一种基于CUDA的无源雷达相干积累及徙动校正算法实现
2019-06-06王兆伟李晓波
王兆伟,李晓波,谢 佳
(中国电子科学研究院,北京 100041)
0 引 言
外辐射源雷达是本身不发射电磁波,利用广播、电视等信号作为辐射源的被动雷达,具有反隐身、抗低空突防及生存能力强等优点,近年来成为国内外研究热点之一[1-3]。
外辐射源雷达由于其自身的优点,经常被用于预警探测系统。而预警雷达对系统的实时处理能力提出了很高的要求。早期的外辐射源雷达主要以调频广播、模拟电视信号作为辐射源,采样率只有几十kHz并且带宽小,分辨率低,一般不需要进行距离徙动校正,因而,普通CPU平台就能实现快速处理。但是,模拟信号分辨率过低(例如,对于200 kHz带宽的信号,分辨率为750 m),严重制约了雷达系统的性能。随着数字信号处理技术的发展,数字电视日益普及,逐渐取代模拟电视技术[4]。同时,数字电视信号具有大带宽、信号稳定等优点,以数字电视信号作为辐射源能够保证较高的分辨率(例如,7.56 MHz带宽的数字电视信号,分辨率为20 m左右)。因而,基于数字电视和数字广播的外辐射源雷达成为外辐射源雷达发展的趋势。
但是,数字电视信号带宽大,采样率通常高达10 MHz,每秒的数据量是模拟信号的上百倍。此外,以数字电视为辐射源的外辐射源雷达分辨率高,当目标高速运动时会出现跨距离单元徙动的问题,在检测前需要进行距离徙动校正处理。而高采样率和距离徙动校正都极大地增加了处理的运算量,现有的处理手段难以满足快速处理的要求。而高性能计算技术的发展,为快速实现提供了可能。
基于此,本文提出了一种基于CUDA的外辐射源雷达相干积累及徙动校正算法的实现方法,并结合GPU的硬件结构和算法特点,从存储结构,数据访问和计算方法三个方面对相干积累及徙动校正算法进行了优化,提高了资源的利用率和信号处理的速度,实现了系统对快速处理的要求。
1 相干积累及徙动校正方法
本文相干积累采用二维分时处理方式,将一维信号做分时处理,划分为快时间和慢时间,利用运动目标多普勒信息进行相干积累检测。具体步骤如下[5]:
(1)分时处理
按系统要求的最大不模糊速度及最大探测距离确定分段长度和分段数,将一维回波信号按分段数进行分段,将一维参考信号进行分时处理(每段长度以末尾补零方式与回波信号保持一致),各段可等效为一个脉冲,等效脉冲内为快时间,各脉冲间为慢时间,构成二维矩阵。
(2)距离向压缩
回波信号与参考信号,各对应等效脉冲间通过匹配滤波(FFT 频域实现)实现距离向脉冲压缩。
(3)各段间通过FFT 获取目标多普勒信息,最终得到二维相干信息
当积累时间较长,目标运动速度很高时,在相参积累时间内,目标的距离走动会超过半个距离分辨单元。这时就需要进行徙动校正,本文采用Keystone变换的Chirp-z算法进行徙动校正[5]。Chirp-z变换基本原理是采用螺线抽样,求取各采样点的z变换,以此作为各个采样点的DFT值。设有限长序列x(n)n=1,2,…,N-1具体步骤如下:
