基于机器学习的网络流量分类算法
2019-06-09吕品潘思羽许嘉李陶深
吕品,潘思羽,许嘉*,李陶深,3
(1.广西大学计算机与电子信息学院, 广西南宁530004 ;2.广西多媒体通信与网络技术重点实验室, 广西南宁530004 ;3.广西高校并行与分布式计算技术重点实验室, 广西南宁530004)
0 引言
互联网应用的蓬勃发展催生了种类多样的网络数据。对网络数据进行自动识别和分类,是全面了解网络运行状态、合理分配网络资源、及时发现异常流量、准确做出控制决策的前提和基础,对于实现自动化、智能化的网络控制与管理至关重要[1]。
已有的网络流量分类技术按其核心思想可以分为基于端口、基于内容、基于启发式和基于机器学习的分类方法[2-3]。基于端口的网络流量分类方法是通过TCP或UDP报文的端口号识别不同类型的网络应用,这种方法在互联网发展初期具有很高的分类效率与分类精度。然而在P2P应用兴起之后,由于这类应用常常使用动态随机端口或进行端口伪装,使得基于端口的网络流量分类方法有效性大幅降低[4]。为了避免流量分类过于依赖端口号,研究人员提出了基于内容的网络流量分类方法,也称为深度包检测(deep packet inspection, DPI)[5]。深度包检测首先读取报文载荷中的特征码,然后在已知应用的特征码库中进行匹配,从而实现对网络数据的分类[6]。出于信息安全的考虑,越来越多的网络数据开始采用流量加密技术,这使得深度包检测技术无法获得报文载荷中的特征码,从而无法进行网络数据分类。一些研究人员提出了基于启发式的网络流量分类方法[7],这类方法虽然不依赖端口号和载荷内容,但是其分类精度和效率都相对较低,难以应用于实际。由于上述网络流量分类方法存在局限性,基于机器学习的网络流量分类技术逐步受到广泛关注[8-9]。基于机器学习的网络流量分类技术是通过网络流量的统计特征对其进行分类,该方法不依赖端口号和特征码,具有较高的分类精度和效率,并且能够应对新型网络数据,因此具有广阔的应用前景。
基于机器学习的网络流量分类又可以分为有监督分类和无监督分类,这两种分类方法分别适合不同的应用场景。有监督分类是通过学习样本类别已知的数据集来构建分类模型,可以实现对已知的流量类型的高准确度检测。有监督分类的代表性方法有朴素贝叶斯[10]、支持向量机(SVM)[11]、K近邻(KNN)[12]、决策树[3,13]等。无监督分类是对未分类的流量数据进行聚合分簇[14-15],能够用于未知应用类型的网络数据分类问题。
