A Frame Breaking Based Hybrid Algorithm for UHF RFID Anti-Collision
2019-06-12XinyanWangMinjunZhangandZengwangLu
Xinyan Wang ,Minjun Zhang and Zengwang Lu
Abstract:Multi-tag collision imposes a vital detrimental effect on reading performance of an RFID system.In order to ameliorate such collision problem and to improve the reading performance,this paper proposes an efficient tag identification algorithm termed as the Enhanced Adaptive Tree Slotted Aloha (EATSA).The key novelty of EATSA is to identify the tags using grouping strategy.Specifically,the whole tag set is divided into groups by a frame of size F.In cases multiple tags fall into a group,the tags of the group are recognized by the improved binary splitting (IBS)method whereas the rest tags are waiting in the pipeline.In addition,an early observation mechanism is introduced to update the frame size to an optimum value fitting the number of tags.Theoretical analysis and simulation results show that the system throughput of our proposed algorithm can reach as much as 0.46,outperforming the prior Aloha-based protocols.
Keywords:RFID,anti-collision,aloha,binary splitting.
1 Introduction
Radio frequency identification (RFID)technology will undoubtedly play a key role in the future development of Internet of Things (IoT)[Iera,Floerkmeier,Mitsugi et al.(2010)].Conventionally,a RFID system consists of a reader and multiple low-cost tags attached to the items to be tracked.Tag collision is a critical issue in an RFID system.It originates from the fact that tags within the vicinity of the reader share a wireless channel.When multiple tags backscatter data to the reader at the same time,the signals interfere with each other,causing the reader to not effectively retrieve the information of any one tag [Bolic,Somplot-Ry1 and Stojmenovic (2010)],which significantly degrades the identification performance,especially in a ultra-high frequency (UHF)RFID system with a high density of RFID tags.Therefore,an anti-collision mechanism is required to tackle the tag collision problem.In addition,considering the low-cost of passive tags and their extreme simplicity nature associated strict constraints are placed on the design of collision arbitration,whose intelligence almost rely on the reader [Vales-Alonso,Bueno-Delgado,Egea-Lopez et al.(2011)].
Anti-collision algorithms for passive RFID system generally can be divided into two categories:tree-based algorithms [Su,Xie,Yang et al.(2017);Cui and Zhao (2010);Su,Sheng,Xie et al.(2018)] and Aloha-based algorithms [Wu and Zeng (2010);Chen,Liu,Ma et al.(2018);Chen (2009)].In tree-based algorithms,the reader recursively divides the collided tag set into several groups until a group has a single tag that can be read without collisions.According to the splitting mechanism,the tree-based algorithms can be classified as query tree (QT)[Su,Xie,Yang et al.(2017)] schemes and binary splitting (BS)schemes [Cui and Zhao (2010);Su,Sheng,Xie et al.(2018)].Specifically,in BS solutions,the collided tag set is separated by a random number generated by the tags,while in QT methods,such separation process is done by their IDs.Technically,QT algorithm is a deterministic solution whose core is based on collision bit identification and tracking technique [Lai,Hsiao and Lin (2015)].However,in practical UHF RFID system,the location of the collision bits is difficult to detect accurately by the reader,because the frequency offset is generated during each backscattering of a tag,which causes the data asynchronization at the reader side [Angerer,Langwieser and Rupp (2010)].Therefore,the QT algorithm is not suitable for a UHF RFID system.
Among Aloha-based algorithms,the Dynamic frame slotted Aloha (DFSA)has been widely adopted by UHF RFID standard,including ISO 18000-6C and EPC C1 Gen2,to deal with the tag collision problem.In DFSA,the reader deploys a dynamically changing frame to read tags,where time is sequentially separated into several frames,with each frame is further divided into multiple time slots.Each frame corresponds to an identification round.During an identification round,a tag randomly selects a slot to respond to the reader.For the DFSA algorithm,a maximum system throughput can be achieved when the number of tags equals to the frame size.Since the cardinality of tag population is unknown to the reader,the DFSA algorithm needs to embed the cardinality estimation function.In order to ensure the accuracy of cardinality estimation,most previous methods [Wu and Zeng (2010);Chen,Liu,Ma et al.(2018);Chen (2009)] incur large computational overhead.Considering most RFID portable readers are only equipped with a single-chip microprocessor,it is challenging to handle the increasing computational overhead in practice.Therefore,an estimation algorithm with a high computational overhead is not recommended as a solution to the cardinality estimation procedure.
