基于词向量和多特征语义距离的文本聚类算法
2019-06-24张贯虹
张 弛 张贯虹
(合肥学院计算机科学与技术系, 合肥 230601)
文本聚类是指根据文本的内在联系(如语义和结构信息),将无类别标注的文本聚合成不同类别集合的过程。此过程是一个无监督的学习过程,事先不需要经过大量的训练,也不需要对文本的类别进行标注。常见的文本聚类方法有基于词频统计的方法、基于主题模型的方法、基于知识库的方法和神经网络的方法,等等。
文献[1-3]介绍了基于词频统计的方法,这种方法具有方便、快捷的优点,但在实际文本间语义相似度计算应用中,存在特征词向量维度高、数据稀疏、忽略低频词以及缺乏语义信息等问题。文献[4][5]介绍的基于主题模型的方法,能将高维的特征词向量空间转换为低维的语义主题空间,解决了特征词向量空间维度高、缺乏语义的问题,但这类方法都是假设数据服从指数分布。实际上,数据分布并不一定完全服从指数分布。另外,这类方法偏向于从高频的数据中归纳语义,忽略了低频词的影响。文献[6-8]介绍的基于知识库的方法,能够解决文本表示特征稀疏、特征词语义缺失的问题,但由于受限于知识库的更新速度,也会影响最终文本聚类的效果。
针对上述文本聚类算法存在的问题,借鉴神经网络算法,现提出一种基于Word2Vec工具的词向量表示方法和多特征语义距离的文本聚类算法(标记为M-W2-KS)。首先,使用基于神经网络的Word2Vec工具所依赖的Skip-gram模型训练大规模语料,得到语料库中所有特征词的词向量表征;然后,使用融合词频、词距、位置信息和词向量欧式距离的自定义多特征文本语义距离计算公式,计算文本集中的任意两个文本的相似度;最后,使用经典的K-means算法对文本集中的文本进行聚类。
1 M-W2-KS算法的基本流程
基于词向量和多特征语义距离的文本聚类,包括数据的预处理、Word2Vec词向量训练、文本间相似度计算和K-means算法聚类等环节(见图1)。
2 Word2Vec词向量训练模型
经典的空间向量模型(VSM)算法是采用独热编码(One-Hot Encoding)的方式将文本表示成向量的形式,向量的维度为文本集中包含的特征词总个数,每个向量代表一个文本。如果文本中某个特征词存在,则向量中相应位置的元素值为1;否则,元素值为0。这种表示方法没有考虑特征词之间存在语义关系,忽略了低频词,易导致文本特征表示语义缺失和维度灾难等问题。
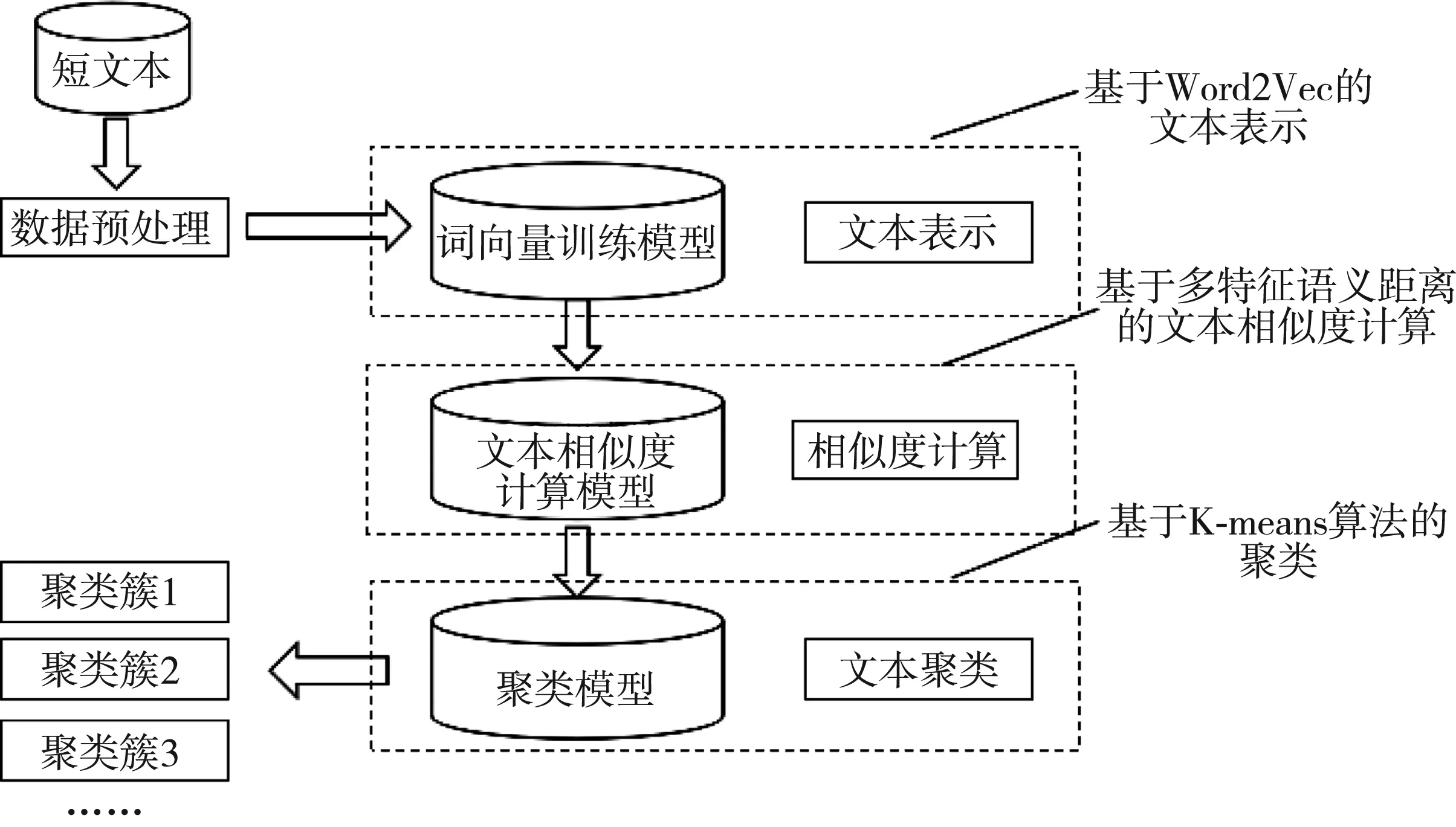
图1 M-W2-KS算法的基本流程
