基于混合架构的高校多源异构数据集成系统
2019-06-11赵佳钐李坤伦徐江李院春
文/赵佳钐 李坤伦 徐江 李院春
1 引言
高校早期信息化的过程中长期存在“数据孤岛”的现象,校属各部门只针对自身的业务需求建设信息系统,缺乏统一的信息标准和规范,导致各业务系统之间数据标准不一致、产生和沉淀的大量数据难以共享。构建公共数据库,被认为是当前解决“数据孤岛”问题最为有效的方法。校园公共数据库汇集了各个业务系统沉淀的有效数据,并向所需业务系统共享数据。然而,传统公共数据库的构建,只处理个人信息、成绩信息、消费数据等结构化数据,对半结构化和非结构化数据无能为力。
为此,研究人员提出构建高校大数据平台的概念,用以采集、清洗、存储高校中的多源异构数据,并通过大数据分析方法,为高校的教学、科研、管理提供帮助。李兰友等提出了一种基于ODI的数字校园数据集成模式,吴振涛等提出了一种在数字化校园中基于数据仓库技术的数据集成应用。这两种架构均是基于传统的数据集成架构,在数据量较大时性能较差,更是难以应对日志、舆情等大规模的半结构化、非结构化数据的处理分析。邓涵元等提出了一种基于MPP-Hadoop混合架构高校数据集成系统,解决处理大数据、扩展性及非结构化数据等方面的问题。然而,这种架构忽略了核心数据的管理和共享功能。高校大数据平台最主要的功能应该是按需为其他业务系统共享核心数据。这些核心数据的数据量不大,但应该便于管理、追溯,同时对数据同步的实时性要求很高,尤其是涉及学籍、财务等方面的数据。
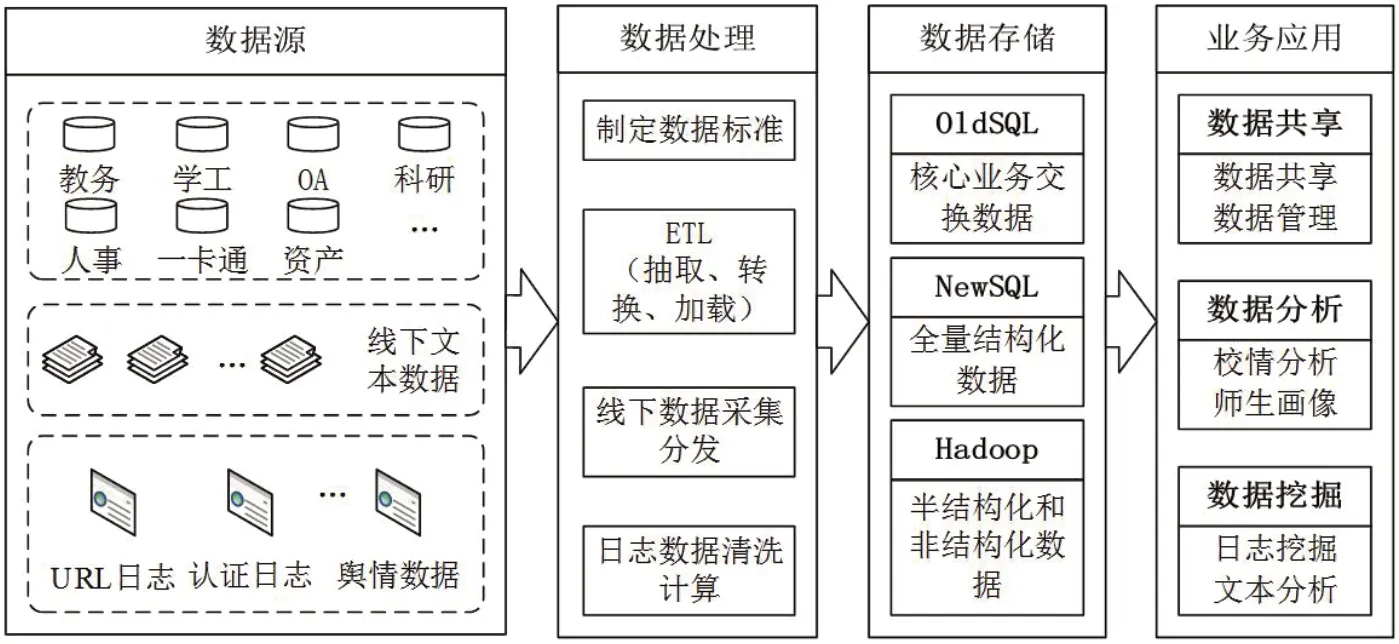
图1:系统架构图

图2:数据平台的物理架构图
本文提出了一种基于混合架构的多源异构数据集成平台。平台融合了OldSQL传统关系型数据库、NewSQL新型分布式数据库和Hadoop开源生态系统,可适应多种业务场景模式。其中,OldSQL平台用于存储学校的核心业务数据,如教师数据、学生数据等,这部分数据的关联关系复杂、对高并发、低延时的需求较高。NewSQL平台作为数据仓库汇总各业务系统的全量数据、过程数据、历史归档数据等结构化数据,这部分数据主要作为校内的数据资产而存储,并支撑平台之上的数据关联分析应用。Hadoop平台用以提供批量数据计算,存储半结构化和非结构化数据,如网络日志数据、数据中心日志数据、学校舆情数据等。
2 平台系统设计
教育行业信息化过程中产生积累的数据相对庞大复杂,即有人员、成绩信息等结构化数据,也有日志、舆情数据等半结构化、非结构化数据。现有的高校大数据平台并不能同时满足海量异构数据的实时共享、处理、分析及存储需求。
2.1 系统设计目标
