基于SSD算法的实时无人机识别方法研究∗
2019-06-06李秋珍熊饶饶王汝鹏
李秋珍 熊饶饶 王汝鹏 祁 迪
(1.武汉数字工程研究所 武汉 430074)(2.华中科技大学计算机科学与技术学院 武汉 430074)
1 引言
近年来,无人机技术的快速发展及无人机使用门槛不断降低,无人机在军事、民用等领域得到了广泛运用。同时也带来了一些新问题,如无人机非法入侵私人区域、无人机碰撞行人等引发的安全问题,因此无人机管控势在必行。由于无人机具有体积小、低速以及电磁信号强度低等特点,所以传统的安全措施如声传感器或雷达是无法检测到小型无人机的,迫切需要建立一套对指定区域无人机目标进行实时、准确地识别和监控系统。无人机识别系统的重要组成部分是图像识别,其功能是将摄像头捕捉到的图像或视频信息进行预处理,从中识别出无人机,从而实现对无人机的检测、识别、监控和预警。图像物体的检测与分类一直是计算机视觉领域研究的重要课题,受益于近几年深度学习的快速发展,物体检测与分类识别有了理论支持和准确性的保障。在物体检测方面有YOLO算法以及后来的SSD算法;由于YOLO简单粗暴地将图像进行网格划分,然后对每个网格进行处理,这样导致定位不精确等问题,特别是小物体及相互靠近的物体,效果不够理想。而SSD算法结合了YOLO和anchor进行检测,在检测的速度和准确性方面优于YOLO。物体分类识别最开始使用的是KNN(K-Nearest Neighbor,K最近邻)算法,其优点是实现方便、数据训练快,缺点是无法适用于太大数量的数据,程序运行时算法加载和初始化过程太耗时。后来又使用深度网络AlexNet,其精确度比KNN要好很多。
基于现有的方法和理论,提出了两种基于SSD算法的实时无人机识别方法,设计并实现了一套实时无人机识别系统,它能够直接从摄像头读入视频流,对视频流中的图像实时识别,将识别结果加入到原始图像中形成新的视频流,并向浏览器推送新的视频流和识别结果。
2 相关工作
2.1 无人机检测
目前,无人机检测主要有以下两类方法。
一是采用传统方法。首先通过滑动窗口来产生不同大小和位置的候选区域图像(图像金字塔),然后对候选区域图像手工提取特征,如SIFT、HOG等特征,最后采用SVM、Adaboost等分类器进行分类。