(1) 选择一个最小的2的整数幂次L,使其满足L≥N+M-1,以便采用基-2FFT算法,其中M为一个CPI内的脉冲数。
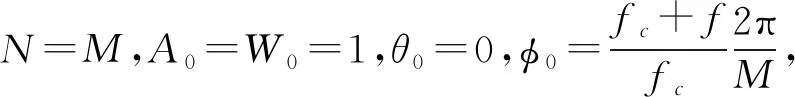
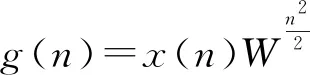
G(k)=FFT[g(n)],L点
(4) 形成L点序列h(n):

(5)V(k)=G(k)H(k),v(n)=IFFT[V(k)],取前M点,作权值即得所求。
其中A0为起始抽样点的矢量半径长度,Θ0为起始抽样点的相角,W0为螺线的伸展率,W0=1表示是半径为A0的一段圆弧。若又有A0=1,则这段圆弧是单位圆的一部分,Ф0为两相邻抽样点之间的角度差。
相干积累及徙动校正处理流程如图1所示:

图1 相干积累及徙动校正处理流程图
2 基于CUDA的算法实现
2.1 CUDA简介
CUDA (Compute Unified Device Architecture,统一计算设备架构)是一种专门为提高并行程序开发效率而设计的计算架构,它将GPU视作一个数据并行计算设备,并且无需把这些计算映射到图形API。CUDA程序的开发语言以C语言为基础,并对C语言进行扩展。
CUDA编程模型将CPU作为主机(Host),GPU作为协处理器(co-processor)或者设备(Device)。在一个系统中可存在一个主机和若干设备。在这个模型中,CPU和GPU协同工作。CPU负责进行逻辑性强的事务处理和串行计算,GPU则专注于执行高度线程化的并行处理任务。CPU和GPU各自拥有相互独立的存储空间(主机内存和设备显存)。CUDA程序是包含主机代码和设备代码的统一源代码。当算法并行部分确定后,并行的部分会形成一个个kernel,每个kernel之内并行,kernel之间串行。串行部分由CPU进行管理,而并行部分由GPU进行运算[6]。结构图如图2所示。
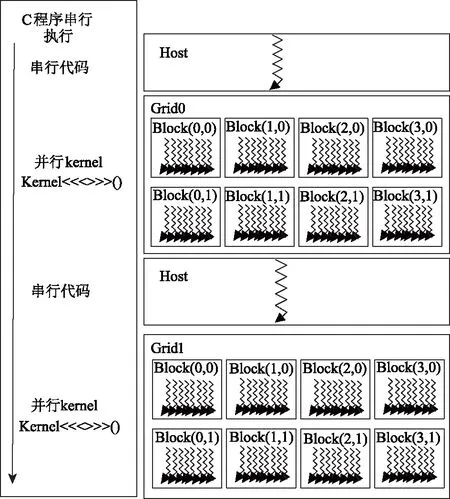
图2 CUDA编程模型
2.2 相干积累及徙动校正算法并行分析
一个算法是否适合CUDA并行关键在于算法的结构。适合CUDA并行的结构如下:
相同数据量,每次执行的数据块不能太小。CUDA并行需要发起线程,数据块越小,发起线程的次数越多,损耗的时间越长。同一块数据之间前后联系不能太紧密。如果同一块数据前后联系紧密,则意味着线程与线程之间需要通信,一个线程需要等待另一个线程的结果,这样会大幅度降低并行的能力。设备与主机之间的通信不能过多,因为CPU内存与GPU显存之间通信是通过总线完成的,而总线的带宽一定,如果数据量过大,传输数据会占用很大一部分时间。这样的结构适合于CUDA并行提速。相干积累及徙动校正算法数据块大,数据前后联系很小,设备与主机的通信只有两次(数据从CPU内存传输到GPU显存和从GPU显存传输到CPU内存),所以结构上完全符合CUDA并行的要求。
由图1可知,相干积累和徙动校正算法的CUDA执行流程如图3所示:
(1) 分段:可以视为数据拷贝,数据前后没有关联,可发起多个线程每个线程完成一个复数类型数据的拷贝。
