关于命名实体识别的生成式对抗网络的研究
2019-06-06冯建周马祥聪刘亚坤宋沙沙
冯建周,马祥聪,刘亚坤,宋沙沙
(燕山大学 信息科学与工程学院,河北 秦皇岛 066004) (燕山大学 河北省软件工程重点实验室,河北 秦皇岛 066004)
1 引 言
互联网的快速发展使网络信息呈爆发式增长,同时网络信息的形式也变得越来越多样化,这给用户有效利用网络信息资源带来了很大的不便.面对网络信息爆发式增长带来的挑战,信息抽取技术逐渐发展起来.信息抽取是指从大规模的无结构文本中提取出用户真正感兴趣的信息,并以结构化或半结构化的形式存储或输出[1].
信息抽取技术起源于20世纪70年代早期对自然语言处理(Natural Language Processing,NLP)的研究,而后从20世纪80年代中期开始蓬勃发展起来,这得益于消息理解会议(Message Understanding Conference,MUC)1的推动.继MUC之后,自动内容抽取(Automatic Content Extraction,ACE)2评测会议也对信息抽取技术的发展起着关键性的作用.
根据ACE的划分,信息抽取主要包括4个方面的研究:命名实体识别、指代消解、实体关系抽取和事件抽取.其中,命名实体识别(Named Entity Recognition,NER)是这些任务中最关键的部分.这是因为命名实体识别是NLP领域中一些复杂任务(如机器翻译、问答系统、信息检索等)的基础.同时命名实体识别又是实体关系抽取的基础.例如,在机器翻译中,3Stanford Open Information Extraction.https://nlp.stanford.edu/software/openie.html.
4http://blog.heuritech.com/2016/01/20/attention-mechanism/
只有将目标句子中的实体准确地识别出来并知道实体之间的语义关系才能够准确的翻译目标句子.在问答系统中,系统只有从用户的提问中准确地识别出实体类型以及实体之间的关系才能更好地为用户解答.
命名实体识别任务最初是在MUC-6上被提出的,它的主要任务是识别出自然语言文本中的各种短语并加以归类.它有两个关键的任务:一是要识别出文本中是否有命名实体,二是要判断出命名实体具体所指的目标类型.命名实体的领域相关性很强;数量巨大,收录非常困难,没有通用化的字典可供查询;表达形式多样,可能采用缩写等其他变化的方式,影响判别准确率等等,这些都给命名实体识别任务增加了难度.
2 相关工作
命名实体识别是NLP领域中一些复杂任务的基础,因此一直以来都是NLP领域中的研究热点.现有的命名实体识别研究方法有基于规则的方法,基于传统机器学习的方法(又叫统计的方法),以及近年来流行的基于深度学习的方法.
基于规则的方法[2]由于手工构造规则,系统能够达到较好的性能,但构造规则时太依赖于专业领域知识,费时费力且系统的可移植性较差.
基于机器学习的方法中,命名实体识别被看作是序列标注问题,传统的机器学习方法有许多适用于序列标注问题的模型.Borthwick等人[3]利用最大熵马尔科夫模型和额外知识集提高了NER的准确性.Lafferty等人[4]提出条件随机场用于模式识别任务.Zhou等人[5]提出使用四种不同特征来提高隐马尔可夫模型在NER任务上的性能.McCallum A[6]提出使用更丰富,更高阶的马尔科夫模型的特征感应法和维特比法用于NER任务.除了基于有监督的机器学习方法,机器学习的半监督和无监督的学习方法也可以用于NER任务.在NER方面,主要的半监督学习方法是“bootstrapping”方法[7,8].李丽双[9]利用半监督SVM模型与CRF模型进行组合的方法,实现了将多分类器组合与字典匹配运用到命名实体识别中,提高了试验效果.此外,还有一些无监督的开放信息抽取系统,如华盛顿大学的TxtRunner[10]、 ReVerb[11]等系统,斯坦福大学的Stanford OpenIE3等是开放信息抽取中的典型工作.