二是采用深度神经网络[1~2]的方法进行对象检测。Girshick R在文献[3]中提出了R-CNN(Regions with CNN features)方法,该方法首先对输入图像提取约两千个感兴趣区域(ROI),然后对每一个ROI计算CNN特征,然后对每个ROI使用SVM分类器进行分类,如图1所示,该方法缺点在于需要大量计算,计算一张图片需要数十秒,显然无法满足实际要求。文献[4]中提出了SPP-Net(Spatial Pyramid Pooling-Network,SPP网络),如图2所示,该方法在R-CNN的卷积层和全连接层之间增加了Spatial Pyramid Pooling(空间金字塔池化)层,使得SPP-Net比R-CNN有着更快的检测速度,但缺点是训练时间长、存储开销大、训练网络过程中无法更新SPP以下的层。针对这两种方法的局限性,Girshick R对R-CNN进行了改善,提出了Fast-RCNN[5],如图3所示,该方法采用了ROI Pooling代替SPP,训练过程在一个阶段完成,速度和准确性都有了较大的提升。针对候选区域的产生方法,文献[6]中提出的FasterR-CNN方法,该方法使用RPN(Region Proposal Network,候选区域网络)来产生候选区域,如图4所示,FasterR-CNN在计算速度上有一定的提高,但对实时计算引用仍然不够快。Redmon J在文献[7]中提出了YOLO算法,相比于Faster R-CNN方法,YOLO的网络结构非常简单,图像经过一次网络,就能得到图中物体对应的位置和该位置所属类的置信概率,如图5所示;首先,将原图划分为S*S的网格,目标中心点所在地各自负责该目标的相关检测,每个网格预测B个边框及其置信度,以及C种类别的概率,YOLO中,S,B,C取决于数据集中的物体类别个数。文献[8]提出了SSD算法用于对象检测,该算法在检测的速度和准确性方面优于YOLO。
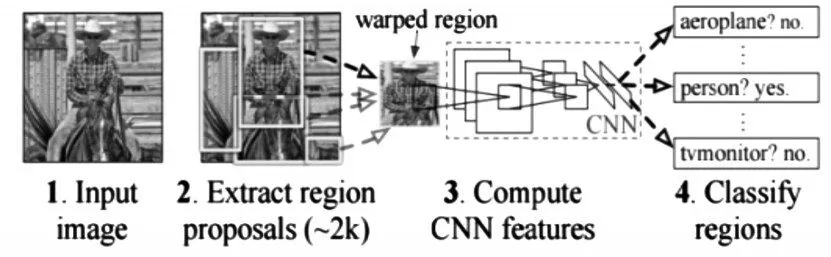
图1 R-CNN的基本算法流程

图2 SPP-Net的基本算法流程
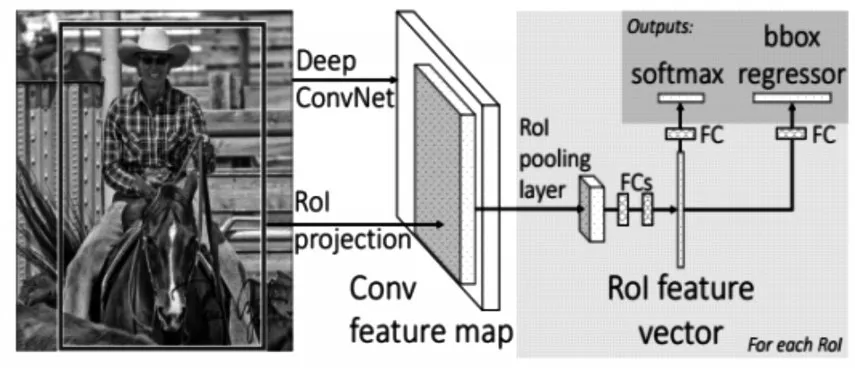
图3 Fast R-CNN的基本算法流程
