基于行人属性先验分布的行人再识别
2019-06-11吴彦丞陈鸿昶李邵梅高超
吴彦丞 陈鸿昶 李邵梅 高超
近年来,随着监控设备在公共场所的普及,行人再识别技术越来越受到人们的重视.行人再识别是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术.但是由于光照、遮挡、行人姿态等问题,同一行人在不同场景中的外观呈现出较大差异,这给行人再识别研究带来了巨大挑战.为了有效应对这些挑战,广大研究者提出了很多解决方法.
1 相关研究
目前的行人再识别算法大体可分为三类,分别是特征表示学习、距离度量学习和基于深度学习的方法.特征表示学习方法利用视觉特征对行人建立一个具有鲁棒性和区分性的表示,然后根据传统的相似性度量算法(欧氏距离等)来计算行人之间的相似度.文献[1]在提取出行人前景的基础上,利用行人区域的对称性和非对称性将前景划分成不同的区域,对于每个区域,提取带权重的颜色直方图等特征描述它们.文献[2]对于提取出的颜色直方图特征,使用PCA(Principle component analysis)对其进行降维.文献[3]结合方向、颜色、熵等多种特征,分级识别行人.虽然特征表示学习的思想较为直接简单,易于解决小规模数据集的行人再识别问题,但是在光照、视角、姿态变化较大的情况下,特征表示学习方法的效果很差.
距离度量学习是一种利用测度学习算法得出两张行人图像的相似度度量函数,使相关的行人图像对的相似度尽可能高,不相关的行人图像对的相似度尽可能低的方法.代表性的距离度量学习算法有文献[4],其中将行人再识别问题转化为距离学习问题,提出了一种基于概率相对距离的行人匹配模型.文献[5]在不同的特征子空间中利用不同的核函数对距离进行度量.文献[6]基于马尔科夫模型对行人之间的距离进行度量.在大规模数据集下,距离度量学习计算开销过大,计算效率过低,容易陷入局部最小值,准确率不高.
深度学习近年来在计算机视觉中得到了广泛的应用,因此不少学者研究并提出了基于深度学习的行人再识别算法.文献[7]最先将深度学习应用于行人再识别领域,使用卷积神经网络提取行人的特征.随后不断研究对其进行改进.文献[8]提出将LSTM(Long short-term memory)模型结合进卷积神经网络中,提高了网络对时序特征的提取能力.文献[9]将注意力模型结合进CNN(Convolutional neural network)网络中,提升了模型的特征提取能力.基于深度学习的行人再识别近年来成为该领域的主流方法,相对于传统方法,具有识别精度高,鲁棒性好的优点.
上述方法有个共同的特点,就是它们仅仅考虑了行人图片的标签信息,也就是只使用了行人ID这个标记信息,并没有采用行人的属性信息.为此,近年来,随着带属性标签行人数据库的出现,有研究人员提出了基于属性的行人再识别方法,比如文献[10−11]使用行人属性进行行人再识别,达到了很好的识别效果.由于基于属性学习的方法具有更符合人类的搜索习惯,能应用于零样本学习等优点,因此当前这类方法成为该领域的研究热点.其中,文献[10]主要针对监控场景下行人属性的识别做出了改进,主要提出了两个行人属性识别网络DeepSAR和DeepMAR,前者对每个属性进行单独预测,后者联合多属性同时预测,在预测每个属性时,考虑到属性内正负样本不均衡的情况,利用数据先验分布对属性预测的权值进行调整,从而提高了行人属性的识别效果.文献[11]提出一种联合识别行人属性和行人ID的神经网络模型,大幅度提高了行人再识别的准确率,作者首先对大规模行人再识别数据集Market 1501[12]和DukeMTMC[13]进行了行人属性的标注,然后基于这些标注图片,设计实现了APR(Attribute-person recognition)神经网络,该网络对输入图片同时进行行人属性和行人ID的提取与识别,将识别结果与图片标注标签进行比对,比对结果作为反向传播的依据,训练得到网络,从网络中提取出代表行人的向量,进行距离度量计算,得到再识别的结果.该网络充分利用了行人的ID信息和属性信息,相对于已有方法,有效提高了行人再识别的精度.本文在APR的基础上,进一步进行了三个方面的改进,首先,网络结构上的改进,在网络中添加了一层全连接层.根据文献[14]的研究,全连接层可以提高网络在微调后的判别能力,保证源模型表示能力的迁移;然后,针对数据集中属性类之间的数量不均衡问题,在损失函数中对各属性的损失基于其包含的样本数量进行了归一化处理,提高网络对不平衡数据的处理能力;最后,针对数据集中各属性正负样本的数量不均衡问题,利用数据中各属性分布的先验知识,通过数量占比来调整各属性在损失层中的权重.测试结果表明,本文算法在公共实验数据集上的实验效果优于目前主流的行人再识别算法,尤其是首位匹配率(Rank-1),相对于APR网络,也是有了较大幅度的提升.
本文其余章节的组织安排如下.第1节介绍本文提出的用于提取行人属性和ID的行人再识别网络结构;第2节介绍本文提出的运用数据先验知识的损失函数设计原理及实现;第3节介绍本文算法在公共数据集上的实验结果及分析;第4节总结全文以及展望.
2 用于提取行人属性和ID的行人再识别网络结构设计
在本节中,主要介绍用于提取行人属性和ID的行人再识别网络结构和算法流程.为了提取到高鲁棒性的行人属性特征描述子,基于数据分布的先验知识,本文对APR网络进行了大幅度改进,具体网络结构见图1.主要分两个部分介绍改进后的网络:基础网络部分,行人特征向量度量部分.下面详细介绍这两个方面的内容.
2.1 模型架构
本文的基础网络主要由两个部分组成,以全连接层FC0为界线,前半部分为残差网络(Resnet[15]),后半部分为行人属性和ID特征分类网络.首先介绍前半部分,在计算机视觉里,特征的等级随着网络深度的加深而变高.研究表明,网络的深度是实现好效果的重要因素,然而太深的网络在训练中会存在梯度弥散和爆炸的障碍,导致无法收敛.Resnet的提出,解决了多达100层的深度神经网络训练的问题,它通过学习残差函数,实现恒等映射,从而在不引入额外参数和计算复杂度的情况下,避免了网络的退化.本文网络采用的是Resnet-50网络,即具有50层深度的网络,该网络主要由卷积层(Convolution layer)、池化层(Pooling layer)和残差块组成.
