基于结构化方法的CBTC系统需求分析
2019-06-14吴耀东
吴耀东
(上海富欣智能交通控制有限公司,上海 201203)
1 CBTC系统概述
地铁CBTC信号系统是基于计算机和通信技术的列车运行控制系统,CBTC系统的主要设备包括车载控制器、轨旁区域控制器、联锁控制器等,都是基于微处理器的计算机设备,CBTC系统的主要功能都由这些计算机设备来承担,通过编制相应的专用软件来实现。所以,本质上讲CBTC系统是一个复杂的软件系统。
2 结构化分析方法概述
需求分析是软件系统开发中的一个关键环节,伴随着软件系统规模和复杂性的不断增长,传统的手工作坊式方法已经很难胜任。结构化分析方法能够很好的适应复杂软件系统的开发,按照“自顶向下逐层分解”的方式,可以有效应对大型复杂系统的分析。
结构化分析方法于20世纪70年代中期由E.Yourdon,Constaintine及DeMarco等人提出并得到广泛的应用,是一种面向数据流的分析方法。结构化分析方法利用图形表达用户需求,采用数据流图、数据字典、结构化语言等方式实现需求的清晰描述。
3 基于结构化方法的CBTC需求分析步骤
3.1 第1步:建立系统的分层数据流图
数据流图描述输入数据流到输出数据流的变换(即加工)过程,用于对系统的功能建模。数据流图的基本元素包括:
1)→数据流:由一组固定成分的数据组成,代表数据的流动方向;
2)□源或宿:由一组固定成分的数据组成,代表数据的流动方向;
3)=文件:使用文件、数据库等保存某些数据结果供以后使用;
4)○加工:描述了输入数据流到输出数据流的变换,即将输入数据流加工成输出数据流。