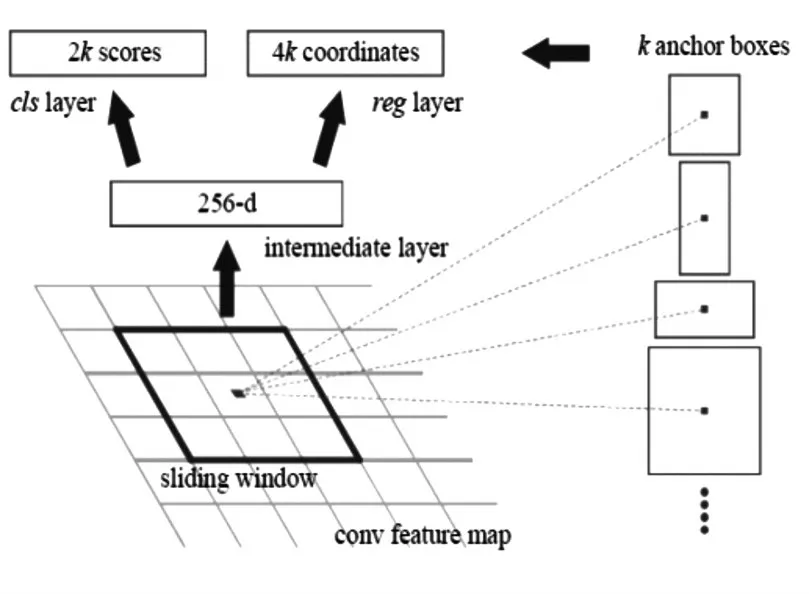
图4 RPN网络结构
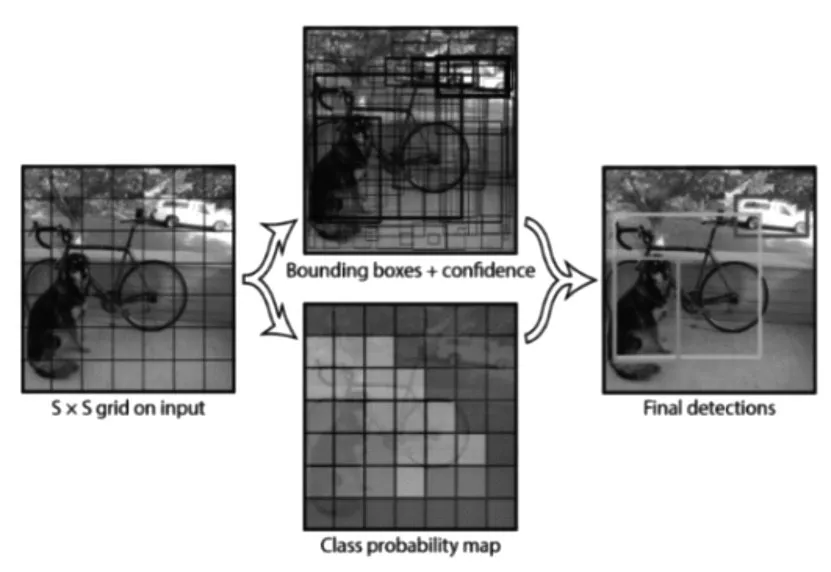
图5 YOLO的基本算法流程
2.2 无人机分类
无人机的分类方法通常分为两大类:一类是利用传统方法,对检测到的无人机提取手工特征,例如无人机的机翼形状、颜色等特征;另一类是采用深度神经网络的方法,提取无人机的特征,浅层的网络如LeNet[9]、AlexNet[10],深层的网络例如ResNet[11]、InceptionNet[12],然后将提取到的特征送入到一般的浅层分类器里面,进行训练和预测。
3 无人机识别系统和识别方法
3.1 系统设计
1)系统处理流程
在实际应用中,为了能够实时、准确地识别划定区域内的无人机,通常采用网络摄像头对划定区域进行监控,将网络摄像头输出的视频流送入到无人机识别系统中。图6所示为系统处理流程图。首先采用视频处理工具JavaCV对视频流进行抓帧;然后对抓取到的图像进行预处理,生成300*300大小的图像;其次将预处理后的图像送入到SSD中进行检测;将检测到的无人机图像抠取出来,送入到无人机分类器中进行分类,最终识别出无人机种类;最后将无人机的位置、种类和置信度标识在原图像中,压缩成新的视频流推送到前端浏览器上实时展示;在浏览器中安装VLC插件,可以实时播放无人机识别信息。
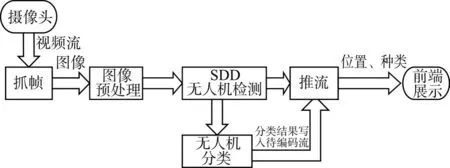
图6 无人机识别系统处理流程图
2)流式计算框架Storm
系统基于Storm分布式实时流式计算框架。抓帧线程运行在Spout中作为数据源,不断地向下面的bolt传递帧数据。SSD bolt接收到Spout抓取的帧图像(经过预处理)之后,识别图像中的无人机,然后将无人机的坐标以及原始图像发送给Resnet bolt。Resnet负责将SSD检测到的无人机特征提取出来,然后发送给KNN进行分类。KNN会在程序启动的时候加载数据集,并且进行训练得到模型,在接收到Resnet提取的特征之后,KNN根据提前训练好的模型对其进行分类,最终得到该帧出现的无人机种类。
