基于数据立方体的评估特征项生成方法
2019-06-13刘海洋唐宇波胡晓峰乔广鹏
刘海洋,唐宇波,胡晓峰,乔广鹏
(1.国防大学联合作战学院,北京 100091;2.航天工程大学,北京 101416)
典型的战区联合作战方案涉及要素众多、作战空间广阔、作战问题多样且指标关联复杂,针对相同的作战方案评估问题,不同的专家往往会给出不同的指标选取建议,就是同一个专家在不同作战阶段所选取的指标也会有所侧重。传统的自上而下逐层分解的指标生成模式[1]:一方面囿于专家经验的条条框框,在指标完备性上很难突破现有的认知;另一方面由于人工介入程度较高,在速度上很难实现快速提升,因此,传统的指标生成模式在作战态势快速变化的情况下显然无法满足需求。为解决评估指标快速选取问题,首先需要构建开放的基础评估指标库,并在此基础上针对特定的评估问题快速选取相关指标,类似于“搭积木”一样快速实现评估指标的组合,同时结合专家经验对指标进行适当的增减与微调,最终形成评估指标产品快速投入评估工作。
在基础评估指标库的构建过程中,评估指标需要相应的评估数据做支撑,而评估数据中蕴含了大量的数据特征,除了利用特征工程由人工构建有限的评估指标外,很多数据特征并未得到有效利用。多维数据模型是面向数据分析应用而提出来的一种直观的概念模型[2]。该模型将数据看作数据立方体(Data Cube)[3]形式。传统的数据立方体是以牺牲存储空间为代价来换取查询效率上的提升,其对所有可能的维度组合进行聚集计算,并将聚集结果进行实例化存储,以缩短查询响应时间[4-5]。为减小数据立方体的尺寸,很多压缩算法被相继提出,如Condensed Cube[6]、Quotient Cube[7]、Dwaf[8]等算法。文献[9-12]等通过使用MapReduce并行架构,实现数据立方体的并行建立、查询和更新等功能,提高了数据立方体的计算效率。文献[13]针对数据流的特点,提出了一种流数据立方体分析挖掘框架,文献[14]对维度属性中的概念分层特性进行了研究,文献[15]从复杂网络的角度对数据立方体内部结构特性进行了研究,文献[16]针对大数据背景下的数据立方体物化视图选择问题,提出了基于云计算环境的物化视图选择算法改进思路。国内外相关研究大多集中在数据立方体的压缩算法与查询效率上,对具有动态时序特性的数据研究相对较少。
依托国防大学兵棋团队研制的大型战役兵棋系统开展联合作战方案推演,能够为联合作战方案评估提供涵盖陆、海、空、天、网电等多维战场空间全过程推演所产生的全时空样本数据。本文按照从数据中获取指标的思路,以兵棋推演数据为基础,基于数据立方体框架构建评估特征项生成模型,利用不同维度组合生成评估特征项。围绕数据立方体中存在的“维度爆炸”问题,利用维度组合裁剪模型来缩小维度组合搜索空间,通过特征项标识算法对生成的评估特征项进行唯一标识,并采用移动时间窗口提取评估特征数据。所提取出的评估特征数据在某种意义上可以看作是评估问题在特定时空条件下所表征出来的特征信息,通过分析挖掘评估特征数据与评估问题的关联性,能够帮助指挥员从不同的视角、不同的侧面理解评估问题。
1 数据立方体框架
定义1:多维数据模型(Multi-attribute Data Model, MDM)
具有多个维度的数据记录,可形式化表达为S=(F0,F1,…,Fi:M),Fi表示维度特征,M为维度度量。
以夺取制空权作战为例,空中作战任务多维数据模型可表示为:
MDM=(作战时间,属性,任务类型,机型,活动空域,状态:数量)
其中,在多维数据模型S中的维度特征主要包括作战时间、属性、任务类型、机型、活动空域和状态等6个维度,特征的度量为飞机的统计数量。数据记录r=(XXXX,1,2,5,4,1:6)可解析为:“作战时间=XXXX”表示纪录作战发生的时刻(可精确至秒级),“属方=1”表示红方,“任务类型=2”表示空中侦察任务,“机型=5”表示某型飞机,“活动空域=4”表示在第4号空域内活动,“状态=1”表示飞机状态良好,“数量=6”表示飞机数量有6架。
