基于遮挡区域建模和目标运动估计的动态遮挡规避方法
2019-06-22张世辉何琦董利健杜雪哲
张世辉 何琦 董利健 杜雪哲
遮挡规避是目标跟踪、三维重建、物体识别、场景绘制、运动估计等视觉领域一个重要且困难的问题,受到了学者们的广泛关注[1−3].遮挡规避是指当视觉目标在某一时刻发生遮挡时,基于检测出的遮挡信息及摄像机当前观测方位信息,通过改变摄像机的观测位置和方向等参数对遮挡区域进行观测以获取遮挡区域信息的过程.
根据视觉目标的状态是静止的还是运动的,可将遮挡规避分为静态视觉目标遮挡规避和动态视觉目标遮挡规避两大类.目前,国内外学者在静态遮挡规避问题的研究方面已经取得了一定的成果.Maver等[4]通过对遮挡区域外接表面进行多边形建模,获取摄像机的下一最佳观测方位.Li等[5]提出了一种通过B样条构建物体模型计算最大信息熵的方法,将摄像机能够获取模型最大信息熵的方位作为下一最佳观测方位.Banta等[6]提出一种组合方法来确定下一最佳观测方位.Wu等[7]利用基于密度的分层轮廓拟合算法来确定下一最佳观测方位.Pito[8]利用PS(Positional space)算法从大量的观测方位中确定下一最佳观测方位.Potthast等[9]提出了一种基于遮挡环境下信息熵的不同确定下一最佳观测方位的方法.张世辉等[10]利用投影降维思想通过对遮挡区域外接表面构建小平面集合从而确定下一最佳观测方位.Doumanoglou等[11]利用稀疏自编码器对深度不变RGB-D块提取特征训练霍夫森林,并基于训练好的霍夫森林通过计算最小化期望熵来规划下一最佳观测方位.Bissmarck等[12]提出面向边界和体积的分层射线追踪算法,利用边界信息和空间信息去除冗余射线确定下一最佳观测方位.同静态遮挡规避相比,动态遮挡规避问题的研究相对较少,主要是因为遮挡区域会随着视觉目标运动而发生改变,如何合理规划摄像机观测方位对视觉目标遮挡区域进行观测是动态遮挡规避过程中的难点.为了解决动态遮挡规避问题,需要对视觉目标进行运动估计以确定运动后遮挡区域变化情况,进而移动摄像机到遮挡区域最佳观测方位下对遮挡区域进行观测.因此,动态遮挡规避的最终目标是获得摄像机一系列的下一最佳观测方位.目前可查到的动态遮挡规避方法是Zhang等[13]通过对遮挡区域建模以及计算视觉目标运动方程,从而规划摄像机的运动方式,对遮挡区域进行动态规避,但该方法存在建模速度较慢、运动估计误差较大等不足.
鉴于目前动态遮挡规避研究较少且已有方法存在的问题,本文提出一种基于遮挡区域建模和目标运动估计的动态遮挡规避方法.该方法主要目的是观测运动视觉目标的遮挡区域,因为在诸多研究和应用如运动目标三维重建、主动跟踪、动态目标识别、机器人自主作业等领域,视觉目标发生遮挡现象是一种普遍存在的情况,此时遮挡区域可能包含更多的有用信息.如果视觉系统能最大限度地观测到遮挡区域,将会有助于视觉任务的顺利完成.选取深度图像是考虑到深度图像更利于获取场景的三维信息,以便更加方便地确定摄像机的观测方位.由于动态遮挡规避过程需要兼顾实时性和准确性,因此在方法设计过程中,主要解决了两个问题:1)如何快速构建动态视觉目标遮挡区域的模型并确定遮挡区域最佳观测方位;2)如何准确地对深度图像中的视觉目标进行运动估计.针对第一个问题,提出了关键点概念,通过提取深度图像遮挡边界中的关键点,构建关键线段实现对遮挡区域快速而准确的建模,在此基础上,利用建模结果和关键线段构建遮挡区域最佳观测方位模型,以确定遮挡区域最佳观测方位.针对第二个问题,为了提高视觉目标运动估计的准确性,提出了混合曲率的概念,通过计算视觉目标深度图像对应的混合曲率矩阵,增加了图像匹配过程中提取特征点的数量,并依据筛选后的匹配点对视觉目标进行运动估计.实验结果验证了本文所提方法的可行性和有效性.
本文第1节概述所提方法的基本思想;第2节论述如何依据视觉目标深度图像遮挡信息实现动态遮挡规避过程;第3节给出实验结果及分析;第4节总结全文.
1 方法概述
1.1 动态遮挡规避问题分析
动态遮挡规避是指运动视觉目标在某一时刻发生遮挡时,以该时刻视觉目标遮挡区域为规避对象,同时对视觉目标进行运动估计,通过合理规划摄像机的运动方式,多次移动摄像机以观测到更多的遮挡区域.图1展示了动态遮挡规避过程.图1(a)为动态视觉目标在某一时刻观测方位下发生遮挡现象,阴影区域即为发生遮挡区域,为了获取到遮挡区域信息,需要规划摄像机的运动方式,使其能够跟随视觉目标并向着遮挡区域最佳观测方位运动.图1(b)为规划摄像机跟随视觉目标运动并观测遮挡区域的中间过程,随着摄像机的运动,更多的遮挡区域被观测到,遮挡区域面积也随之减少.图1(c)为摄像机到达遮挡区域最佳观测方位时的观测效果,此时遮挡区域被全部观测到,摄像机完成了动态遮挡规避的全过程.