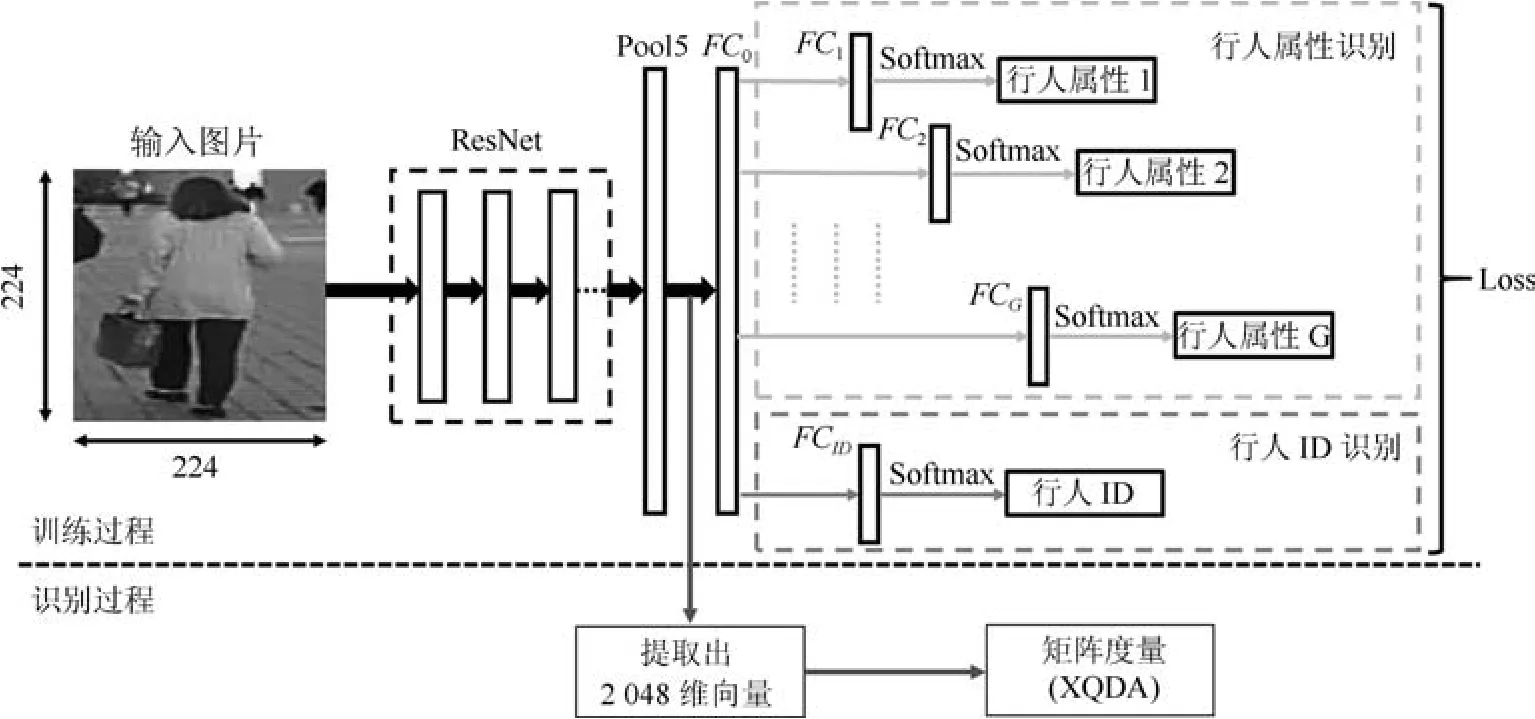
图1 网络结构示意图Fig.1 Schematic diagram of network structure
卷积层主要用于对图像或者上一层的特征图(Feature map)作卷积运算,并使用神经元激活函数计算卷积后的输出.卷积操作可以表示为:
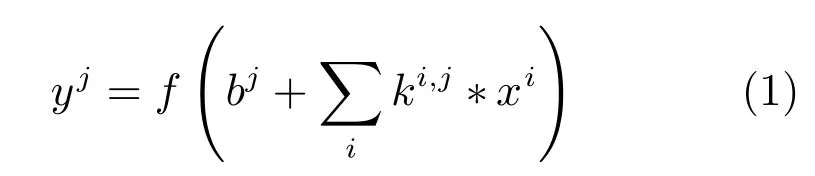
其中,xi为第i层输入图像或特征图,yj为第j层输出特征图,ki,j是连接第i层输入图像与第j层输入图像的卷积核,bj是第j层输出图像的偏置,∗是卷积运算符,f(x)是神经元激活函数.
池化层主要对卷积层的输出作下采样,其目的是减小特征图尺寸大小,增强特征提取对旋转和形变的鲁棒性.一般使用平均值池化和最大值池化两种方式,设输入特征图矩阵F,子采样池化域的大小为c×c,偏置为b,池化过程移动步长为c.则平均值池化和最大值池化的算法表达式分别为:
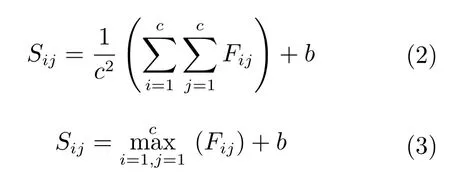
残差块是整个网络的核心部分,基本思想是在一个浅层网络基础上叠加一个恒等映射(Identity mappings),并学习残差函数,从而使得网络不退化而且性能更好.残差块共有两层,计算表达式如下:
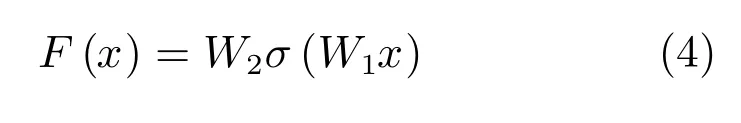
其中, 表示非线性函数Relu,W1和W2表示两个卷积层的参数矩阵.
最后通过一个捷径(Shortcut)与恒等映射相加,再通过一个Relu函数,获得输出y.
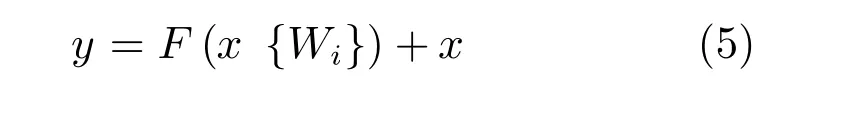
网络的后半部分为行人属性和ID特征分类网络,主要用于提取行人的属性特征和行人ID特征,由全连接层(Fully connected layers,FC)、Softmax层和损失层(Loss layers)组成.本文网络架构相较于APR网络最大的改进之处就是添加了FC0层,根据文献[14]的研究,FC0层的主要作用是在模型表示能力迁移过程中充当“防火墙”的作用.具体来讲,本实验是基于ImageNet上预训练得到的模型进行微调( fine tuning)得到最后的训练结果的,则ImageNet可视为源域(Source domain).针对微调,若目标域(Target domain)中的图像与源域中图像差异巨大,如本文的实验中,使用的是行人数据集,相比ImageNet,目标域图像不是各种物体的图像,而是行人图像,差异巨大.在这种情况下,不含全连接层的网络微调后的结果要差于含全连接层的网络.因此,在源域与目标域差异较大的情况下,添加FC0层,可保证模型表示能力的迁移.