Recent works Chen et al.[Chen,(2014);Solic,Radic,and Rozic (2014);Wu,Zeng,Feng et al.(2013);Su,Sheng,Hong et al.(2016);Capetanakis (1979)] have presented many energy efficient algorithms with low computational overhead.The author in Chen [Chen (2014)] introduced a fast in-frame adjustment (FIFA)anti-collision algorithm.The FIFA assigns a few specific time slots to the tag backlog estimation and frame size adjustment.The FIFA significantly reduces the computational complexity compared to conventional algorithms [Wu and Zeng (2010);Chen,Liu,Ma,et al.(2018);Chen (2009)].However,the performance of FIFA is sensitive to the initial frame size.Solic et al.[Solic,Radic,and Rozic (2014)] presented an Improved Linearized Combinatorial Model (ILCM)which only involves some low-cost operations,so it works for implementation.Since the ILCM adopts a frame-by frame (FbF)tag quantity estimation on the basis of the count value of idle,successful and collision slots experienced in the previous full frame,the performance of ILCM is limited to the accuracy of a single estimation.Therefore,its performance deteriorates with the large scale of tag number.In Wu et al.[Wu,Zeng,Feng et al.(2013)],a hybrid protocol named adaptive binary tree slotted Aloha (ABTSA)has been proposed by embedding the merits of tree-based and Aloha-based protocols.The prototype of binary tree slotted Aloha (BTSA)algorithm is proposed in Su et al.[Su,Sheng,Hong et al.(2016)].The tags fall into a collided slot will be recognized by a basic binary splitting method at once,while the remaining tags will wait until the foregoing tags are successfully identified.When the size of a frame is approaching to the tag population,BTSA can achieve an asymptotic system throughput of 0.43,which is higher than that of DFSA algorithms.However,since the tag population is unknown to the reader,the BTSA’s performance is poor when adapting to a wide range of tags is required.The ABTSA is an enhanced version of BTSA.The ABTSA adopts the technique of Q-algorithm in EPC C1 Gen2 standard:the reader adjusts the frame size based on the response of tags slot-by-slot (SbS).Since the ABTSA can maintain a reasonable frame size for the tag backlog,it can achieve stable system throughput at about 0.40.Su et al.[Su,Sheng,Hong et al.(2016)] presented an effective frame breaking policy named detected sector based dynamic framed slotted Aloha (ds-DFSA)to reduce the computational cost and improve the reading performance of Aloha-based algorithms.The highest performance in terms of system throughput peaks at 0.41.
To further enhance the reading efficiency and guarantee the reliability of DFSA,we propose an enhanced adaptive tree slotted Aloha (EATSA)for the UHF RFID system.In EATSA,the reader starts a reading process by broadcasting an appropriate frame consists of several slots.Each tag randomly picks one of a number of time slots and responds to the reader.The reader can observe three states for a given time slot:idle,successful and collided.Since EATSA is also based on Aloha algorithm,its performance will be unavoidably related to the tag backlog and initial frame size.The EATSA can adjust the frame size closing to the number of tags via an early observation mechanism,while the collided tags are resolved by the binary splitting based on the idle slots elimination.Benefiting from the early observation mechanism and IBS,the identification performance of the RFID system can be dramatically improved.The simulation results reveal the significant improvement in system throughput of an RFID system by using EATSA.Note that the improved system throughput is realized with reduced computational complexity in our proposed methods.
2 The proposed EATSA algorithm
The proposed anti-collision approach is constituted by two phases:optimum frame size determination and effective binary splitting for each collided slot.Specifically,the EATSA algorithm uses slot observations from a small portion of time slots in a frame to set the optimum frame to fit the rest tags.If the ongoing frame does not best fit the current tag backlog,the reader will terminate this reading process early and update a new frame size for upcoming round.Otherwise,the reading round will continue,and the collided slots will be immediately resolved by our proposed binary splitting method.To determine the optimum value of frame for tag population,an estimation method can be given as [Su,Sheng,Hong et al.(2016)]:

whereSdsandCdsrepresent the numbers of successful and collision slots counted in the proportion (also called detected sector)of the frame.Fdsindicates detected sector size.SinceFdsis the part of the overall frame,it changes as the full frame changes.nestis estimated tag quantity before current identification round.According to (1),the reader terminates the reading round in advance if thenestdoes not fall within the optimal range corresponding to the current frame size.In other words,the reader needs to use an updated frame size and detected sector to launch a new round of reading.It is noted that the estimated tag backlog isnestsubtracting the successful slots during current identification round.The above iterative process will continue to run until the appropriate frame size is detected.According to the previous works [Su,Sheng,Hong et al.(2016)],the optimal range of tag quantity for each frame size can be summarized in Tab.1.
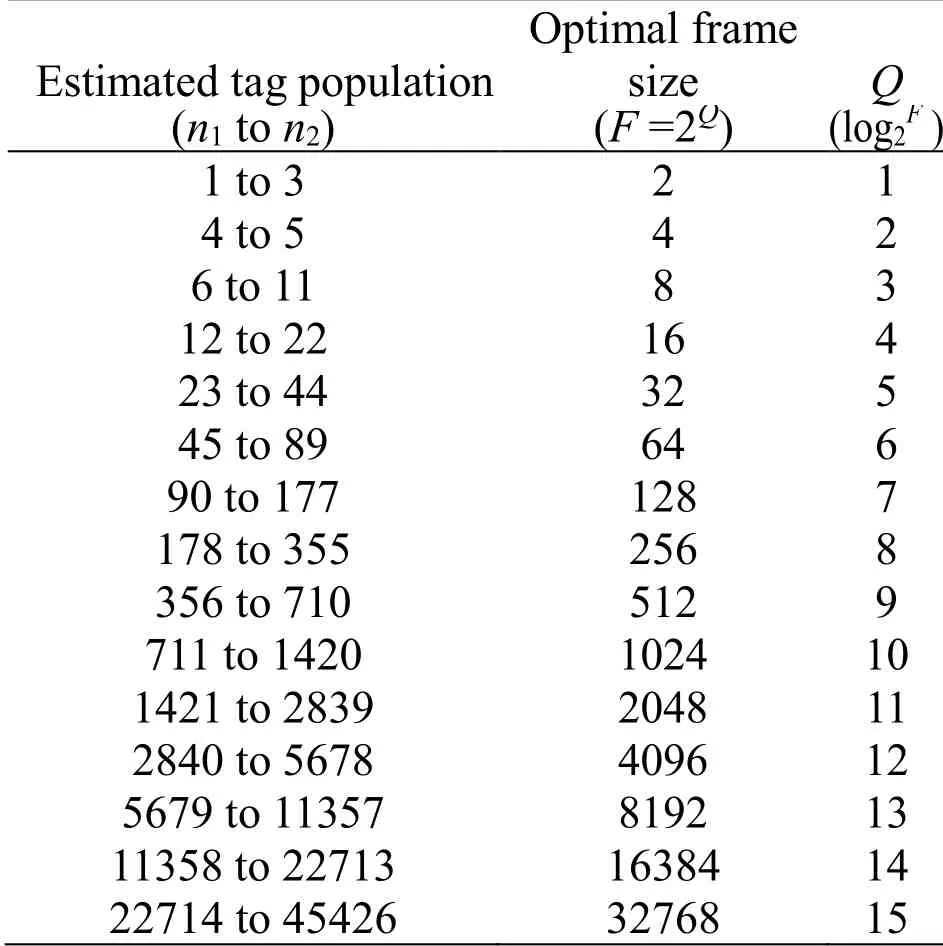
Table 1:The Optimal Relationship between frame size and tag population
The EATSA is described in Fig.1.As can be observed,the reader continues the current identification round after determining the optimal frame.The reader records the collided slot index and queries tags by the IBS method if an appropriate frame size is obtained.Fig.2 shows the flowchart of the IBS.As shown in Fig.2,the idle slots introduced by BS algorithm of ABTSA are removed with a schedule of IBS.Moreover,in IBS,designing a 1-bitRsignal can be used to assist collision arbitration,thereby reducing the transmission of redundant data during arbitration.Therefore,the proposed EATSA can significantly improve the identification performance.