例如:CBTC的ATP 系统的第一层、第二层、第三层数据流如图1、2、3、4所示。
数据流图的分层绘制方式如下。
1)如图1所示的第一层数据流图也称为顶层图,顶层图中只有代表整个软件系统的1个加工(即ATP系统),描述软件系统与外界(源或宿)之间的数据流,该加工不必编号。
2)如图2所示的第二层数据流图也称为0层图,0层图只有1张。0层图中的加工必须编号,这里采用F1到F4的编号,即ATP系统可分解为F1到F4共4个加工。
3)如图3、4所示的第三层数据流图是对于0层图中加工的进一步分解,图中的加工必须编号,并且编号需要和其父图相对应,这里采用Fx.1、Fx.2并依次类推的形式。例如“F1列车测速定位”可以分解为“F1.1列车运动计算”到“F1.5确定位置不确定性”这5个加工。
4)第三层数据流图处于最底层,最底层的图也称为底层图,其中所有的加工不再分解成新的子图。
对于数据流的绘制有如下注意事项。
每个数据流拥有一个定义明确的名字标识,例如图1中的“进路状态”、“信号机状态”;
数据流可以在源和宿、加工以及文件之间流动。
对于文件的绘制有如下注意事项。
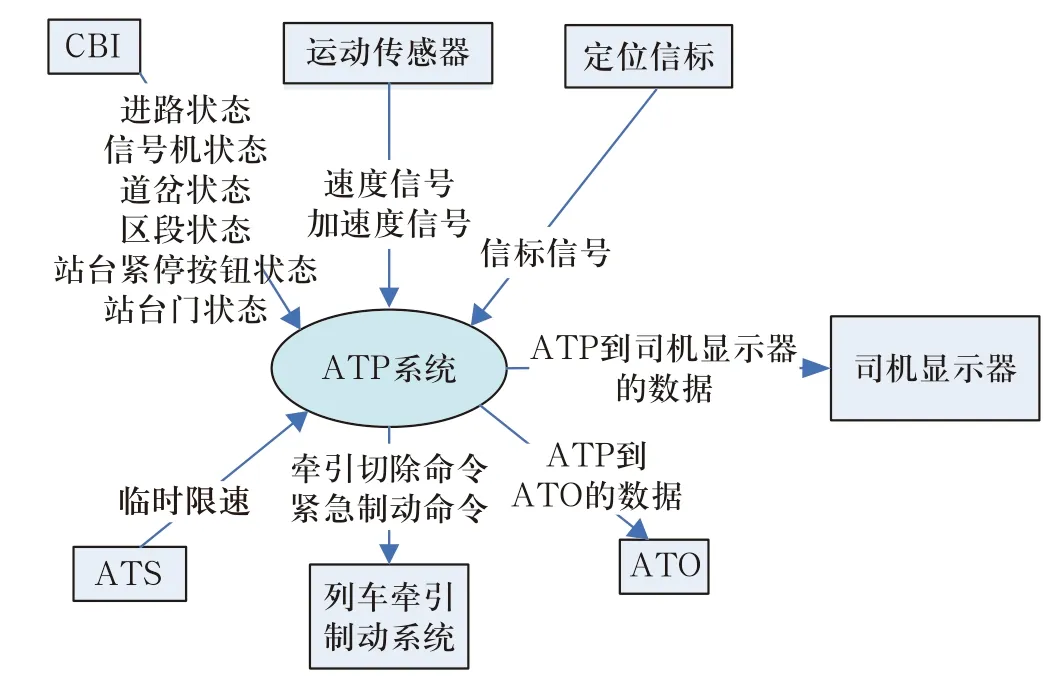
图1 第一层数据流图-ATP系统Fig.1 Layer 1 data flow diagram - ATP system
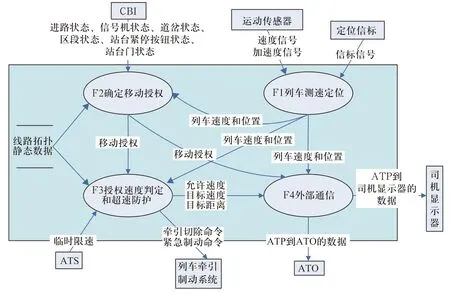
图2 第二层数据流图-ATP系统Fig.2 Layer 2 data flow diagram-ATP system
