基于SolrCloud的银行实时报表系统设计与实现
2019-06-10段文龙包崇明周丽华孔兵
段文龙 包崇明 周丽华 孔兵

摘 要:为了解决传统银行报表系统无法满足千万级以上数据实时查询、统计问题,基于SolrCloud技术提出一种新的实时报表系统,并就系统设计与实现作详细介绍,最后使用银行交易数据对系统进行一系列测试。实验结果表明:该系统对数据进行实时查询与统计操作时,耗时均在毫秒级范围内,可以很好地完成千万级以上数据的实时查询与统计。
关键词:SolrCloud;实时查询;报表系统;数据处理DOI:10. 11907/rjdk. 181893
中图分类号:TP319文献标识码:A文章编号:1672-7800(2019)002-0079-05
Abstract: For solving the problem that the traditional bank report system has been unable to meet the needs of real-time query and statistics for tens of millions of data, base on SolrCloud technology, this paper designs a new real-time report system and makes a detailed introduction to the construction and index design of the real-time report system. Finally, a series of tests were conducted on the system using the bank transaction data. The experimental results show that when the real-time reporting system performs real-time query and statistics operations on data, it takes time in the range of milliseconds. The experimental conclusion is obtained that the real-time reporting system based on SolrCloud technology can complete the real-time query and statistics of more than tens of millions of data well.
Key Words: SolrCloud; real-time query; report system; data processing
0 引言
报表系统作为银行系统的重要组成部分,在其中占据重要位置。报表系统通过对银行交易数据进行统计、分析得到有用信息,为银行管理层决策提供了有力支持[1-2]。数据实时统计分析对银行分析用户交易情况和辅助银行管理人员决策显得更加重要[3]。
国内外银行报表系统经过多年发展,各种报表工具相继出现。国外报表系统主要包括早期电子报表[4] 、专业报表管理软件、报表生成组件、基于大数据技术的报表系统等,各种报表系统虽然功能强大,但是无法对数据进行实时查询、统计[5]。