近年来,随着深度学习算法的普及,很多学者开始将深度学习算法应用在NER领域,而且已经取得了卓越的效果.Athavale V[12]提出的BiLSTM模型采用了双向长短时记忆(Bi-Long-Short-Term Memory,BiLSTM)网络,通过BiLSTM网络将上下文结合起来,进行NER的训练,取得了良好的效果.Huang Z[13]和Lample G[14]采用BiLSTM与CRF(Conditional random field algorithm)结合的方法,进行命名实体识别的实验,不但能充分利用上下文的信息,又能考虑到句子的语义规则信息,从而取得了比单纯BiLSTM更好的效果.Chiu等人[15]使用BiLSTM+CNN模型来获取更多的特征,在输入层,将词向量和词特征进行结合,然后利用CNN进行特征抽取,最后,通过BiLSTM进行训练,从而提高了效果.Rei等人[16]在RNN-CRF模型结构基础上,重点改进了词向量与字符向量的拼接,采用CRF作为输出层,并以预测的标签作为条件,使用注意力机制(Attention)4将原始的字符向量和词向量拼接改进成权重求和,使用两层传统神经网络隐层来学习Attention的权值,这样就使得模型可以动态地利用词向量和字符向量信息.深度学习的方法在NER领域虽然取得了很好的效果,但是仍然存在很大的改进空间,比如超参数的选择仍然依赖经验,优化过程过早收敛等情况.
2014年,Ian Goodfellow[17]提出了生成式对抗网络,即GAN(Generative Adversarial Networks)模型.最初,GAN模型是用于生成图像这样的连续数据的,并不能直接用来生成离散数据.而当离散数据做微小改变时,在映射空间中也许根本就没有对应意义的序列,所以当GAN处理NLP这种离散数据的任务时,容易出现梯度消失的问题.此外,GAN无法判断目前生成的某一部分序列的质量,因为它只能给生成的完整序列打分.
但是,这些问题近两年已经有所突破.于澜涛等人[18]提出的SeqGAN(Sequence Generative Adversarial Nets)模型,通过执行强化学习中的策略梯度解决了原始GAN在序列标注问题中无法为生成器提供梯度的问题.SeqGAN中的奖励信号仍来自判别器对完整序列的判断,只不过它使用蒙特卡洛搜索返回中间状态的动作步骤来实现为部分序列打分.Arjovsky M[19]提出了WGAN模型来解决NLP领域的梯度消失问题.该论文给出了GAN训练效果不稳定的原因,并利用wassertein距离进行了解决,同时解决了GAN的模式崩溃的问题.Mirza M[20]提出的CGAN模型针对NLP领域以往的GAN不能生成特定属性的问题,进行了相关改进,它将特定属性融入到生成器和判别器当中,从而解决了GAN不能生成特定属性的缺点.Gulrajani I[21]在WGAN的基础之上提出了WGAN-GP,通过采用lipschitz连续性限制的方法,解决了训练梯度消失或者梯度爆炸的问题,同时,提高了收敛速度.
相关研究工作表明,GAN可以在NLP任务上有杰出表现.但在NER方面,GAN还没有相应的研究.因此,本文将CGAN和WGAN-GP两者的优点结合,提出一个适合于命名实体识别任务的条件Wasserstein生成式对抗网络(Conditional Wasserstein Generative Adversarial Nets,CWGAN).
3 基于CWGAN的命名实体识别
命名实体识别任务一般被看做序列标注问题.因此,本文将未标注的句子作为条件,构建CWGAN模型,完成命名实体识别任务.在对抗学习中本文将命名实体识别任务描述如下:给定一个未标注的由一系列单词组成的句子X={x1,x2,…,xn},并以此作为CWGAN模型的条件,生成器模型通过条件生成句子的标注序列,判别器模型给生成的标注序列打分,并为生成器模型提供反馈指导生成器模型训练,最终训练好的生成器模型能够生成质量较高的命名实体标签Y={y1,y2,…,yn},其中xi代表单词,yi代表其对应的生成标签.
3.1 用于命名实体识别的CWGAN模型的设计思路
本小节介绍用于命名实体识别的CWGAN模型的设计思路.如图1所示,模型分为两部分:生成器模型(G)和判别器模型(D).