定义2:数据立方体(Data Cube, DC)
给定一个时间段内的MDM,按照不同维度组合构建的一个数据集合。对于数据立方体中的每条数据记录r=(f1,f2,…,fn:m),其中r[Fi]=fi∈Fi,i=1,2,…,n,fi为特征Fi的值,m为度量值。
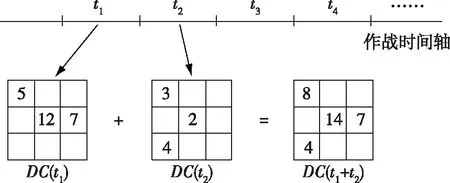
数据立方体可以理解为多维数据模型在某时间段内的集合,对于时间维度T,ti-1 定义3:父代单元和子代单元 对于数据立方体中的数据单元Cm和Cn,定义*表示该维度折叠且不考虑聚合计算,则Cm是Cn的父代(或者Cn是Cm的子代)可表示为: (1) 记为Cn[t]⊂Cm[t],即两个数据单元的时间相同,父代单元至少在一个维度上能够包含子代单元,且在其他维度上和子代单元的取值相等。父代单元与子代单元之间的关系可用数据立方体晶格表示[16],父子两代的数据单元具有连接关系,且由父代单元指向子代单元,在3个维度上的数据立方体晶格如图1所示。 图1 在3个维度上的数据立方体晶格 以空中作战任务数据立方体中的数据单元C0=(SIDE-1, J10B, AIR-ATTACK) 为例,其父代单元有如下7个: C1=(*, J10B, AIR-ATTACK) C2=(SIDE-1, *, AIR-ATTACK) C3=(SIDE-1, J10B, *) C4=(*, *, AIR-ATTACK) C5=(*, J10B, *) C6=(SIDE-1, *, *) C7=(*, *, *) 上述例子中没有显示数据单元的度量值M,父代单元的度量值可以由其子代单元的度量值通过聚合计算得出。 假设数据立方体的维度为N,则该数据立方体的维度组合规模为 MD=2N (2) 若数据立方体在每个维度上的取值基数为li,记为li=|Fi|表示第i维候选值的数量,其中i=1,2,…,N。则该数据立方体能够生成的特征项规模可达 (3) 在某时间段内考察数据立方体中的数据,时间间隔越小,时间分辨率越高,所产生的数据规模越大。若该时段T内有k个时间片段,则最终的数据规模为 (4) 举例来说,空中作战任务数据立方体在仅考虑属方、机型与任务类型3个维度的情况下,其维度组合有23=8种。假设属方维度包括红、蓝、绿3方,机型维度包括84种不同型号的飞机,任务类型维度包括14种不同类型的任务,则可生成的特征项数量为(3+1)×(84+1)×(14+1)=5 100。若考察时间段设为4个小时,时间窗口间隔为5分钟,则该时段内共有48个时间片段,最终形成的数据规模为48×5 100=244 800。 基于数据立方体框架,采用工程化的维度组合方法生成评估特征项,同时根据时间窗口大小,将数据切分为不同粒度的数据块,通过聚合计算获得与评估特征相对应的评估数据。在兵棋推演数据的基础上,数据立方体提供了有组织、时序化的汇总数据,因此能够在不同粒度层次上对数据单元进行较为全面的挖掘与分析,从而大大增强了探索式数据挖掘的能力,为后续的问题评估提供全量、实时和多层次数据支撑。 在利用数据立方体生成评估特征项的过程中,首先为缩小计算时间与存储空间上的成本,需要对维度组合空间进行适当的缩减;其次需要对大量的评估特征项进行唯一标识,以便于后续的计算与检索;最后在获取数据的时间窗口上应能够动态调整,以满足不同粒度上的评估需求。 由数据立方体模型产生的维度组合数量是幂级增长的,如给定n维记录r=(f1,f2,…,fn:m),则可以产生2n种维度组合。随着维度数量的增加,将会出现海量的维度组合,从而造成数据立方体的“维度爆炸”问题。因此,一般在维度的选择上,需要引入领域专家的先验知识,对相关维度的选取层次与取值范围进行适当的限定,同时考虑计算的时间效率和存储的空间效率,综合选取数据立方体的维度。 1)限定维度组合规则 从兵棋推演数据中抽取相关维度,需要领域专家的先验知识,而将抽取出的维度进行组合则需要考虑数据的涵义与推演的常识,部分不合理的维度组合将被剔除。