图1中全连接层FC1-G和FCID主要起到分类器的作用,对于每一个全连接层来说,它的参数由节点权重矩阵W、偏置b以及激活函数f构成,可以表示为:
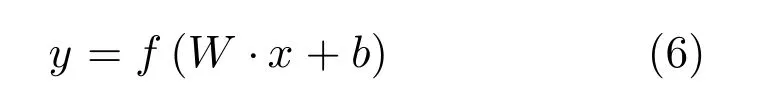
其中,x,y分别为输入、输出数据.
而Softmax层主要在全连接层的基础上,进行分类结果的概率计算.可以表示为:
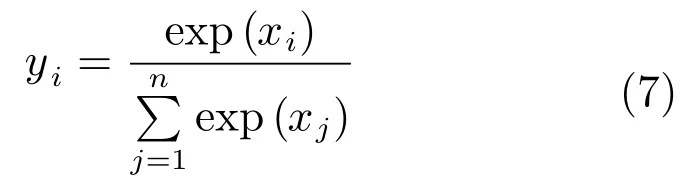
其中,xi为Softmax层第i个节点的值,yi为第i个输出值,n为Softmax层节点的个数.
Loss层采用交叉信息熵损失(Cross-entropy loss)计算方式,可以表示为:
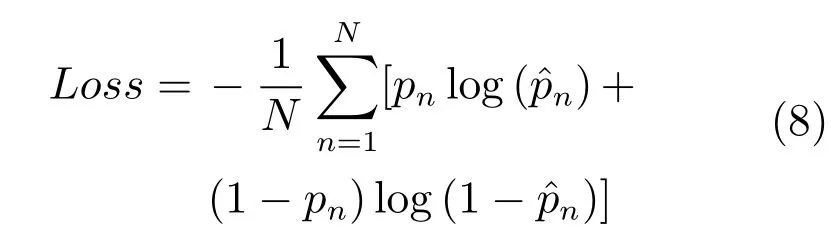
2.2 行人特征向量度量部分
本文从网络中的FC0层中提取出2048维的特征向量,用于表示行人特征,采用交叉视角的二次判别分析法(Cross-view quadratic discriminant analysis,XQDA)[16]进行向量之间距离的度量,该方法是在KISSME算法和贝叶斯方法基础上提出的.该方法用高斯模型分别拟合类内和类间样本特征的差值分布.根据两个高斯分布的对数似然比推导出马氏距离.
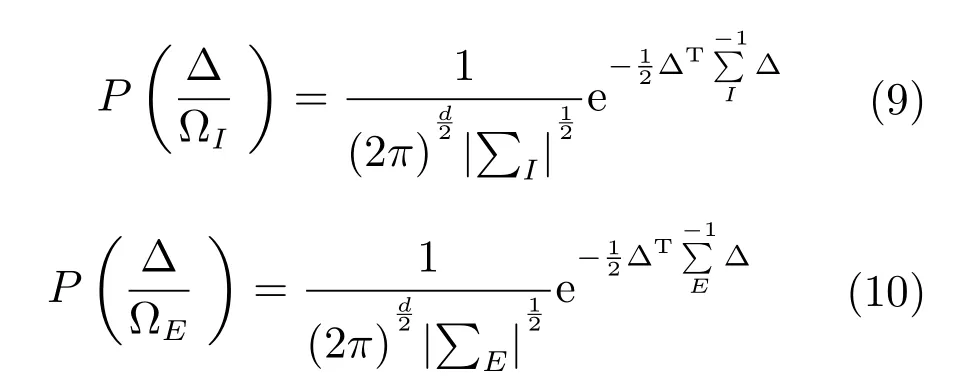
上述两式取根号相除,得到对数似然比为:
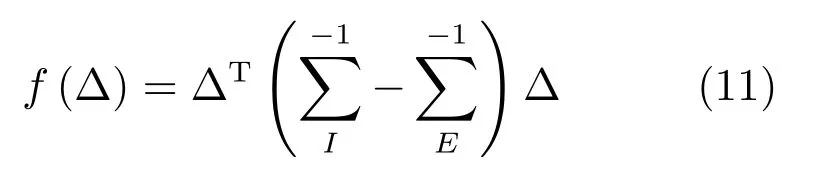
则两个样本之间的距离为:

最后对所有的样本之间的距离进行排序,选取距离最小的样本作为识别结果.
3 基于数据分布先验的损失函数设计
第1节从整体上介绍了本文提出的行人再识别网络,本节主要介绍网络中损失层计算的改进之处.本文主要利用数据先验分布,对第1节提出的式(8)进行进一步的阐述和改进,为了便于问题描述,做出如下假设.
假设训练数据集中(以Market 1501数据集为例,见表1)包含N张行人图片,分别属于M个不同的行人,每张图片标注了G类属性,包括性别,头发长短,是否带包,上衣颜色等属性,对于每一类属性,其中包含了Kg种属性,以上衣颜色为例,其中包含黑色,白色,黄色等多种属性.将数据集用集合方式描述如下:
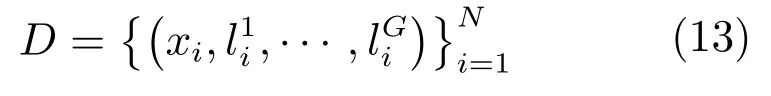
其中,xi为第i张行人图片,行人的第g类属性可以用向量表示,每类属性中的第k种属性都是二值向量表示,即如果行人存在该属性,则,反之则
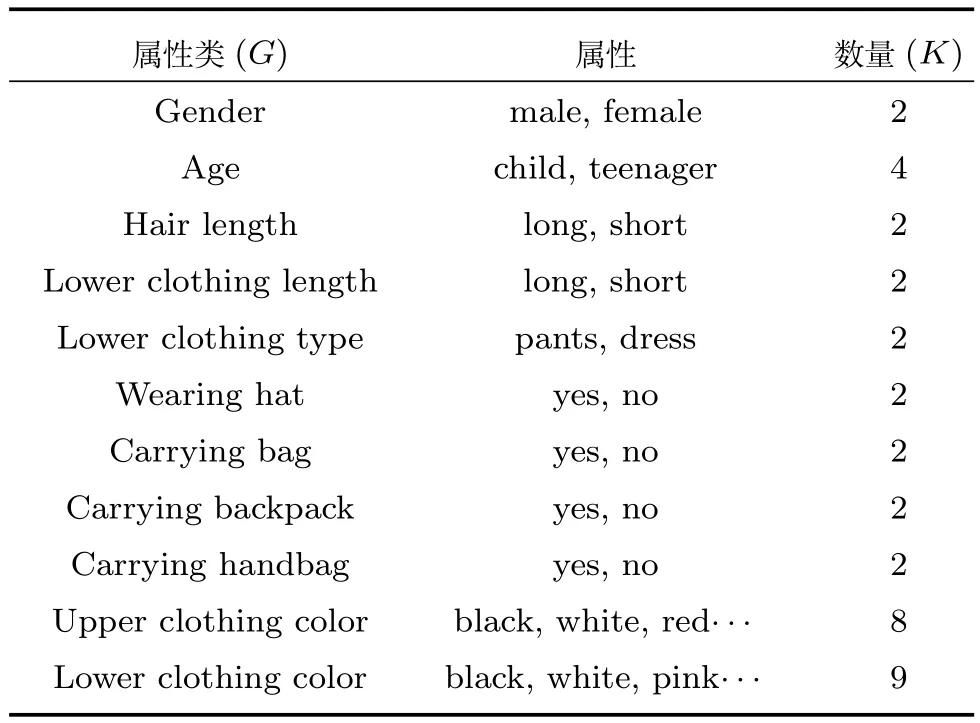
表1 Market 1501数据集中的属性类别Table 1 The attribute category of Market 1501 dataset
APR网络中的损失函数包括两部分,一部分是属性识别的损失函数,一部分是行人ID识别的损失函数.可以用下式进行计算:
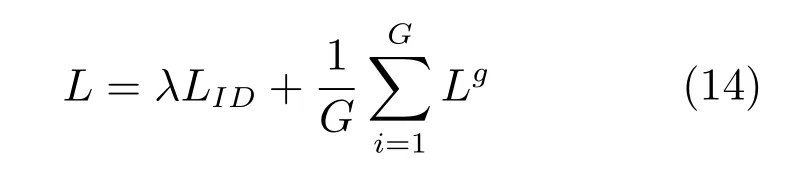
其中,LID表示行人ID识别的损失函数,Lg表示各类属性识别的损失函数,λ为参数,用于调节两者的权重.