生成器模型(G)定义了在给定句子的情况下生成该句子对应的命名实体标签序列的策略.本文的生成器模型使用的是一个BiLSTM网络.将句子序列X输入到生成器中(句子序列是未标注的),将未标注的句子作为条件信息,用于生成标注,通过BiLSTM网络得到每个单词的上下文信息表示,通过全连接层以及softmax层得到每个单词在各个命名实体标签上的概率.判别器模型(D)使用的是一个BiLSTM网络.将句子序列X及其对应标注标签序列L(专家预先标注的标签)连接作为正实例输入到D,同时,将句子序列X与G生成的标签序列连接起来作为负实例输入到BiLSTM网络,以专家标注的标签为参照,为生成的标签序列的打分,将每个词的生成标签得分进行求和,返回句子中每个词的标签的总得分,最后句子的得分是句子中每个词的得分的均值.由于得分均值是通过每个词和标注组合的得分加和而来,所以在反向传导过程中,D能针对G每一步的输出进行反馈.D给G的反馈是针对于句子中每个词的,这样做相对于直接对整个标签序列和句子序列进行判别,返回的信息更多,更有助于G的优化.

图1 CWGAN整体框架Fig.1 Whole frame diagram CWGAN
3.2 输入表示
NLP任务中通常要把文本转换成分布式表示,本文采用词向量的方式来表示文本中的单词,使用词向量的目的是将句子中的每个单词映射成K维实值向量.例如,给定一个句子X={x1,x2,…,xn},通过映射词向量矩阵E∈R|V|×dw将每个单词xi表示为dw维实值向量,V是词表的大小(词向量训练语料中的词的数目).
3.3 生成器模型
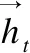
如图2所示,得到单词的上下文表示后,通过一个全连接层并将结果传送给softmax层得到每个单词在各类标签上的条件概率,计算方法如下:
(1)
公式(1)表示在参数θ下,单词xi的标签归为y的概率,其中,nm是标签种类个数,o是全连接层后的输出,其计算方法如下:
(2)
其中,W′代表全连接层的权重矩阵,hi代表单词xi的上下文信息,b′为偏置向量.
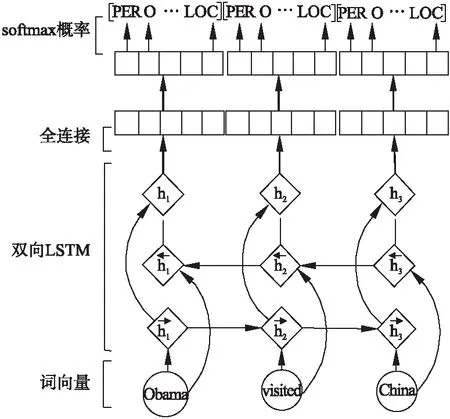
图2 生成器的BiLSTM处理过程Fig.2 Bidirectional LSTM processing of generator
3.4 判别器模型
本文提出的CWGAN模型中的判别器模型也是BiLSTM网络.使用BiLSTM,可以为每个单词的标签单独打分.由于句子的长度是不固定的,通过填充将句子转换为具有固定长度T的序列,该长度是生成器模型的输出设置的最大长度.
判别器的BiLSTM的输入有两种,一种是句子序列x1,…,xT和对应的标注标签序列l1,…,lT的连接[X;L],另一种句子序列x1,…,xT和生成器生成的标签序列y1,…,yT的连接[X;Y](两个句子序列相同,标签不同).其中X,L,Y分别为句子序列矩阵X1:T和生成标签矩阵Y1:T以及标注标签矩阵序列L1:T,它们分别建立为:
X1:T=x1;x2;…;xT
Y1:T=y1;y2;…;yT
L1:T=l1;l2;…;lT
其中,xt,yt,lt是k维词向量表示,分号是连接运算符,且在[X;L]和[X;Y]中为行连接,在X1:T、Y1:T以及L1:T中为列连接,即,若标签序列维度为n1,则连接后的[X;L]和[X;Y]的维度为T×(dw+n1).