以空中作战任务中的属方、机型和任务类型3个维度为例,机型维度中的歼10、歼11和歼20等机型应与属方维度中的红方相组合,与蓝方或绿方的维度组合均为不合理的维度组合,另这3种机型可派出执行空中巡逻、空中游猎等任务,而执行空中运输、电子对抗等任务的情况则应被剔除。因此,在考虑数据涵义与推演常识的基础上加入维度组合规则,能够排除掉很多不合理的组合情况,从而缩小了搜索空间,省掉不少没有意义的维度组合计算。 假设数据立方体有N个维度,第i个维度记为Di,i=1,2,…,N,维度Di的取值可用Dij表示,j=1,2,…,|Di|。维度Di与维度Di+1的组合记为(Di,Di+1),组合后生成的特征项集合可表示为S=(Di1,Di2,…,Dim)~(D(i+1)1,D(i+1)2,…,D(i+1)n)。在数据涵义已知的情况下,通过加入维度组合规则,将维度取值限定在有限个数量较小的集合中,避免出现不合理的维度组合情况。图2所示为一个在3个维度上的组合规则集合特例,其中|D1|=m,|D2|=n,|D3|=k,该维度组合的限定规则集合为 S1=D11~(D21,D22,…,D2i)~(D31,D32,…) S2=D12~(D2i,D2(i+1),…)~(D31,D33,…) … Sm=D1m~(D2(j+1),…,D2n)~(D31,…,D3k) (5) 图2 在3个维度上的组合限定规则集合 通常情况下,维度组合的限定规则可通过对兵棋推演数据的预统计获得,对各维度取值之间的组合情况进行计数,将计数值不为零的组合情况添加到规则集合中。限定规则也可使用排除规则,将不可能出现的维度组合情况加入到规则集合中,其作用原理与组合规则相同。在实际应用过程中,具体使用哪种规则应根据数据预统计情况综合判断。 2)限定维度组合测量阈值 数据立方体的聚合操作一般可以分为分布型(distributive)、代数型(algebraic)和整体型(holistic)3类[3]。在兵棋推演数据聚合操作中,常见的如sum和count等都属于分布型聚合操作。这类分布型聚合操作的父代单元聚合了其所有子代单元的值,由父代单元的取值可得到子代单元的上限和下限,而由子代单元也可以推理出父代单元取值的范围,如式(6)所示。 count(X)=sum({count(Xi|i=1,2,…,n)}) (6) 其中,父代单元X可由子代单元Xi集合组成。对于父代单元X下的任意子空间g的取值上下限如式(7)所示: count(g)=sum({count(Xi|i=1,2,…,n)}) count(g)=min({count(Xi|i=1,2,…,n)}) (7) 结合式(7)可知,父代单元与子代单元间的包含关系在分布型操作中体现出单调特性,即 Cac[count]>τ→Ca[count]>τ,Cc[count]>τ (8) 由上述父代单元与子代单元的上下限原理,可得维度组合测量阈值限定规则如下: 对于分布型聚合操作,如父代单元的测量值小于阈值,则所有它的子代单元的测量值必定小于阈值,因此可以裁剪掉所有子代单元。 如给定记录r=(a,b,c),若Ca[count]<τ,则Cab|ac|abc[count]<τ。对于n维度的数据,可先对每个维度进行单维度统计,假设经统计后有k个单维度数据单元的测量值小于限定阈值(一般设限定阈值为0),则可以裁剪的维度组合数量为2k,而对于数据库中每条数据记录可减少统计操作2k-n次。如果单维度阈值筛选效果不佳,也可尝试进行二维或高维的阈值筛选,其原理与单维度阈值筛选相同。由于兵棋推演数据中维度的取值往往具有稀疏性,所以裁剪模型通过限定测量阈值的方法通常可以剔除掉大多数的维度组合。 数据立方体通过维度组合产生了大量的特征项,而这些特征项中不同维度的属性值又包含多种类型,如离散型、连续型以及字符型等等。为便于后续计算,对于单个维度的不同属性值,还需要对其进行字典化处理,即以序列量化的形式对其进行编码。 特征项标识(Feature Identifier, FI)算法的功能就是把维度组合所产生的特征项映射成唯一整数,且算法支持维度或属性的扩展,即对现有维度或属性进行新增或修改都不会与原值产生冲突。