行人ID识别的损失函数具体形式为:
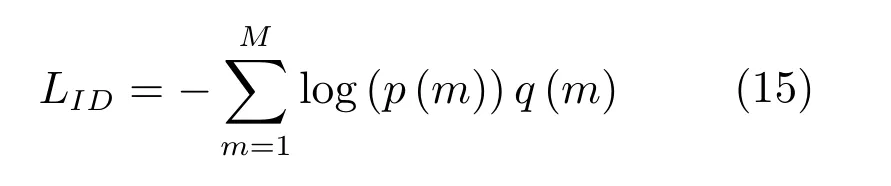
其中,p(m)表示第i个样本属于第m类行人的概率,由FCID层后的Softmax层计算得到;如果假设y为标注的正确行人类别,则q(y)=1,当m 6=y时,q(m)=0.
行人属性识别的损失函数具体形式为:
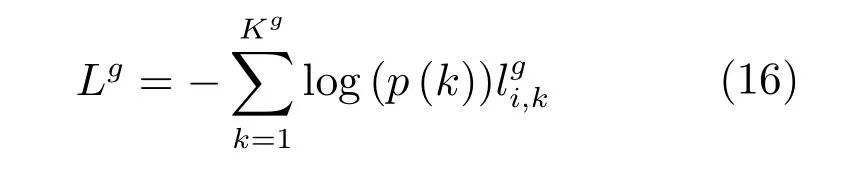
其中,p(k)表示第i个样本属于第g类属性中第k种属性的概率值,由FC1−G各层后的Sofxmax层计算得到.
在APR网络的基础上,本文主要对基于属性识别的损失函数,就是式(16)进行了改进.这部分改进包括两方面:1)基于属性样本数量对损失函数进行归一化;2)基于各属性中正负样本数量的占比对不同的属性赋予不同的权重.下面在第3.1节和第3.2节分别进行介绍.
3.1 基于属性样本数量的损失函数归一化
对通用的行人数据集统计发现,属性间存在的样本数量不平衡现象,这极大得影响了行人再识别的识别准确性.以Market 1501数据集为例,表2中统计了数据集中行人各属性的数量.从表2可以看出,年龄是青年,穿短袖上衣,短裤等属性的样本数量较多,分别为569,712,641个样本.携带手提包,帽子,穿粉色下衣等属性的样本数量很少,分别只有86,20,2个样本.针对各属性样本数据不平衡的情况,本文在损失层的计算中,对各属性的损失,基于其所包含的样本数量进行了归一化处理.最终,损失层改写为下式:
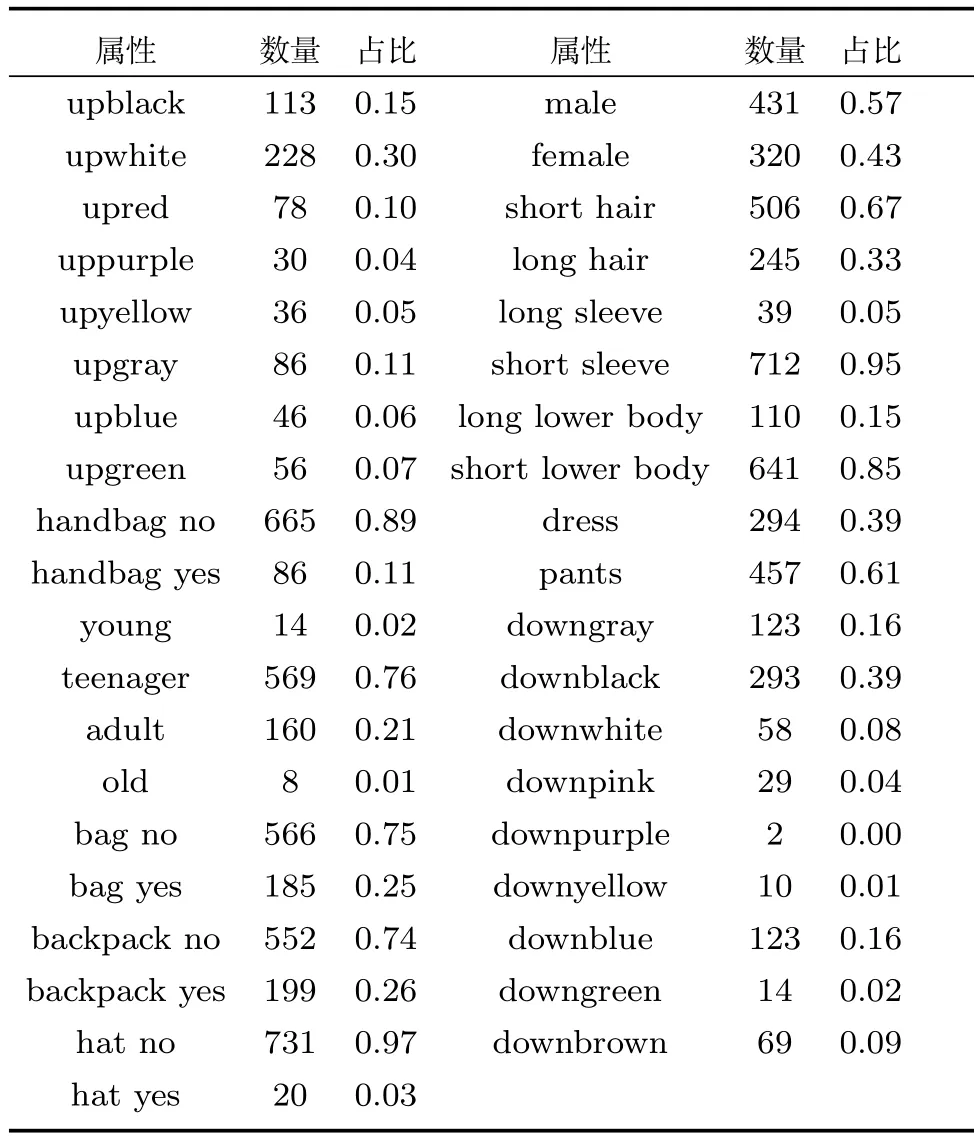
表2 Market 1501数据集中行人属性训练样本数量及占比Table 2 Statistics of Market 1501 dataset

其中,Ng表示第g类属性的训练样本数量,表示第g类属性中第k种属性的训练样本数量,概率值是FC1−G各层的输出经由Softmax层计算而得的,表示第i个样本属于第g类属性中第k种属性的概率值.