图1 动态遮挡规避过程示意图Fig.1 Sketch map of dynamic occlusion avoidance
1.2 动态遮挡规避总体思想
基于上述对动态遮挡规避问题的分析,本文提出一种解决动态遮挡规避问题的方法.1)在摄像机当前观测方位下采集视觉目标运动前后两幅深度图像,将第一幅深度图像中的遮挡区域作为要规避的区域,同时提取遮挡边界关键点以及与其相对应的下邻接点构建关键线段,并利用关键线段对遮挡区域建模,在此基础上,利用遮挡区域建模结果和关键线段构建遮挡区域最佳观测方位模型.2)对两幅深度图像分别利用反投影变换计算图像中各像素点对应的三维坐标,并利用三维坐标计算两幅深度图像的混合曲率矩阵.3)对两幅深度图像对应的混合曲率矩阵提取特征点进行匹配,并对匹配特征点进行筛选,根据筛选后匹配点的三维信息对视觉目标进行运动估计.4)利用遮挡区域最佳观测方位模型和视觉目标运动估计方程,合理规划摄像机的下一最佳观测方位.同时,判断摄像机在相邻两次观测方位下获取视觉目标遮挡区域面积的差值是否小于给定阈值.若不小于给定阈值则移动摄像机到下一最佳观测方位下继续采集视觉目标深度图像,并利用遮挡区域最佳观测方位模型和新的运动估计方程重新规划摄像机下一最佳观测方位,否则动态遮挡规避过程结束.图2展示了动态遮挡规避过程的总体流程.
2 动态遮挡规避
2.1 构建遮挡区域最佳观测方位模型
2.1.1 提取遮挡边界关键点构建关键线段对遮挡区域建模
采集视觉目标发生遮挡时的第1幅深度图像,利用文献[14−15]中的方法检测深度图像中的遮挡边界以及遮挡边界的端点.为了对遮挡区域进行快速建模,通过分析深度图像中遮挡边界点之间的位置关系,本文提出了关键点概念.其定义主要包括两部分:1)定义遮挡边界上的端点为关键点;2)如果任一遮挡边界点不为端点并且其八邻域内不存在其他关键点,则将该遮挡边界点与八邻域内全部遮挡边界点组成线段,若任意相邻线段所对应的斜率不同,那么定义该遮挡边界点为关键点.
图3展示了视觉目标Bunny在当前观测方位下的遮挡边界和遮挡边界的关键点.其中灰色点代表遮挡边界点,黑色点代表遮挡边界的关键点.
获取完遮挡边界关键点之后,即可对遮挡区域进行建模.图4展示了构建关键线段并利用关键线段对遮挡区域建模的过程.本文采用如下方式对遮挡区域进行建模:依次选取遮挡边界上的关键点mi,通过计算其八邻域内深度差值最大的点作为其下邻接点并记为,如图4(a)所示,其中黑色点代表遮挡边界上的关键点,白色点代表与关键点相对应的下邻接点.然后在三维空间中依次将遮挡边界关键点mi和与其相对应的下邻接点相连构成关键线段li,并将相邻关键线段之间所围成的空间四边形记为patchi,如图4(b),其中i为1到N−1的整数,N为关键线段个数.所有N−1个patch即为对遮挡区域的建模结果.
2.1.2 计算patch的面积、法向量和关键线段观测方向、中点
为了构建遮挡区域最佳观测方位模型,需要计算patchi的面积和法向量以确定关键线段的观测方向.利用四边形面积公式计算patchi面积,计算公式为

其中,α为patchi中对角线构成的夹角(图4(b)),Si为patchi的面积.

图2 动态遮挡规避过程的总体流程Fig.2 The overall flow of the proposed dynamic occlusion avoidance
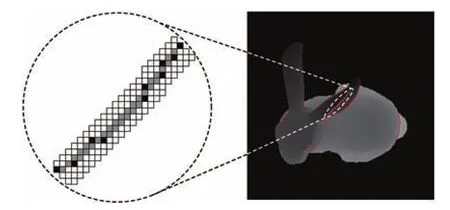
图3 Bunny的遮挡边界及其关键点Fig.3 The occlusion boundaries and key points of Bunny
由于pa tchi的法向量可能指向视觉目标内部或外部,为了保证计算出的patchi实际可观测面积的有效性,选取指向视觉目标外部的法向量作为patchi的法向量.在不考虑法向量方向的前提下,patchi法向量的VVVpatchi计算公式为

其中,µi为三维空间中从mi指向的向量,γi为三维空间中从指向mi+1的向量.为了保证patchi的法向量方向指向视觉目标外部,通过对关键点和下邻接点分析可知,当关键点位于下邻接点左(上)侧,则patchi的法向量计算公式应为µi×γi;当关键点位于下邻接点右(下)侧,则patchi的法向量计算公式应为γi×µi.
确定出patchi的法向量之后,即可在此基础上进一步计算关键线段观测方向.考虑到组成关键线段的点存在端点的情况,本文分两种情况对关键线段观测方向进行定义:1)若与关键线段li对应的点mi为端点,则定义li与其相邻关键线段围成patch的法向量为该关键线段的观测方向;2)若与关键线段li对应的点mi不为端点,则定义关键线段观测方向为