为解决高校数据共享难、分析难、不完整的问题,本文从数据源出发,将高校数据资产分为三类。第一类是高校的核心业务数据,第二类是全量结构化数据,第三类是日志、舆情数据等半结构化、非结构化数据。各类数据的数据总量和特点不同,上层业务应用对不同种类数据的需求也不同。核心业务数据的数据量不大且相对稳定,但关联关系复杂,对高并发、低时延的要求高,上游数据源数据做出更改时要求下游业务系统同步修改。全量结构化数据主要是作为全量数据资产而存储,便于回溯数据、支撑上层数据分析类应用。这类数据的关联关系复杂,数据量逐年增加,且增长较快,对数据的实时性有一定的要求。日志、舆情等半结构化和非结构化数据主要用以支撑上层的数据挖掘应用,相比于前两类数据,这类数据的数据量庞大且增长快速。

表1:物理平台的节点配置
2.2 系统总体架构
本文提出的基于OldSQL-NewSQLHadoop的大数据共享分析平台,既能满足当前业务的数据需求,又符合行业未来的数据发展规划。其中,传统关系型数据库OldSQL存储高校的核心业务数据,可消除长期信息化过程中的数据孤岛现象,确保数据的权威性、有效性、实时性。NewSQL技术作为高校的数据仓库存储全量的结构化数据,如全量业务数据、过程数据等,确保数据的完整性。Hadoop平台用以存储和处理日志、舆情等半结构化和非结构化数据,为高校的数据挖掘、政策制定提供数据支撑。如图1所示,根据数据来源及应用情况,大数据共享分析平台的系统总体架构可分为四层,即数据源层、数据处理层、数据存储层和业务应用层。
2.3 平台业务流程
高校的信息化的程度相对完善,诸如教务系统,学工系统、OA系统、科研系统、人事系统等,每天都会积累大量的数据。同时,很多重要数据仍游离于信息系统之外,以文本的形式保存。这部分数据作为学校隐形的数据资产,其重要性不言而喻。除结构化数据之外,校内师生每天还会产生大量的半结构化和非结构化数据,如URL日志、认证日志以及校园舆情数据等。这些数据在研究学生日常行为和数据中心安全上有极大的价值。本文提出的数据集成系统中,数据源层包括高校的各个业务系统、线下文本数据、日志数据及舆情数据。
在获取到数据源后,数据处理的第一步便是制定统一的数据标准,并梳理数据源、清洗数据源的数据质量。其中,ETL数据预处理完成数据的抽取、转换、加载。数据抽取是针对不同业务系统数据进行全量或者增量的数据抽取。抽取完成后,需要对抽取的数据进行过滤清洗,并根据制定的数据标准转换数据格式,生成新的数据,加载到目标数据库。对于未采用信息化手段,以纸质形式或电子文档存储的数据,需要采用手工录入或工具导入的方式清洗并加载到目标数据库。在处理大量的日志和舆情数据时,预处理阶段利用Hadoop平台进行对数据进行简单的清洗分类,将数据分析价值较高的数据留存在HDFS。
在数据存储层,本文将高校的数据分成了三大类,即核心业务数据、全量结构化数据、半结构化和非结构化数据,并根据各类数据的特征和用途采用不同的数据存储技术。数据在经过采集、预处理、分类存储后,提供给上层业务应用展现才能发挥其最大价值。业务应用层可分为三类应用。第一类是数据共享类应用,主要负责数据的可视化管理和核心业务数据的共享。第二类是数据分析类应用,这类应用以三类数据为支撑,将校园大数据以不同维度的可视化方式展现出来。第三类是数据挖掘类应用,主要利用Hadoop平台的大数据分析处理工具,挖掘半结构化和非结构化数据的潜在价值。