在数据R=(F1,F2,…,Fn:M)中,|Fi|表示第i维的基数,使用下列步骤进行特征项标识。 1)由于维度属性值具有多样性,需要先把记录R的维度Fi映射成连续的自然数,即Fmap(fi)→Ni,0≤Ni≤|Fi|; 2)在步骤1)中产生n个自然数Ni,i=1,2,…,n,形成集合S=(N1,N2,…,Nn),对S中的任意非空子集,使用配对函数产生唯一的自然数标识。 定义4:配对函数(Pairing Function, PF) 配对函数的定义是把二维元组映射为一维元组,可形式化表示为π:N×N→N。一般情况下,配对函数是一类双射函数[17],在自然数域内具有单调递增的特性。 在元组维度较高的情况下,可使用嵌套模式进行映射,本文选择Cantor配对函数[18]进行配对映射。在对不同维度的属性取值进行编码的基础上,按照维度顺序对属性取值进行嵌套配对,把中间配对结果当成下一步递归操作的输入。Cantor配对函数的嵌套映射原理见式(9)。 (9) 当元组维度较高时,Cantor配对函数可采用嵌套模式生成映射值,而当某些维度基数较大时,映射结果往往会出现大数值的情况,给标识理解与后续计算带来一定的不便。此时,可考虑对配对函数进行部分改进,其基本思路是在不改变计算模型的情况下,尽量产生较小的映射值。 改进配对函数的理论依据如下: 1)在数据立方体中,数据单元描述与维度的先后顺序无关,即数据单元(F1,F2)=(F2,F1); 2)嵌套计算为倒序计算,数值排序越靠后则参与循环的次数就越多,其对映射结果的影响就越大。 定义5:改进配对函数(Improved Pairing Function, IPF) 改进配对函数的定义如式(10)和式(11)所示。 IPF(F1,F2,…,Fn)→|F1|>|F2|>…>|Fn| (10) 对给定维度Fi: freq(fi1)>freq(fi2)>…>freq(fin)→n1 (11) 式(10)表示对输入维度的先后顺序进行排序,即改进配对函数的输入维度顺序取决于维度基数大小,基数越大则维度越靠前。式(11)表示对维度取值的先后顺序进行排序,在把维度取值编码成连续自然数时,将小自然数赋给出现频率高(freq值大)的维度取值。通过对兵棋推演数据进行预统计,可以得到不同维度基数的大小和维度值的出现频率。使用改进配对函数能够有效减少大数值在嵌套中的计算次数,从而达到控制输出映射值的目的。 特征项标识算法先通过数据统计对维度顺序进行排序,并把维度值出现频率按照由高到低的顺序编码成由小到大的自然数,通过嵌套函数得到所有相关的维度组合,并使用Cantor配对函数获得所有特征项的唯一标识。结合维度组合裁剪模型,对特征项标识算法进行改进,可得到基于裁剪模型的特征项标识算法,如算法1所示。 算法1:基于裁剪模型的特征项标识算法 输入:数据记录r=(f1,f2,…,fi:m),裁剪阈值τ; 输出:数据r生成的所有特征项标识。 Step1: set Step2: Step3: (f1,f2,…,fj)←(f1,f2,…,fi)| Step4: 根据IPF模型中式(11)和式(12)进行排序编码操作,(f1,f2,…,fj)→(n1,n2,…,nj); Step5: set Step6: set Step7: begin for x∈{ Step8: Step9: end for; Step10: return 在数据立方体框架下,经过维度组合裁剪模型处理后生成的特征项,可视为有效的评估特征项,与评估特征项对应的评估数据需从兵棋推演数据中经聚合计算得到。由于兵棋推演数据本身带有时间标签,其具有内在的时序性,在对兵棋推演数据进行分析时应采用定制时间窗口按需在不同时间粒度上进行分析。 兵棋推演数据中的时间主要包括作战时间和物理时间,作战时间是按照虚拟的作战逻辑进行演化,而物理时间则是对发生具体操作的真实时间的记录,在作战方案评估过程中应以作战时间为主线对兵棋推演数据进行分析。在作战时间轴上对时间进行离散化处理,生成连续的时间片段,按照时间片段对评估特征项进行聚合操作,将得到的结果存入评估特征空间中。 