本文主要针对有监督的分类应用场景,采用分类效率和精度都较高的决策树方法[3],设计了网络流量数据分类算法,其中决策树的构建效率与分类精度成为本文重点考虑的问题。与文献[3]、[13]等不同的是,为了提高分类模型的构建效率,本文根据网络流各个属性的信息熵,选取对分类影响最大的属性子集作为网络流量分类的依据,这样可以在分类精度几乎不受影响的前提下,大幅缩短模型建立的时间,从而提高了决策树的构建效率。通过在真实网络流量数据集上进行实验,并且与开源机器学习平台Weka在相同数据集上的运行结果对比,证明本文提出的网络流量分类模型具有更高的建模效率和分类精度。
本文的主要贡献可总结为以下两点:
① 设计了基于信息熵的网络流量属性选择算法,从网络流量数据的249个属性中选取8个属性进行分类,能达到与使用全部属性相近的分类精度,同时使决策树模型的构建时间大幅降低;
② 设计了基于决策树模型的网络流量分类算法,在真实权威数据集上验证了分类算法的有效性和高效性,达到了比开源机器学习平台Weka更优的性能。
1 基于机器学习的流量分类算法
因不依赖端口号、不依赖数据包有效载荷且具有自适应性,机器学习成为了网络流量分类领域的研究重点,决策树模型是机器学习领域的一个重要分支,是一种基于实例的归纳学习算法。该算法在模型建立后执行分类速度较快,能在短时间内分类大型数据源,并具有较高的准确率,故被各个领域广泛应用。
1.1 特征属性选择
决策树能够从有标记的数据集中构建出有分类和预测能力的模型,其分类算法包括两个步骤:
① 采集带有类别标记的样本数据作为训练集,构建出用于分类的决策树模型。这个过程的本质是从数据中获取知识经验,然后进行机器学习[16]。
② 使用步骤①中构建的决策树模型,对新的无类别标记的样本数据集进行分类。
构建决策树是使用决策树方法进行分类的核心。建模的基本思想是根据属性测试结果把数据集分为若干个子集,然后递归地对相应的子集进行划分,每次划分后产生一个中间节点,当无需划分时,当前节点即为叶子节点。
在划分的过程中,应尽量把所有可能属于同一类别的样本数据划分在决策树的同一个分支,即每个节点包含集合的样本纯度尽可能高。其关键点在于,执行每一步之前如何选择一个最佳的当前测试属性,才能构建出高性能的决策树。
由此可知,决策树建立的重点是在每一次划分前,选择出最佳的属性对样本数据集进行划分。
以S表示当前样本数据集,用“信息熵”来作为样本数据集纯度的度量指标。信息熵Ent(S)的值越小,样本数据集S的纯度越高,其定义如下:
(1)
其中,pi表示当前数据集S中包含的i类样本的数量占整个集合样本总数的比例,y表示S中包含的样本类别数量,即i∈[1,y]。
建立决策树可以使用信息增益指标来进行最佳属性选择。其核心思想在于以信息增益为度量指标,每次选择信息增益值最大的属性来对数据集进行划分,自上而下构建决策树。
信息增益表示采用属性A对数据集S进行划分时,所能获得的收益。信息增益值越大,把属性A作为划分属性获得样本的纯度就越高,所得到的收益也就越大。由于样本数量在每个分支节点的分布不同,该分支节点的重要程度与其样本数量成正比,导出信息增益公式如下:
(2)
其中,S为当前样本数据集合;样本数据中属性A的取值范围为V(A)(V(A) =A1,A2,…,An);以A为划分属性对S进行划分,所产生的分支节点数量为n,在第i个节点上的样本数据集,包括了S中所有在属性A上取值为Ai的样本记录。Si表示第i个节点上的样本集合(i∈[1,n])。
从式(2)可以看出信息增益这一标准偏向于对于值域广的属性,为了减少这种误差,在选择划分属性时,本来考虑以信息增益率作为指标。
在数据集S中,属性A的信息增益率定义如下:
(3)
其中IV(A)是属性A的固有值,当属性A可能的取值数量越多,IV(A)取值越大,其定义如下:
(4)
该算法并不是直接选择信息增益率最大的候选划分属性,而是使用了一个启发式:首先从候选的划分属性中找出信息增益高于平均值的属性子集,再从这个子集中找出增益率最高的属性。
1.2 决策树算法设计与实现
决策树是依赖有标记的训练集生成的分类器模型,因此在建模之前需要先将有标记的样本数据读入程序,作为训练集。预处理操作包括把属性值和属性的名称相关联,以及按照样本数据的类别划分训练集。使用Map
1.2.1 决策树的构建
用递归方法生成决策树。每一次递归选择出最佳的划分属性,使用最佳属性对样本数据集进行划分,每次划分产生决策树的一个分支,划分到不能继续划分出当前数据集的子集时,把当前节点设为叶子节点,算法此时结束。递归构建决策树算法如算法1所示。
算法1决策树构建算法
输入:样本数据集S,样本属性集合A
输出:以N为根节点的决策树T
Step 1:生成包含数据集S的根节点N。
Step 2:判断S的数据类别是否为具有相同的类别标签L,若相同则转step 3,若不同则转step 4。
Step 3:设N为叶子节点,其标签设为L,算法退出。
Step 4:判断A是否为空集或S中样本在A上取值是否相同,若是则转step 5,若不是则转step 6。
Step 5:设N为叶子节点,S中样本数量最多的类别设为该节点的标签,算法退出。
Step 6:选择A中信息增益率最高的属性a作为划分属性。
Step 7:循环对属性a的每个取值ai执行step 8至step 9。
Step 8:节点N产生一个包含数据集Sv的分支,Sv为S集合中属性a取值为ai的样本子集。
Step 9:若Sv为空集,则将分支节点标记为叶节点,其类别标记为S中样本最多的类并退出算法;否则以(Sv,A-{a})为参数递归调用本算法。
1.2.2 使用决策树进行数据分类
使用决策树进行分类的过程如算法2所示。将决策树的根节点N和待分类的测试数据作为输入,过程是根据测试数据属性值进行从根节点至叶节点的匹配,最终到达叶节点的类别即为测试数据的分类结果。
算法2测试集分类算法
输入:决策树测试数据的根节点N,测试数据
输出:测试数据的所属类别
Step 1:找到决策树根节点N的属性a。
