基于卷积神经网络的带遮蔽人脸识别
2019-06-22徐迅,陶俊*,吴瑰
徐 迅,陶 俊*,吴 瑰
(江汉大学 a.数学与计算机科学学院;b.工程训练中心,湖北 武汉 430056)
0 引言
作为模式识别和图像处理领域成功的应用之一,人脸识别在过去20年里一直都是研究热点。人脸识别的普遍性、可采集性与被采集者的可接受性较高,具有方便友好、易于接受、不易伪造等一系列优点。随着技术的发展,人们对公共安全更加关注,对人脸识别这一技术也有了新的要求。在实际生产生活中采集到的人脸图像不一定是完整清晰的,对光照差异、面部表情变化、有无遮挡物等干扰因素的鲁棒性是判定一个人脸识别系统好坏的标准之一。
传统的人脸识别方法[1-3]有基于线性回归分类(linear regression classification,LRC)的方法。LRC 能很好地识别无遮挡的人脸,识别率良好,但是在加入遮挡等干扰因素下,效果不佳。基于稀疏表示分类(sparse representation-based classifier,SRC)的人脸识别方法原理在于人脸的稀疏表示是基于光照模型。SRC 有一个很强的假设条件:所有的人脸图像必须是事先严格对齐的;否则,稀疏性很难满足。换言之,对于表情变化、姿态角度变化的人脸都不满足稀疏性这个假设。所以,经典的SRC 很难用于真实的应用场景。
近年来,神经网络应用于人脸识别成为研究热点。其采用的方法有基于受约束的局部神经域[4](constrained local neural field,CLNF)和卷积神经网络相结合的方法[1]。CLNF 方法实际上是对受约束的局部模型(constrained local models,CLM)的创新,主要研究对人脸特征点的定位算法。相对于传统的CLM 等算法,拟合速度更快、准确率更高,能够使人脸识别技术更加精确,具有更大的优势。但是,当人脸在光照、噪声、背景等环境因素较为恶劣的情况下,CLNF 算法虽然能在特征点定位方面保持一定的精确性,但对特征点的搜索和特征点拟合的过程耗时较长。深度卷积神经网络框架VGG-NET 是Oxford 大学计算机视觉组和DeepMind 公司的研究人员在2014年联合开发的一种深度神经网络,其识别率相较于过去的网络结构有一定的提升。还有如GoogleNet 和ResNet 等深度神经网络框架性能优异,相较于传统的方法均有相当明显的优势,其在如手写数字、车牌识别等方面已经有很好的应用。
本文采用深度卷积神经网络Inception-ResNet-v1[5]框架进行人脸识别。Inception-ResNet-v1 框架是结合了GoogleNet 和ResNet 发明的,克服了传统神经网络参数太多,容易过拟合;而网络庞大,计算复杂度大,难以应用;网络越深,梯度越往后穿越容易消失(梯度弥散),难以优化模型等缺点。其性能相较于过去的卷积神经网络模型有较大的提升。对遮挡、表情变化、姿态角度变化等干扰因素具有鲁棒性。可实现复杂条件下的人脸识别。
1 模型结构
图1 为系统的模型结构[6-7],本文模型采用的是卷积神经网络模型的基本结构。每个模块功能如下:
1)Batchs:输入的人脸图像样本,这里的样本是已经过人脸检测找到人脸并裁剪到固定尺寸的图片样本。
2)DEEP ARCHITECTURE:深度学习框架,实验采用的是Inception-ResNet-v1 网络结构。
3)L2:特征归一化,防止模型过拟合。
4)EMBEEDING:嵌入层。
5)Triplet Loss:三元组损失函数。

