间点的个数,可视为采样窗口宽度为参数Y对参数X在[t,t+τ-1]时段内的条件概率分布。由于发动机的衰退速度比较缓慢,可假设X、Y在[t,t+τ-1](t∈[1,T-τ+1])时间段内服从二元正态分布,并通过参数之间的协方差计算pt(x,y)。由此,给出参数排序的规整过程如下:
步骤1 将参数归一化,并得到所有Xobs样本的归一化合并矩阵 U(obMsN)×T。其中,N为样本总数,T为样本长度。
步骤2 获取参数的全部排列顺序集合,Λ={Λs,s=1,2,…,M!}。
步骤3 将Uobs参数按照Λ当中的排列方式进行全排列得到参数矩阵集合{Uobs(Λs),s=1,2,…,M!}。
步骤4 创建指标矩阵集合{Hs,s=1,2,…,M!},并利用如下伪代码进行参数排序规整指标计算:
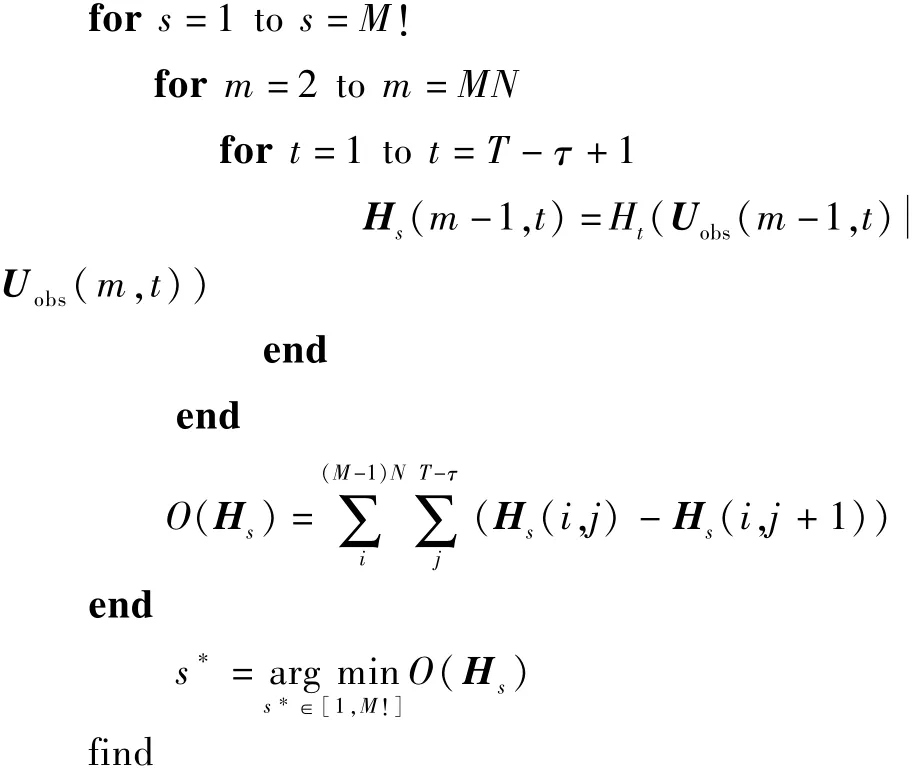
其中,O(Hs)为条件熵增长因子,为本文所提出的参数排序规整指标。根据式(1)~式(4)可知,条件熵增长因子是一个量化不同排序下相邻工况参数和性能参数之间的联合分布随发动机衰退出现的变化的大小程度的指标。当条件熵增长因子(通常为负值)较小时,说明该种参数排序方式使得发动机的性能衰退模式信息表达更为明显,由此降低了特征提取难度。
步骤5 按照 Λs*对 Xobs当中的参数顺序进行规整并作为CAE的输入。
3 发动机修后性能预测实验
3.1 实验数据及实验安排
为了验证本文方法的有效性,收集了某航空公司的91次发动机维修案例作为实验样本。为了使所有的Xobs具有相同的长度,采用等间隔采样的方式,从各样本当中选取了100个采样点。发动机的维修工作范围部分数据在图3中给出,其中灰色色块代表1,无色色块代表0,可参照图2中给出的数据结构进行解读。每个单元体的拆解数据矢量包含了其自身的拆解情况及其下属各部件的拆解情况。为了与本文方法进行对比,还分别利用堆叠自编码器(Stacked Auto-Encoder,SAE)和一维卷积自编码器(1-Dimensional Convolutional Auto-Encoder,CAE-1D)对 发 动 机 修 前TEGTM单维序列进行特征提取以作为发动机送修性能状态的表征,而其余特征提取过程和预测过程与本文中方法相同。此两类方法分别记为SAE-1D-XGBoost和 CAE-1D-XGBoost,本文方法则记为 CAE-XGBoost。