其中,VVVli为关键线段li的观测方向,wi为patchi的面积值,VVpatchi为 patchi的法向量,wi+1为patchi+1的面积值,VVpatchi+1为patchi+1的法向量,w为wi与wi+1的和,E为端点个数.同时,为了尽可能多地观测到关键线段,定义关键线段的中点ci作为观测点,计算公式为

2.1.3 构建遮挡区域最佳观测方位模型
依据上述方法完成对遮挡区域建模和获取关键线段观测方向后,下一步需要构造遮挡区域最佳观测方位模型.由于摄像机对遮挡区域内未知表面的观测可近似等价于对相邻关键线段之间围成四边形区域的观测,因此能够最大量观测到相邻关键线段之间围成的四边形面积信息的观测方位即为遮挡区域最佳观测方位.基于此思想,本文定义遮挡区域最佳观测方位模型为

其中,(xp,yp,zp)为摄像机的观测位置.β为常数,β值越大函数越精确.ϕi为将关键线段li的端点平移到当前摄像机观测中心点时,关键线段li的观测方向Vli与其中点ci到摄像机当前观测位置(xp,yp,zp)构成向量的夹角,θi为将关键线段li的端点平移到当前摄像机观测中心点时,摄像机观测方向与关键线段li所成的夹角,如图5所示.1/(1+exp(−βcos(ϕi)))是一个激活函数,当ϕi夹角在 0◦~90◦时,1/(1+exp(−βcos(ϕi))) 约等于1,即关键线段能被摄像机观测到才参与计算;当ϕi在 90◦~180◦时,1/(1+exp(−βcos(ϕi))) 约等于0,表示关键线段不能被摄像机观测到,此时关键线段不参与计算.sin(θi)为第i条关键线段的投影长度与关键线段长度的比值.Si为关键线段li与其相邻关键线段围成patch的面积,当关键线段li对应的点mi为端点时,Si为li与其相邻的关键线段围成一个patch的面积;当关键线段li对应的点mi不为端点时,Si为li与其相邻的关键线段围成两个patch的面积之和.

图4 遮挡区域建模示意图Fig.4 The sketch map of modeling occlusion region

图5 当前摄像机观测中心点与关键线段的位置关系Fig.5 The position relation between the observation center point of current camera and the key line segments
2.2 视觉目标运动估计
2.2.1 获取深度图像混合曲率矩阵
鉴于视觉目标在运动过程中其物体表面的曲率信息并不会发生改变.因此,对两幅深度图像分别利用反投影变换计算图像中各像素点对应的三维坐标,并利用三维坐标计算两幅深度图像的混合曲率矩阵.在此基础上,通过对视觉目标运动前后两幅深度图像对应的混合曲率矩阵提取特征点进行匹配,依据匹配信息计算视觉目标运动方程.混合曲率计算公式为

其中,pixeli表示深度图像中第i个像素点的混合曲率,本文采用Besl等[16]提出的方法计算第i个像素点的平均曲率MCi和高斯曲率GCi,k为常数,k值越大,图像表面信息越丰富.图6展示了视觉目标Bunny的深度图像和与其深度图像对应的混合曲率矩阵图像.
2.2.2 采用SURF算法匹配图像计算运动方程
依次获取视觉目标运动前后两幅深度图像对应的混合曲率矩阵之后,下一步工作是对提取的混合曲率矩阵进行匹配,考虑到动态遮挡规避过程的实时性与准确性要求,本文采用SURF算法[17]对两幅深度图像对应的混合曲率矩阵进行匹配.SURF算法优点是采用Hessian矩阵以及积分图像的概念,加快了算法的运行时间与效率,并且对旋转、仿射变换、噪声都有一定的鲁棒性.具体匹配过程如下:1)对视觉目标运动前后两幅深度图像对应的混合曲率矩阵提取特征点.2)计算与特征点对应的特征描述符.3)对两幅深度图像对应混合曲率矩阵提取出的特征点进行匹配.由于视觉目标运动过程中产生的误差可能导致算法得到的匹配点不准确并且部分特征点在视觉目标外部,因此采用三角形法则[18]对匹配结果进行筛选并去除视觉目标外部的特征点.图7展示了视觉目标Bunny运动前后深度图像所对应混合曲率矩阵提取出的特征点.图8展示了筛选之后的匹配效果.