与国外相比,我国报表工具开发起步较晚,技术发展相对滞后。到20世纪80年代末,我国财务软件公司才开发出通用的报表系统,其中具有代表性的是用友公司开发的用友UFO[6]。到20世纪90年代,随着Windows使用越来越广泛,各大公司依托 Windows系统平台开发了基于Excel的报表系统,但是该类报表系统功能比较简单,并对Excel有很大依赖性。随着大数据技术快速发展,各大互联网公司开始开发自己的大数据报表系统,极大地解决了传统报表系统对大量数据处理困难的问题,但各种报表系统仍无法实现对数据的实时查询、统计[7]。
本文通过对部分银行报表系统的深入分析,找到现有报表系统无法对数据进行实时查询、统计的问题症结。通常,部分银行报表系统为了缩短数据查询时间,提高客户体验度,往往先对数据进行离线计算,后查询。该方法虽然在一定程度上达到了实时查询效果,但是无法对实时交易数据进行统计分析,通常只能获得前一天数据的统计分析结果,并且只适合数据量不大的情况。然而随着大数据时代到来,银行各种数據呈爆发式增长,该方法已经很难满足数据实时统计、查询的需求。银行开始使用大数据处理技术进行数据计算,一定程度上缓解了海量数据的计算压力,但是数据计算大多仍采用离线计算方式,无法实现真正意义上的实时统计、查询[7-9]。
本文通过对银行报表系统应用背景的分析与研究,利用SolrCloud技术可近实时搜索的特性[10],设计新的报表系统框架,开发了一个针对银行业务的报表系统,以实现对千万级以上数据进行实时统计、查询的目标。本文介绍了系统开发中用到的工具、方法和技术,对类似工作有一定参考价值。
1 SolrCloud
SolrCloud是为了解决海量数据搜索及满足高容错需求,在Solr[11]和Zookeeper[12]基础上设计的分布式搜索引擎。SolrCloud适用于海量数据及高并发搜索服务,可以在毫秒级时间范围内完成千万级以上数据的搜索服务。
SolrCloud是高可靠系统,由多台Solr服务器共同组成Solr集群,通过Zookeeper管理整个集群的运作[13]。SolrCloud将全部索引文件分布到Solr集群中不同Solr服务器上,当用户进行信息检索时,由SolrCloud进行任务划分,将小的检索任务分配给不同Solr服务器进行信息检索,最后将多台服务器检索结果合并,并将结果返回。在SolrCloud中,可以为Solr服务器配置一个或多个备份服务器,当主服务器出现故障时,备份服务器可以代替主服务器对外提供搜索服务,保证搜索服务正常运行。
SolrCloud在继承Solr基本功能的基础上,对Solr原有功能进行了扩展,增加了新特性:①对信息进行集中配置;②自动完成系统容错;③可以完成近实时搜索;④信息搜索时,自动完成负载均衡[14-15]。
2 系统设计
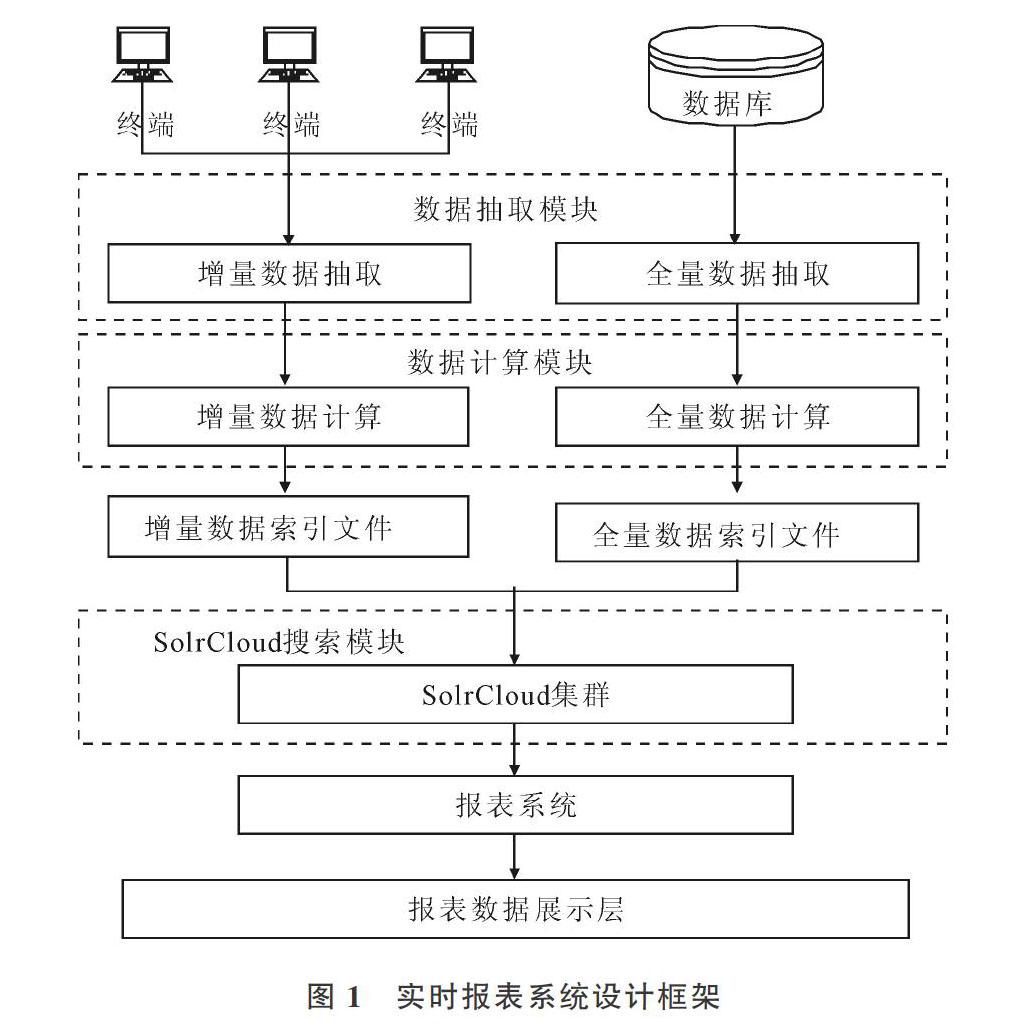