图1 系统结构Fig.1 System structure
模型的作用是将人脸图像X嵌入到d维度的欧几里得空间。与一般的深度学习架构不一样的是,传统的深度学习框架一般都是Double Loss 或者Single Loss,而本文采用3 张图片输入的损失函数Triplet Loss 直接学习特征间的可分性:相同身份之间的特征距离要尽可能小,而不同身份之间的特征距离要尽可能大。
1.1 Inception-ResNet-v1的网络结构
模型采用的结构是卷积神经网络(CNNs)的一种。CNNs 本质是一个前向反馈神经网络,与多层感知器的最大区别是网络前几层由卷积层和池化层交替级联组成,通过神经元平面上神经元的权重共享,不同的卷积核提取不同的特征,有效减少了卷积神经网络训练过程中的参数数量,降低了运算复杂度。
模型采用Inception-ResNet-v1 网络结构[8-15],该结构结合了ResNet 与GoogleNet。图2 为网络结构主体,之后连接一个Stem 结构。Stem 用于对进入Inception 模块前的数据进行预处理。Stem 后用了3种共20 个Inception-ResNet 模块,模块中添加了residual connection 模块,residual connection 模块的作用是加速网络收敛,使网络的训练速度加快。模型中3 种Inception 模块间的Reduction 模块起到池化层的作用,使用了并行的结构来防止bottleneck 问题。

图2 Inception-ResNet-v1 网络结构主体Fig.2 Structure of Inception-ResNet-v1
1.2 损失函数
模型采用的损失函数为Triplet Loss[3],是根据3张图片组成的三元组(Triplet)计算而来的损失(Loss)。其中,三元组是由Anchor(a)、Negative(n)、Positive(p)组成。设单个个体的图像为,该个体的其他图像为,其他个体的图像为。由于在图像中同一类人脸图像的距离要小于不同类人脸图像的距离,因此有优化函数不等式为:
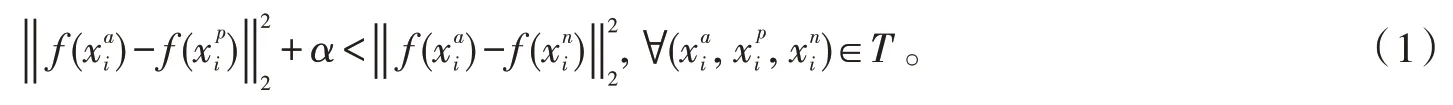
根据不等式(1),可以得出模型损失函数:

损失函数的意义在于:求最小化(类内距离-类间距离+边际)。其中表示类内距离表示类间距离,α是一个常量。优化过程就是使用梯度下降法使得损失函数不断下降,即类内距离不断下降,类间距离不断提升。
1.3 欧式距离算法
模型在分类识别模块采用的是欧式距离算法,欧式距离算法的核心是:设图像矩阵有n个元素(n个像素点),用n个元素值(X1,X2,…,Xn)组成该图像的特征组。特征组形成了n维空间,特征组中的特征码即每一个像素点构成了每一维的数值。在n维空间下,两个图像矩阵各形成了一个点,然后利用(3)式计算图像间的距离,

模型通过欧式距离法计算两图片间的距离,其距离的范围在[0,4]之间,因此相同的图片间的距离为0。而同类图片之间的距离要小于不同类图片间的距离,因此可以通过判断图像间距离的远近来对图像进行分类。
2 程序设计
本文程序在TensorFlow 框架下采用Python 语言实现。程序分成两大部分,分别为训练部分和分类部分。图3 为训练部分的程序流程图。首先载入图片训练集数据,然后检测图片中的人脸,剪辑图片,剪辑的大小为160*160。启动网络模块,输出结果通过L2 正则范数进行归一化,之后通过损失函数计算损失,校正参数,最后输出训练集模型。
图4 为分类程序流程图。首先载入图片,之后载入训练模型。对载入的图片进行预处理。计算两图片间的欧式距离dist。根据训练集图片间的距离得出区分图片间的最佳距离阀值。根据得出的阀值对测试集图片进行分类,计算模型的识别率。
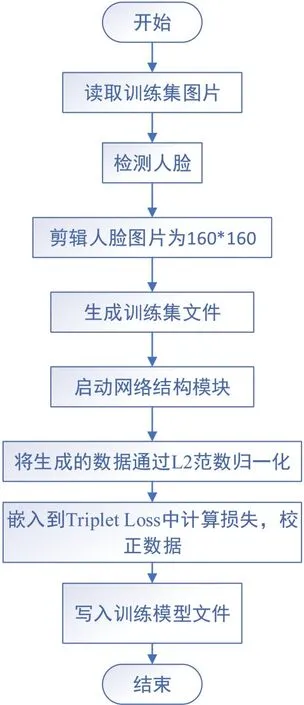
图3 训练程序流程图Fig.3 Flow chart of training program