图6 Bunny的深度图像及其对应的混合曲率矩阵图像Fig.6 The depth image of Bunny and its corresponding mixed curvature matrix image

图7 视觉目标Bunny运动前后的特征点Fig.7 The feature points of Bunny before and after motion
依据筛选后的匹配点,可以对视觉目标进行运动估计.假设视觉目标运动前后匹配点的对应关系为

从式(7)可以看出,运动估计的结果就是求得一组R、T,使之满足全部运动前后匹配点的三维坐标.考虑到动态遮挡规避过程的实时性,本文采用奇异值分解法[19]计算式(7)中的R和T.定义一个矩阵A

其中,

n为筛选后的匹配点个数.
对矩阵A进行奇异值分解可以得到A=UΣVT,其中R=V UT,将其代入式(7)可得到T.至此完成了视觉目标的运动估计.
2.3 规划摄像机下一最佳观测方位
获取遮挡区域最佳观测方位模型与运动估计方程之后,即可在此基础上规划摄像机的下一最佳观测方位.通过分析动态遮挡规避过程可知,若把摄像机观测位置代入运动估计方程,便可实现摄像机随动于视觉目标,但为了获取遮挡区域信息,需要在摄像机随动于视觉目标的同时引入摄像机为规避遮挡区域所需运动的偏移量.式(5)并非一个凸模型,故很难直接求得最优解去计算摄像机所需运动的偏移量.考虑到动态遮挡规避的最终结果是获取摄像机一系列观测方位,而最优化方法在求解非凸模型过程中计算出的搜索方向可以为摄像机运动偏移量的确定提供依据.目前可行的最优化方法有最速下降法、牛顿下降法、共轭梯度法、信赖域法等.由于该模型较易计算导数,且牛顿下降法相比于其他方法具有迭代次数少、收敛快的特点,从而有利于减少摄像机为规避遮挡区域所需运动的次数.故综合考虑方法的可行性和时间消耗,本文采用牛顿下降法求解模型的搜索方向来计算摄像机的运动偏移量,将摄像机下一最佳观测方向VVnext与观测中心点Pnext的计算公式分别定义为

其中,Vposition代表摄像机当前观测位置,λ为步长因子,λ值越大摄像机移动距离越远,但匹配点数量会相应减少从而影响运动估计的准确性.Pcurrent代表摄像机当前观测中心点.
依据计算出的下一最佳观测方向VVnext和观测中心点Pnext便可计算摄像机的下一最佳观测位置Pnc,计算公式定义为

其中,d为当前摄像机位置到观测目标中心点的固定距离.此时,将已经得到的下一最佳观测方位(Pnext,Pnc)作为当前观测方位(Pcurrent,Vposition),在新的观测方位(Pcurrent,Vposition)下继续采集视觉目标的深度图像,并计算所观测到的遮挡区域面积S,计算公式定义为

其中,θi为第i个patch的法向量与patch的中心点(patch四个点坐标的算术平均值)到当前摄像观测方位构成向量的夹角,Si为第i个patch的面积.基于式(12)的求解,判断相邻两次观测方位下观测到的视觉目标遮挡区域面积差值是否小于给定阈值,计算公式定义为

其中,Snext为下一观测方位下观测到的视觉目标遮挡区域面积,Scurrent为当前观测方位下观测到的视觉目标遮挡区域面积.
重复式(6)~(13)的过程直到式(13)成立为止,此时获得了一系列摄像机下一最佳观测方位(Pnext,Pnc),动态遮挡规避过程结束.
2.4 动态遮挡规避算法
输入.运动视觉目标深度图像,摄像机内外参数.
输出.动态遮挡规避过程中摄像机的下一最佳观测方位集合.
步骤1.提取视觉目标深度图像遮挡边界的关键点以及与其相对应的下邻接点构建关键线段,并利用关键线段对遮挡区域建模.
步骤2.依据式(1)~(5)构建遮挡区域最佳观测方位模型.
步骤3.根据式(6)计算相邻两幅深度图像的混合曲率矩阵;采用SURF算法进行匹配,并依据三角形法则对匹配点进行筛选;根据式(7)和式(8)对视觉目标进行运动估计.
步骤4.根据式(9)~(11)规划摄像机下一最佳观测方位;依据式(12)计算摄像机能观测到的遮挡区域面积;若相邻两次面积差值大于阈值ε,跳转至步骤3继续进行遮挡规避;直到动态遮挡规避过程结束.
步骤5.输出摄像机的下一最佳观测方位集合.
3 实验及分析
3.1 实验方案及数据集
为了全面合理地验证所提方法的可行性和有效性,本文做了4组实验.1)构建遮挡区域最佳观测方位模型过程中各个阶段可视化实验;2)针对不同曲率矩阵提取特征点的对比实验;3)动态遮挡规避实验;4)与已有动态遮挡规避方法的实验比较.实验硬件环境为Intel(R)Core(TM)i7-3770 CPU@3.40GHz,内存8.00GB.实验中的3维模型来自深度图像领域著名的Stuttgart Range Image Database[20]和Kinect采集的真实视觉目标.实验采用C++编程实现.实验过程中采用OpenGL实现视觉目标运动,设置OpenGL投影矩阵的参数为(60,1,200,600),视窗大小为400像素×400像素,深度图像的分辨率为640像素×480像素.摄像机到观测目标中心点的固定距离d=300mm,常数β=200,常数k=3,步长因子λ=2.5(常数β、k和步长因子λ均为经验值),考虑到动态遮挡规避对准确性和实时性的要求,以及为了与文献[13]进行对比实验等因素,本文选取阈值ε=30mm2(后文中,世界坐标系的单位均为mm).
3.2 实验结果及分析
3.2.1 构建遮挡区域最佳观测方位模型过程中各个阶段可视化实验结果和分析
为了更加形象地说明本文方法构建的遮挡区域最佳观测方位模型.图9给出了构建遮挡区域最佳观测方位模型过程中各个阶段的可视化结果.图中最左侧的文字表示视觉目标,图9(a)是初始观测方位下深度图像,图9(b)是遮挡边界、关键点及下邻接点,图9(c)是关键线段的观测方向,图9(d)是遮挡区域最佳观测方位下的可见关键线段,图9(e)是遮挡区域最佳观测方位下的深度图像.