为了解决文本特征表示存在的语义缺失和维度灾难问题,2003年,Bengio等人提出了基于前馈神经网络的概率语言模型(NNLM)[9],其所依赖的核心概念就是词向量。该模型分为输入层、投影层、隐藏层和输出层4个层次,计算量大是它的一个缺陷。2013年,Google的Tomas Mikolov团队对该模型进行了优化,并开发了基于神经网络的Word2Vec工具。Word2Vec工具依赖于Skip-gram 模型[10]和CBOW模型[11],这两种模型都是通过训练大规模语料数据,将文本特征词映射成一个低维实数向量,有效解决了NNLM存在的问题。
我们选择Word2Vec工具的Skip-gram模型对文本进行词向量训练。该模型是基于Hierarchical Softmax构造的一颗Huffman树,能够根据当前输入的词,从大规模非标注的文本数据中预测上下文词出现的概率,即能够通过当前词语出现的概率来预测周围出现的词。根据词语在窗口中的共现原理,基于窗口滑动来计算词语间的共现概率,这样每个特征词生成的词向量中都包含了一定的文本结构信息和语义信息。
Skip-gram模型包括输入层、投影层和输出层。其中,输入层为当前特征词,词的词向量Wt∈Rm;输出为该特征词上下文窗口中词出现的概率;投影层的目的是使目标函数L值最大化。
假定有一组词序列w1,w2,…,wN,则
(1)
式(1)中:N为词序列的长度;c表示当前特征词的上下文长度(一般取5~10,效果较好);p(wj+1|wj)为已知当前词wj出现的概率下,其上下文特征词wj+1出现的概率。
通过Skip-gram模型训练得到的全部词向量,组成词向量矩阵X∈Rmn。以xi∈Rm表示特征词i在m维空间中的词向量。特征词之间的相似度,可以使用对应词向量之间的距离来衡量。两个向量之间的欧式距离,如式(2)所示。
d(wi,wj)=‖xi-xj‖2
(2)
式中:d(wi,wj)表示特征i和j的语义距离;xi和xj表示特征词wi和wj对应的词向量。d(wi,wj)的值越小,说明两个特征词之间的语义距离越小,语义越相似。
3 文本相似度计算方法
Skip-gram词向量模型保留了文本的语义信息,但没有考虑到每篇文本所独有的结构特点,忽略了特征词词频、位置和词距信息。借鉴文献[12]提出的基于语义复杂网络的文本相似度计算方法,综合考虑特征词的词频、位置和词距信息以及特征词向量欧式距离公式,提出如下涉及多个特征的文本相似度计算方法。
(3)
l(wi,wj)=(αtfij×idfi+βκ+γgij)×
d(wi,wj)
(4)
(5)
(6)
其中:Sim(D1,D2)表示任意两个文档D1和D2之间的文本相似度;|V1|、|V2|分别表示文档D1和D2中特征词的数量;l(wi,wj)表示特征词i和j之间的多特征语义距离;d(wi,wj)表示特征i和j的语义距离;pi、pj表示特征词i、j在各自文档中的权重占所有特征词权重的比列;idfi为特征词的信息熵,idfi=log(Ntfi+0.01);k为特征词位置权值,当特征词出现在标题时k=2,出现在其他位置时k=1;gij表示特征词i在文本j中首次出现到末次出现的距离权重;beginij为特征词i在文档j中首次出现的位置,lastij为特征词i在文档j中最后一次出现的位置;length(j)表示文档j的特征词序列长度;α、β、γ为不同的三类特征的权值,α+β+γ=1。
