基于深度神经网络的肝硬化中医治疗预测研究*
2019-06-19胡冯菊
肖 瑞 裴 卫 胡冯菊 肖 勇
(湖北中医药大学信息工程学院 武汉 430065)
1 引言
中医病历又称医案、诊籍, 是中医临床各科医生对具体患者进行辨证论治的文字记录, 包括患者的生活习性、病情、诊断、治疗及预后等情况, 从而成为保存、查核、考评乃至研究具体医生开展具体诊疗活动的档案资料[1]。但随着信息化、网络化的不断推进,电子病历已成为现今医疗记录的大趋势[2]。应用电子病历不仅提高就诊效率、规范中医行业术语,还为后期中医药研究提供数据资源。中医电子病历除具备一般电子病历的特征外还具有自身的特殊性。在病历内容上不仅包括四诊、辩证、立法、处方,西医检查和诊断等现代医学诊疗信息,还包括中医学辨证论治的诊疗信息;在病历结构上既要满足医疗、法律、管理的要求,还要满足中医临床信息全面、准确采集的要求并做到高度结构化,以便对四诊信息中的定性描述进行量化记录;在标准规范化上,建立统一、全面、规范的中医治疗术语词表以便对诊疗用语进行规范;在诊疗处方上,中医处方及中药的药疗医嘱与西医处方和配药有很大不同,其配药流程和西医也不相同[3-4]。
肝硬化是由各种因素导致慢性肝损害的一类晚期肝纤维化疾病,肝移植是治疗肝硬化唯一有效手段,但受到供肝及费用等问题限制[5]。查阅近10年关于中医药治疗肝硬化腹水的相关文献可知,从病因病机及中医治疗两方面而言,肝硬化腹水的中医病机为正气亏虚,气滞、水停、血瘀3者错综为患,中医治疗以辨证分型施治、基本方加减、外治法为主[6]。
2 研究现状
在电子病历研究方面国内外均有一定成果。王昱[7]等基于电子病历数据进行临床接触支持研究,对电子病历数据进行挖掘。李昆[8]等利用深度学习方法结合传统机器学习方法,在电子病历匿名化、胎儿体重预测和疾病分类预测等方面进行预测模型构建的尝试。李准[9]等研究冠心病电子病历中与患者、疾病相关的指标,对冠心病进行分类,进一步探讨检查检验结果与用药之间的关联性。商金秋[10]等通过电子病历进行数据预处理和结构化提取,结合具体需求进行可视化组织与分析。蒋慧丽[11]等提出基于语义技术的电子病历信息集成框架,利用该框架解决电子病历集成及推理问题。陆奕宇[12]等通过对慢性乙型肝炎(乙肝)及肝炎后肝硬化中医证候分类进行系统生物学研究,为乙肝及肝炎后肝硬化的诊断和个体化治疗提供参考依据。本文以中医电子病历中肝硬化数据为研究基点,从中医治疗肝硬化的检查指标入手,通过对电子病历中检查数据进行主成份分析(Principal Component Analysis,PCA),提取出符合要求的致病指标(特征),构建致病指标和诊断结果二元组,将得到的致病指标与诊断结果二元组进行深度神经网络(Deep Neural Network,DNN)预测和支持向量机(Support Vector Machine,SVM)分类处理,通过对两种模型结果对比分析,对肝硬化中医电子病历中检查与诊断结果的关系进行研究。其中SVM是基于统计学习理论的结构风险最小化原则的分类方法[13], 是一种监督化学习分类模型。基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略是间隔最大化,最终可转化为一个凸二次规划问题的求解。基本原理是通过将非线性数据映射到高维特征空间,在这个空间构造最优分类超平面,该超平面使类别间的分类间隔最大,有效克服维数灾难和过拟合等传统算法的缺点,能处理小样本、非线性、高维数据,因而成为研究复杂系统问题的热点算法。