图9 各个阶段的可视化结果Fig.9 The visualization results of each phase
从图9可以看出,对于视觉目标Duck,由于在当前观测方位下遮挡情况不太显著并且各个关键线段之间围成的patch面积差值较小,故在遮挡区域最佳观测方位下观测到的遮挡区域面积较小;对于视觉目标Bunny,Mole,Rocker和Knot,由于在当前观测方位下遮挡情况相对显著并且各个关键线段之间围成的patch面积差值较大,故在遮挡区域最佳观测方位下观测到的遮挡信息较多.由此可见,当视觉目标遮挡现象越显著并且各个关键线段之间围成的patch面积差值越大,本文方法构建的遮挡区域最佳观测方位模型越好,进一步验证了所提关键点方案的可行性.
3.2.2 针对不同曲率矩阵提取特征点的对比实验
视觉目标深度图像所对应曲率矩阵将对最终提取的特征点产生较大的影响,进而影响到视觉目标运动估计的准确性.为了验证本文所提混合曲率特征的有效性,分别对基于高斯曲率、平均曲率和混合曲率三种不同曲率计算出的曲率矩阵的实验结果进行了比较.图10展示了针对不同视觉目标运用不同曲率获取与深度图像相对应的曲率矩阵的可视化结果.图中最左侧的文字表示视觉目标,图10(a)是视觉目标深度图像,图10(b)是高斯曲率矩阵,图10(c)是平均曲率矩阵,图10(d)是混合曲率矩阵.
分析图10结果可知,高斯曲率能较好地表达视觉目标内部表面的纹理信息,平均曲率能较好地表达视觉目标边缘的轮廓信息,本文所提的混合曲率则能够更好地表达视觉目标边缘轮廓与内部表面纹理信息.
为了更好地说明本文所提混合曲率特征的效果.表1给出了与视觉目标深度图像对应不同曲率矩阵提取特征点的量化结果,实验结果为30幅深度图像对应的曲率矩阵提取特征点的平均数(取整).其中NC表示采用平均曲率矩阵提取特征点的个数,NG表示采用高斯曲率矩阵提取特征点的个数,NGC表示采用混合曲率矩阵提取特征点的个数.从表1可以看出,采用本文方法获取视觉目标特征点的结果明显优于其他两种方法获取视觉目标特征点的结果,进而验证了本文所提混合曲率特征的有效性.
3.2.3 动态遮挡规避实验的结果和分析
为了验证本文所提动态遮挡规避方法的可行性和有效性,分别进行了仿真实验和真实实验.

图10 不同曲率矩阵的可视化结果Fig.10 The result of visualization for different curvature matrices
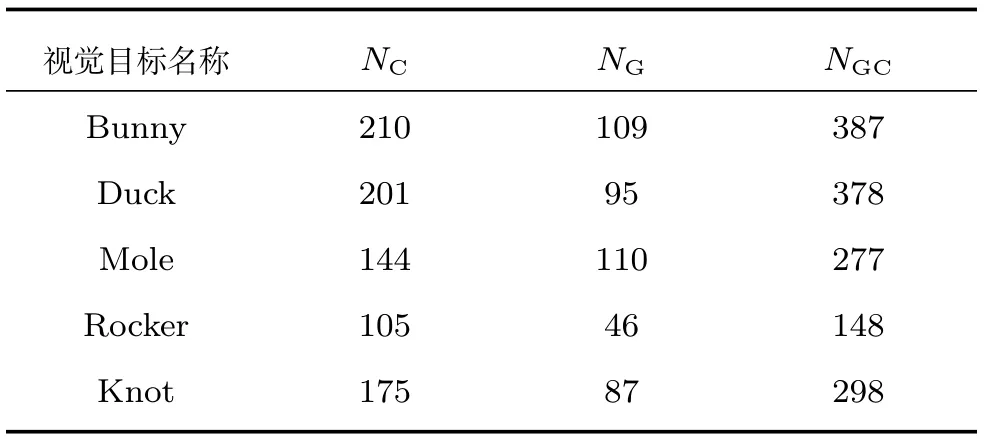
表1 不同曲率矩阵提取特征点结果的量化评估Table 1 Quantitative evaluation of the result of feature points extracted by different curvature matrices
在仿真实验中,选取Stuttgart Range Image Database中的3维视觉目标Dragon和Bunny作为实验对象,使其在不同的运动方式下进行动态遮挡规避.表2是视觉目标Dragon在初始观测方位[190,−200,118]T下以2mm/s的速度沿向量[−2,0,0]T做平移运动的动态遮挡规避过程.表3是视觉目标Bunny在初始观测方位[−196,170,150]T下以5◦/s速度绕向量[−1,1,2]T做旋转运动的动态遮挡规避过程.表4是视觉目标Bunny在初始观测方位[190,−200,118]T下以3mm/s的速度沿向量[1,0,0]T平移的同时以2◦/s速度绕向量[2,1,0]T做旋转运动的动态遮挡规避过程.由于摄像机在动态遮挡规避过程中移动次数较多,仅展示了摄像机在部分观测方位下的观测结果.
在真实实验中,基于视觉目标Printer(打印机),Kettle(水壶)和Plant(海葱)的不同运动方式进行动态遮挡规避实验,并利用Kinect采集它们的深度图像.图11是视觉目标Printer,Kettle和Plant的RGB图像、深度图像、深度图像中的遮挡边界及其关键点.分析图11(c)中不同视觉目标的深度图像可知,在图像采集过程中,由于Kinect自身误差、遮挡及柔性物体例如Plant易发生形变、尺度变化等现象,从而导致获取的深度图像存在一定的边界不连续、信息缺失或噪声.但通过分析图像11(d)的结果可知,对于存在上述情形的遮挡边界,所提方法依然能够较准确地提取到遮挡边界上的关键点,从而验证了本文所提关键点筛选方法具有一定的鲁棒性.

