雾霭图像实时处理算法加速策略
2019-06-19刘晓春
崔 文,李 强,刘晓春,李 由
(1. 中国人民解放军96941部队, 北京 102208; 2. 国防科技大学 空天科学学院, 湖南 长沙 410073;3. 中国航天员科研训练中心人因工程重点实验室, 北京 100194 )
红外成像末制导[1]是精确制导武器的一种重要制导方式,采用前视红外末制导的导弹在进行攻击检查时可用图像匹配[2-8]实时推演判断识别点可跟踪性,以特定姿态仿真导弹导引至目标点的可行弹道。雾霭气象条件下,为保障命中精度,红外导引头一般需要对实时图进行预处理而后进行匹配运算。为仿真红外导引头实时匹配导引过程,完成目标实时跟踪性判断,本文针对限制对比度自适应直方图均衡(Contrast-Limit Adaptive Histogram Equalization, CLAHE[9])和归一化互相关(Normalization Cross Correlation, NCC)算法开展加速策略研究,提出基于统一计算设备架构(Compute Unified Device Architecture, CUDA)的雾霭图像实时处理加速方案,程序优化后,可实现目标可跟踪性实时判断。
1 软硬件设计考虑
在实时图像处理算法设计领域,学者们研究的热点集中在数字信号处理器(Digital Signal Processor, DSP)、现场可编程门阵列(Field Programmable Gate Array, FPGA)和多核中央处理器(Central Processing Unit, CPU)算法设计与应用。陈正刚等[10]研究了基于DSP与FPGA的视频跟踪系统硬件设计和NCC方法快速实现,将一帧图像的跟踪算法计算时间降至20 ms以内。肖汉等[11]采用图形处理器(Graphics Processing Unit, GPU)并行化方法研究图像匹配问题,获得7倍于CPU实现的图像匹配运算速度,虽然在影像数据较大时,由于未对主机和设备之间的数据传输进行优化,实时度明显降低,但研究给后继者以启迪,推动着GPU并行化应用加速发展。宋骥等[12]改进优化了基于GPU并行计算的图像快速匹配,改进优化后的算法对图像尺寸有较强适应性。实时图像处理硬件设计方面,曾有研究人员[13-14]指出,对于数据处理能力要求很高的应用领域,GPU具有CPU甚至高端DSP不可比拟的性能优势。