实时报表系统在详细分析银行业务特点的基础上,结合SolrCloud技术的近实时搜索特性,主要分为数据抽取模块、数据计算模块、SolrCloud搜索模块、数据加密模块4个核心模块。其中,数据抽取模块主要功能是抽取实时交易数据和全量数据,为数据计算模块提供原始数据源;数据计算模块主要功能是对报表原始数据进行计算,并将计算结果整理成SolrCloud索引结构数据,为SolrCloud提供数据源;SolrCloud搜索模块主要功能是为银行用户提供实时检索服务;数据加密模块主要功能是保证整个系统中数据传输、上传及计算等过程的安全。图1详细展示了实时报表系统设计框架。
2.1 数据抽取模块
数据抽取模块作为实时报表系统的核心模块,主要完成原始数据采集,为整个报表系统提供数据源。根据银行业务特点,将数据源分为两部分:增量数据源和全量数据源。增量数据源是银行设备的实时交易数据,为整个报表系统提供实时数据源,保证报表系统可以统计任意时间段的交易情况。全量数据源是增量数据源的补充,由于增量数据需要实时更新到SolrCloud集群中,大量、频繁的插入、更新操作,在集群中产生了大量索引碎片,占用大量存储空间,同时影响了检索效率。为解决该问题,每天都需删除增量数据生成的索引,并使用当天全量数据进行SolrCloud索引重建。
数据抽取模块根据数据源不同,可以分为增量数据抽取子模块和全量数据抽取子模块,前者主要进行增量数据抽取,后者主要进行全量数据抽取,并将数据导入到高可靠分布式HDFS文件系统中[16]。
2.1.1 增量数据抽取子模块
增量数据抽取子模块主要介绍实时数据获取和数据计算的具体设计,可以分为4个步骤:第一步,当终端发生交易时,终端会通过加密程序处理数据,生成相应密文上送到服务器;第二步,当服务器上的监听程序监听到数据请求时,数据接口接收上送的密文;第三步,由于交易存在高并发量情况,为了避免数据丢失,在进行数据处理前,将密文存入数据暂存队列中,利用多线程依次读取数据,对密文进行解密,还原原始交易数据;第四步,提取原始交易数据中的有用信息,包含机构名、设备名、交易编码、交易金额等多个重要信息,然后分别从SolrCloud集群中获取设备分类宽表和机构分类宽表的数据,按照设备名称和机构名称分别根据交易码对两张宽表的数据进行重新计算及更新,并将更新后的宽表数据保存至索引更新等待队列中。
在整个处理过程中,由于交易量较大,如果使用传统的串行方式计算交易数据,不但占用资源多,而且耗时长、效率低。因此,采用多线程并行执行数据的计算过程,可以极大地提高计算效率,缩短整个子模块处理时间。
2.1.2 全量数据抽取子模块
全量数据抽取子模块主要介绍全量数据的抽取及上传过程,根据实际需要将整个过程分为4个步骤:第一步,Spring启动定时任务,开始全量数据抽取,将抽取的全量数据保存到本地文件中;第二步,对全量数据文件使用DES加密模块进行文件加密,得到加密数据文件;第三步,将加密数据文件上传到HDFS中,从HDFS中读取接收到的加密数据文件,并对加密文件进行解密,得到原始数据文件;第四步,将解密得到的原始数据文件加载到Hive相应表中。
在该子模块设计过程中,为了保证全量数据抽取顺利完成,针对几个核心问题提出如下解决方案:
(1)全量数据过大、存储难。由于每天产生的全量数据量很大,随着时间增加,其存储问题极大地限制了系统拓展。因此,在该子模块设计时,利用分布式文件HDFS的存储优势完成全量数据存储。全量数据采用文件形式保存,然后存储在分布式文件系统HDFS中。全量数据由数据库中多张表的数据组成,包括交易数据流水表、设备信息表、机构信息表和交易码信息表等。因此,全量数据从数据库导出时不再进行数据处理,直接将每个表的数据保存为本地数据文件,其中每一行保存数据库中的一条信息,同一行中使用逗号分隔不同字段,便于以后对数据文件进行解析,最后将生成的全量数据文件加密后上传到HDFS中。