表2 视觉目标Dragon做平移运动时的动态遮挡规避过程Table 2 The dynamic occlusion avoidance process of visual object Dragon with translation motion

表3 视觉目标Bunny做旋转运动时的动态遮挡规避过程Table 3 The dynamic occlusion avoidance process of visual object Bunny with rotation motion

图11 真实实验结果Fig.11 The result of real experiment
在真实实验中,由于目前实验硬件条件的限制,无法使摄像机随动于视觉目标的同时对视觉目标进行拍摄.考虑到实验的完整性,通过对Kinect采集到的不同视觉目标的深度图像进行三维重建,进而利用OpenGL模拟了不同视觉目标在不同运动方式下的动态遮挡规避过程.表5是视觉目标Printer在初始观测方位[0,1,1200]T下以2mm/s的速度沿着向量[0,1,0]T做平移运动的动态遮挡规避过程.表6是视觉目标Kettle在初始观测方位[0,−1,600]T下以2o/s的速度沿着向量[−2,1,0]T做旋转运动的动态遮挡规避过程.表7是视觉目标Plant在初始观测方位[0,−1,650]T下以2o/s的速度沿着向量[−2,1,0]T做旋转的同时以2mm/s的速度沿着向量[0,1,0]T做平移运动的动态遮挡规避过程.

表4 视觉目标Bunny做平移和旋转运动时的动态遮挡规避过程Table 4 The dynamic occlusion avoidance process of visual object Bunny with both translation and rotation motion

表5 视觉目标Printer做平移运动时的动态遮挡规避过程Table 5 The dynamic occlusion avoidance process of visual object Printer with translation motion