(2)fft/ifft:参考文献[10]中验证了CUDA作fft/ifft的快速性。
(3) 复乘:两组数据对应位置相乘,与前后数据无关不需要线程间的通信,可以发起多个线程每个线程计算一个数据。
(4) 矩阵转置:可以视为数据拷贝。
由上可知,相干积累和徙动校正算法完全适合用CUDA并行提速。
2.3 优化
CUDA并行处理性能优化包括三个基本策略:
(1) 最大化并行执行,发起的线程个数最好与流处理器的数目相匹配。
(2) 优化内存使用,使用常量内存和共享内存等手段使设备与全局内存之间的通信减少。
(3) 优化指令使用,在权衡计算精度与速度的基础上,优化指令结构。

图3 CUDA执行流程
根据以上三个策略,本文也对算法的实现进行了优化。
初始阶段本实验的核心问题在Chirp_z耗时太长,由于其运算过程中存在多重循环故其执行所耗时间最长,未优化前耗时达到总执行时间(6144段3.6 s左右)的80%以上。故优化的侧重点放在了该部分。
首先,针对多重循环(本实验中为16384重循环),本实验进行了循环分割。通过分析发现,循环之间是没有联系的,而且每次循环的数据量也不是很大,故在开辟显存时可以开辟一块大的存储空间存放多次循环所用到的数据。即将多重循环以牺牲显存为代价合并为一重循环(本实验为将512次循环合并为一次),分割之后的chirp_z的循环次数得到极大的减少(由16384重减少到32重)。这样,既充分利用了显存资源也极大的减少了执行时间。
其次,通过分析发现chirp_z部分函数较多,单次运行数据量不大而且存在kernel之间数据相互独立的情况。Kernel越多线程块儿发起的次数越多,造成的资源和时间的浪费越大。本实验中,进行了内核的合并,将多个数据相互独立的核函数合并为一个,即在实现kernel时,加一个判断线程号小于某个值时执行原有kernel1,大于该值时执行原有kernel2。最大化的利用了系统的资源,同时线程发起的次数减少也节省了执行时间。
经过上述两次优化,chirp_z的执行时间减少为当前总时间(6144段1.6 s左右)的25%,优化的重点转移到chirp_z外。
由图3可知,要进行CUDA并行处理必须先将数据从CPU内存传输到GPU显存,但是CPU内存和GPU显存之间总线的带宽是有限的,而随着分段数的增多,数据量也不断增加,数据传输的时间也不断增加。当数据分6144段时,数据传输的时间占总时间(6144段1.6 s)的20%以上。为了提高数据传输的速度,本次实现使用锁定页内存进行了优化,使传输时间减少了50%之多。数据传输包括两部分:CPU->GPU 和GPU->CPU。考虑到由于CPU->GPU传输的数据是在分段之前故数据量很少(只有GPU->CPU的1/6),而在数据从GPU->CPU的前面是fft和数据拷贝操作,可以进行异步执行优化。对数据进行了分割(等分成六份),使用流操作将主机内存和设备显存之间数据传输与核函数执行进行了优化,使得在主机内存和设备显存之间数据传输时,GPU执行其他kernel,减少了执行时间。同时,为了减少设备与全局内存的通信,本次实现对多个kernel进行了共享内存优化,也减少了执行时间。经过优化,执行时间得到极大的减少,基本能够满足快速实现要求。