(2)数据在网络传输过程中传输错误。由于数据在网络传输过程中存在传输错误,为了保证数据传输顺利完成,设计了数据重传机制。当数据文件导入HDFS文件系统后,返回导入结果字段,根据结果字段进行是否重传判断,如果导入成功则完成全量数据抽取,否则进行数据文件重传。
(3)数据在网络传输中丢失信息。数据文件通过网络进行传输时面临信息丢失风险,而数据丢失可能给银行和客户带来极大损失。因此,采用DES加密算法对文件数据加密,以保证数据在传输过程中的安全。
2.2 数据计算模块
数据计算模块根据数据源不同,可分为增量数据计算子模块和全量数据计算子模块两个部分。
2.2.1 增量数据计算子模块
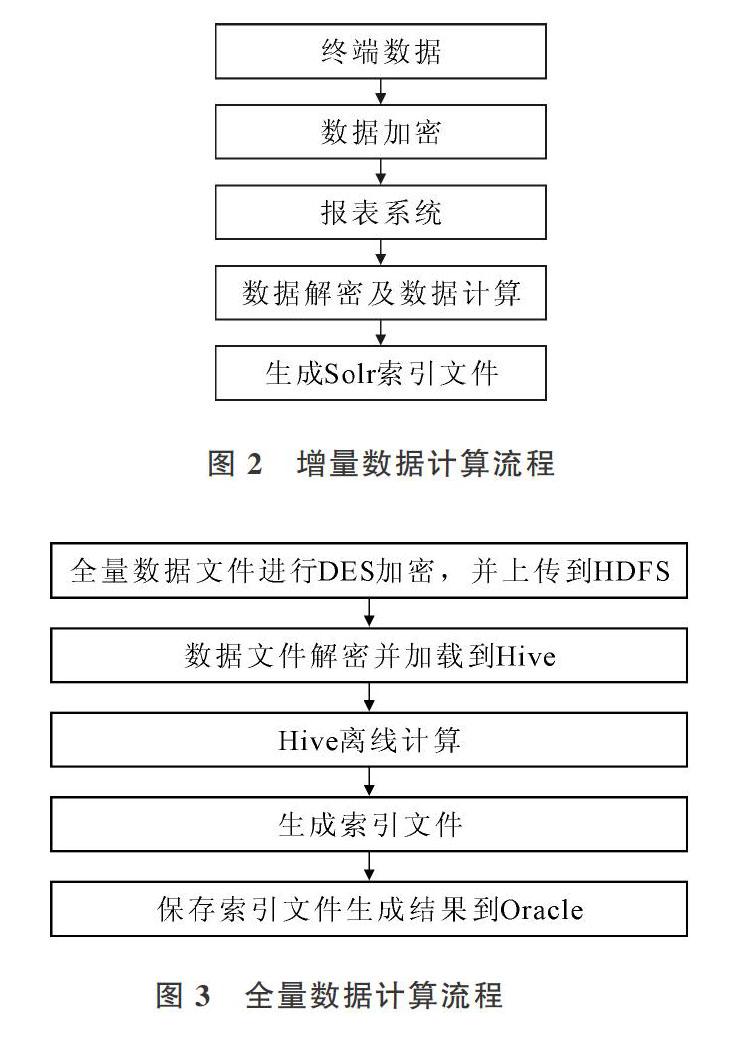
增量数据计算子模块在进行增量数据计算时,由于数据并发量高,采用多线程队列进行数据接收、计算。增量数据计算具体过程如图2所示。
第一步,从终端设备获得实时交易数据并使用DES加密算法对数据进行加密处理,然后将加密数据上送到报表系统后台。当后台线程监听到上送数据时,调用空闲线程接收上送数据并加入等待队列。第二步,當后台检测到等待队列处于非空状态时,调用空闲线程从等待队列获取待处理数据,空闲线程对数据使用DES算法进行解密,得到原始数据信息。第三步,从原始数据信息中筛选出需要的数据进行计算。第四步,将计算结果按照最初设计好的索引格式保存到Solr索引文件中。
2.2.1 增量数据计算子模块
全量数据计算子模块进行全量数据计算时,由于数据量太大,传统的存储方式很难满足系统需要,系统设计时引入适合海量数据离线计算的Hadoop[12]平台,进行数据的分布式存储和计算[17]。全量数据计算具体过程如图3所示。
第一步,对全量数据文件使用DES算法进行加密,然后将加密文件上送到Hadoop平台中的分布式文件系统HDFS中。文件上送结束后,系统会返回上送结果标识,根据结果标识判断下一步执行操作。若标识是0,表示上送失败,后台程序启动重传机制不断进行数据文件上送,直至数据上送成功。第二步,数据文件上送成功后,后台启动解密程序对数据文件进行解密,得到原始数据文件,将原始数据文件加载到Hive中。第三步,当加载结束后,Hive开始对新加载的数据文件进行计算,整个计算根据交易码、机构名称、设备名称等进行分类,将分类计算结果保存在不同中间文件中。第四步,根据规则将多个中间文件按照Solr索引格式进行合并,合并结果保存在相应的Solr索引文件中。第五步,计算完成后,需要将相关信息存储到Oracle操作日志中,主要包括文件信息、上送时间、计算结束时间等。
2.3 SolrCloud搜索模块
SolrCloud搜索模块主要为整个系统提供数据实时查询、统计功能,同时还提供索引创建、更新及删除等功能。在该模块中,索引结构设计对SolrCloud的检索效率会产生很大影响。由于系统中所需报表数据由多张数据库表的有用信息组成,为了提高搜索效率,采用宽表结构对多张表的信息进行融合[18]。同时,该设计的另一个优势是,宽表结构与SolrCloud索引结构一致,创建索引时,只用创建一条索引而不用创建多条索引,减少了索引数量,同时避免跨表检索,缩短了检索时耗,提高了检索效率。系统中宽表结构设计的方法一致,本文介绍其中一个宽表结构,图4描述了报表系统中设备统计报表的宽表结构。