Softmax层的计算方式如下:
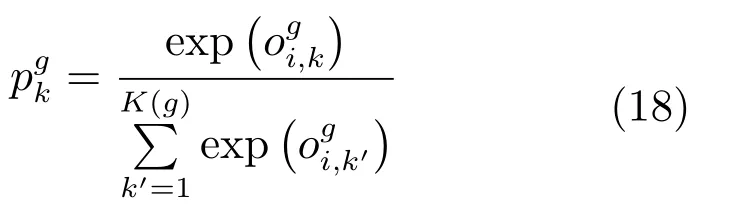
对于行人类别来说,每个行人的样本数量大致相同,基本不存在数据不平衡问题,则不需要进行归一化操作.假设FCID层的输出为z=[z1,z2,···,zM]∈RM,同理可得,第i个样本属于第m类行人的概率为:

则可以将式(15)改写成如下损失函数:

对于整个网络来说,不能只计算属性或者行人类别的损失函数,这会导致训练无法收敛.所以网络采用联合损失函数的方式,将两者结合起来,作为网络整体的损失函数,联合方式可以用下式表示:
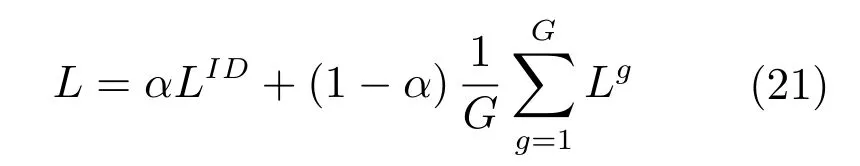
其中,0≤α≤1,该参数用于调节两个损失层在网络中的权重,通过实验得到最佳值.在整个训练过程中,通过反向传播和梯度下降来计算网络参数.
3.2 基于属性正负样本权重调整的损失函数设计
行人再识别数据库中,不仅存在属性间样本数量不平衡的问题,也存在属性内正负样本数据不平衡问题.在选取的三个实验数据集中,行人属性内的正负样本数据不平衡的现象也非常严重.以Market 1501数据集为例,从表2中可以看出,比如在是否戴帽子这个属性类中,戴帽子的占较少数,没有帽子的占大多数,占比为0.03/0.97.在上衣长短这个属性中,也是正负样本比例不均,长袖的只占0.05.在这种情况下,正样本在在识别过程中起到的影响过小,不能很好地反应行人属性真实情况,影响识别的效果.为了解决正负样本不平衡的情况,参照文献[10]的方法,本文在第3.1节提出的损失层计算基础上,利用数据先验分布知识,基于各属性中正负样本占比,对属性识别的损失函数通过引入权重的方式进行了调整,将式(17)改写为下式:
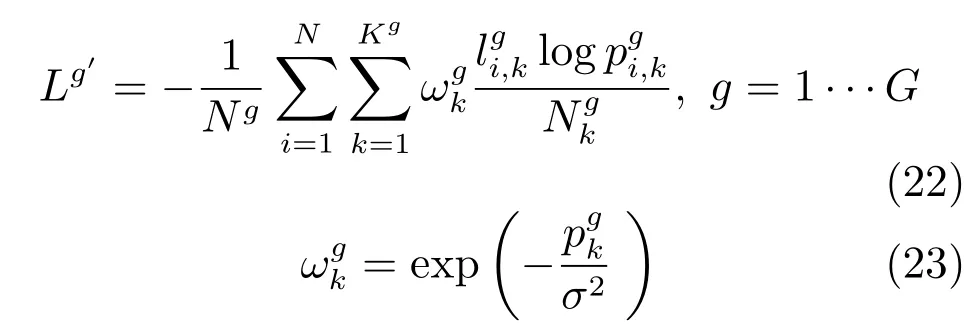
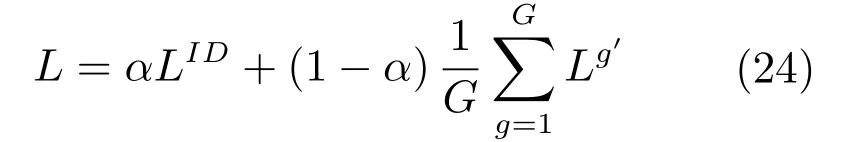
4 实验结果与分析
本节首先介绍实验中使用的测试数据和算法性能的评测准则,其次介绍本文算法中的一些相关参数设置和选取实验,然后在不同公开实验数据集上测试对各行人属性的识别结果,最后介绍本文算法在不同公共实验数据集上与已有的行人再识别算法的性能比较.本文所有的实验是基于深度学习框架Matconvnet实现的,实验平台是配备64GB内存的Intel Core i7处理器和24GB显存的Nvidia TITAN X显卡的GPU工作站.
4.1 数据集和评价指标
本文主要基于三个具有行人属性标注的行人再识别数据集进行实验,分别是Market 1501、DukeMTMC数据集和PETA数据集,其中的一些行人图片例子见图2.

图2 数据集行人图片举例Fig.2 Example of dataset pedestrian picture
Market 1501数据集是由6个摄像机拍摄采集生成的大规模行人再识别数据集,包含32668张行人图片和3368张查询集图片,共有1501个不同ID的行人,对每个行人标注了27种行人属性.其中751个不同ID的行人作为训练集,750个不同ID的行人作为测试集.在本文实验中,使用其中的651个ID的行人作为训练集,剩下的100个ID的行人作为验证集,用于确定参数.