为了使 SAE-1D-XGBoost和CAE-1D-XGBoost的预测结果达到最优,其所包含的SAE被设计为5层结构,特征层当中的特征值个数分别被设为5、10、15、20以进行网络结构寻优;而 CAE-1D-XGBoost与 CAE-XGBoost具有13层网络结构,其编码网络含有3个卷积层和最大池化层以及1个特征层,解码网络含有由3个上采样层和卷积层,其中CAE-1D-XGBoost特征层当中的特征值个数又分别被设为10、20以优化网络结构,而 CAE-XGBoost的特征层则包含25个特征值。对于发动机的维修工作范围数据,3种方法均选用 CAE-1D-XGBoost对 XFAN、XCORE、XLPT分别进行特征提取,特征层所包含特征值的个数皆为5。此外,为了验证参数排序对 CAEXGBoost预测精度的影响,本文对参数的所有5!种排序下的预测精度进行了测试并记录了误差均值。每个方法当中,训练集和测试集均随机划分且样本容量比值为71:20。3种方法皆进行10次预测实验,且记录各方法在此10次实验当中对发动机修后 TEGTM的预测均方差(Mean Squared Error,MSE)的均值和方差以评估方法精度和稳定性。
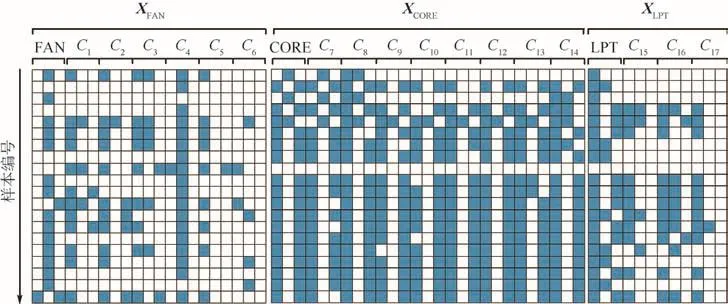
图3 航空发动机维修工作范围部分实验数据Fig.3 Partial data of aircraft engine maintenance workscope data used for experiment
3.2 实验结果及讨论
表 1给出了 SAE-1D-XGBoost、CAE-1D-XGBoost、CAE-XGBoost对单维TEGTM参数序列和多维参数序列的重构精度,包含了预测均方差及平均相对误差(Average Relative Error,ARE)的均值和方差,所有方法的最优输出结果以下划线标出。
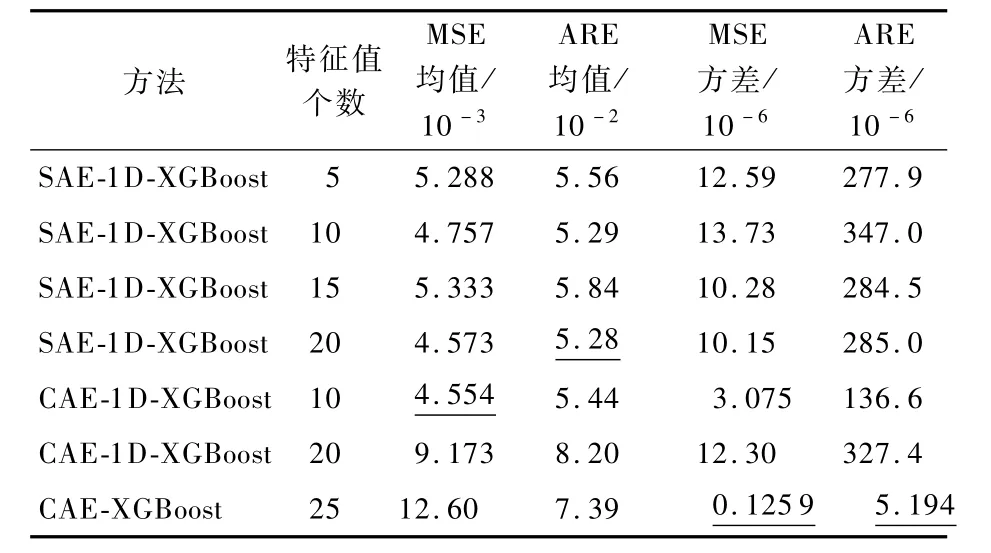
表 1 SAE-1D-XGBoost、CAE-1D-XGBoost、CAE-XGBoost对参数序列的重构误差Tab1e 1 Reconstruction error of parameter series by SAE-1D-XGBoost,CAE-1D-XGBoost and CAE-XGBoost
从表1中可以看出,具有10个特征值的CAE-1D-XGBoost的重构 MSE的均值最低,而具有20个特征值的 SAE-1D-XGBoost的重构 ARE均值最低,说明 CAD-1D-XGBoost和 SAE-1D-XGBoost的特征提取能力较为接近。与之相比,CAE-XGBoost重构精度最低,然而其MSE和ARE的方差却最低,说明其具有最佳的稳定性。为了对 SAE-1D-XGBoost和 CAE-1D-XGBoost的特点详加对比,图4、图5分别给出了网络结构最优情况下 SAE-1D-XGBoost(20个特征值)和 CAE-1DXGBoost(10个特征值)对某台发动机 TEGTM单维序列样本的重构误差曲线。