Caffe框架是由美国加州伯克利大学开发的一个深度学习框架,由C++语言编写,运行速度快,Caffe内部提供了一套基本的编程框架,可以实现GPU并行架构下的深度卷积神经网络、深度学习等算法,并且支持GPU和CPU的无缝切换。网络定义采用文本文件定义,方便编写。因此,本识别系统就是采用Caffe框架完成底层的深度学习算法实现。
3.2 图像预处理
深度神经网络能够有良好的学习效果,决定性因素之一就是训练集大小。如果训练集的规模太小,达不到网络模型参数要求,那么神经网络将难以提取足够的特征进行学习,在实际应用时也达不到很好的效果。本系统所需要的无人机图像数据主要来自互联网,很多情况下无法获取大量图像数据,所以采用对图像进行预处理,就可以提升图像数据量。图像预处理主要包括改变图像宽高比、旋转、剪切变换、放大缩小等。
3.3 无人机检测方法
上述介绍了目前常用的对象检测方法和理论,为了满足识别系统的实时性和准确性要求,本文采用SSD算法对无人机进行检测。如图7所示,与YOLO不同的是,SSD采用了特征金字塔结构进行检测,使用了多尺度featuremaps(特征平面)同时进行Softmax分类和位置回归,因此在检测的速度和准确性方面优于YOLO。相比R-CNN系列,抛弃了regionproposal的过程,计算速度更快。
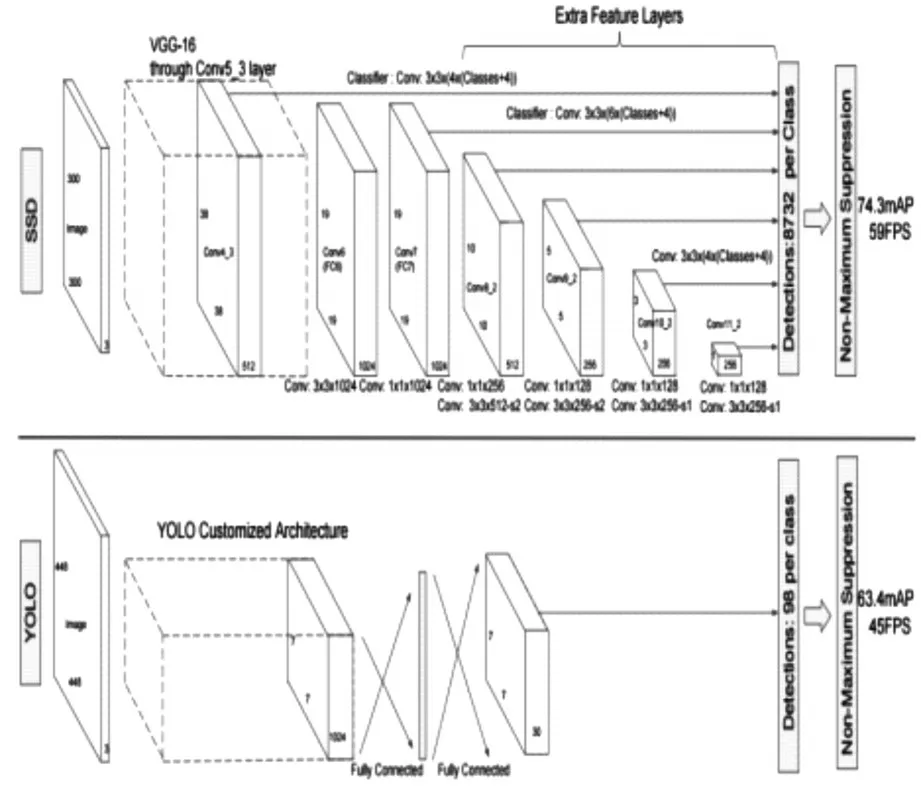
图7 SSD和YOLO网络结构比较
SSD算法采用了VGG16(一种深度卷积神经网络)前面的5层网络,然后利用atrous算法将fc6和fc7层转化成两个卷积层,另外再增加了3个卷积层和一个均值池化层,不同层次的feature map分别用于defaultbox(缺省窗口)的偏移和不同类别的预测,最终通过非极大值抑制方法得到最终的检测结果。
在训练策略上,SSD首先找到每个groundtruthbox(人工标注窗口)对应的default box中IOU大于0.5的default box作为正样本,剩余的作为负样本,因此一个groundtruth照片可能对应多个正样本。下面公式是训练目标函数,其中N表示正样本数目。
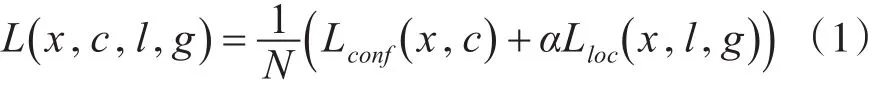
