基于Fisher判别法的飞发故障分系统预测模型研究
2019-06-13朱兴动章思宇范加利
朱兴动,章思宇,范加利
(1. 海军航空大学,山东 烟台 264000;2. 海军航空大学青岛校区,山东 青岛 266000)
飞机发动机是飞机核心部分,发动机的可靠性直接影响飞机能否正常完成飞行任务,因此对飞机发动机的故障和维修记录的统计分析就显得尤为重要,对于提高飞行的安全性和整机的可靠性有着极大的作用。本文在充分查阅某型飞机的资料和相关单位搜集机务维修记录与数据的基础上,运用多元统计分析理论,提出了一个基于Fisher判别分析法的分类预测模型,找出各影响因子与故障所在系统之间的内在联系[1]。
1 飞机发动机分系统与数据结构化
1.1 飞机发动机分系统
发动机作为飞机的核心组成部分,其本身结构十分复杂。通过比对GJB4855—2003和技术资料可知,该型飞机中所有系统与飞机发动机相关的有发动机系统、发动机起动系统、发动机操纵系统、发动机指示及告警系统和动力装置系统五类[2]。据此,可以根据故障件型号将所有故障分到这五个系统中。
1.2 数据的预处理与标准化
飞机发动机的维修记录多为自然语言记录,且项目较多,较为繁杂,不便于使用数据统计分析工具进行分析判别。为了更有效地使用维修质控记录,需要进行筛选和标准化等一系列数据预处理工作。
1)选择影响故障分布的指标
影响故障分布的指标有很多,如发生故障时飞行的总时间、总架次、故障部位等。根据经验,选取故障发生月份、故障发生部位、故障件返修次数、故障件修后时次、飞机修后工作时间、专业、发动机修后工作时间、发现时机、故障件无故障工作时次等9个指标作为故障分系统的因变量。在这九个指标中,月份、故障发生部位、专业、发现时机为自然语言叙述,其余指标为数值。
2)数据的标准化方法[3]
如使用SPSS工具对数据进行分析,需按照一定的规则将部分非结构化数据标准化。为此,本文使用自行编写的程序,先扫描所有故障记录,对各选定指标的具体名称,按照出现次数进行统计,统计结果按频数从小到大排序,再赋予相应的数值,完成自然语言记录的标准化。最终,标准化的结果如表1所示。
具体指标对应的各名称和值如下:
①月份:一至十二月分别赋值1~12。
②故障发生部位:1-弹舱,2-设备舱,3-后机身,4-电源舱,5 -其他,6-起落架舱,7-前机身,8-座舱,9-发动机舱。
③-专业:1-综合航电,2-电气,3-仪表,4-飞机,5-机械,6-发动机,7-特设。

表1 数据标准化结果
④发现时机:1-滑行,2-周期性工作,3-换季检查,4-其他,5-飞行中,6-更换发动机,7-定期检查,8-空中,9-直接机务准备,10-飞行后检查,11-飞行启动,12-特定检查,13-再次出动准备,14-机械日,15-预先机务准备。
⑤系统:1-发动机操作系统,2-动力装置,3-发动机系统,4-发动机操纵系统,5-发动机指示及告警系统。
除上述4个自然语言描述的指标和发动机系统之外,故障件修后时次、飞机修后时间、发动机修后工作时间、故障件无故障工作时次的数据均为数值,为更便于进行数据分析,将发动机修后工作时间、故障修后时次、飞机修后工作时间、故障件无故障工作时次等几个数值较大的指标进行概化,分为0,0-500,500-1 000,1 000-1 500,1 500-2 000,2 000小时以上6个档次,并根据不同档次从大到小依次按0-6赋值。