Figure 1:The flowchart of the proposed EATSA
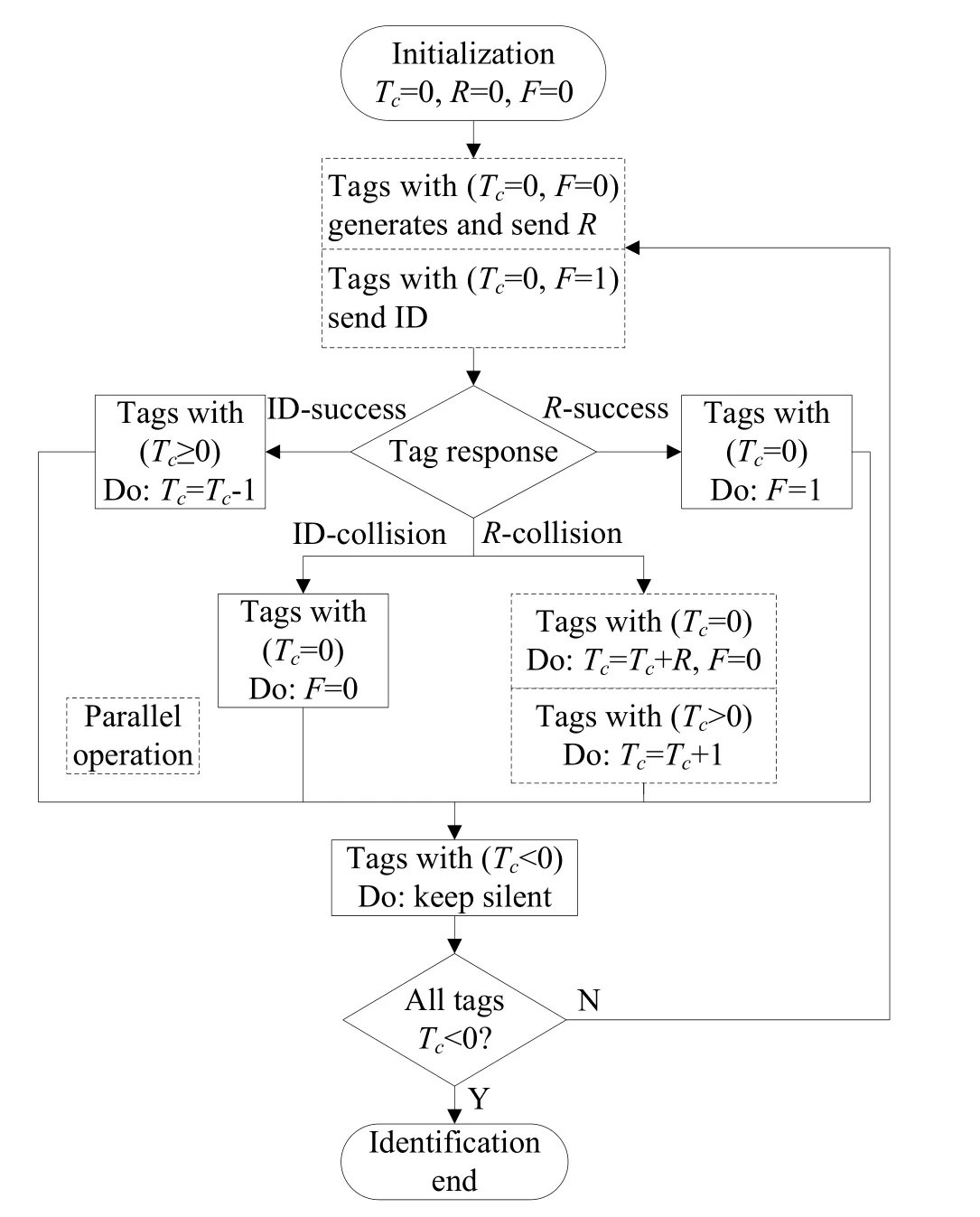
Figure 2:The flowchart of the IBS
In EATSA,an initial frame size may be not optimal for the tag backlog.However,the frame size will be adjusted by the adjustment strategy described in Fig.1.After several rounds of frame size determination phases,the reader can find a suitable frame for the tag set to be identified.If the optimal frame size is detected,the ISB nested in EATSA can achieve the optimal efficiency.We also use a visual example,as shown in Fig.3,to illustrate the superiority of the proposed algorithm.In the example,it is assumed that the tag number to be identified is 8,and the frame size is initialized as 8.The ILCM algorithm estimates the cardinality using the count value of collision slots and successful slots observed in the full frame.The ds-DFSA allocates separate frames for each collision slot to resolve them.The ABTSA and EATSA determine