Step 2:根据测试数据属性a的值找到N的对应子节点Nc。
Step 3:判断Nc是否为叶节点,如果是则返回Nc的类别作为测试数据的分类结果;否则以(Nc, 测试数据)为参数递归调用本算法。
1.2.3 评价指标
用召回率(Recall)和精度(Precision)评估该决策树分类性能。统计如下三个变量:
用N表示:统计数据集中每个类别的样本数量。
用F表示:统计决策树分类结果中每个类别的样本数量。
用R表示:统计决策树能正确分类的每个类别的样本数量。
Recall和Precision计算公式如下:
(5)
(6)
2 实验结果分析
本节通过实验来评估基于机器学习的网络数据分类算法,使用准确率(Accuracy)、精度(Precision)、召回率(Recall)、建模时间、分类时间作为考察算法的关键指标。考虑数据拥有信息量与还原过程的复杂度,使用网络数据流级别的数据类型进行分类,能够在保证拥有的信息足以判别数据类别的同时,付出较小的计算代价和存储成本。
实验使用1台CPU主频为2.50 GHz、内存大小为4 G、装有Windows 64位操作系统的PC,用Java编程语言实现本文提出的网络流量分类器。在决策树分类算法的研究过程中,使用剑桥大学Moore教授在文献[17]提出的数据集作为实验数据集。Moore教授的实验小组在2003年8月20日收集了10个时间段内的网络流量数据(每个时间段的数据是一个数据子集),这10个时间段的起始时间随机选取、均匀分布,每个时间段长约为28 min。
2.1 实验设置
为了对本文构建的决策树模型进行性能评估,设计了以下3个实验。
实验1:选择特征属性。数据集中每个数据样本包含249个特征属性,为了提高建模效率,从中选取一个特征属性子集构建决策树。本实验的目的是验证所选择的特征属性子集能够在保证模型性能的前提下,使建模效率大幅提高。
实验2:确定实验的训练集和测试集。用数据集中的10个数据子集分别建立决策树模型,并对同一个测试集进行测试,选择测试结果最佳的决策树模型的数据作为训练集;从每个数据集中随机抽取10 %的数据合成测试集TEST。使用从实验1选择出来的特征属性子集构建的决策树进行测试。
实验3:进行对比实验。把实验结果和开源机器学习平台Weka的实验结果进行对比。
2.2 实验1:属性选择实验
Weka是一个开源的机器学习实验平台,可在该实验平台上进行数据的分类、聚类,及对数据属性进行选择等。首先使用data1进行实验,以data1的全部数据做为训练集,使用data2作为测试集,如表1所示。

表1 实验1数据集Tab.1 Dataset in experiment 1
使用样本数据的全部属性(249个)进行第1次实验,得到决策树平均建模时间为15.97 s,对测试集进行分类预测的时间为1.3 s,总体的分类准确率为98.51 %。