表6 视觉目标Kettle做旋转运动时的动态遮挡规避过程Table 6 The dynamic occlusion avoidance process of visual object Kettle with rotation motion
表2~7中,第1列是摄像机在动态遮挡规避过程中所拍摄的视觉目标深度图像编号,当遮挡规避过程结束时,由不同表的第1列图像编号不同可知,当视觉目标以不同的方式进行运动时,摄像机的运动次数也是不同的.第2列是摄像机在一系列下一最佳观测方位下拍摄到的视觉目标深度图像,分析相关图像可知,本文方法在动态遮挡规避过程中求得的一系列下一最佳观测方位都与人类视觉的观测习惯相符.第3、4列分别是筛选匹配点之后的匹配图像和匹配点数,可以看出筛选后的匹配点都更加准确,从而有利于后续估计视觉目标运动以及规划摄像机的下一最佳观测方位,以便摄像机获取更多的视觉目标遮挡信息.第5~7列分别是计算出的摄像机下一最佳观测方向、观测位置和在相应观测方位下求得的遮挡区域面积.从这些数据及其变化趋势可以看出,随着动态遮挡规避过程的进行,越来越多的遮挡区域被观测到.
3.2.4 与已有动态遮挡规避方法的实验比较及分析
虽然目前动态遮挡规避方面的文献较少,但为了更全面合理地评估本文方法的效果,将本文方法与同样基于深度图像且考虑遮挡信息的代表动态遮挡领域最新进展的文献[13]中的方法进行了三组对比实验.1)不同建模方法以及下一最佳观测方位的对比实验;2)运动估计的对比实验;3)动态遮挡规避最终结果的对比实验.考虑到本文真实实验过程并不完整,即动态遮挡规避部分仍然采用重建后的3维模型进行实验,这与基于Stuttgart Range Image Database中的3维模型进行实验并无本质区别,并且为了保持与文献[13]实验对比部分的一致性,故此部分并未增加真实实验的对比数据.下面分别给出三组对比实验的结果及分析.
表8是本文方法和文献[13]方法在相同初始观测方位下对遮挡区域建模的时间消耗对比结果.从表8可以看出,对于不同视觉目标遮挡区域,本文建模方法在时间消耗上均低于文献[13]中的方法,进一步验证本文方法在建模速度上更满足动态遮挡规避对实时性的要求.
为了更好地衡量本文所提建模方法,将两种建模方法计算出的下一最佳观测方位进行实验对比.图12是两种方法在所求下一最佳观测方位下获得的视觉目标深度图像.其中,第1行为当前观测方位下的视觉目标深度图像,第2行为文献[13]方法计算出的下一最佳观测方位下的视觉目标深度图像,第3行为本文方法计算出的下一最佳观测方位下的视觉目标深度图像.表9是两种不同建模方法求解出的下一最佳观测方位下获取的视觉目标表面点的量化结果.其中Nnbv代表摄像机在下一最佳观测方位下获取到的视觉目标表面点的个数,No代表被重复观测到的视觉目标表面点的个数,Nnew=Nnbv−No代表实际新增点的个数,Ro代表重合率,Rnew代表新增率.
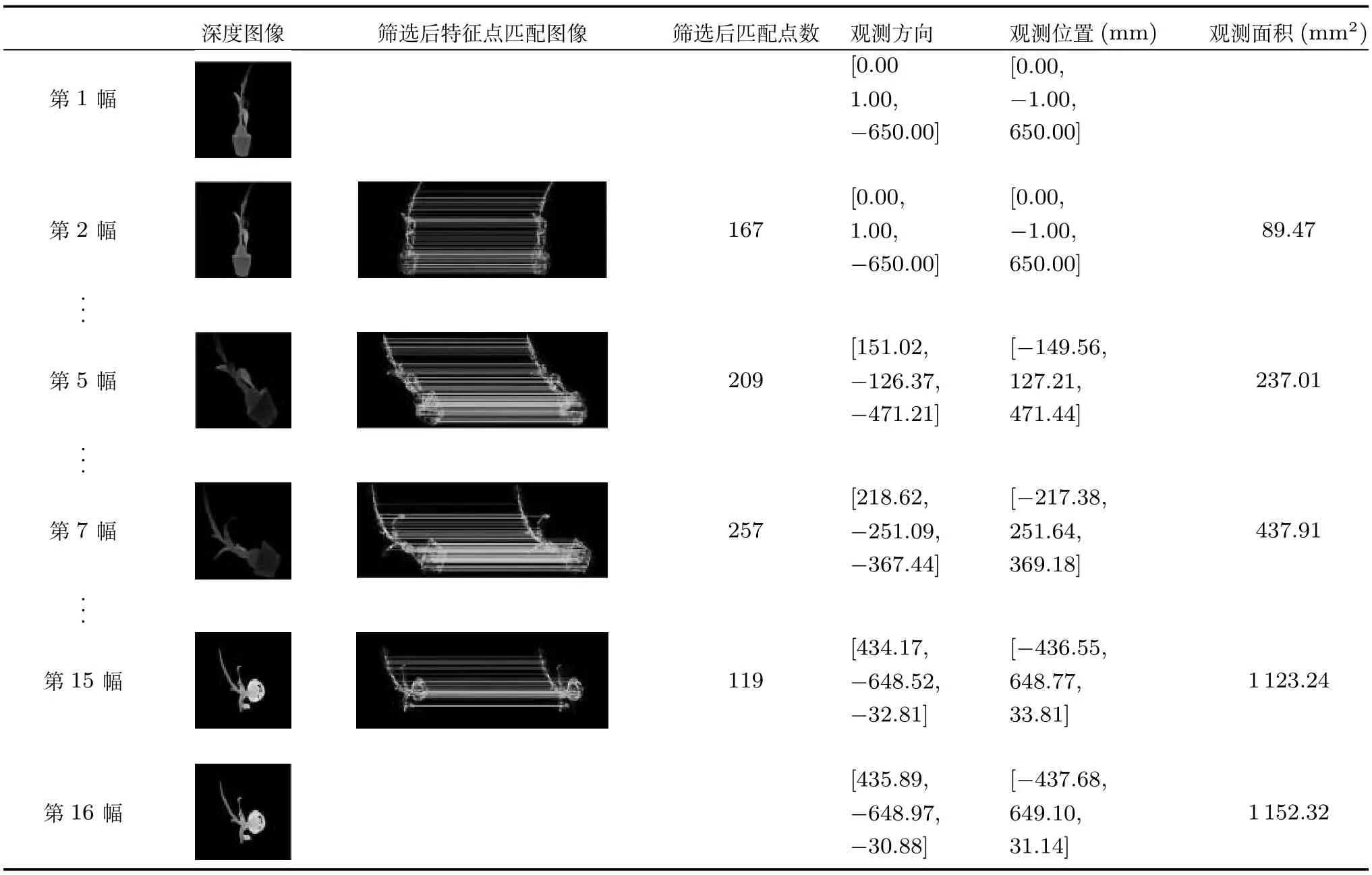
表7 视觉目标Plant同时做旋转和平移运动时的动态遮挡规避过程Table 7 The dynamic occlusion avoidance process of visual object Plant with both translation and rotation motion