the optimum value of frame size for the tag backlog,and the collided tags are identified by BS and IBS,respectively.As can be seen from Fig.3,the EATSA consumes the least slots than other methods.It is foreseeable that as the number of tags continues to increases,its performance advantages will become more apparent.
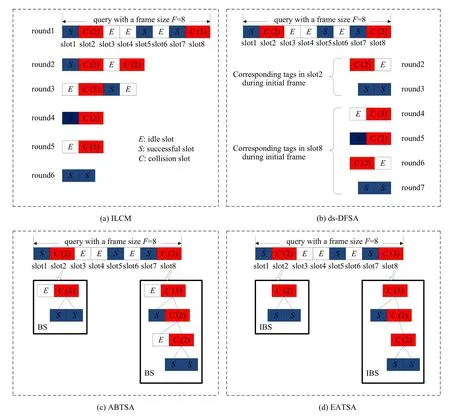
Figure 3:An identification example of various algorithms
3 Performance analysis of the proposed EATSA
In this section,we theoretically analyze the performance of EATSA,specifically the total number of slots and system throughput.The number of total slots equals the number of successful,idle and collision slots.The system throughput is defined as the ratio of the number of successful slots to the total number of slots required to identify all tags involved in these successful slots.
Lemma 1.LetNIBS(m)indicates the slot number consumed by IBS to identifymtags.Then,NIBS(m)is calculated as