通过以上规则,使用自行编写的数据标准化程序完成数据标准化,为统计及计算过程做好数据准备。
2 数据分析与模型的建立
2.1 影响指标筛选
影响发动机故障分布的指标多种多样,且每个指标对于分类结果的影响并不相同,为了简化模型与计算过程,需要通过一定的分析手段去除一些非关键的指标。
使用SPSS统计分析软件,得到组均值均等性检验表如表2所示。
表2中,各统计量含义和取值范围如下所示。
Wilks Lambda∶Wilks Lambda是组内平方和与总平方和之比,取值范围为0~1,值越小说明该因素对模型影响越大[4]。
F:即F检验,用于检验模型中的各个因素是否可以用于模型的估计,F没有取值范围,值越大说明该因素越适合模型。
df1:表示自由度。

表2 组均值均等性检验表
df2:无特殊意义,需满足df1+df2=N,N为模型的样本数量。
Sig.:Sig.表示显著性,取值范围为0~1,值越小说明组间的差异越显著。
在筛选过程中,最需要关注的是显著性指标。由表中数据最后一列Sig.值可以看出,月份、故障件返修次数和发现时机3个指标的值超过了0.05,这就意味着,在0.05的显著水平上,不能拒绝月份、故障件返修次数和发现时机这三个指标在分组的均值相等的假设,即认为其余六个指标在分组的均值是有显著差异的。因此,可以认为月份、故障件返修次数和发现时机这三个指标对于分类影响不大,为简化模型和计算,之后的计算过程中将不再考虑这三个指标。
2.2 Fisher判别分析
2.2.1 Fisher判别法简介
Fisher判别法是一种经典的分组判别法,其基本思想是将高维的数据点投影到低维空间,使得数据点更加聚集。当分组数为k时,指标为p个,借助方差分析构造出k个判别函数,函数的通式如下所示:
(1)
其中,确定参数ci的原则是使组间差距最大,组内差距最小。对于一个未分类的样本数据,将p个指标分别代入求出Fi值后,值最大的对应的分组即为该样本所在组[5]。
2.2.2 数据集检验
在使用Fisher判别分析前,需要对数据进行检验,以便确定Fisher法是否适用于目前的数据集。检验的方法主要是通过计算数据集的Fisher典型判别函数得分情况,即计算典型判别式的特征值和在组差异的显著性值。特征值占总体特征值的比例越大,也即正则相关性值越大,说明典型函数的判别能力越强,显著性值越小,说明该典型函数在分组时的差异更显著。
将数据输入程序,经过计算获得如表3、4所示的结果。
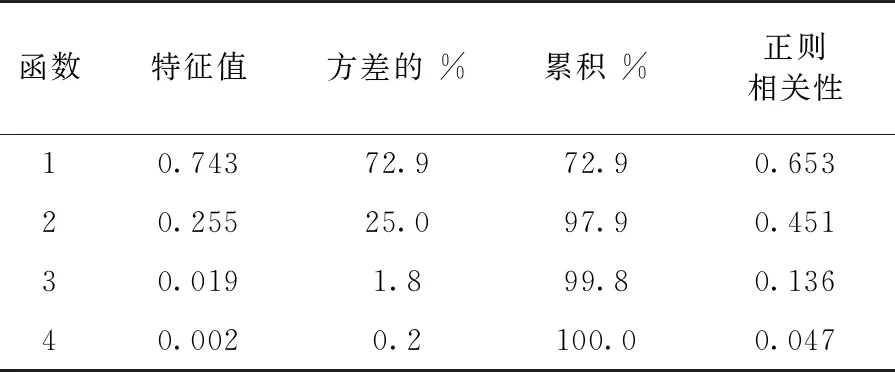
表3 特征值

表4 Wilks Lambda
由表3和表4的检验结果可以看出,分组需要四个Fisher典型判别函数。其中判别函数1至判别函数3在显著水平0.05上判别效果是显著的,且前三个判别函数可以解释整体方差的99.8%,说明前三个函数可以较好的对数据集进行分组,即该数据集可以通过Fisher判别犯法进行分组的。因此可以认为,Fisher判别分析是适用于当前数据集的[6]。