对data1使用特征属性选择算法,信息增益率从大到小排名前八的属性编号为1、38、60、79、96、101、143、188。使用这8个属性进行下一组实验,得到决策树平均建模时间为0.42 s,对测试集进行分类的平均时间为0.15 s,总体的分类准确率为98.27 %。两次实验平均建模时间对比如图1所示;网络流量平均分类时间对比如图2所示;网络流量分类精度对比如图3所示。第2次实验建模时间仅为第1次实验的2.63 %,分类时间仅为第1次实验的十分之一,而两个模型分类的整体准确率相差不到0.3 %。

图1 建模时间对比Fig.1 Modeling time comparison

图2 分类时间对比
Fig.2 Classification time comparison

图3 分类精度对比
Fig.3 Classification accuracy comparison
对于具体的网络流量种类,两次实验得到的分类精度和召回率对比分别如图4和图5所示。使用属性子集建立起来的模型,虽然对于小流量(例如FTP-DATA)的分类精度和召回率略有降低,但对于WWW、Mail、P2P等主要流量分类的精度和召回率,与使用原始数据集建立的模型基本持平,甚至在一些类别上有所提高(如MULTIMEDIA)。

图4 两次实验精度对比
Fig.4 Precision comparison

图5 两次实验召回率对比
Fig.5 Recall comparison
上述结果表明,在特征属性选择算法基础上构建决策树模型,能够在分类精度几乎不受影响的情况下,大幅降低建模时间。因此使用特征属性子集来构建决策树的方法是有效的。
通过对每个数据集使用特征属性选择算法并进行测试验证,最终选择序号为1、39、66、79、97、101、125、136的属性组成属性子集进行后续的实验。特征属性子集包含的属性及其含义如表2所示。
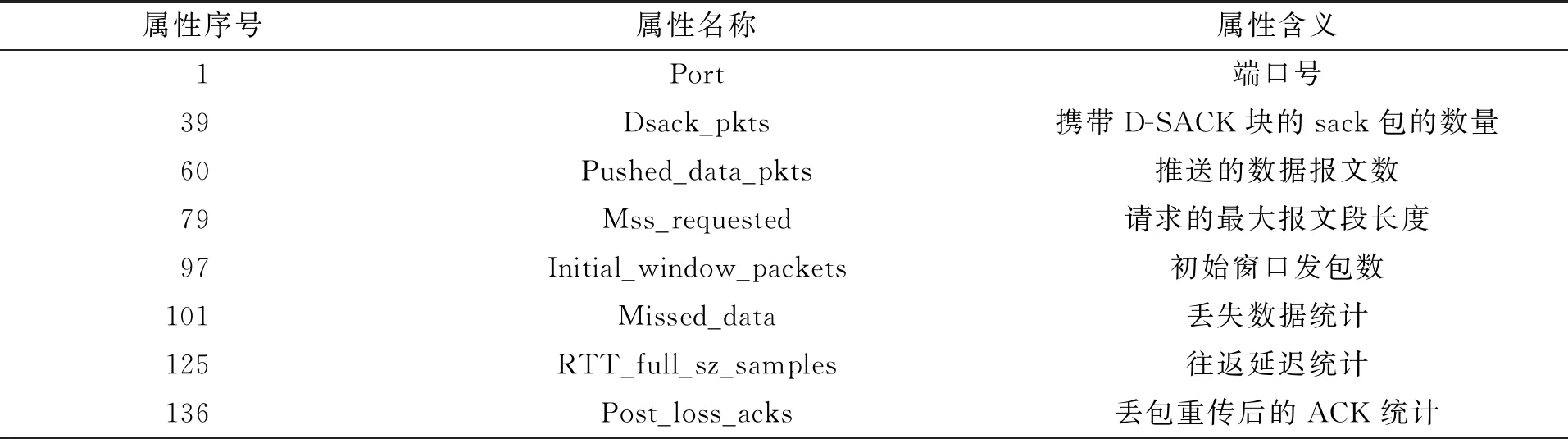
表2 选择出的特征属性Tab.2 Selected feature attributes
2.3 实验2:确定测试集和训练集
使用10个数据集分别作为训练集,构建出10个决策树分类模型。依次对这10个模型进行分类测试,比较其建模效率和分类性能等指标,确定data6为构建的决策树模型的训练集。本文基于data6构建的决策树模型记为DTC(decision tree-based classifier)。将TEST作为测试集,在该数据集上运行Weka和DTC比较建模效率和网络流量分类性能,实验结果见“2.4节”。
2.4 实验3:与Weka平台进行比较
本实验中,首先在Weka平台上以data6为训练集,TEST为测试集进行实验,然后使用DTC模型在TEST上进行测试。两次实验得到的建模效率对比、分类时间对比、总体分类精度对比分别见图6~图8。