Proof:The reading process of the binary splitting can be regarded as a depth-first traversal of a complete binary tree where it iteratively divides the collision tag set into 0 and 1 groups.Therefore,all intermediate nodes in the tree can be considered as collision slots,while leaf nodes correspond to idle slots or successful slots.Since all of idle slots are removed,the total slots consumed by IBS to identifymtags are

whereC(m)is the number of collision slots caused by BS traversingmtags.LetI(m,k),S(m,k)andC(m,k)represent the number of idle,successful and collision nodes,respectively,generated by the BS in identifyingmtags in thek-th layer of the tree.ThenC(m)is

Letp(k)=1-2-kdenotes the probability that a node on thek-th layer of the tree is empty,then we have

Hence,C(m,k)can be derived as
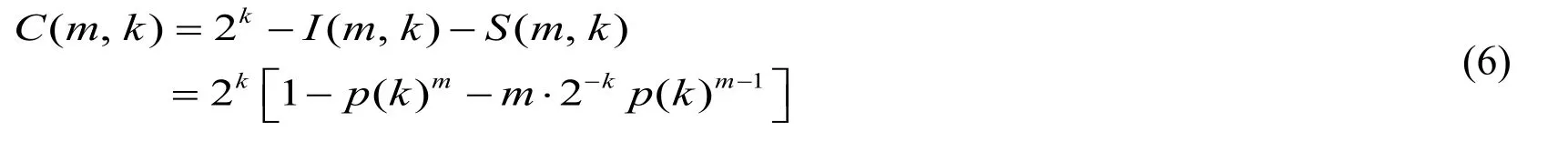
According to (3),(4)and (6),the Lemma 1 can be yielded.
Theorem 1.The optimal expectation of the number of total slots consumed by EATSA algorithm to readntags is

Proof.Given an initial frame sizeF,the probability ofrtags falling into one of theFslots satisfies binominal distribution and can be denoted as

LetAr(r=1,2,3,…,n)denotes the number of slots includingrtags.The expectation ofArcan be given as

So,the number of slots consumed by EATSA algorithm to readntags is expressed as

WhenF=n,EATSA algorithm can minimize the slot number to identifyntags.That is to say the optimal expectation of the number of total slots can be achieved.It is reasonable to assumeF>>1,from (8),we can have

Therefore,according to lemma1,(10)and (11),the(n)can be further expressed as

Therefore,Theorem 1 can be yielded.
Theorem 2.The optimal system throughput of EATSA algorithm is

Proof:From the Theorem 1 and the definition of the system throughput,we have

Therefore,Theorem 2 can be yielded.It is noted that Theorem 2 reveals the performance limit of the proposed EATSA under perfect condition i.e.,the tag backlog is known for the reader.In the simulations,performance comparison shows that the solution proposed in this paper has considerable advantages in both perfect and imperfect conditions.
4 Simulation results
In order to verify the performance of EATSA algorithm,we performed Monte Carlo simulation and compared it with priori arts including FIFA,ILCM,ABTSA and ds-DFSA.All simulation experiments are repeated 500 times,and then the average is taken as the result.Fig.4 compares the system throughput of various algorithms,the initialQare from 4 to 7 (F=2Q)while the tag number increases from 100 to 1000,and the variation interval is 100.Since all of the above five algorithms are Aloha-based,their performance is affected by the initial frame size.Among these algorithms,the ILCM is most sensitive to the initial frame size.When the tag number is far away from frame size,the ILCM is unable to tune a proper frame to fit the unread tags,and cause performance degradation.That is to say,the stability and scalability of ILCM are poor and cannot adapt to the tag number varying within a large dynamic scale.