2.2.3 系统分组模型的建立
Fisher判别法致力于寻找一个最能够反映组与组之间差异的投影方向,即寻找使组之间差异最大,每个组内部离差平方和最小的线性判别函数[7]。
多个分组的Fisher判别函数系数的求法如下所述,设有k个分组G1,G2,…,Gk,其均值和协方差矩阵分别为μ1,μ2,…,μk和Σ1,Σ2,…,Σk,从k个分组中抽取一个含p个指标的观测样本,假定建立的判别函数为
C(Y)=c1Y1+…+cpYpC′Y
(2)
其中,系数c1,c2,…,cp确定的原则是使得组间差达到最大,而组内差到达最小。
当X∈Gi时,有
i=1,2,…,k
(3)
令
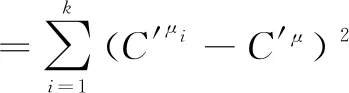
(4)
B相当于组间差,E相当于组内差,使用判别分析的思想,构造的最大特征根,而系数向量C为最大特征根对应的特征向量[8]。
(5)
求得Δ(C)极大值,即可得到判别函数,显然B0,E0均为负定矩阵,Δ(C)的极大值方程为
|B0-λE0|=0
(6)
根据以上计算思想,将数据集输入SPSS统计分析软件,使用SPSS聚类分析功能进行模型的训练[9],获得系统判别函数的系数如下表所示。
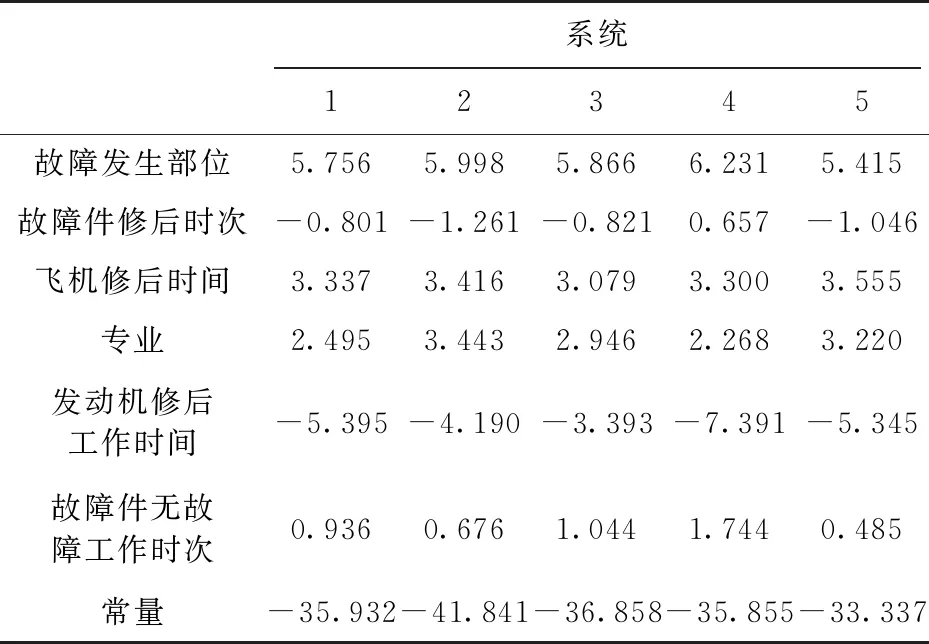
表5 分类函数系数
由表5可得六个系统判别函数分别为:
F1=5756x1-0801x2+3337x3+2495x4-
5395x5+0936x6-35932
(7)
F2=5998x1-1261x2+3416x3+3443x4-
4290x5+0676x6-41841
(8)
F3=5866x1-0821x2+3079x3+2946x4-
3939x5+1044x6-36858
(9)
F4=6231x1-0657x2+3300x3+2268x4-
7391x5+1744x6-35855
(10)
F5=5415x1-1046x2+3555x3+3220x4-
5345x5+0485x6-33337
(11)
其中,x1为故障发生部位,x2为故障件修后时次,x3为飞机修后时间,x4为专业,x5为故发动机修后工作时间,x6为故障件无故障工作时次。
假设故障发生在起落架舱,故障专业类别为特设专业,且该故障件的修后时次为141.3小时,该机发动机修后工作时间为100小时,距飞机上次大修时间为1000小时,该故障件的无故障工作时间为200小时,在这种情况下,根据前文所述的数据标准化方法,向判别函数组中代入以下参数:
通过计算可得到各方程的值为
根据Fisher判别法的判别标准,由于在5个F值中F5最大,故认为若符合上述情况时,故障最有可能发生在系统5,即发动机指示及告警系统中。
模型的分类效果如图1所示。
由图可以看出,第1、4、5三组与其他分组之间相距较远,分类效果较好,而2、3组之间距离较近,导致系统分类可能会出现差错,影响分类结果的准确性。
3 模型的检验与效果评估
为了检验模型的判断结果的正确性,下面将使用欧氏距离法进行验证[10]。
3.1 欧氏距离法原理