以上研究表明,选用合适的硬件和软件实现对实时图像处理速度至关重要,是值得设计人员重点考虑的因素。基于逻辑门和触发器等数字电路进行并行任务处理的FPGA,实时性很高,但造价昂贵、编程速度慢,并不适合做实时图像处理算法验证实验。鉴于上述研究成果和工程经验,本文初步确定采用GPU+CPU的硬件组成形式进行实验。
针对实时图像处理并行加速,有文献[15]指出,基于开源计算机视觉库OpenCV进行数字图像处理、模式识别、运动跟踪等多核CPU算法开发可以提升运算速度;文献[16]指出,采用高效的GPU并行计算算法,构建CPU/GPU异构计算平台已解决众多模拟计算加速问题;文献[17]指出,在目标跟踪点搜索及跟踪应用领域,基于CUDA并行程序设计的GPU编程加快了运算速度。也就是说,多核CPU并行算法、GPU并行算法都可用于图像处理加速。更好更优的算法决定了更少的计算时间,是实现实时性的关键,也是本文要着重考虑的问题。
2 实时处理算法
2.1 问题描述
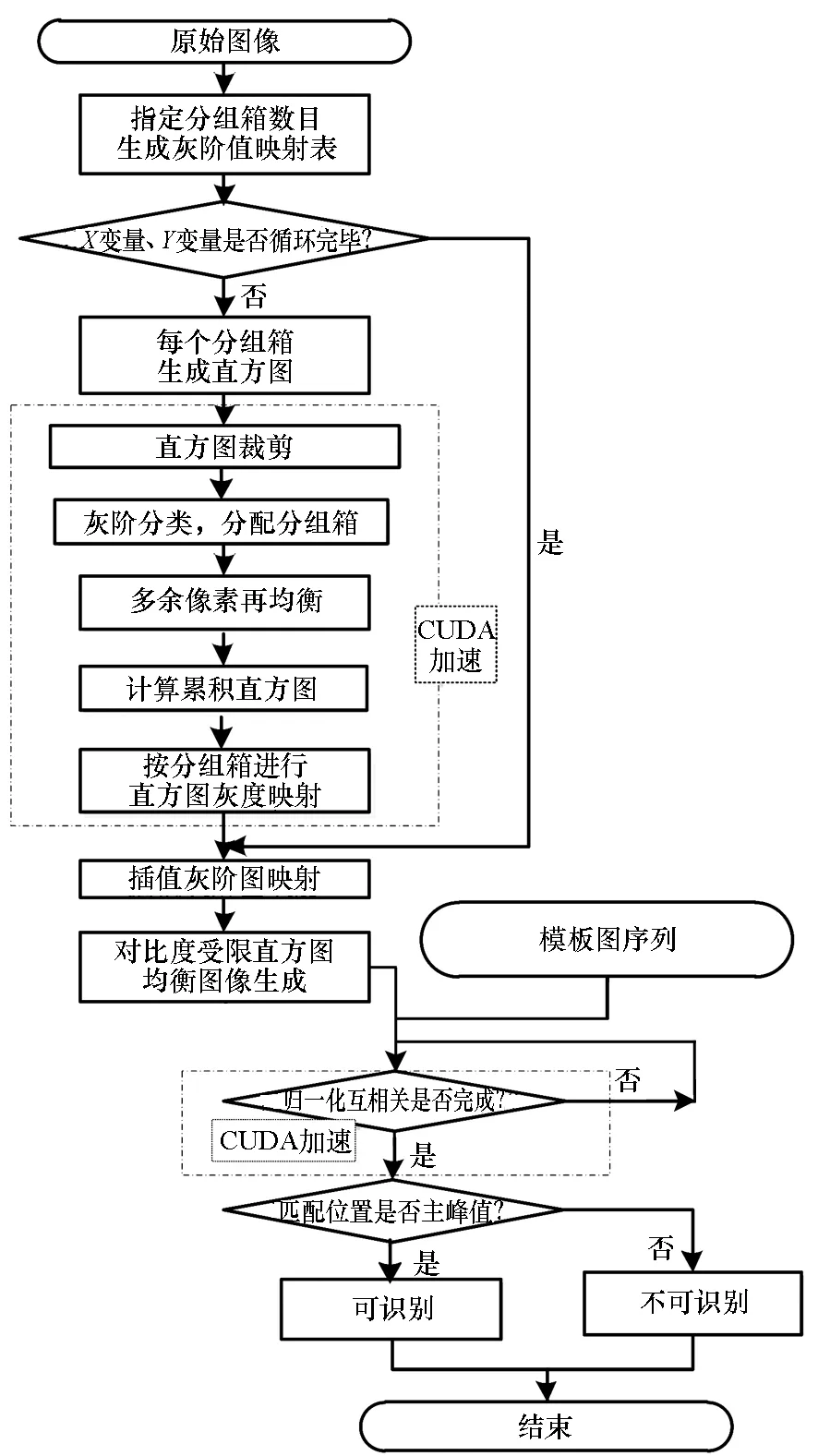
图1 雾霭图像实时处理算法计算流程图Fig.1 Real-time foggy image processing flowchart
在进行加速策略研究之前,先对加速的对象——雾霭图像实时处理算法进行简单描述。该算法以CLAHE算法和模板图像匹配算法为核心要素,计算流程见图1。基于分块处理的自适应直方图均衡算法可对雾霭天气条件下的图像进行去雾增强,并通过限制对比度阈值去除图像噪声影响,均衡效果较经典直方图优秀且不会过度放大噪声。图像匹配就是以“图”搜图,较为成熟的有基于模板的匹配和基于特征的匹配两种[1]。基于模板的匹配是从实时图中搜索比对出模板图,计算量大[18],对旋转、形变、遮挡比较敏感,但匹配准确度高,需要考虑硬件加速;基于特征的匹配是从实时图中搜索到特征量,计算量相对较小,对灰度、形变及遮挡的适应性较好,匹配精度较高。常用的图像匹配计算公式有绝对平均误差(Mean Absolute Deviation, MAD)、绝对差和(Sum of Absolute Differences, SAD)、最小均方误差(Mean Squared Error, MSE)和NCC(如式(1)所示)。对于本文研究的目标实时跟踪性判断来说,需要考虑相互匹配的图像间亮度变化可能,NCC能更好消除这种影响,准确度更高。