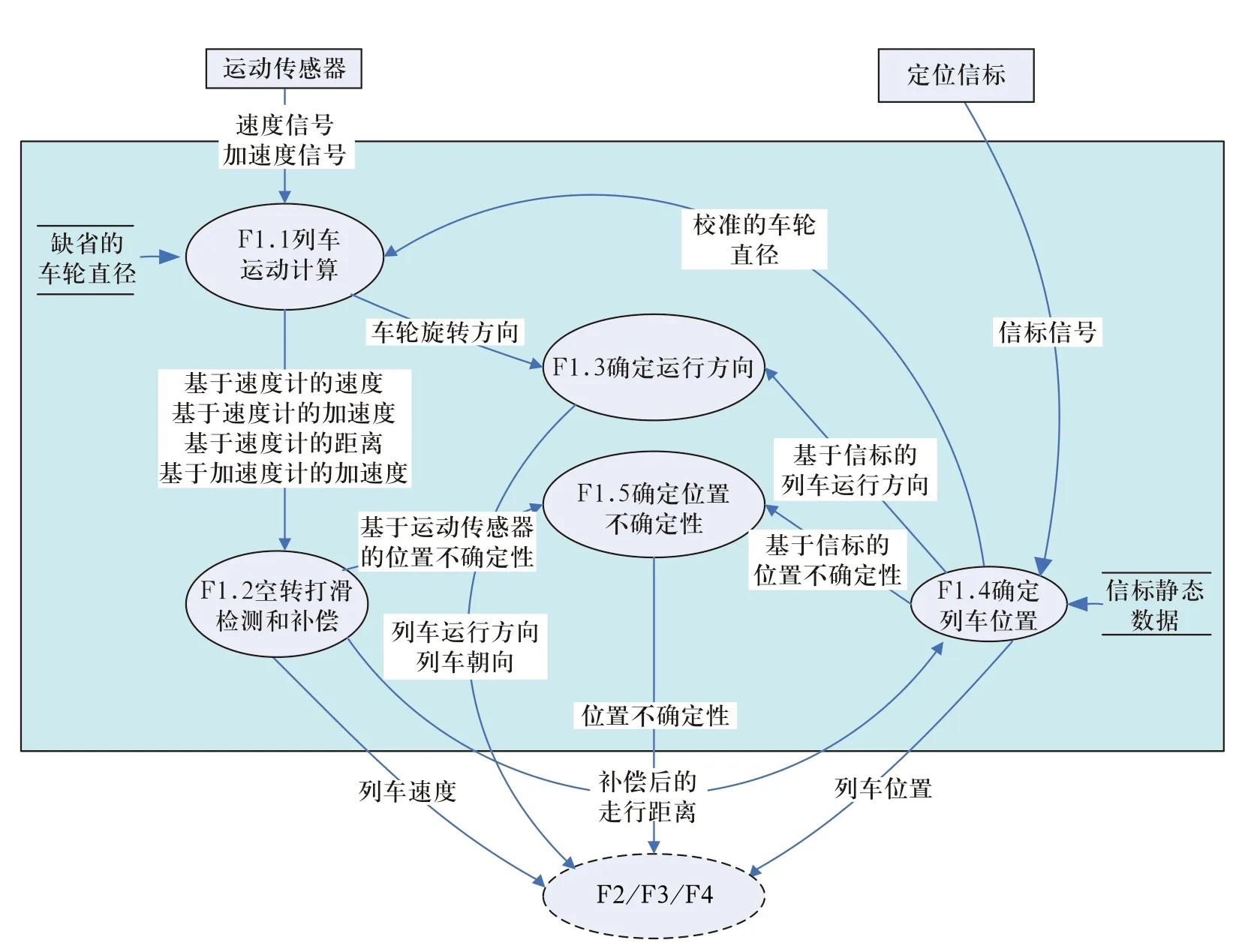
图3 第三层数据流图-F1列车测速定位Fig.3 Layer 3 data flow diagram-F1 train speed and position measurement
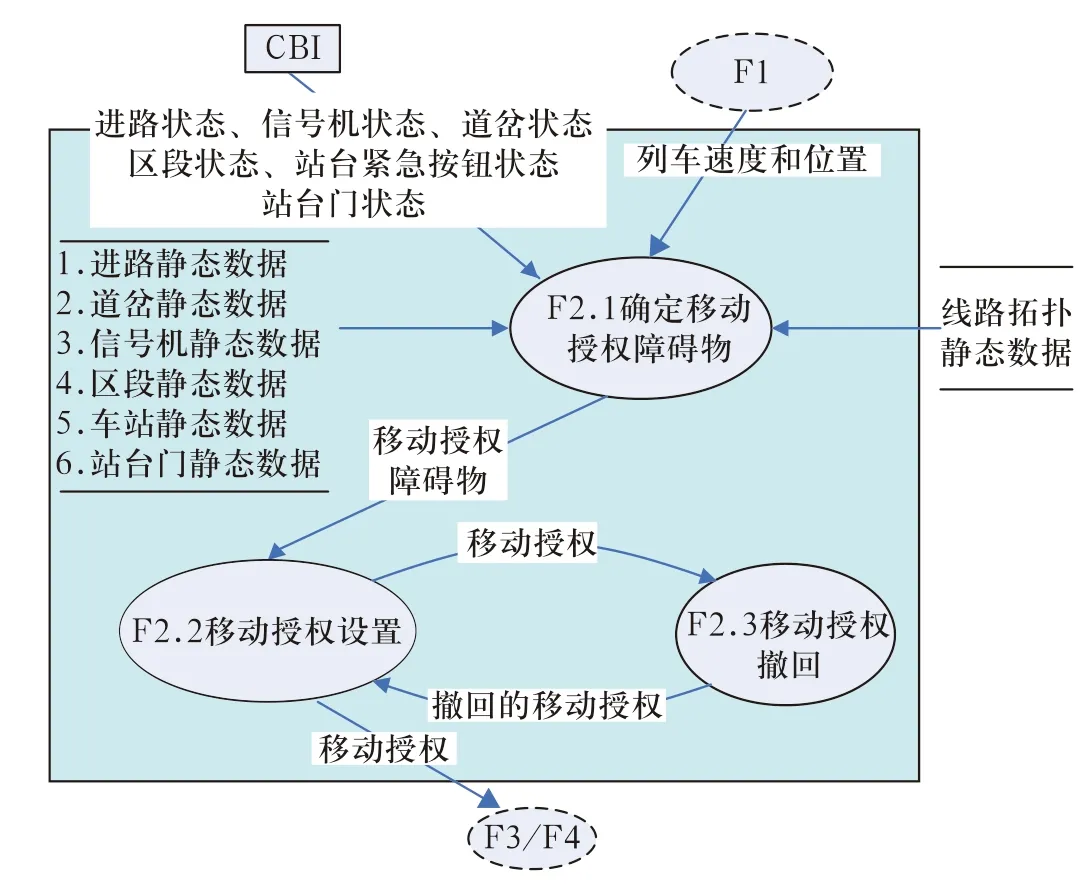
图4 第三层数据流图-F2确定移动授权Fig.4 Layer 3 data flow diagram-F2 MA confirmation
每个文件用一个定义明确的名字标识,如图2中的“线路拓扑静态数据”和图3中的“缺省车轮直径”都是文件的名字。
文件由加工进行读写。
对于源或宿的绘制有如下注意事项。
当数据流从该符号流出时表示是源,如图1中的CBI和“运动传感器”是源。
当数据流流向该符号时表示是宿,如图1中的“司机显示器”和ATO是宿。
当两者皆有时表示既是源又是宿。
3.2 第2步:建立系统的数据字典
数据字典对数据流图中的数据流(或文件)进行描述,通过在数据字典中建立一组严密一致的数据定义,可以帮助软件分析人员和用户之间交流,同时也有助于软件人员之间的交流,容易达成对数据的统一认识。当所有软件人员都根据公共的数据字典对数据进行描述和对模块进行设计,可以避免很多接口问题的麻烦。
在数据字典中主要包含下列信息。
1)名称:描述数据流的名称,每个数据流的名称必须各不相同。
2)来源:描述数据流的来源,可以是源或宿,也可以是文件或加工。
3)去向:描述数据流的去向,可以是源或宿,也可以是文件或加工。