DukeMTMC数据集是由8个摄像机采集,包含34183张行人图片和2228张查询集图片,共有1812个不同ID的行人,其中1404个不同ID的行人出现在不同摄像机拍摄视野中,剩余的408个不同ID的行人是一些误导图片,对每个行人标注了23种行人属性.根据数据集本身的划分,其中702个不同ID的行人用于训练,剩余的702个不同ID的行人用于测试.
PETA数据集是由19000张行人图片组成,图片分辨率分布在17×39到169×365之间.这些行人图片共包含8705个不同ID的行人,每张行人图片标注了61个二值行人属性和4个多值行人属性.在本文实验中,随机选取其中的9500张行人图片作为训练集,1900张行人图片作为验证集,7600张行人图片作为测试集,按照经典的数据集使用方式,只选取其中标注数量最多的35个行人属性作为识别目标.
为了与已有算法公正比较,实验中,采用先前工作普遍采用的评价框架.将数据集事先划分为训练集和测试集,其中测试集由查询集和行人图像库两部分组成.当给定一个行人再识别算法,衡量该算法在行人图像库中搜索待查询行人的能力来评测此算法的性能.已有的行人再识别算法大部分采用累积匹配特性(Cumulative match characteristic,CMC)曲线评价算法性能,给定一个查询集和行人图像库,累积匹配特征曲线描述的是在行人图像库中搜索待查询的行人,前r个搜索结果中找到待查询人的比率.首位匹配率(r=1)很重要,因为它表示的是系统真正的识别能力.另外,同时采用平均准确率(Mean average precision,mAP)评价算法性能,平均准确率是对准确率和召回率的全面反映,计算平均准确率时,将准确率和召回率作为横纵坐标,绘制曲线,曲线包围的面积就是平均准确率的值,该值最大时,表示系统的准确率和召回率达到了最优.
4.2 网络参数与结构设置
本网络参数设置是在文献[11]的基础上微调而得的,训练过程中设置批尺寸(Batch size)大小为64,epochs为55,学习率初始值为0.001,在最后5个epochs中,调整为0.0001.各参数的微调过程具体见图3.
参数α.如图3(a)所示,其中曲线代表了式(24)中的参数对准确率的影响,当α取不同值时,网络的行人再识别准确率也随之发生变化.基于Market 1501数据集,当网络不使用行人属性标签信息时(即α=1时),首位匹配率是72.36%.当网络仅考虑行人属性标签信息时(即α=0时),首位匹配率是76.81%.当0.1≤α≤0.9时,也就是同时考虑属性和ID标签信息时,首位匹配率要普遍高于单独考虑这两者,在α=0.7时,首位匹配率达到最大值86.90%.基于DukeMTMC数据集,当α=1时,首位匹配率是60.34%.当α=0时,首位匹配率是62.16%.在α=0.7时,首位匹配率达到最大值72.83%.基于PETA数据集,当α=1时,首位匹配率是70.13%.当α=0时,首位匹配率是65.24%.在α=0.6时,首位匹配率达到最大值76.37%.综上考虑,实验中取α=0.7.
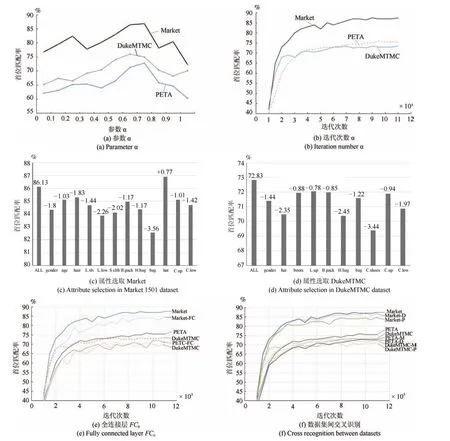
图3 网络参数及结果对比Fig.3 Comparison of network parameters and results
迭代次数.如图3(b)所示,其中曲线代表了当网络迭代不同次数时,网络的首位匹配率变化情况.每迭代1000次测试一次网络性能,随着迭代次数达到8000次左右,网络性能基本稳定,所以将网络的epochs设置为55.
属性选取.图3(c)表示了Market 1501数据集去除不同属性后,网络的再识别准确率.有些行人属性容易产生误检和漏检,从而对行人再识别带来负效应,所以考虑从数据集标注的行人属性中,剔除一些具有负效应的属性.以所有属性参与训练得到的准确率作为基准,每次去除一类属性,得到识别准确率,与基准进行对比,其中横坐标为去除的属性.图3(d)表示了DukeMTMC数据集的实验结果.可以发现,在Market 1501数据集中,不使用是否有帽子这个行人属性,再识别的准确率反而得到了提升,主要因为帽子这个属性漏检的概率较大,所以本文实验中不使用该属性.而在DukeMTMC数据集的测试结果表明,减少任一行人属性后,行人再识别的识别效果都会降低,所以使用所有的属性.
全连接层FC0.如图3(e)所示,其中曲线代表了网络是否添加全连接层FC0对网络准确率的影响.图中实线的趋势线代表添加了完整本文算法结果,虚线的趋势线代表去除全连接层的本文算法,可以发现,添加了全连接层后,本文提出的训练网络更加的稳定,能更快的迭代到稳定值,并且提升了算法在三个数据集上的首位匹配率.与本文算法完整算法相比,去除全连接层后,在Market 1501、DukeMTMC和PETA数据集上的首位匹配率分别下降了0.89%,0.76%和1.31%.可以看出,全连接层的添加对于本文算法的识别效果具有较大的提升作用.添加全连接层能够较明显改善识别效果的原因主要有如下两点:1)根据文献[13]的研究,全连接层可以提高网络在微调后的判别能力,使得网络在这三个常用数据集上的判别能力得到提升;2)本文采用的是残差网络,不包含全连接层,所以在添加了全连接层后,丰富了网络结构,从而提高特征提取能力,进而提升了网络的识别效果.鉴于以上两点,本文采用添加了全连接层FC0的网络.