2.4 关键问题及解决思路
系统在建设过程中,面临的主要的问题是数据标准的制定。高校的信息化起步早,校内各部门信息化的进程不同,这直接导致了各个系统之间的数据标准不统一,进而促使校内各系统直接的数据共享困难。因此,构建校内大数据平台最重要的一环便是制定统一的校内数据标准,规范各类数据元素。数据标准的制定不仅要大而全,涵盖学校当前的数据治理目标和对未来的数据规划,而且要尽可能向国家标准和行业标准靠拢。于此同时,要从规章制度上规范各业务部门的数据格式,保障数据质量。
3 系统的部署与实现
3.1 平台物理架构
核心业务数据的关联关系复杂、对高并发、低延时的要求较高,因此本文选取稳定性、性能更优的Oracle数据库来存储。同时,采用Oracle RAC做双机的负载均衡架构,避免单点故障。核心业务数据库的后台存储采用全闪存集中式双活存储,以保障数据的高可用性。对于要求次之,数据量增长较快的NewSQL数据库,本文采用开源的CockRoach数据库,目前配置了3个节点的集群,每个节点服务器均配置2块600GB的SAS硬盘,3块240GB的SSD。Hadoop平台采用6个节点规模的集群,每个节点服务器均配置2块600GB的SAS硬盘和6块6TB的SATA硬盘。平台的物理架构如图2所示。节点的具体配置如表1所示。
3.2 学生预警系统
业务应用以学生预警系统为例,学生预警本身包含两方面,一方面是学业预警,另一方面是行为预警。涉及到的数据包括学生的成绩信息、上课点名信息和学生上网日志,这三种数据分别存储于核心业务数据平台、全量结构化数据平台和Hadoop平台之上。其中,学生成绩信息用于分析学生的学业完成情况。上课点名信息用于刻画学生的课程出勤情况,对学生有一定的警示作用。通过对上网行为日志的挖掘,并综合考虑目标网站的性质,可科学分析学生在思想、行为上是否异常,如是否牵涉校园贷等。学生预警系统面向的用户主要分两类,一类是学生,另一类是教学管理人员。对学业完成度较差或课堂出勤率较低学生,可利用短信、微信等信息接收终端向学生和辅导员自动推送警示信息。学生行为预警则主要面向教学管理群体,在保证学生基本隐私的前提下,向少数管理人员推送学生的网络行为异常情况。
4 结束语
在构建校园大数据平台的过程中,首先要根据不同业务和数据使用情况,划分校内的数据资产。每种类型的数据特点各有不同,上层业务系统对各种类数据的需求也不同。因此需要根据每种类型数据的特点,采用不同的技术架构,对数据进行清洗存储。本文结合OldSQL、NewSQL和Hadoop技术,采用一种基于混合架构的高校多源异构数据集成方案。从而消除了数据孤岛,实现校内核心数据的实时共享,完善数据资产的整治,解决海量异构数据的分析难题。