从图4可以看到,宽表中字段由设备信息表、机构信息表、交易流水表的有用信息共同构成,该设计使原来需要创建多条SolrCloud索引,变为只需创建一条索引。同时,也不需要跨域检索信息,只需检索一条索引信息即可,极大地提高了效率。
2.4 数据加密模块
整个报表系统中所有数据均是银行每个客户交易的具体信息,数据通过网络传输到分布式Hadoop集群的HDFS文件系统存在很大风险,一旦出现数据泄露,会给银行和客户造成不可预期的严重后果,因此在报表系统中数据的安全性显得尤为重要。
DES算法作为分组密码算法的一种,算法公开、安全级别高、密钥获取容易、运算过程简洁[19]。因此,DES算法在通信领域得到广泛运用[20]。系统采用DES算法对全部数据文件加密,然后通过网络传输到分布式Hadoop集群,并存储在HDFS文件系统中,最后对新上传的数据文件使用解密算法处理,将其写入新的数据文件中,同时删除原有加密数据文件。
3 系统实现
系统设计从安全性和稳定性考虑,采用多数生产环境所用的Linux系统,主要部署在安装有Linux系统的集群中。实验开发环境是基于VMware技术构建的系统环境[21]。为了实现Linux集群环境,首先需要创建多个VMware虚拟机,然后为其搭建Linux集群,最后配置集群所需各种软硬件环境。针对系统各模块,环境搭建主要分为Hadoop环境搭建、离线数据计算所需Hive搭建、Solr集群环境搭建等几个模块。下文介绍系统安装和部署。
3.1 系统开发环境搭建
主要介绍报表系统在开发前环境的搭建。搭建系统所需的软硬件环境,主要步骤如下:①创建VMware虚拟机,安装Centos系统;②搭建分布式Hadoop集群;③在Hadoop集群中搭建Hive,然后搭建Mysql数据库并存储Hive元数据;④搭建Zookeeper集群,进行Solr集群管理;⑤搭建Tomcat服务器,并完成Solr与Tomcat的集成;⑥搭建分布式SolrCloud集群。
表1详细描述了系统搭建过程中所用软件相关信息。整个系统环境基于Linux集群,每一台Linux主机的环境配置基本相同。因此,主要对一台Linux主机进行环境配置,完成一台配置后将其Linux主机克隆到不同Linux主机中,最后对每台Linux进行必要调整。
3.2 系统实现及展示
在数据计算模块,全量数据计算由于数据量太大,因此本文设计了两种计算方式提高其计算效率:①采用“分治”思想,将全量数据文件分类别计算,并将计算结果保存在中间文件中,最后将所有中间文件合并为特定宽表结构的数据文件;②采用MapReduce并行计算框架对数据进行计算。图5展示了机构分类报表对机构交易数据统计的情况。
实验证明,实时报表系统可以在毫秒级时间范围内完成千万级以上数据的统计、查询。
4 结语