欧氏距离法是一种通过计算观测点到组质心距离,通过比较距离大小来进型分类的方法[11],观测点到组质心距离最近,则说明观测点属于该组。
欧氏距离法分两步,第一步计算观测点坐标值,计算公式如下所示:
(12)
其中,方程的个数由典型函数判别式个数来确定,Xi为计算出的坐标值,xi为输入参数,n为输入参数的个数。
第二步则通过欧氏距离计算公式得到观测点坐标值到质心的距离,公式如下所示:
(13)
其中,X为组质心坐标值,n为坐标的维数。
3.2 模型检验
通过SPSS计算可得源数据集的标准化典型函数判别式和组质心处函数分别如表6和表7所示,由前文所述,由于第四个方程的置信度未到达要求,故仅用前三个方程进行计算。

表6 标准化典型函数判别式系数

表7 组质心处函数
由表中系数可得观测点的坐标公式如下所示:
X1=-0265x1-0830x2+0008x3+0439x4+
1585x5-0495x6-0369
(14)
X2=0479x1+0434x2-0363x3-0333x4-
974x5+0601x6-2354
(15)
X3=0605x1-0072x2+0287x3+0497x4-
1101x5±0003x6-7684
(16)
其中,x1为故障发生部位,x2为故障件修后时次,x3为飞机修后时间,x4为专业,x5为故发动机修后工作时间,x6为故障件无故障工作时次。
代入前文所述的参数,由公式(14)、(15)、(16)通过计算可得该观测点的坐标如下所示:
再将观测点的坐标代入公式(13)中,使用表7 中的组质心函数得到该观测点到各质心的距离为
可以看出,D5的距离最短,因此认为在该情况下发生的故障是属于系统5,即发动机指示及告警系统,这与通过模型判断所得结果相一致,说明模型计算所得结果是准确的。
3.3 模型效果评估
常用的预测模型有许多种,如趋势外推模型,线性回归模型,神经网络等等。下面使用多元线性回归预测模型[12]来对数据进行分析预测。
通过SPSS软件计算得到多元回归预测模型如式(17)所示,拟合效果如图2所示:
Y=-0172x1-0064x2+0109x3+0065x4-
0409x5-0161x6+5188
(17)
其中,x1为故障发生部位,x2为故障件修后时次,x3为飞机修后时间,x4为专业,x5为故发动机修后工作时间,x6为故障件无故障工作时次。

图2 多元线性回归预测模型拟合效果
通过实际的数据检验,多元线性回归模型的综合预测正确率为40.9%,而Fisher故障分系统预测模型的最终预测正确率为74.4%,可见在预测正确率上,分系统预测模型的预测效果优于多元线性回归模型。
4 结束语
本文使用Fisher判别法,设计了一种系统故障预测模型,并使用欧氏距离法验证了模型预测的准确性。相比于其他常用预测分析模型,本模型采用Fisher判别分析思想,易于理解和实际应用,且分类效果较为良好。通过大量实际维修记录数据的检验,该模型可以对70%以上的数据样本进行正确分类。但是,由于机务维修记录往往存在错漏和不准确的现象,导致预测结果的准确率会受到一定的影响。随着维修记录的数据不断增加,新的影响指标的加入,该模型的预测准确性将会随之增加,同时挖掘出数据与数据之间更有价值的信息。