(1)
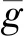
要解决的问题就集中到如何在毫秒间完成图像匹配,即算法实时化加速问题。
2.2 加速方案一:OpenMP多核CPU并行
OpenMP多核CPU并行加速方案是采用多线程技术进行并行计算加速。特点是CPU所有的核共享一个内存,不同核执行不同线程,在同一内存的不同部分操作多数据,加速的目的是将各线程工作负载均衡分配,CPU整体计算速度达到最高。常见的For循环语句采用图2方式实现代码并行化;不同代码段并行执行时,采用OpenMP Section语句(见图3)实现。
#pragma omp parallel for schedule(dynamic)
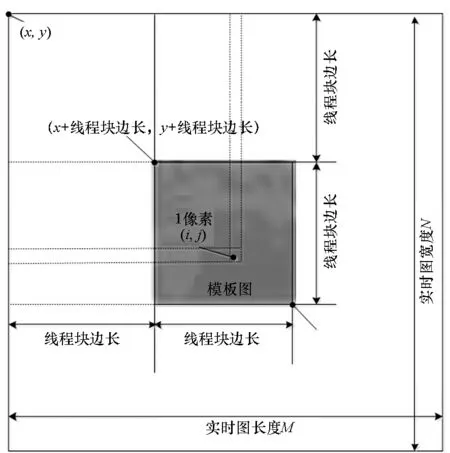
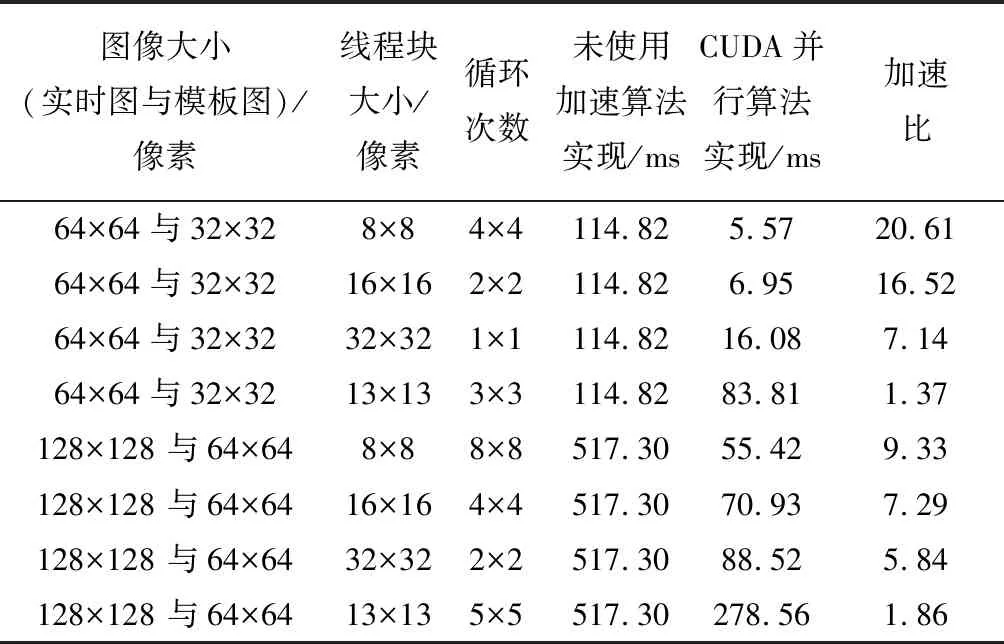
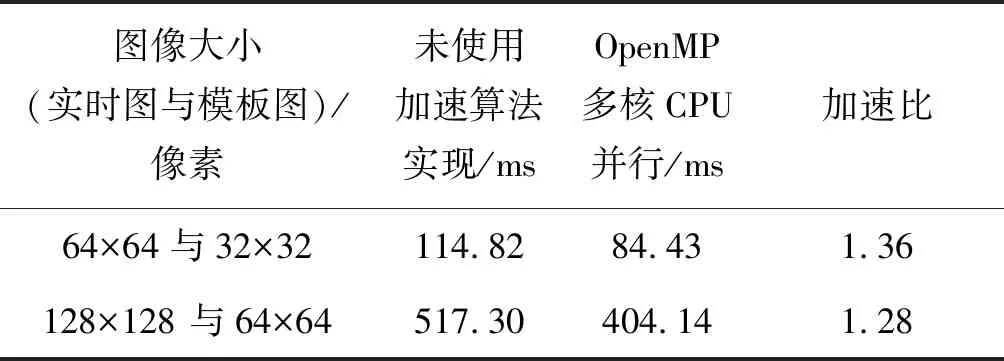
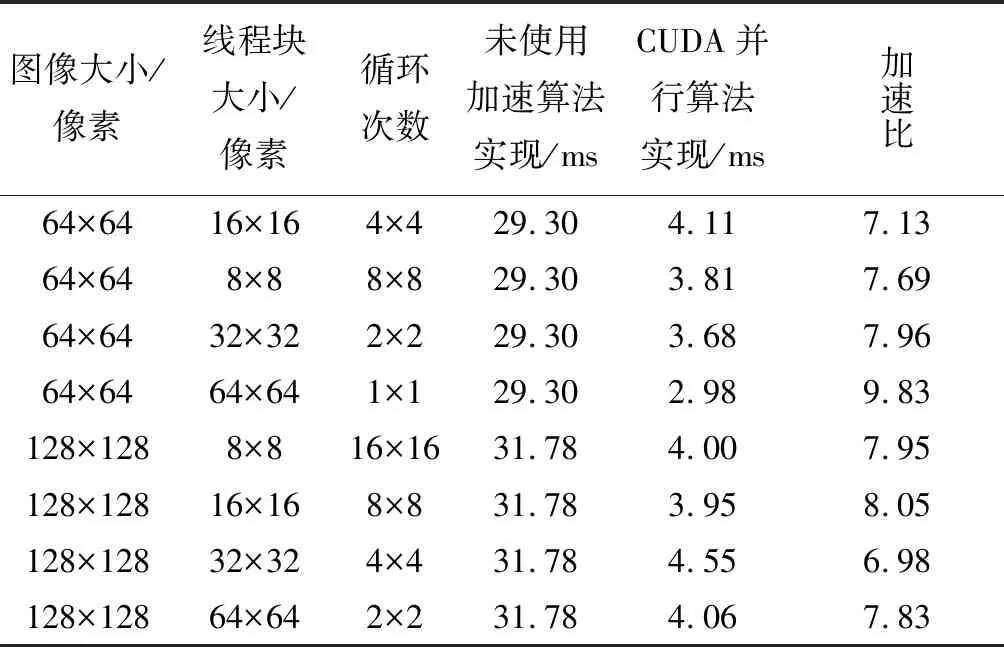
for(i=0;i { 可并行部分代码; } 图2 OpenMP并行化For循环实现方式 #pragma omp parallel sections GPU并行加速方案是通过使用NVIDIA公司的CUDA编程模型实现“block间粗粒度并行”和“thread间细粒度并行”双层并行加速。 加速方案用CUDA实现时,由CUDA编程指定CPU指令和内存分配,GPU完成具体并行计算。具体说就是,用CPU可编译执行的代码实现并行数据加载内存,数据映射到GPU,然后GPU开展并行计算、共享存储器块内数据,定制运行的众线程数量,完成核函数(用_global_前缀标明)并行计算,完成后再把控制权交回CPU,数据映射回CPU,最终进行数据存取和文件读写,由GPU可编译执行的代码和CPU可编译执行代码共同完成全算法加速。加速算法实现时,要注意划分的线程块内warp数目合理,每个流处理器都可交替执行内部warp,提高整体计算效率;也要根据NVIDIA GPU设备的流处理器个数,并行使用合理的线程块block数,提升流多处理器(Streaming Multiprocessor, SM)利用率。 