图6表明,DTC的建立模型时间为137 ms,仅为Weka平台建模时间(260 ms)的三分之二。从图7可以看出,使用相同的测试集进行分类,DTC的分类时间高于Weka。图8则显示出DTC和的分类精度略高于Weka。
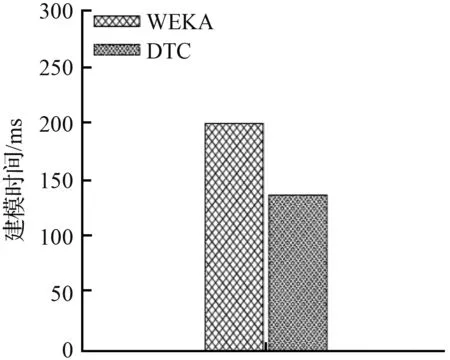
图6 建模时间对比Fig.6 Modeling time comparison

图7 分类时间对比
Fig.7 Classification time comparison

图8 分类精度对比
Fig.8 Classification accuracy comparison
具体到每种网络流量,图9和图10分别表明DTC和Weka平台对相同数据集分类的精度和召回率。从图中可以看出,对于主流流量WWW、Mail,两者的精度和召回率大体上保持一致,并且都接近100 %。值得注意的是,对于当下较为流行的P2P流量分类结果,DTC的召回率虽稍低于Weka,但分类精度相对Weka提高了约60 %。而在所占比例较小的网络流量中,DTC相比Weka也有一定优势。例如,对于ATTACK,DTC的精度是Weka的2.5倍;而对于Services,DTC的分类精度可达到100 %。

图9 网络流量分类精度对比
Fig.9 Precision comparison
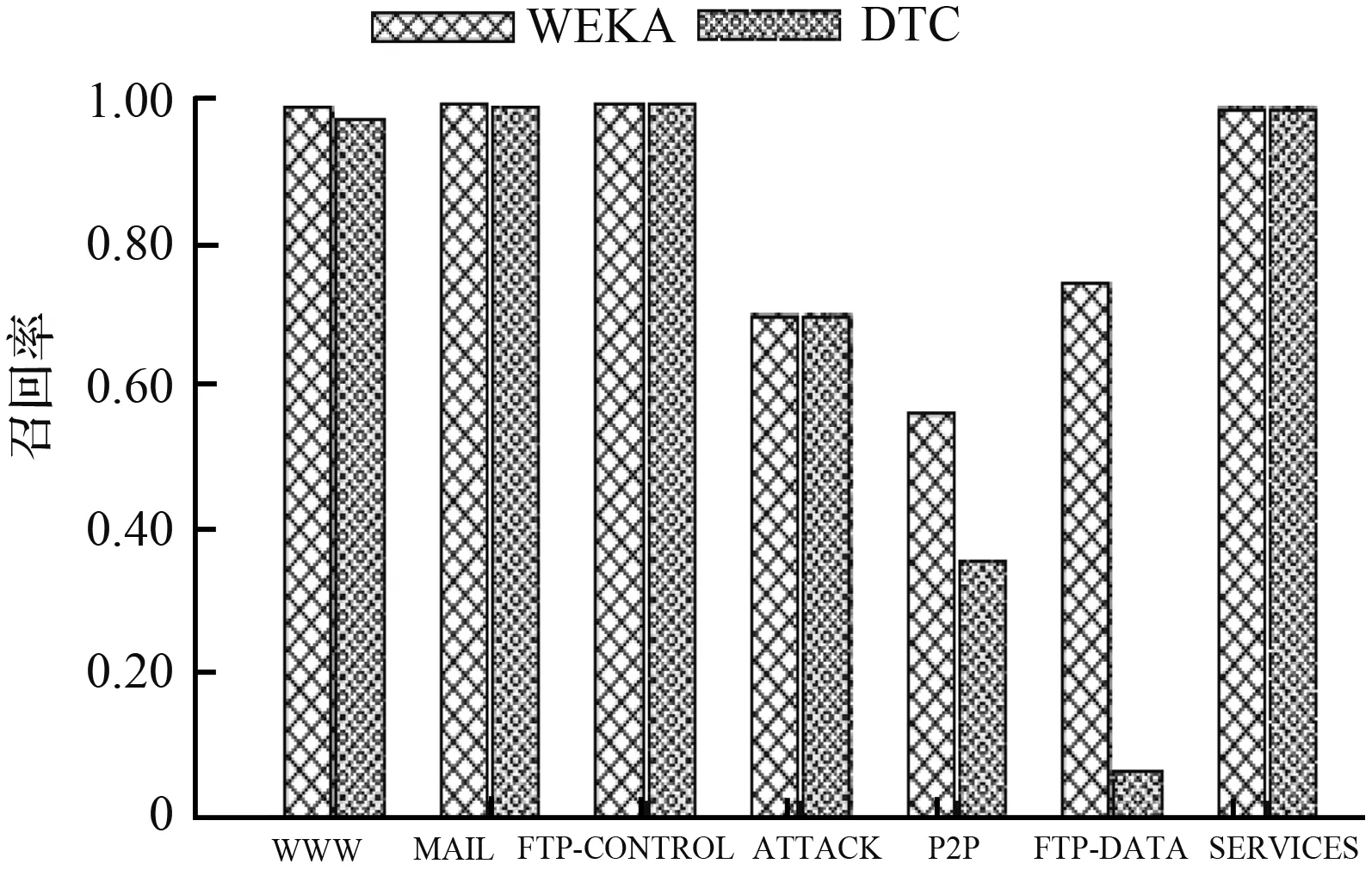
图10 网络流量分类召回率对比
Fig.10 Recall comparison
从上述实验结果可以看出,本文提出的决策树分类模型相对于Weka平台的决策树模型,在建模时间方面具有显著优势,并且一些网络流量类型上比Weka具有更高的分类精度。因此,本文提出的基于机器学习的网络流量分类算法具有良好的实用性和高效性。
3 结语
为了对网络流量进行高效的分类,本文提出了基于机器学习的网络流量分类算法。该算法基于机器学习中的决策树模型,对网络数据流量进行分类。在建模阶段,通过特征属性选择算法选择信息增益率高的属性构成特征属性子集,采用开放数据集作为模型的训练集。在测试阶段,使用建模时间、分类时间、准确度、召回率、精度等指标进行评价,将实验结果与Weka实验平台的测试结果进行对比,证明了本文提出模型的高效性。Weka平台的建模时间是本文提出模型建模时间的1.5倍左右,且两者在主流网络流量分类方面的性能相当,对于某些小规模流量本文方法的分类性能甚至优于Weka。
本文提出的方法属于机器学习中的有监督学习,需要事先收集数据集作为训练集。在未来的研究工作中,将继续深入研究无监督学习策略,在没有事先构建模型的情况下对网络流量进行分类,进一步增强网络流量分类器的实用性。