一般文本之间的相似度应当与特征词之间的相似度成正比。两个文本的相似度越高,特征词在这两个文本中出现的位置、词频、词距以及词向量之间的距离也应该越相似,两者间的重要程度差距也应该越小。将计算结果进行归一化处理,得到文本相似度计算公式:
Sim(D1,D2)=1-u-Sim(D1,D2)
(7)
式(7)中,u的取值为大于1的正数。u值越大,表明计算结果越趋近于1的速度就越快。
4 K-means算法分类流程
上述基于词向量和特征语义距离的文本聚类算法,其具体流程如下。
输入:待聚类文本集合D={D1,D2,D3,…,Dn}
输出:k个聚类文本簇
(1) 对输入的文本集合进行遍历,对每一个文本(Di)使用分词工具进行分词、去停用词等操作,得到文本特征词集合S={S1,S2,S3,…,Sm}。
(2) 使用Skip-gram模型对分词后得到的大规模语料库进行训练,得到每个特征词的词向量。
(3) 对每个文本进行特征词词频、位置和词距信息的统计和计算。
(4) 随机选择k个文本作为初始聚类质心,使用公式(4)计算每个文本与这k个聚类质心之间的距离,选择距离最短的质心作为自己的质心。
(5) 依次计算具有同一个质心的文本到其他质心的距离,选择距离最短的质心作为该文本新的质心。
(6) 循环执行步骤(4)(5),直到质心不再变化。
5 实验与结果分析
5.1 实验数据与结果评价指标
使用“中文维基百科”作为基本的训练语料,选取复旦大学李荣陆课题组提供的中文语料作为测试数据集。实验中,选择了语料库中的计算机、空间、环境、政治、艺术、经济、体育等7个类别的新闻文本。
在评价算法的分类效果时,通常使用综合评价指标F-measure值作为评价依据,它是准确率(P)和召回率(R)的加权调和平均。在实际应用中,参数θ值通常取1,也就是最常见的F1值。F1值越大,表明分类的效果越好。定义:P=a(a+b),R=a(a+c),F-measure=(θ2+1)PRθ2(P+R),F1=2PR(P+R)。其中,a表示被正确分类的文档数量,b表示被判定为属于某个类别而实际却不属于该类别的文档数量,c表示被判定不属于某个类别而实际却属于该类别的文档数量。
5.2 实验设置与结果分析