4)数据流组成:描述该数据流的组成。一个数据流可能由多个数据项组成,如图1中数据流“ATP到司机显示器的数据”是由“列车速度”和“目标速度”等多个数据项组成的。
5)数据类型:描述数据流中每个数据项的数据类型和取值范围。
例如:对图1“第一层数据流图-ATP系统”中的数据流建立数据字典,如表1所示。
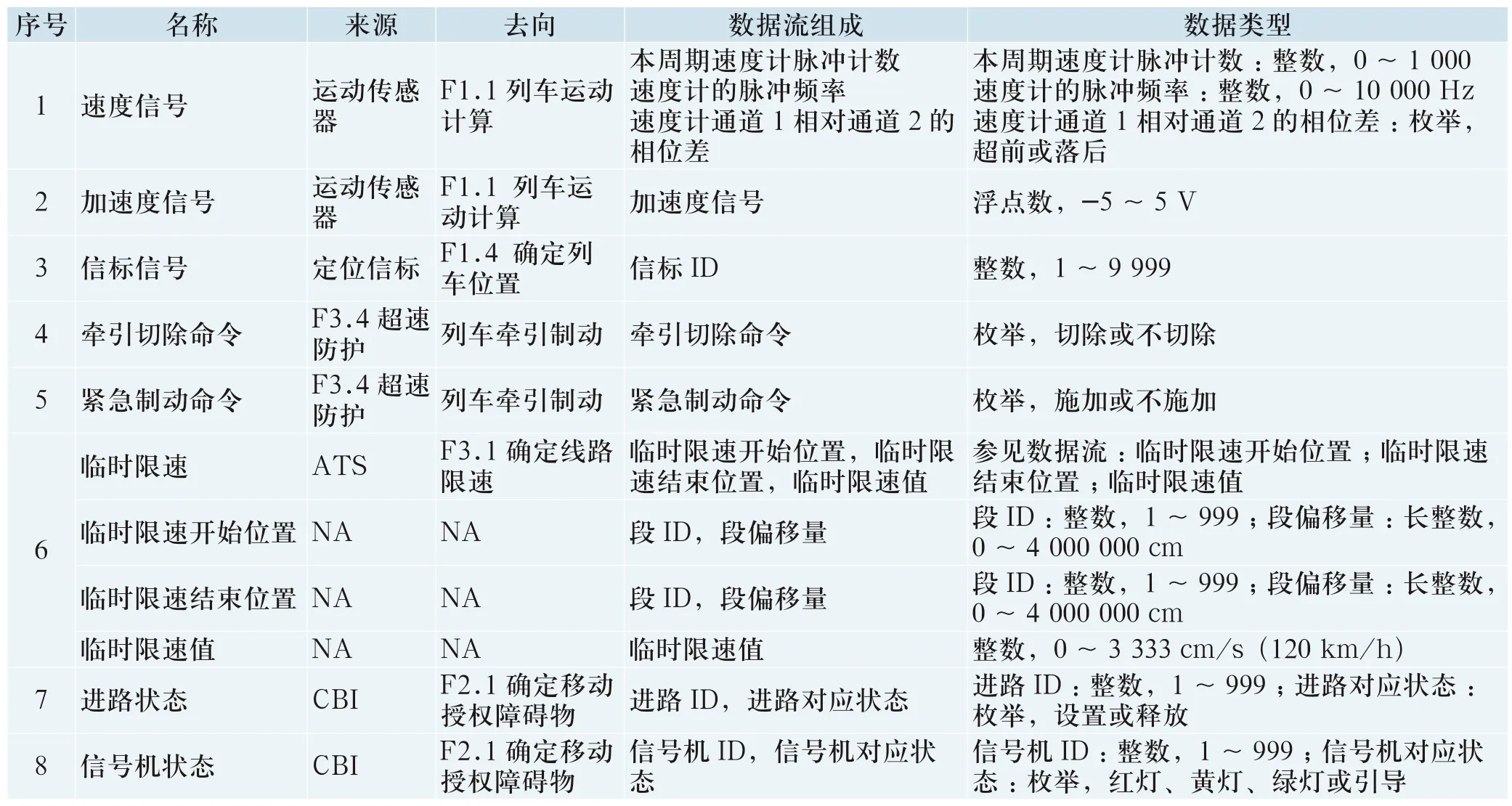
表1 “第一层数据流图-ATP系统”的数据字典Tab.1 Data dictionary of “layer 1 data flow diagram - ATP system”
对于数据流图中的文件,可以看做一种特殊的数据流,对其建立对应的数据字典。
例如:对图2中的文件“线路拓扑静态数据”建立数据字典,如表2所示。

表2 文件“线路拓扑静态数据”的数据字典Tab.2 Data dictionary of document “line topology static data”
3.3 第3步:建立系统的加工说明
加工说明是对数据流图中的每个加工所做的说明。加工说明由输入数据、加工逻辑和输出数据组成。输入数据是该加工要处理的源数据,加工逻辑主要描述把输入数据变成输出数据的策略和方法,输出数据是加工后的目的数据。
加工说明通常采用结构化语言,结构化语言是一种介于形式语言和自然语言之间的一种半形式的语言,是自然语言的一个受限制的子集。结构化语言和高级语言不完全一样,它结构通常分为内、外两层,没有严格的语法。外层语法比较具体描述操作的控制结构,采用顺序、选择和循环等控制结构将加工中的各个操作连接起来,并且还可以相互嵌套。内层语法比较灵活描述了具体的操作,主要明确地表达出要“做什么”,而不写出具体做的方法。