图3 数据立方体时间窗口的聚合操作 如图3所示,数据立方体中的时间粒度选择支持时间窗口间的聚合操作,即小时间单元的累加可得大时间单元上的度量值。假设生成的评估特征项数量为n,对于任意第j个特征项,j=1,2,…,n,其在时间上的度量值均满足时间聚合计算条件,合并算式如式(12)所示: ∀1≤j≤n:DC[j,hj(ita+tb)]←DC[j,hj(ita)]+DC[j,hj(itb)] (12) 以某次兵棋推演数据为基础,讨论联合作战方案中制空权争夺问题。对制空权评估来讲,应重点考虑空中作战、地面防空、侦察预警、干扰压制、后装保障等方面的影响因素,以空中作战因素为例选取兵棋推演数据如表1所示,在属方、任务类型和机型3个维度上进行维度组合,度量指标为数量,时间为作战时间。 经数据预统计可知,属方维度的基数是3,任务类型维度的基数是14,机型维度的基数是84,不经裁剪生成特征项的规模为5100。根据维度组合裁剪模型,属方1对应的空中作战任务类型有12种,共有49种机型参与空中作战任务,每种空中作战任务类型对应的机型数量取值范围在[1,18]中,属方1可生成的特征项数量为99,属方2和3依次可生成50和57,故经裁剪后生成特征项规模为206项,裁剪率接近96%。 抽取作战时间为20XX年X月X日6:00-7:00,作战空间为XX号作战空域,统计在特定时间内能够对XX号作战空域产生影响的作战飞机数量,其中限制条件为空中任务编队距作战空域的距离同时小于探测距离与打击距离(或干扰距离)。设定时间窗口大小为5 min,时间间隔为1 min,共生成60组评估特征数据如表3所示。 考虑空中作战、地面防空、侦察预警与干扰压制4类影响因素,在实际实验过程中对部分维度属性取值在概念层次上进行了聚合,如雷达型号基数较大,则可按照雷达作用距离将其概括为远程雷达、中程雷达与近程雷达3个维度。针对制空权评估问题综合选取了107个特征项,抽取1个小时内100个作战区域的近4 000组评估特征数据作为特征数据集,利用兵棋推演实验来判定制空权标签数据,基于WEKA平台分别采用朴素贝叶斯(NB)、支持向量机(SVM)、多层感知机(MLP)和随机森林(RF)4种机器学习方法进行有监督训练,训练结果如表4所示。 由表4可知,除NB算法外,其余3种算法的分类准确率均超过了92%,而RF算法的准确率略高于SVM和MLP算法。从机器学习算法的分类效果来看,依据本文提出的方法所生成的评估特征项涵盖了制空权评估的部分关键特征,能够为分析制空权评估问题提供有效支撑。由107个特征项与标签组成的训练样本集在制空权分类中的部分数据分布情况如图4所示。 表1 兵棋推演空中作战任务数据示例 表2 经裁剪后生成的特征项规模统计 表3 空中作战任务评估特征数据抽取示例 表4 评估特征数据在4种不同机器学习算法上的训练结果对比 图4 部分评估特征数据在结果分类上的分布情况 基于数据立方体的评估特征项生成,本质上来讲就是提取在特定时空条件下对当前作战态势产生影响的外在表征,且尽可能涵盖相关的关键特征。从部分专家经验来看,大规模的评估特征项可能会有很多没有军事意义或毫无价值,但是从数据的角度来看,特征的意义与价值则取决于特征数据与最终评估问题的相关性。结合从兵棋推演数据中获取的评估特征数据,构建评估特征空间,可为后续的基于机器学习的评估模型提供可靠的训练样本数据集。在评估特征空间构建过程中,主要考虑特征的完备性和数据的时效性两个方面。在完备性方面,主要采用维度组合的方式生成大规模的特征项,再利用裁剪模型缩小评估特征空间;在时效性方面,主要采用移动时间窗口的方法提取特定时段内的特征数据,较好的体现了作战态势的动态演化以及作战效果影响的时延特性。

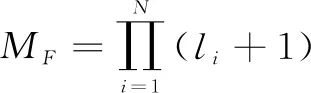

2 评估特征项生成模型
2.1 维度组合裁剪模型

2.2 特征项标识算法

2.3 时间序列索引描述
3 实验结果与分析





4 结束语