3 实测数据处理结果
数据说明:
辐射源:DTTB数字电视信号
原始数据:回波信号和参考信号 (各9 M复数类型数据 68.6 M)
分段:1024段 数据增加一倍;6144段数据增加6倍。
本文对相干积累和徙动校正算法在CPU和在GPU环境下的计算效果进行比较,实验环境如下:
应用本文实现方法如图4所示:
图4 a)、b)为基于CUDA的二维相干积累实现结果,其中图a)为未经过keystone校正的结果,图b)为经过keystone校正的结果。由实验结果可知,经过keystone校正后目标信噪比明显提高(本次实现5 dB以上)而且没有造成目标点的丢失。验证了基于CUDA的相干积累及徙动校正算法的实现结果是正确的。
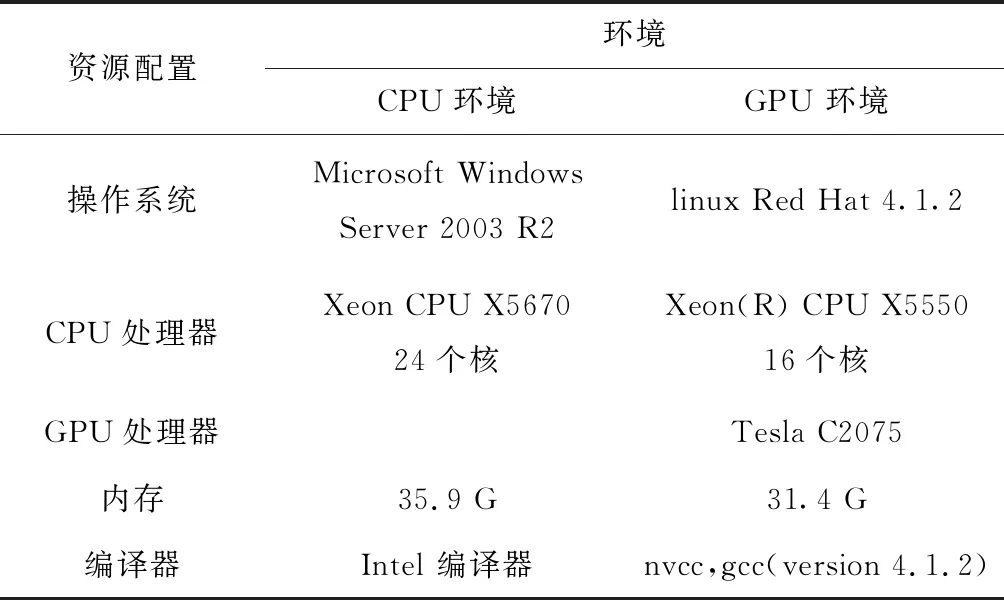
表1 不同环境资源配置
两种平台下相干积累及徙动校正性能对比如表2所示:

表2 不同环境下处理性能比较(单位 ms)
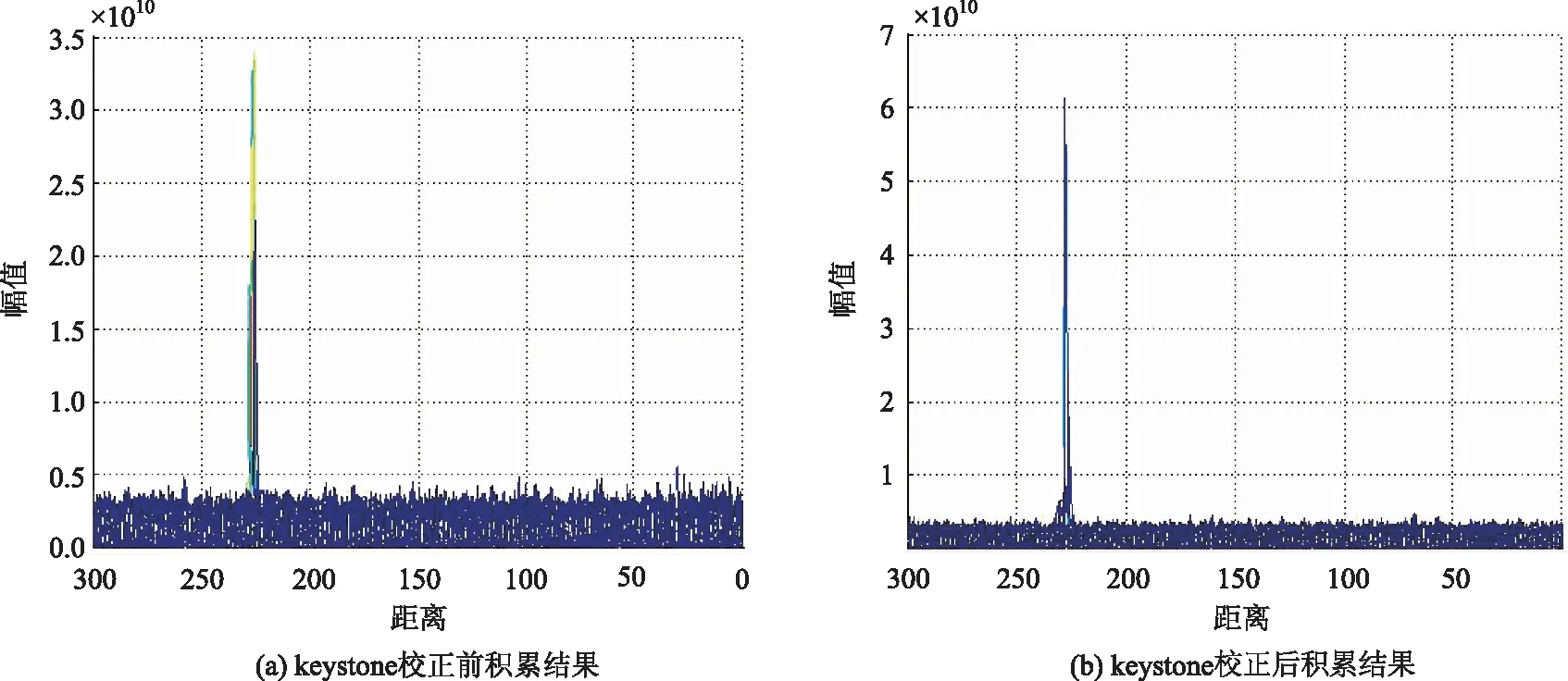
图4 keystone校正前后对比图
CPU平台下,采用OpenMP并行方法,使用20个CPU内核进行运算,可以发现1024段、2048段、6144段的处理时间基本呈现线性增长趋势,这与其运算量的线性特点相符合。在GPU平台下,采用CUDA编程模型并根据并行需要对算法的结构进行了优化。1024段、2048段、6144段的处理时间也同样呈现线性趋势。GPU平台和CPU平台下的结果相比较发现,使用CUDA编程模型比使用CPU平台OpenMP并行所用时间明显减少,加速比可达11倍。在3.3节优化分析中提过,由于CPU到GPU总线速度的限制,CPU内存和GPU显存之间数据的传输在算法执行中的所耗费的时间比重越来越大。而对于加速比列进行分析发现,1024段到2048段加速比由10.05提升到11.03。数据分2048段的情况下,在数据传输耗时多的情况下仍能得到更高的加速比,也验证了3.2节中提到的GPU更适合大数据量的运算。
由2048段到6144段加速比由11.03提升到11.35,提升空间并不是太大。这主要是因为CPU内存与GPU显存之间数据传输耗时太多。数据分6144段时,数据传输的时间120 ms左右,严重限制了性能的提升。所以,在数据过大时,受显存和总线的限制,算法执行的性能会受到很大影响。所以,在选择数据块的大小时要充分地考虑总线和显存的限制,不能一味的加大数据块。通过表2可以发现使用CUDA编程模型时,基本能够达到实时处理的要求。
4 结 语
随着大规模计算需求的增长,基于GPU的通用实现方法得到了广泛的使用。本文提出的实现方式通过在存储结构,数据访问和计算方法三个方面的优化,在性能上有了极大的提高,能够满足快速实现的要求,这也显示出GPU相对CPU在可并行运算方面的绝对优势。