使用64位Win7操作系统。CPU是Intel(R) Core(TM) i5-7200U @2.50GHz 2.60GHz,内存为8G,开发工具为jupyter notebook下的Python3.7。使用北大开源分词包pkuseg-python,用“四川大学机器学习智能实验室停用词库”过滤停用词,以“中文维基百科”作为训练的语料库。每个类别中,选择 1 000篇文本作为实验数据。词向量的维度选择为300。语料库中没有出现的词,不参与最终文本语义距离的计算。
为了验证实验的有效性,引入文献[13]所构建的基于词频的方法(标记为T-VSM)、文献[14]所构建的基于主题模型的方法(标记为LG-LDA)和文献[15]所构建的基于知识库的方法(标记为 YX-BTM)进行对比实验。参数α、β、γ分别设置为0.37、0.35、0.28。由于K-means算法的聚类结果受初始质心的影响,这里使用10次聚类实验的平均值作为最终的结果。每次聚类实验中,K-means算法的迭代次数设置为1 000次。
实验结果显示,在7个文本类别上的平均准确率(P)、召回率(R)和F1值,由T-VSM、LG-LDA、YX-BTM到M-W2-KS,总体上是呈递增趋势。其中,P的平均值依次为0.70、0.76、0.76、0.87,R的平均值依次为0.67、0.74、0.76、0.83,F1的平均值依次为0.69、0.75、0.79、0.85(见表1)。
LG-LDA算法的分类效果优于T-VSM算法,这是因为T-VSM算法只是对特征词的词频进行统计,没有考虑非结构化文本中隐藏的主题信息。基于HowNet的BTM模型,由于扩充了文本特征词的语义信息,避免了聚类结果中质量差的文本的干扰,聚类结果又优于LG-LDA算法。M-W2-KS算法使用“中文维基百科”作为训练语料库,扩充了文本特征词的语义信息,并使用Skip-gram模型对词进行词向量的训练,充分利用文本的上下文,融合了词频、词距和位置信息来计算文本间语义相似度,聚类效果又优于YX-BTM算法。图3为各个文本类别F1值的折线图。

表1 四种算法在各数据集上的F1值

图3 不同算法在各类别中的F1值比较
从最终多个类别数据的聚类实验结果来看,我们提出的M-W2-KS算法要比其他几种算法的聚类效果更好。基于词向量和多特征语义距离的 M-W2-KS算法,不但能够使特征词向量的表征具有上下文语义和结构信息,保证特征词语义的集中,也能够对文本进行特征降维处理,避免发生维度灾难,能够有效提高文本相似度计算结果的精确性,保证聚类结果的准确性。
6 结 语
基于词向量的文本表示和多特征语义距离的文本聚类算法,利用词向量的性质,克服了传统文本特征向量表示方法存在的问题(如数据稀疏和网络词汇更新速度快等因素对文本聚类结果的影响);引入融合特征词词频、词距和位置的权重,自定义多特征语义距离计算公式,改进了文本间的相似度计算方法。实验结果表明,运用这种算法,能够使聚类结果更加准确,可以提升聚类效果。