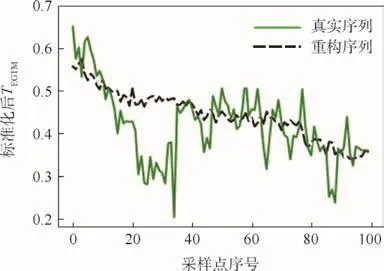
图4 SAE-1D-XGBoost对T EGTM序列的重构精度Fig.4 Reconstruction precision of T EGTM series by SAE-1D-XGBoost
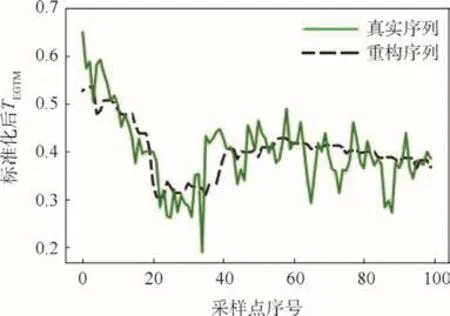
图5 CAE-1D-XGBoost对T EGTM序列的重构精度Fig.5 Reconstruction precision of T EGTM series by CAE-1D-XGBoost
观察图4可以发现,SAE-1D-XGBoost能够较好地重构TEGTM序列的缓变成分,却未能捕捉到突变成分。而图5中CAE-1D-XGBoost虽然在局部的重构精度低于SAE-1D-XGBoost,却在整体上比较准确地重构了整条曲线。这说明CAE-1D-XGBoost所提取出的数据特征的表达能力整体上要优于 SAE-1D-XGBoost所提取出的数据特征。图6给出了某台发动机的各单元体维修工作范围矢量以及 CAE-1D-XGBoost的重构矢量,图中数据以FAN—CORE—LPT进行排序。
由图6可知,重构矢量能够较好地逼近原始矢量,且机队内所有样本的FAN、CORE、LPT单元体维修工作范围矢量的重构误差(ARE)分别为0.112 3、0.105 2、0.149 8,说明所提取的维修工作范围特征对原始数据的表达能力良好。
表2给出了3种方法在多次预测中对发动机修后TEGTM的预测MSE和ARE的均值,其中最优预测结果以下划线标出。CAE-XGBoost的预测误差与本文所提出的条件熵增长因子的相关性在图7中给出,而3种方法对发动机修后TEGTM的预测误差(一次预测)在图8中给出。由图7可知,CAE-XGBoost在所有120种参数排序下的预测误差极大值与极小值相差较大,而条件熵增长因子与预测误差(MSE)的 Pearson相关系数达0.936 7,说明了利用条件熵增长因子对参数排序进行规整的必要性和有效性。通过计算条件熵增长因子,CAE-XGBoost选择了 TEGTM—N2—ZALT—N1—T1这一排序来构造多元参数序列,在该种排序下获得了所有方法中对发动机修后TEGTM的最高预测精度(见图7),且没有出现粗大误差。