数据集间交叉识别.如图3(f)所示,其中实线代表了根据各自数据集的先验分布训练得到的网络进行数据集内识别结果(例:用数据集Market 3中的训练集训练得到的网络,对数据集Market 1501中的测试集进行测试),虚线表示基于三个数据集的先验分布训练的网络进行数据集间交叉识别的结果(例:用数据集DukeMTMC和PETA中的训练集分别训练得到的网络,对数据集Market 1501中的测试集分别进行测试分别记为Market-D和Market-P,后面的命名规则相同,需要说明的是,当待测数据集中含有训练数据集中没有的属性时,从待测数据集的训练集中选取含有特殊属性的样本,对训练集进行扩充以后再进行训练.);实验结果表明,数据集间交叉识别的性能相对于数据集内识别的性能是有轻微下降.对于数据集Market 1501来说,利用数据集DukeMTMC和PETA中的训练集训练得到的网络,在该数据集上测试得到的首位匹配率相比于数据集内识别结果,分别下降了0.82%和1.13%;对于数据集DukeMTMC来说,利用数据集Market 1501和PETA中的训练集训练得到的网络,在该数据集上测试得到的首位准确率相比于数据集内识别结果,分别下降了0.67%和1.38%;对于数据集PETA来说,利用数据集Market 1501和DukeMTMC中的训练集训练得到的网络,在该数据集上测试得到首位匹配率相比于数据集内识别结果,分别下降了1.54%和1.78%.这主要是因为PETA中属性分布相对于Market 1501和DukeMTMC有较大的差异.但是相对于不考虑数据先验分布的APR网络,数据集间交叉识别的性能还是有所提升,在Market 1501,DukeMTMC和PETA数据集上,首位匹配率分别至少提升了1.48%,0.76%,2.61%.所以,在实际应用中,在对待检测数据集属性分布不可知的情况下,可以直接采用基于已有的数据集训练的网络实现行人再识别工作.

表3 Market 1501数据集各属性识别准确率(%)Table 3 Accuracy rate of each attribute recognition of Market 1501 dataset(%)
4.3 各属性的识别精度
本文基于三个通用行人属性数据集,分别进行了行人属性的识别实验,识别准确率如表3∼表5所示.同样地,选取APR网络的实验结果作为对比,其中APR网络在PETA数据集上的结果是基于APR文献源代码复现得到.
首先,从整体来看,在这三个数据集上,本文的识别准确率相较于APR网络都有了较大的提升,平均准确率分别提升了0.99%、2.03%和3.83%,就各属性来说,识别准确率也都提升了0.12%∼7.29%不等.这表示本文提出的网络相较于APR网络在行人属性识别上具有更好的性能.
其次,从一些具有强数据不平衡的属性来看,以Market 1501数据集为例,其中是否有包这个属性,识别准确率提高了7.29%,提升程度比较大,对于一些数据平衡的数据,比如性别这个属性,识别准确率只提高了0.28%.这表明本文提出的基于数据先验分布知识的权值调整策略,对行人属性的提升具有明显的效果,尤其是具有强数据不平衡的属性,提升效果更为明显.

表4 DukeMTMC数据集各属性识别准确率(%)Table 4 Accuracy rate of each attribute recognition of DukeMTMC dataset(%)

表5 PETA数据集各属性识别准确率(%)Table 5 Accuracy rate of each attribute recognition of PETA dataset(%)
最后,如图4所示,列举了两个行人属性识别结果的例子,本文的网络会对行人所有的属性进行预测并打分,可以发现,左边行人的属性预测全部正确,而右边行人的下衣种类和是否带手提包两个属性识别错误.

图4 行人属性识别结果举例Fig.4 Example of the result of pedestrian attributes
4.4 行人再识别结果
本文基于三个通用行人属性数据集,进行了行人再识别实验,实验结果如表6∼表8所示.表中“*”表示原文献中没有公布相关数据,本文使用其源码复现得到.其中“–”表示没有该项实验结果.
4.4.1 Market 1501数据集
首先,针对本文提出的三个改进点分别做了对比实验,在表6中分别以“本文–FC0”,“本文–归一化”,“本文 –权重”代表基于APR 网络单独添加这三处改进得到实验结果,“本文–归一化+权重”代表同时添加这两项改进得到的实验结果.可以发现,相对于APR网络,这4处改进在首位匹配率上都得到了提升,分别提升了1.08%、0.63%、1.38%、2.02%,其中添加了全连接层和改变权重对实验效果的提升比较明显,对数据进行归一化也有一定提升.相应的平均准确率也有0.44%、0.15%、0.56%、0.79% 的提升,这说明三处改进对于提高行人再识别结果都有较大作用,而且联合归一化和占比权重调整两处改进,得到了较单独改进更好的实验效果,说明两处改进之间具有互补之处.
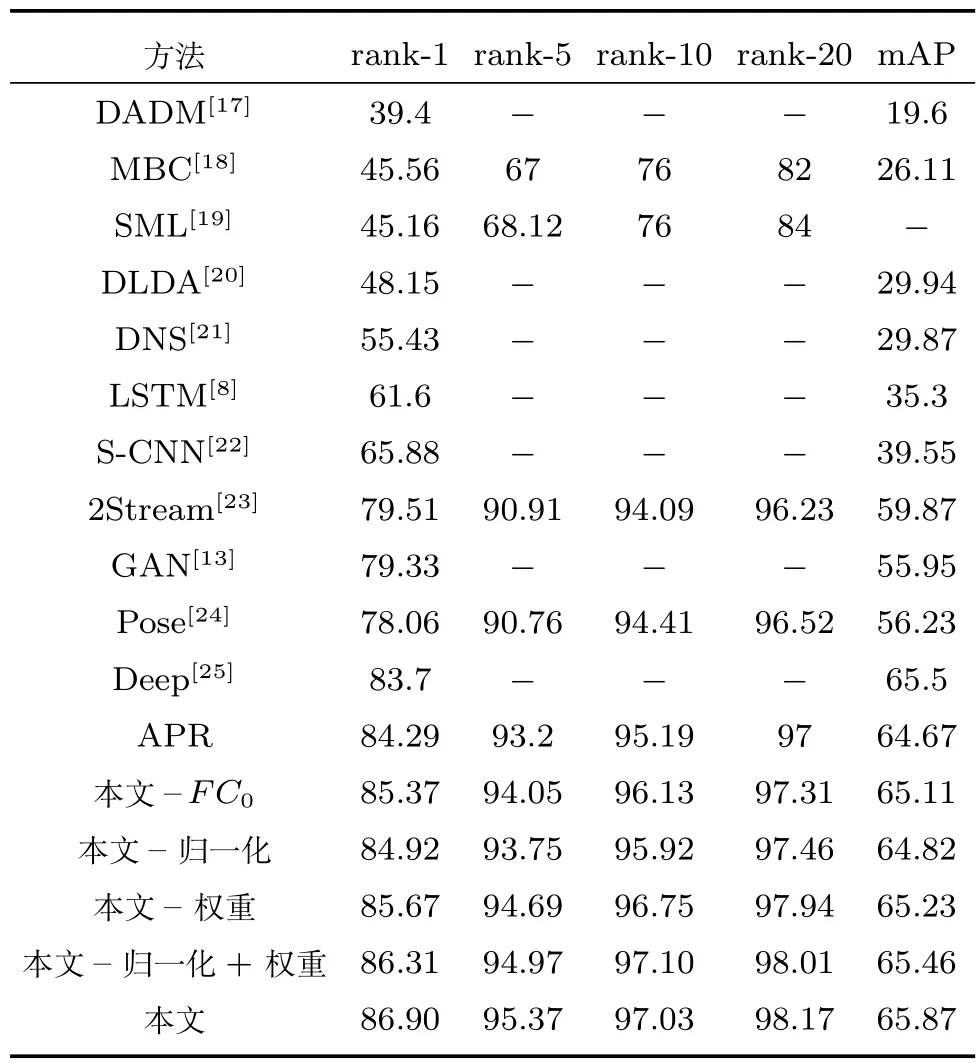
表6 Market 1501数据集行人再识别结果Table 6 Re-id results of the Market 1501 dataset
其次,在Market 1501数据集,本文选取了DADM、MBC等经典方法进行对比.可以发现,传统方法的首位匹配率普遍不是很高,一般在50%以下.在使用深度学习方法以后,准确率得到了一个巨大的提升,而APR网络更是达到了84.29%的首位匹配率和64.67%的平均准确率.本文在APR网络的基础上,进一步提高了识别的准确率,达到了86.90%的首位匹配率和65.87%的平均准确率,第5,10,20匹配率也有相应的提升.