Defaultbox在不同层的feature map下生成的,所以对不同尺度的物体检测效果都比较好。用于预测的feature map上的每个点都对应有6个不同的default box,显然会导致正负样本不平衡,在训练过程中,采用了Hard Negative Mining的策略(根据confidence loss对所有的box进行排序,使正负例的比例保持在1:3来平衡正负样本的比率。
SSD官方在Github上面公开了代码,且提供了基于PASCAL VOC2007、VOC2012和COCO数据集的Caffe深度学习框架下训练好的模型文件,这里可以直接利用模型文件做网络前向运算,得到无人机对象的位置信息。
3.4 无人机分类方法
上述已介绍了常用无人机分类方法,为了满足识别系统的实时性和准确性要求,本文采用深度神经网络方法进行无人机分类。即有两种方法:一种方法是通过深度神经网络提取无人机的深度特征,然后结合线性分类器;另一种方法是采用已经训练好的模型进行Fine-tuning,直接进行端到端的预测。
1)基于ResNet(残差网络)和KNN的无人机分类方法
传统的CNN在网络层数增加后会出现“梯度消失”问题,网络参数无法更新,性能趋于饱和甚至下降,这会使得深度网络的训练变得十分困难。
ResNet提出了残差学习的概念,优化目标从原来的拟合输出变成了输出和输入的差。如图8所示,残差网络的结构块中,一共有两层,第一层对输入x做一次前向运算,然后通过一个shortcut和第二个Relu层一起获得输出。实验表明,残差网络能够训练更加深的网络,有利于提取更高层次的特征,因此采用ResNet提取无人机的深度特征是非常合适的。
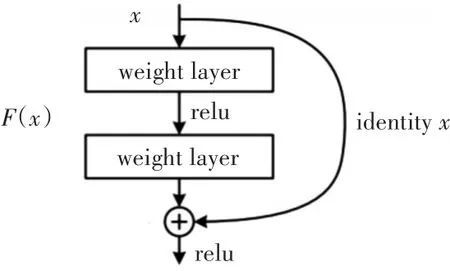
图8 ResNet网络结构块
提取深度网络特征后,采用KNN算法对提取到的特征进行分类。KNN核心思想是:如果一个样本在特征空间中的K个最相邻的样本中大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
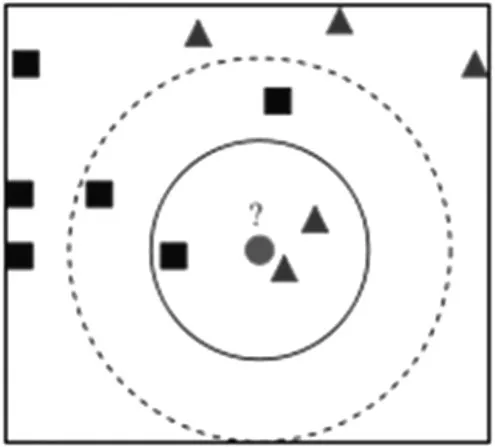
图9 KNN示意图
KNN是一种惰性分类算法,随着训练数据的输入逐步训练,如图9所示,如果要判断圆形是哪一类,根据K值的取值不同得到的结果也不一样,当K=3,圆形被赋予三角形的类,当K=5,圆形被赋予四方形类,KNN训练过程就是要确定最佳K值。在KNN的训练过程中,通过不断尝试K值,统计分类准确率,选择最佳最终确定最佳的K值。