3 前期准备
3.1 数据来源
以某地区三甲中医院2015年1月-2016年1月期间诊断结果为乙肝肝硬化和非乙肝肝硬化的1 273例门诊记录的电子病历为数据来源(参照2011年8月中国中西医结合学会消化系统疾病专业委员会制定的《肝硬化中西医结合诊疗共识》[14])。字段主要由诊疗记录中的患者基本信息(门诊号、西医诊断、性别、年龄等)、检验(首次来末次检查总胆红素、凝血酶原时间、白蛋白等)、检查(部位、时间、报告结果等)以及中医诊断信息构成。
3.2 纳入标准
该中医院属于国家重点专科医院,中医电子病历数据结构化程度较为规整,根据筛查检验检查结果,借助具有多年临床经验的医生的指导,将有明确诊断结果的数据纳入。对于检查检验指标缺少数据则不纳入使用。不影响实验的指标缺失,如个人信息,纳入使用。按此标准进行统计纳入,最终符合要求数据为1 243例。
3.3 数据预处理
特指对中医检查数据的预处理,主要是针对中医检查数据中的常规字段,包括对检查数据进行修正和规范化。主要是对表意不明确或有歧义的数据进行修正,主要由临床医师进行人工筛查、纠正。对检查数据的规范化主要由于检查数据中存在一种指标有多种说法或有的说法不规范,先通过模糊查找,再通过医学相关专业人员辅助核定。
3.4 特征提取
完成源数据预处理后进行特征提取,主要是通过主成份分析法对肝硬化检查指标进行分析,提取数据中的中医检查数据,重点对中医检查部位、结果等方面进行主成份分析,具体步骤为:将检查记录中各项数据按句号进行分列,人工剔除不可用或无效信息指标;规整数据,统计诊断指标总数;统计源数据中每个诊断指标出现次数,计算各诊断指标频率;将各诊断指标频率除以诊断指标总数,计算每个诊断指标占有率;通过诊断指标占有率进行指标筛选,选取诊断指标占有率高的指标,确定为主要致病指标,即为特征。按照纳入标准完成数据预处理后,利用特征构建方法对检查记录各项数据进行分列,得到共包含指标数据4 914条(含重复项);对分列数据进行规整统计后共包含指标数据2 002条(不含重复项);对规整后数据进行统计指标占有率筛选后最后得到主要用于训练模型指标数据140条。
4 模型构建
本研究使用的中医电子病历门诊数据中包含明确的诊断结果,对于未包含明确诊断结果的数据进行剔除处理,通过对病例特征分析得到可用特征,将可用特征与疾病的明确结果相结合,构建致病指标与诊断结果二元组,将获取的特征按照one-hot representation编码规则进行编码,每一病例均以特征展开而构成特征向量,以此构建特征矩阵。将构建好的特征矩阵进行神经网络预测分析和SVM分类器训练,其中神经网络模型中输出层和SVM分类器结果均定义为二维向量形式,表示电子病历中检查结果为阴性和阳性,即代表是否患病。在神经网络训练过程中对每个训练样本存在一个标准输出,即标签y,取值为1或0,使用交叉熵损失函数优化此神经网络模型,其交叉熵表达式为:
l=-yln(y′)-(1-y)ln(1-y′)
(1)
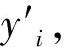
(2)