表7 DukeMTMC数据集行人再识别结果Table 7 Re-id results of the DukeMTMC dataset
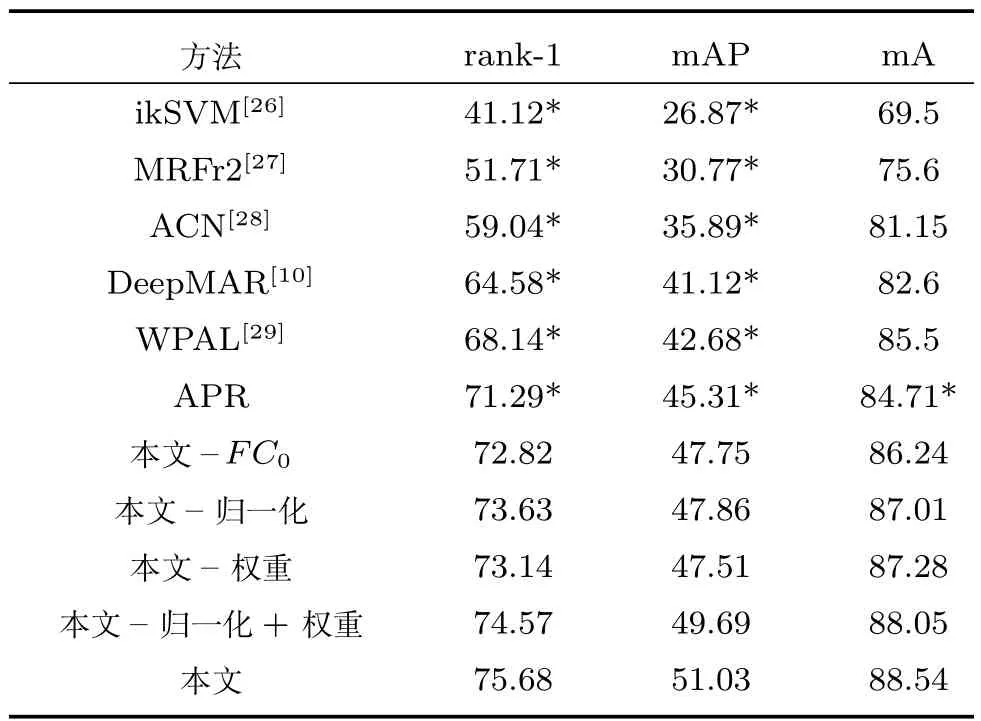
表8 PETA数据集行人再识别结果Table 8 Re-id results of the PETA dataset
4.4.2 DukeMTMC数据集
同样的,针对本文提出的三个改进点分别做了对比实验.从表7中可以发现,相对于APR网络,这四处改进在首位匹配率上都得到了提升,分别提升了0.87%,0.26%,1.13%,1.42%,类似于Market 1501数据集的实验结果,添加全连接层和改变权重对实验效果的提升比较明显,相应的平均准确率也有0.48%,0.25%,0.79%,0.96%的提升,这说明对于该数据集,这三处改进也有较好的实验效果.
其次,针对DukeMTMC数据集,由于使用该数据集的评测方法与Market 1501数据集不尽相同,从中选取了BoW、LOMO等经典方法进行对比.可以发现,这两种传统方法的效果不是很好.对抗学习达到了67.68%的首位匹配率.APR网络在该数据集达到了70.69%的首位匹配率和51.88%的平均准确率.本文在APR网络的基础上,在该数据集上达到了72.83%的首位匹配率和53.42%的平均准确率.由于这几个方法没有提供第5、10、20匹配率,所以在此不作对比.
4.4.3 PETA数据集
与前两个数据集相同,针对本文提出的三个改进点分别做了对比实验.从表8中可以发现,相对于APR网络,在这4处改进中分别提升了 1.53%、2.34%、1.85%、3.28%,类似于前两者的实验结果,添加全连接层和改变权重对实验效果的提升比较明显,相应的平均准确率也有1.53%、2.30%、2.57%、3.34% 的提升,由于该数据集各属性之间数量差异较大,且属性内正负样本不平衡严重,所以本文方法在此数据集上有较大提升.
其次,针对PETA数据集,很多方法是比较各属性的平均准确率(Mean accuracy,mA),而不是比较rank-1和mAP的值,所以本文一方面进行了mA的比较,可以发现,本文达到了88.54%的属性平均准确率,较传统方法有了大幅度提升,相对于APR网络也是有3.83%的提升.另一方面,本文通过对文献源代码进行复现,得到rank-1和mAP的值,可以发现,本文相对于APR网络和经典算法,也是有较大的提升,达到了75.68%的首位匹配率和51.03%的平均准确率.
综上可以得出,本文提出的网络相对于一些经典方法,在首位匹配率和平均准确率上都有很大的优势,相较于APR网络也有较大的提升,表明本文提出的基于数据先验知识的行人再识别网络,对于行人再识别效果提升是有效的.如图5所示的行人再识别结果的两个例子,可以发现,虽然存在一些误识,但是总体识别效果已经达到较高的程度.

图5 行人再识别结果举例Fig.5 Example of the re-id result
5 结语
随着深度学习技术的发展和带属性标注行人数据集的出现,近年来基于行人属性的行人再识别有效提升了识别精度.在已有研究基础上,本文基于行人属性中的数据先验分布知识设计了新的用于行人属性识别和再识别的深度神经网络.实验结果验证了本文方法的有效性.但依旧没有充分挖掘数据集的内在信息,实验效果还可进一步提高.后续工作将进一步研究如何在网络设计中融入属性之间的相关性和异质性.