在KNN中,通过计算对象的距离来衡量各个对象的相似性指标,一般使用马氏距离或曼哈顿距离,如下列公式所示。
欧式距离:
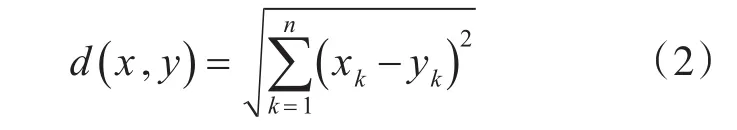
曼哈顿距离:
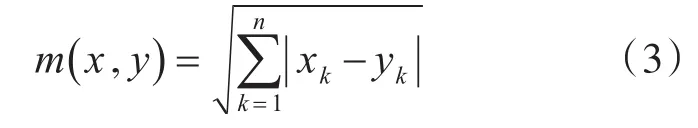
2)基于AlexNet的无人机分类方法
AlexNet是在2012年ImageNet竞赛冠军获得者Hinton和他的学生设计的。AlexNet由5个卷积层加上3个全连接层构成,参数个数为60M,神经元个数650K,分类数目为1000类,图10所示为AlexNet结构图。由于无人机样本数量有限,且缺少大量的标注数据,因此这里选择采用AlexNet在ImageNet数据集训练好的模型进行Fine-tuning,保留前面的5个卷积层,将后面的3个全连接层的output参数分别修改为1024,512,5。
3.5 抓帧和推流
抓帧和推流使用的都是视频处理工具JavaCV,该工具将FFmpeg和OpenCV用Java进行了封装,几乎FFmpeg所有功能都能使用,主要通过JNI的形式调用FFmpeg的服务。
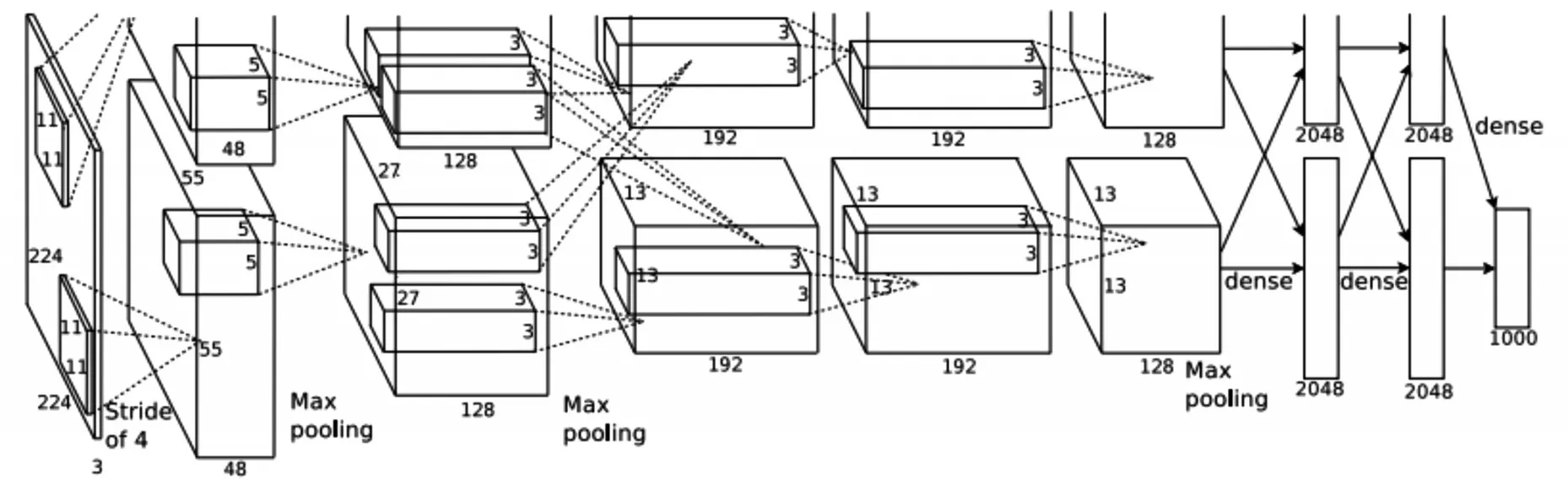
图10 AlexNet结构图
FFmpegFrameGrabber工具用来抓帧,其原理是FFmpeg在后台启动一个线程,不断地从视频源中抓取图像数据,然后推到缓冲队列中。该工具支持多种视频流格式,包括RTSP、RTMP以及主流格式的视频文件等。FFmpegFrameRecorder工具用来推流,该工具支持推送RTMP和RTP的视频直播流,也可以将视频帧录制成离线视频,这就需要在调用前配置bitrate、fps及编码格式等即可。
4 实验结果与分析
4.1 数据集
数据集获取:利用Python爬虫从互联网上爬取无人机照片,然后进行数据清洗和手动分类,标注无人机的种类。无人机可分为五类:固定翼、四旋翼、六旋翼、八旋翼和直升机。数据集分布如表1所示,训练集共有1366张图片,测试集共有339张图片。

表1 无人机数据集分布
4.2 实验结果