对于一个训练集St来说,将其均匀划分为多个小数据集(mini-batch):Sti,每个mini-batch中具有M个训练样本,对训练集Sti={x1,x2,…,xM}而言,交叉熵总和为:
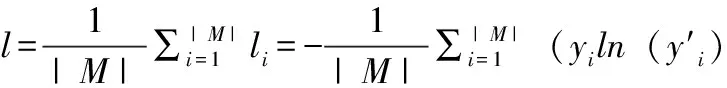
(3)
损失函数为l,因此优化目标是尽可能地减小l,即(min(l))。
神经网络预测模型,见图1。图例通过Visio绘制,最底层为输入层,也就是构建的特征矩阵,共140维;最顶层为输出层,与诊断结果相对应,共2维,即代表肝硬化检查结果是阴性还是阳性(是否患肝硬化)。
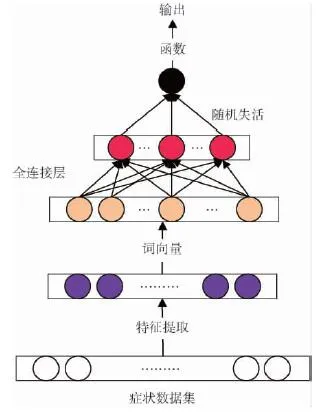
图1 神经网络预测模型
根据电子病历诊断信息可将诊断数据分为两类:诊断结果为阳性或阴性。构建出二分类SVM分类器,通过与神经网络模型相同的数据集进行训练,将结果与神经网络预测模型进行对比分析。
5 结果分析
深度神经网络预测结果,见表1、表2。两表分别是迭代100次和1 000次的结果,另外对训练和测试数据进行不同比例的预测。结果表明运用本研究使用的方法预测结果准确率可达到80%,其中训练数据和测试数据的比值在7∶3较为合适。
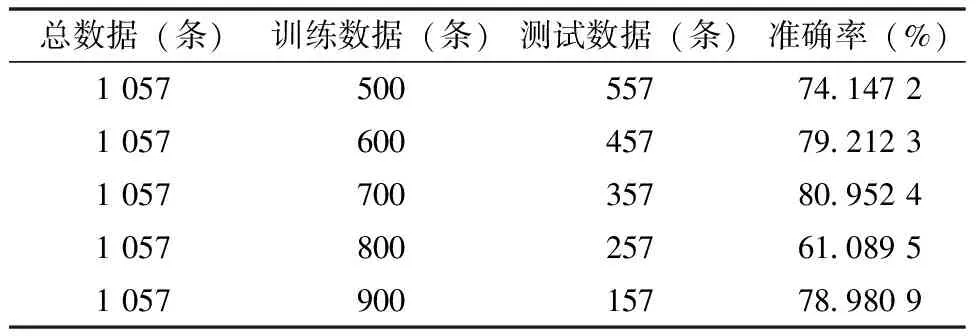
表1 预测结果(迭代100次)
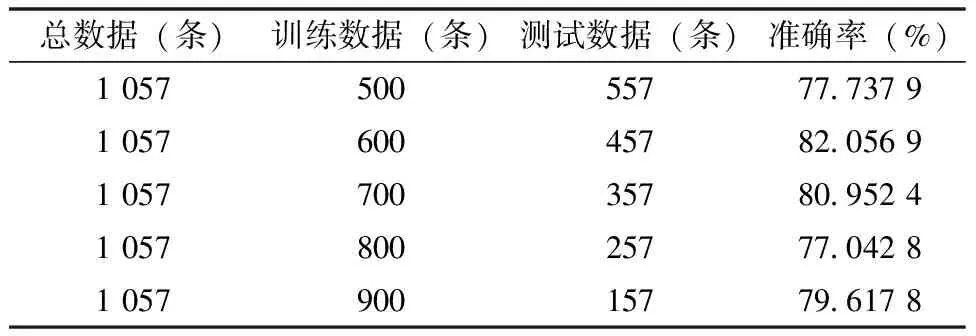
表2 预测结果(迭代1 000次)
在进行SVM训练中阳性和阴性分别用+1和 -1表示,通过已构建的特征向量,采用SVM模型进行训练,Libsvm开源软件包,利用n-fold进行交叉验证,其中n取值为10,通过反复试验跳转参数,最终结果,见表3。

表3 SVM实验结果
通过对比可以看出在两者预测准确率均达到80%的情况下神经网络模型准确率相对于SVM模型准确率要高。表明筛选出的诊断肝硬化的指标可作为诊断肝硬化核心指标,以该指标构建训练的模型可对患者进行肝硬化预测诊断,若将该模型应用于临床能够有效降低患者就医成本,提高医生诊疗效率,对临床诊断肝硬化或研究其他疾病具有一定指导意义。
6 讨论
6.1 电子病历缺陷
在互联网高速发展下电子病历普及程度越来越高,但各电子病历软件智能程度不一,特别是中医电子病历,其中的医用专业术语标准不统一且当前未形成统一规范,不同医生记录过程存在差异,在进行电子病历相关数据挖掘过程中存在各种问题,从而影响数据质量。
6.2 数据清洗
数据挖掘过程中不可或缺的重要步骤,决定后期挖掘效果和质量。由于中医电子病历中医用专业术语标准不统一、描述不规范,在进行数据清洗和预处理时需要剔除掉不可用、修改不规范、填补缺失值等,从而使得数据集减小,对模型训练有一定影响,同时由于数据预处理过程中需采用人工筛查、规整和规范化,可能造成异常或错误数据等问题,从而使得整体数据质量出现问题。
7 结语
在模型构建算法上,本文仅从神经网络模型和支持向量机分类模型出发,借鉴前人经验,缺乏其他算法的对比和对复合算法的构建。后续研究中将进行更加严格、规范化的清洗工作,以进一步提高模型准确性,采用更大、更有效的数据集进行模型训练,对更多算法进行对比,以求提出更适合肝硬化病症特点的算法进行算法复合模型训练,从多种角度进行探索,训练出准确率更高的模型,将模型投入临床试用,为中医临床提供辅助诊疗,为中医药智能化提供辅助。