表8 两种建模方法的时间消耗(ms)Table 8 Time consumption of two modeling methods(ms)
结合图12和表9的分析可知,由于本文方法与文献[13]均是通过对遮挡区域建模,进而计算下一最佳观测方位,因此,对于遮挡情况不太显著的视觉目标Duck和Mole,由于在初始观测方位下遮挡区域相对较少,影响下一最佳观测方位计算的准确性,从而导致在下一最佳观测方位下计算出的新增率相对偏低;对于遮挡情况相对显著的视觉目标Bunny,Rocker和Dragon而言,由于下一最佳观测方位计算相对准确,所以新增率相对较高.与本文方法相比,由于文献[13]方法在遮挡区域建模过程中,对遮挡面积不同的区域并没有做任何区分,而本文方法在遮挡区域建模过程中,更注重对遮挡面积较大的区域进行观测,根据实验结果来看,在新增点和新增率上,本文方法都比较好.综合来看,与文献[13]相比,本文方法的适用性更好,更符合人类的观测习惯.
为了衡量本文运动估计的准确性,针对做不同运动的视觉目标Bunny,分别采用文献[13]和本文中的方法进行运动估计,并将运动估计得到的结果对初始观测方位[0,−1,300]T进行变换,最后分析变换结果和时间消耗.表10是两种运动估计方法的对比结果.

表9 两种方法的下一最佳观测方位实验结果量化评估Table 9 The quantitative evaluation of experimental results in next best view for two methods

表10 两种运动估计方法的对比结果Table 10 The comparison results of two motion estimation methods

图12 两种方法在下一最佳观测方位下获取的视觉目标深度图像Fig.12 The depth images of visual object in next best view for two methods
从表10可以看出,本文方法的运动估计结果与Ground truth最为相近,并且在时间消耗上明显低于文献[13]中的方法.这是由于文献[13]采用SIFT算法匹配图像,该算法需要计算每个关键点的128维特征向量,从而导致运动估计的时间较长,并且该方法没有对错误匹配点进行筛选,致使最终运动估计结果与Ground truth相差相对较大.而本文方法采用SURF算法匹配图像,在相同条件下SURF算法的匹配速度是SIFT算法的3倍,并且本文通过计算深度图像混合曲率矩阵,增加了匹配点的数量,同时,对错误匹配点进行筛选,以确保本文方法在耗时较少的情况下也能具有相对较高的准确性.由此可见,本文方法在运动估计及其误差方面具有一定的优势和改进.
此外,在动态遮挡规避最终结果方面进行了对比实验.表11是部分具有代表性的视觉目标在不同观测方位和运动方式下对应的实验结果.其中,代表视觉目标要规避的遮挡区域总面积,Spurpose代表目标观测方位下观测到的遮挡区域面积,Sview为动态遮挡规避过程结束时的观测方位下观测到的遮挡区域面积,η表示有效规避率即Sview与Spurpose的比值,¯T代表动态遮挡规避过程中计算下一最佳观测方位所需时间(平均值).

表11 两种动态遮挡规避方法的量化评估Table 11 The quantitative evaluation of dynamic occlusion avoidance for two methods
分析表11可知,与文献[13]相比,本文方法通过计算与视觉目标深度图像相对应的混合曲率矩阵,增加提取特征点的数量并且对匹配点进行筛选,为准确估计视觉目标运动奠定了基础.因此,无论视觉目标做简单运动(第1、3、5组实验)还是复杂运动(第2、4、6、7、9、10组实验),在最能反映实际动态遮挡规避效果的有效规避率η指标上,实验结果都明显高于文献[13]方法的结果.对于第8组实验,由于在当前观测方位下相邻关键线段之间构成的patch面积差值不明显,故本文方法的有效规避率低于文献[13]方法的结果.对于第6、7、9、10组实验,由于视觉目标在初始观测方位下遮挡情况不太显著,进而影响下一最佳观测方位计算的准确性,最终导致有效规避率相对偏低.由此可见,当遮挡情况越显著,通过遮挡区域最佳观测方位模型计算的下一最佳观测方位越准确,本文所提方法的有效规避率就相对越高.对于每次获取下一最佳观测方位所需的时间¯T,主要受运动估计以及计算摄像机下一最佳观测方位等因素的影响,而本文方法在运动估计方面的时间消耗低于文献[13]中的方法,并且采用牛顿下降法减少下一最佳观测方位计算过程中的迭代次数,故本文方法获取下一次最佳观测方位所需的时间明显少于文献[13]方法的结果.综合来看,与文献[13]相比,本文方法在对遮挡区域建模、视觉目标运动估计以及规划摄像机下一最佳观测方位等方面,更好地达到了动态遮挡规避问题的求解要求.
4 结论
本文提出了一种利用深度图像遮挡信息对运动视觉目标遮挡区域进行规避的方法.所提方法的贡献主要体现在三个方面:1)提出了深度图像遮挡边界关键点的概念,并利用关键点与其对应的下邻接点构建关键线段实现对视觉目标遮挡区域的快速建模;2)依据遮挡区域建模结果和关键线段构造遮挡区域最佳观测方位模型,并结合最优化方法求解模型,为摄像机下一最佳观测方位的确定提供了依据;3)提出了一种混合曲率特征,通过计算深度图像对应的混合曲率矩阵,使得SURF算法能够提取到更多的特征点,增加了匹配点的数量,为准确估计视觉目标运动奠定了基础.实验结果表明,所提方法能够实现对运动视觉目标遮挡区域的动态规避过程,且与人类的视觉观测习惯相符.需要指出的是,所提方法构建的遮挡区域最佳观测方位模型是一个非凸模型,未来将在尝试构建更优的最佳观测方位模型等方面展开研究.