GPU算法开销常见的有调度开销、GPU内核函数启动开销和内核函数之间数据传输开销。算法优化主要考虑循环融合和内核融合。循环融合是尽量将明显独立的循环进行归并,减少总体迭代的次数;内核融合是将数据重用、内存合并、线程间数据共享。雾霭图像实时处理算法加速策略中的归一化互相关部分,考虑申请共享内存进行CUDA并行实现,使得每个线程块block、每个线程thread都能访问和操作这块共享内存。由于共享内存是基于存储体切换架构的,无论多少个线程发起操作,每个存储体每个周期只执行一次操作,即如果有线程束中的一个线程访问片上共享内存,所有的线程都能在这同一指令周期内同时执行访问共享内存,无须顺序访问,因而能有效减少图像匹配算法像元读取访问次数,降低数据访问开销。 图4 实时图内block划分Fig.4 Block division in real-time figure 需要说明的是,匹配循环次数也对算法效率产生影响。由于匹配循环次数等于[(实时图宽度-模板图宽度)/ 线程块Y方向大小, (实时图长度-模板图长度)/ 线程块X方向大小],匹配循环次数越少, CUDA内核函数1次可使用核心数越多,算法开销也越小。当内核函数计算需被拆分成多次,无法一次完成时,加速效果将大大降低。以上性能加速均基于线程块大小的平方与匹配循环次数的乘积小于GPU设备标称核心数目。实验使用的GPU单个线程块block管理的最大线程数量为1024,BLOCKSIZE必须小于等于32。固定模板图为64像素×64像素,模板图线程块大小BLOCKSIZE可从典型值8、16、32中取一种;固定模板图为32像素×32像素,模板图线程块大小BLOCKSIZE可从典型值8、16中取一种。又鉴于实验所用GPU设备标称核心数目,线程块大小、匹配循环次数最好按表1所列配对方式选取,具体的实验结果参见下一部分内容。 表1 主要设计参数配对表 CLAHE部分的CUDA优化加速是分别对直方图生成、直方图裁剪、直方图再均衡环节进行,将图像各个分组箱分块内的像元灰阶数、分组箱分块内超出限定灰度阈值范围的灰阶数目使用共享存储器实现数据共享,实现图像像素点For循环累加计数运算CUDA并行化,达到降低算法开销、优化加速的目的。 针对上述两种加速方案开展对比实验。针对图5(a)所示的雾霭图像进行去雾处理,处理后的图像增强效果见图5(b)。