Figure 4:Simulation results:system throughput of various algorithms
Compared to the FbF tag quantity estimation in ILCM,the ABTSA adopts the SbS estimation mechanism,so ABTSA can guarantee more stable performance.Although a more accurate estimation can be achieved due to the SbS mechanism,the required costs may be extremely high because examination and adjustment should be performed at every slot.Such highly accurate estimation may also dramatically increase the computation complexity when implementing into a capability-limited reader.From the implementation point of view,a compromise between estimation accuracy and computation complexity should be considered.To reduce the computation complexity,ds-DFSA and EATSA introduce the frame breaking policy for frame size adjustment.These two algorithms determine optimum value of frame on the basis of the observation results in a fraction of the current frame.If the ongoing frame does not best fit the current tag backlog,the reader will terminate this reading process early and update a new frame size for upcoming round.Since estimation is only performed over a few slots,the impact of the estimation error it produces on overall performance is weakened.FIFA adopts the similar early observation mechanism.The computation complexity of ds-DFSA,EATSA and FIFA algorithms are significantly reduced.Also can be seen from Fig.4,the average system throughputs of five algorithms from the highest to the lowest are EATSA,ds-DFSA,ABTSA,FIFA and ILCM.Specifically,the average system throughput of EATSA is about 0.4560 which is higher than the upper bound of the system throughput of existing Aloha-based algorithms.In order to better compare the performance of EATSA with existing literatures,Tab.2 summarizes the average system throughput of various algorithms and gives its amplification ratio based on the ILCM algorithm when an initial frame size set to 16,32,64 and 128,respectively.
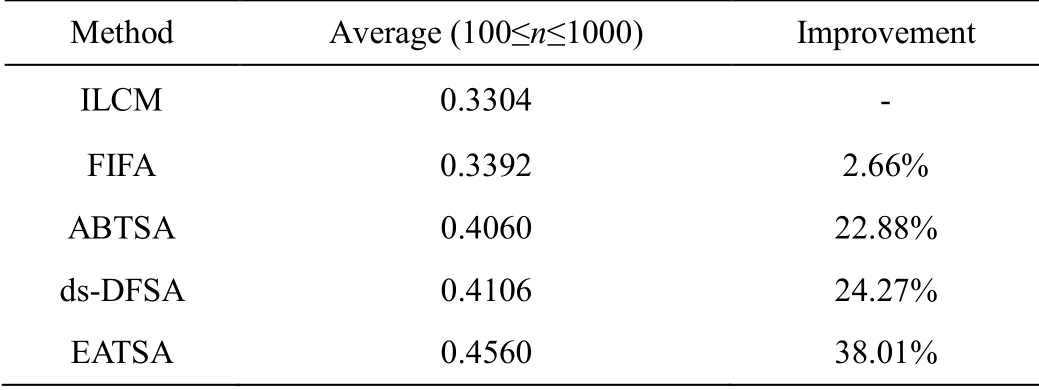
Table 2:Comparison of system throughput for various algorithms
Fig.5 shows the simulation results on system throughput under both perfect and imperfect conditions.The initial frame size is set as 128.As can be seen from Fig.5,the result of imperfect condition is close to that of perfect condition.However,limited by the estimation accuracy,the performance under imperfect condition has 5% performance loss in comparison with the result under perfect condition.
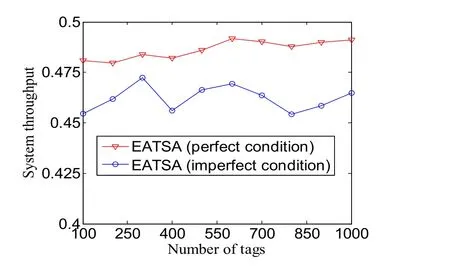
Figure 5:System throughput under both perfect and imperfect conditions
5 Conclusion
We proposed a new anti-collision algorithm for the UHF RFID system that can achieve good performance.The proposed scheme is based on the frame breaking policy and the IBS method.To reduce the computational complexity of the algorithm and improve the identification performance,the proposed solution adopts only one early examination of current frame size to determine the optimality of the frame size and use IBS method to identify the collided slot one by one.Theoretical analysis and simulation comparisons verify the advancement of the proposed algorithm compared to prior arts.
杂志排行

Computers Materials&Continua的其它文章
- Development of Cloud Based Air Pollution Information System Using Visualization
- A Learning Based Brain Tumor Detection System
- Shape,Color and Texture Based CBIR System Using Fuzzy Logic Classifier
- LRV:A Tool for Academic Text Visualization to Support the Literature Review Process
- Application of Image Compression to Multiple-Shot Pictures Using Similarity Norms With Three Level Blurring
- On Harmonic and Ev-Degree Molecular Topological Properties of DOX,RTOX and DSL Networks