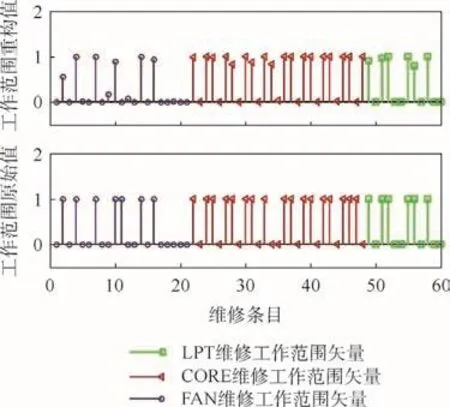
图6 各单元体维修工作范围原始值矢量及CAE-1D-XGBoost重构矢量Fig.6 Original component maintenance workscope vector and reconstructed vector by CAE-1D-XGBoost
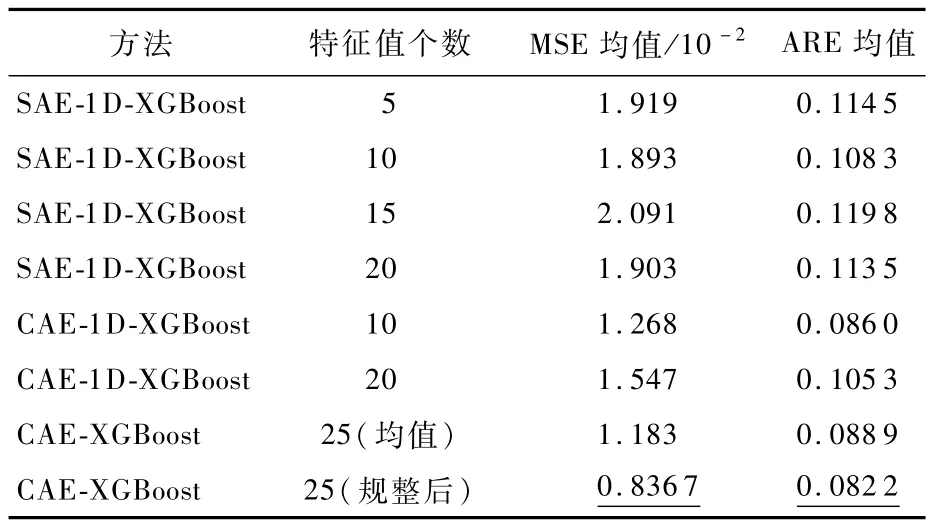
表 2 SAE-1D-XGBoost、CAE-1D-XGBoost、CAE-XGBoost对发动机的修后T EGTM预测误差Tab1e 2 Prediction error of engine post-repairing T EGTM by SAE-1D-XGBoost,CAE-1D-XGBoost and CAE-XGBoost
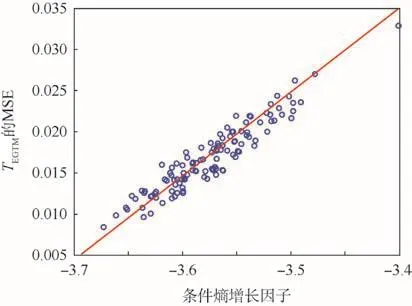
图7 修后T EGTM预测误差与条件熵增长因子的相关性Fig.7 Correlation of prediction error of post-repairingT EGTM and condition entropy increasing factor
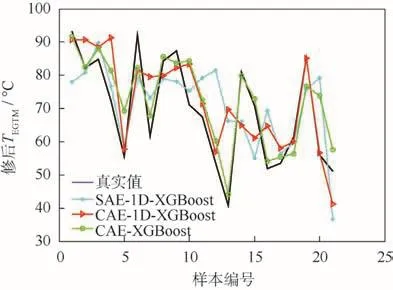
图 8 SAE-1D-XGBoost、CAE-1D-XGBoost、CAE-XGBoost对发动机的修后T EGTM预测误差Fig.8 Prediction error of engine post-repairing T EGTM by SAE-1D-XGBoost,CAE-1D-XGBoost and CAE-XGBoost
与此同时,对比表1结合可以看出,当利用TEGTM单维序列表征发动机送修性能状态时,TEGTM预测误差与参数序列重构误差具有较强相关性(SAE-1D-XGBoost和 CAE-1D-XGBoost的预测MSE与单参数序列重构MSE的Pearson相关系数分别为0.6747和0.9881),说明对传统的基于单维参数序列的数据融合预测方法而言,保证特征的表达能力对预测精度至关重要。