近处楼房、远处楼房、天空均得到对比度增强,去雾效果显著。进行方案一加速和方案二加速后,图像匹配归一化算法部分GPU加速后的性能指标、OpenMP多核CPU加速后的性能指标分别见表2、表3;CLAHE算法部分GPU加速后性能指标、OpenMP多核CPU加速后性能指标分别见表4、表5。 (a) 原始雾霭图像(a) Origin foggy image (b) 去雾霭效果图(b) Foggy image processing effect show图5 雾霭图像处理效果Fig.5 Foggy image processing effect 表2 NCC算法GPU加速后性能指标 表3 NCC算法OpenMP多核CPU加速后性能指标Tab.3 Performance indicators of NCC algorithm with multicore CPU OpenMP acceleration 表4CLAHE算法GPU加速后性能指标 Tab.4 Performance indicators of CLAHE with GPU acceleration 表5 CLAHE算法OpenMP多核CPU加速后性能指标Tab.5 Performance indicators of CLAHE with multicore CPU OpenMP acceleration 查看表2中加速比为1.37和1.86的两个数据发现,选用的线程块尺寸大小不合适(图像大小不能整除线程块尺寸大小)会造成加速比过低,导致效果接近表3中OpenMP多核CPU加速效果。为提高加速比,在GPU CUDA加速实现策略中避免选择此种线程块尺寸。剔除两数据后的表2,图像匹配 GPU优化加速后较未使用加速策略前计算时间缩短至4.85%~17.11%,计算性能提高5~20倍,加速效果理想。对比表4、表5可以发现,CLAHE算法GPU优化加速后时间可缩短至10.17%~14.32%,计算性能提高6~9倍。分析表2中图像大小与加速比关系可发现,使用CUDA并行实现NCC加速时,选定线程块大小后,存在实时图与模板图最优尺寸配对,使加速比达到最大。 透过数据本身,进一步分析可得到:线程块大小设计对加速性能有很大影响,这进一步验证了优化设计的原理;当图像大小是线程块尺寸大小的整数倍时,相比随意的线程块大小尺寸,计算时间更短,这是因为减少了总迭代次数,降低了算法开销;同时线程块越小,GPU使用的核心数越多,加速性能越明显。