采用了两种方法对无人机进行分类,一种方法是将无人机送入到ResNet网络中提取1000维无人机的深度特征,然后利用KNN训练合理的K值,得到最终的分类结果;另一种方法对AlextNet训练好的模型做Fine-tuning(微调),将AlexNet的最后三层参数的输入卷积核的个数做些修改,修改后求解网络,修改后的AlexNet的网络结构如表2所示。

表2 修改后的AlexNet网络结构
1)基于ResNet和KNN的无人机分类结果
利用ResNet在VOC和COCO训练集上的模型提取深度特征,训练KNN分类器,得到最终分类结果,如下表所示。当K取5时准确率较高,可以达到79%。
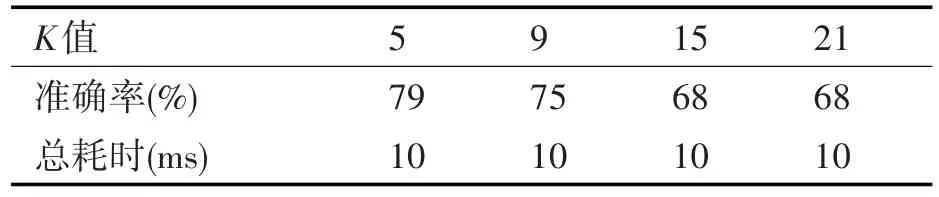
表3 ResNet+KNN分类结果
2)基于AlexNet的无人机分类结果
经过Fine-tuning的AlexNet网络模型训练耗时大概花费6h,网络收敛较快,迭代到第79代时达到了最高准确率83.75%,准确率曲线如图1所示,略优于官方提供的AlexNet数据模型(top 1-5的准确率达到80.2%)的准确率。
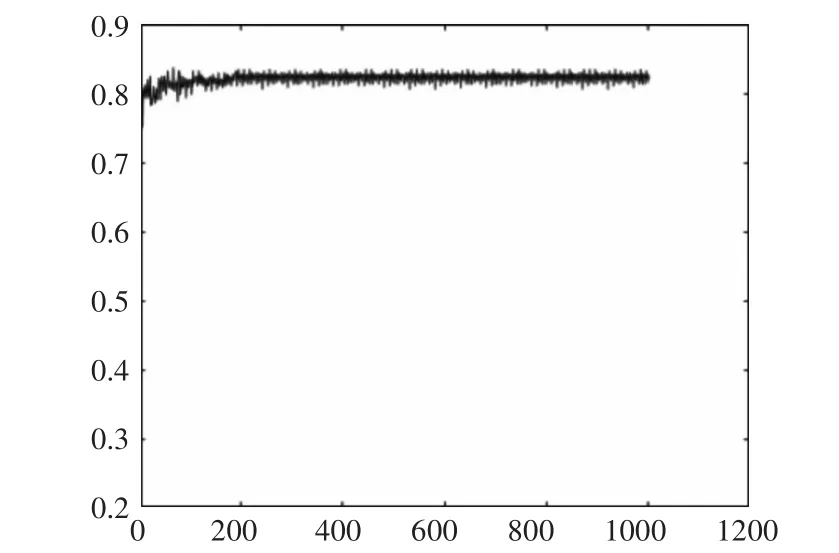
图11 AlexNetFine-tuning过程迭代准确率曲线
4.3 结果分析
上述两种方法都能实现实时无人机识别,且准确率方面第二种方法优于第一种方法。无人机识别效果如图12所示,本无人机识别系统能够实时对视频文件或摄像头拍摄的视频流进行无人机识别,并且实时对无人机类别和相似度做出标记。

图12 无人机识别效果图
5 结语
针对图像中无人机目标的快速检测和识别问题,本文提出了两种基于SSD算法的实时无人机识别方法,设计并实现了一套实时无人机识别系统,即能够实时检测无人机的位置、识别无人机的种类;最高识别准确率达到83.75%,略优于官方提供的AlexNet数据模型的准确率80.2%,识别速度也基本满足实时性要求;该系统已应用到实际项目中。由于无人机的有效标记数据非常少,不同视角观测的无人机差异非常大,导致无人机在真实应用场景下的识别率比较低,难以有效区分无人机种类。所以下一步工作是收集更多不同视角的无人机数据以及改进识别模型,进一步提高无人机识别准确率。