本文针对银行报表千万级以上数据无法实时统计、查询的问题,基于SolrCloud分布式搜索框架近实时查询的特点,设计了一个适合银行的实时报表系统。通过实验证明,基于SolrCloud技术实现的实时报表系统在毫秒级时间范围内,很好地实现了千万级以上数据的实时统计、查询,为银行实时报表系统设计提供了一定参考。现阶段该实时系统也存在一些不足,如全量数据文件在HDFS中进行存储时效率不高,下一阶段需针对此问题着重改进存储方法,以提高文件存储效率。
参考文献:
[1] 王文欣. 中资银行境外分行报表系统分析[J]. 現代商贸工业,2013,25(3):117-118.
[2] 宋华. 企业数据统计分析报表系统的设计分析[J]. 决策与信息:下半月,2013 (5):132-133.
[3] 马文庆,王晋生,张少华. 基于Web的实时报表系统研究[J]. 中国科技信息,2011(21):60.
[4] 颀桓. 基于数据仓库的商业银行报表系统基础数据分析设计[J]. 企业技术开发,2011,30(23):127-129.
[5] 周豪. 大数据量下的实时数据报表系统的设计与实现[D]. 北京:北京交通大学,2016.
[6] 冯鑫永. 用友UFO报表系统存在的问题及对策[J]. 财会月刊,2014(3):96-98.
[7] 周志阳,陈飞. 大数据实时计算平台技术综述[J]. 中国新通信,2017,19(4):47.
[8] 杨东芳,王少英. 面向大数据的计算框架研究[J]. 河南科技,2015(1X):20-22.
[9] 王磊,张真,王胤然. 实时云计算数据库——数据立方[J]. 中兴通讯技术, 2013,19(4):25-31.
[10] SOLR WIKI. Welcome to the Apache SolrWiki[DB/OL]. https://wiki.apache.org/solr.
[11] TREY G,TIMOTHY P. Solr in action[M]. New York:Manning Publications Co,2014.
[12] WHITE T. Hadoop权威指南[M]. 周敏,曾大聃,周傲,译. 北京:清华大学出版社,2011.
[13] 赵璞,朱志祥,张康益. 高性能分布式搜索引擎Solr的研究与实现[J]. 电子科技,2015,28(4):73-75.
[14] RAFAL K. Apache Solr 4 cookbook[M]. Birmingham:Packt Publishing,2013.
[15] 李戴维,李宁. 基于Solr的分布式全文检索系统的研究與实现[J]. 计算机与现代化,2012(11):172-173.
[16] 曹卉. Hadoop分布式文件系统原理[J]. 软件导刊,2016,15(3):15-17.
[17] 许吴环,顾潇华. 大数据处理平台比较研究[J]. 软件导刊,2017,16(4):212-214.?
[18] 马宁,杜武伦,王勇. 面向大数据的商业银行监管报送系统研究[J]. 软件导刊,2016,15(4):157-160.
[19] 沈鑫剡. 计算机网络安全[M]. 北京:人民邮电出版社,2011.
[20] 冯登国. 网络安全原理与技术[M]. 北京:科学出版社,2003.
[21] 王春海. VMware Workstation与ESX Server典型应用指南[M]. 北京:中国铁道出版社,2011.
(责任编辑:何 丽)