例如,对于图3中“F1.1列车运动计算”的加工说明如下所示。
1)输入数据
速度信号、加速度信号、缺省的车轮直径、校准的车轮直径。
2)输出数据
基于速度计的速度,基于速度计的加速度,基于速度计的距离,基于加速度计的加速度,车轮旋转方向。
3)加工逻辑
IF轮径已经校准 THEN
基于速度计的速度=(pi×校准的车轮直径)/(本周期速度计脉冲计数/速度计的脉冲频率)
基于速度计的速度=基于速度计的速度(本周期)-基于速度计的速度(上周期)
基于速度计的距离=(pi×校准的车轮直径)×本周期速度计脉冲计数/每周期的速度计脉冲计数
ELSE
基于速度计的速度=(pi×缺省的车轮直径)/(本周期速度计脉冲计数/速度计的脉冲频率)
基于速度计的速度=基于速度计的速度(本周期)-基于速度计的速度(上周期)
基于速度计的距离=(pi×缺省的车轮直径)×本周期速度计脉冲计数/每周期的速度计脉冲计数
END IF
IF速度计通道1相对通道2的相位差为超前THEN
车轮旋转方向=正向
ELSE
车轮旋转方向=反向
END IF
基于加速度计的加速度=加速度计信号×g/加速度计的满量程转换值
4 总结
结构化分析方法是一种基于数据流图的需求分析方法,具备一整套严格和完整的需求分析过程和方法。采用结构化分析方法,可以有效避免传统的手工作坊式需求分析方法中的个人随意性,提高需求分析的清晰性、准确性和完整性。在CBTC信号系统的开发中应用结构化分析方法,可以有效提高整个CBTC系统开发效率并降低开发成本。