相对于利用多元参数表征发动机送修性能状态的 CAE-XGBoost来说,二者的 Pearson相关系数仅为0.103 6;与此同时,CAE-XGBoost对参数序列的重构误差大于 SAE-1D-XGBoost和 CAE-1D-XGBoost,而对修后 TEGTM的预测误差却低于SAE-1D-XGBoost和 CAE-1D-XGBoost,说明采用多元参数序列表征发动机的送修性能状态虽然提升了特征提取的难度,却因考虑到了多元参数之间的协同变化过程,使得提取出的数据特征能够更为准确地表征发动机的送修状态。
表3给出了XGBoost在3种方法中对各类影响因素对发动机的修后TEGTM的重要性占比评估结果。为了保证结论的可靠性,本文又进一步将3种方法的结论进行综合,计算公式为
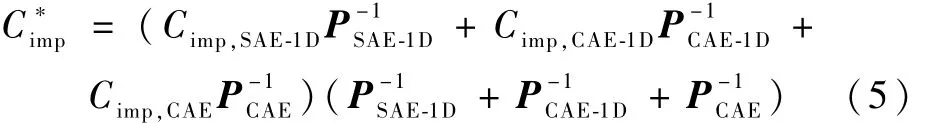
式中:Cimp为3种方法所给出的各影响因素对发动机修后TEGTM重要性占比;P为各方法的预测均方差。
综合后的影响因素重要性占比在图9中给出。可以得知,3类影响因素对发动机修后性能的重要性排序为:使用时间>送修性能>维修工作范围。与此同时,3类影响因素的重要性占比相互之间较为接近,分别为39.35%、32.32%、28.34%。说明发动机维修计划应该均衡考虑三方面因素,在保证修后性能达标的情况下,尽量延长发动机的使用寿命。
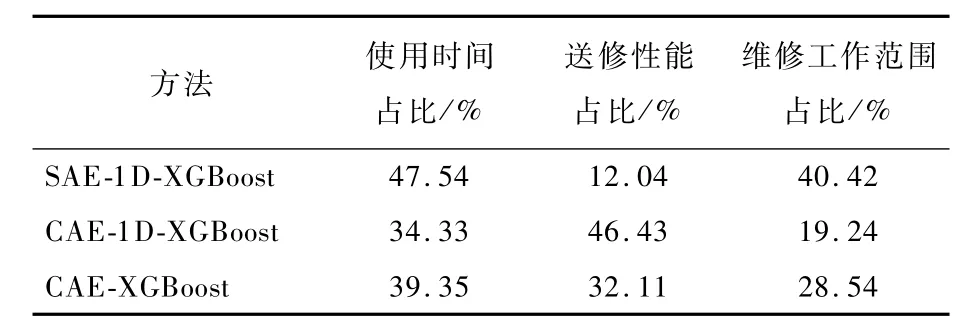
表3 不同方法中影响因素对发动机修后T EGTM的重要性占比Tab1e 3 Percentage of inf1uentia1e1ement importance to engine post-repairing T EGTM in different methods
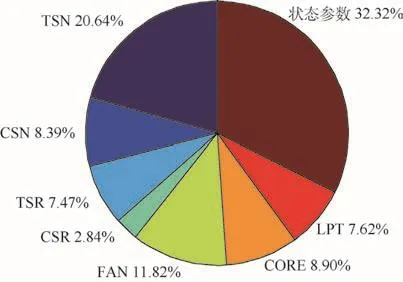
图9 不同方法综合后各影响因素对发动机修后T EGTM重要性占比Fig.9 Percentage of influential element importance to engine post-repairing T EGTM synthesized by different methods
4 结 论
针对航空发动机修后性能预测过程中的多源异构数据融合问题,本文提出了条件熵增长因子作为发动机的多元传感器参数序列的排序规整指标,利用CAE对规整后的序列进行特征提取和特征融合,并训练 XGBoost算法预测发动机的修后排气温度裕度和评估各类影响因素的重要性。本文研究主要解决了下列问题:
1)采用合成特征训练XGBoost算法,有效融合了多源数据信息,获得了较高的发动机修后性能预测精度。
2)提出了条件熵增长因子作为多元参数序列中的参数排序规整指标,提升了算法效率与精度,同时量化了各类影响因素对发动机修后性能的重要程度。