对于图像匹配NCC算法,实时图为64像素×64像素、模板图为32像素×32像素、线程块大小为8像素×8像素时,CUDA使用核心数为4×4×8=128<384(GPU核心数),并且中间成果数据融合效率最高,因而加速性能最高。当实时图为128像素×128像素、模板图为64像素×64像素、线程块大小为8像素×8像素时,CUDA使用核心数为8×8×8=512>384(GPU核心数),内核函数计算被拆分成多次计算,加速性能有所减弱,但因分块形式对于数据融合较为高效,也能最终获得9.33倍的加速效果。 1)充分利用共享寄存器的CUDA加速算法设计,可以降低GPU设备读取数据次数,实现并行线程间数据共享,实现算法加速。单幅图像CUDA加速算法线程块尺寸设计对加速性能有较大影响,当模板图图像大小是线程块尺寸大小整数倍时,相比随意的线程块大小尺寸,计算时间更短;对于性能指标固定的GPU,选定线程块大小后,能实时处理的实时图和模板图存在最优尺寸大小,可通过仿真实验方法进行测试标定。 2)从总体时间性能指标方面来看,基于CUDA的雾霭图像GPU并行处理算法计算速度较未进行CUDA加速优化前提高5~20倍,且GPU使用的核心数越多,加速性能越明显;64像素×64像素实时图与32像素×32像素模板图匹配的计算时间仅为5.57 ms,达到实时仿真计算的要求,能够用于目标实时跟踪性判断检测。 3)在解决单幅图像并行处理需求方面,使用OpenMP实现多核CPU并行加速效果不如使用GPU CUDA加速明显,OpenMP算法开支时间较大,实时性较差。相比之下,OpenMP多核CPU并行更适合多幅图像同时进行处理,减少总体作业开支时间。
Fig.2 For loop′s OpenMP parallelization
{
# pragma omp section
{
可并行代码
}
# pragma omp section
{
可并行代码
}
}
图3 不同段并行执行的OpenMP Section语句
Fig.3 Different section parallelization in OpenMP2.3 加速方案二:高效GPU并行算法
2.4 CUDA实现并行加速策略

3 结果与分析



4 结论