图4 分类程序流程图Fig.4 Flow chart of classification program
3 实验数据与测试
3.1 实验数据和实验参数
为验证本文模型的性能,实验通过摄像头采集图片结合LFW 数据集制作训练集。随机选取10 000张图片作为训练集,模型训练的学习率为0.1,共学习500 轮,每轮的大小为1 000。以图5 为基准图制作带遮挡干扰因素的人脸识别测试集。如图6 所示,从左往右第一排分别为嘴部遮挡、眼部遮挡和眼部嘴部同时遮挡的人脸关键特征信息实验图共3 组,每组包括不同人、性别和年龄段分别有100张。第二排为遮挡率在10%左右,20%左右和30%~45%之间的人脸图片,遮挡部位随机分布,每组各100 张。

图5 基准人脸图Fig.5 Benchmark of experimental human face

图6 人物图像遮挡干扰添加示意图Fig.6 Diagrammatic sketch of figure image with occlusion interference
3.2 在特定条件下添加遮挡因素的实验
为验证模型在脸部关键信息如眼部和嘴部被遮挡的情况下模型的识别率,实验通过在测试集图片的脸部关键部位如眼部和嘴部添加遮挡测试模型的识别率。如表1 所示,进行3 组实验,每组测试集图片各100 张。模型在眼部被完全遮挡的情况下其识别率为98.8%;在嘴部被遮挡的情况下其识别率为98.6%;当眼部和嘴部同时遮挡时,识别率为96.9%。

表1 不同遮挡部位的识别率Tab.1 Recognition rates with different occlusion parts of face
为验证模型在不同遮挡率下的识别率,实验通过在测试集上添加遮挡率不同的干扰因素。如表2所示,模型在没有遮挡的情况下识别率为99.2%,在遮挡10%~20%的情况下,识别率为98.6%。在遮挡30%~45%的情况下模型的识别率为96.9%。

表2 不同遮挡率下模型的识别率Tab.2 Recognition rates of models under different occlusion rates
3.3 数据验证与实验分析
实验通过摄像头采集图片结合LFW 数据集制作扩充测试集测试其准确率。样本数为4 234,样本包括不同人种和性别。实验的遮挡率为20%~30%,遮挡均为眼部和嘴部等人脸关键信息,测得模型的识别率为98.2%。因此可以得出,在遮挡率在20%~30%的干扰因素下,模型对不同人种、不同年龄层次、不同性别仍可以有很好的识别率。
实验选取的相同人物图片存在时间年龄差异,不同人存在性别、人种、年龄等的差异,并且均添加了针对人脸关键特征信息遮挡的干扰因素,从实验可以看出,虽然在添加了遮挡的干扰因素下,模型的识别率有所下降,但是其在20%~30%左右的遮挡率下识别率为98.2%。
3.4 与其他模型的性能对比
如表3 所示,实验的测试集共4 234 张图片,测试SRC 和LRC 算法和本文算法在添加20% ~30%左右的遮挡干扰因素下的识别率,测得本文算法识别率可以达到98.2%,具有一定的实际应用价值。而SRC 和LRC 算法的识别率却并不如意。由此可以得出结论,相比于其他算法,在遮挡因素对模型进行干扰的情况下,没有使模型失去稳定性,仍可以很好地区分出不同人的人脸,并且识别率较高。综上所述,相比于传统算法而言,本文算法在带遮挡的人脸识别问题上更具有实用性。

表3 在遮挡率为20% ~30%时不同算法的识别率Tab.3 Recognition rates of different algorithms when the occlusion rate is 20%-30%
4 结语
本文的模型基于卷积神经网络并且损失函数采用Triplet Loss,直接学习特征间的可分性:相同身份之间的特征距离要尽可能的小,而不同身份之间的特征距离要尽可能的大。模型通过大量图片进行训练与测试,20% ~30%左右的遮挡干扰因素下人脸识别率为98.2%。验证了模型在遮挡等的干扰因素下,仍能准确地对人脸进行识别。相比于现在的其他传统的人脸识别模型,模型对遮挡等干扰因素具有鲁棒性,人脸识别率较高,具有实际应用价值,实现了在遮挡的干扰因素下的人脸识别。