(3)

图3 判别器的BiLSTM处理过程Fig.3 Bidirectional LSTM processing of discriminator
3.5 优化目标函数
本文提出的CWGAN模型使用WGAN-GP模型的梯度更新方式,即通过拉近真实样本分布和生成样本分布之间的Wasserstein距离(又叫Earth-Mover,EM距离)来优化目标函数.Wasserstein距离的公式定义如下所示:
(4)
其中,Pr代表真实样本的分布,Pg代表生成器生成样本的分布,∏(Pr,Pg)代表真实样本分布Pr和生成样本分布Pg组合起来的所有可能的联合分布的集合.从每一个可能的联合分布γ中采样得到一个真实样本x和一个生成样本y,即(x,y)~γ,算出这对样本的距离‖x-y‖,然后就可以计算该联合分布γ下样本对距离的期望E(x,y)~γ[‖x-y‖].在所有可能的联合分布中能够对这个期望值取到的下界(公式(5)等号右边),即定义为Wasserstein距离.通过拉近真实样本和生成样本的Wasserstein距离来拉近两个样本的分布,其好处是在两个样本分布无重叠或重叠部分可忽略的情况下,Wasserstein距离仍然可以提供有意义的梯度.
在对抗训练的过程中,判别器的作用是为生成器生成的数据(分布)打分,生成器则根据判别器给出的分数做出微小的调整,然后再将新生成的数据交给判别器打分.所以当输入判别器的样本稍微改变,判别器不能给出与上次样本差距太大的分数,即需要限制判别器打分的变动幅度.对于判别器的这种限制可以通过施加Lipschitz限制实现,如下:
‖f(x1)-f(x2)‖≤K|x1-x2|
(5)
其中K是一个大于等于0的常数,x1和x2是样本空间内的元素.本文的CWGAN模型利用梯度惩罚来实现Lipschitz限制,即额外设置一个损失项:
[‖xD(x)‖p-K]2
(6)
为了使损失项的期望能够进行采样,只在生成样本集区域、真实样本集中区域以及夹在它们中间的区域进行采样.加上以上损失项后判别器损失函数定义如下:
L(D)=-Ex~Pr[D(x)]+Ex~Pg[D(x)]+

(7)

(8)
判别器期望拉大两个分布之间的Wasserstein距离,生成器希望拉近两个分布之间的Wasserstein距离.
生成器的损失函数定义如下:
L(G)=Ex~Pg[D(x)]+cost
(9)
其中,cost代表真实样本与生成样本的交叉熵,计算公式如下:
cost=-[D((l′)log(D(y′))+(1-D(l′))log(1-D(y′))]
(10)
其中,l′代表句子序列和对应的标注标签序列的连接[X;L],y′代表句子序列和生成器生成的标签序列的连接[X;Y].
本模型采用Adam优化算法来优化判别器和生成器的损失函数.为了防止生成器训练时发生梯度爆炸,使用裁剪(clip)的方法限制每次更新后梯度的范围,一旦生成器的梯度超过了设定阈值就对其进行“裁剪”,使其保持在设定阈值范围内.
4 实验结果及分析
为了证明本文提出的CWGAN模型的优越性,本节设置了几组对比实验,通过比较CWGAN模型和BiLSTM模型在不同数据集上实现NER任务时的性能,以及不同设置下CWGAN模型在NER任务中的性能来说明CWGAN模型的效果.另外需要说明的是,本文的CWGAN算法只与基础的BiLSTM模型进行了比较,因为上节提到的BiLSTM+CRF模型、CNN+BiLSTM模型,以及CNN+Attention+BiLSTM模型都是在BiLSTM基础模型上增加新的模块从而改善了性能,本文算法同样可以在输入端和输出端增加相应的模块来改善性能,这里就不再一一进行比较.
4.1 数据集及评估标准
本节实验使用的数据集是CoNLL-2002中的西班牙文数据集和CoNLL-2003中的英文数据集.
CoNLL-2002中NER任务数据集包含了西班牙文数据集和荷兰文数据集.西班牙文数据集是由西班牙的EFE通讯社提供的新闻组成.该数据集标记有四种不同的命名实体类型,分别为:人名(PERSON),地名(LOCATION),组织机构名(ORGANIZATION)以及其他命名实体(MISC),即不属于以上三种实体中的任何一种.该数据集包含了标准的训练集,验证集和测试集.如表1所示.
5https://en.wikipedia.org/wiki/Word2vec
6https://nlp.stanford.edu/projects/glove/
表1 CoNLL-2002 NER任务西班牙文数据集规模表
Table 1 CoNLL-2002 NER Task Spanish dataset scale table
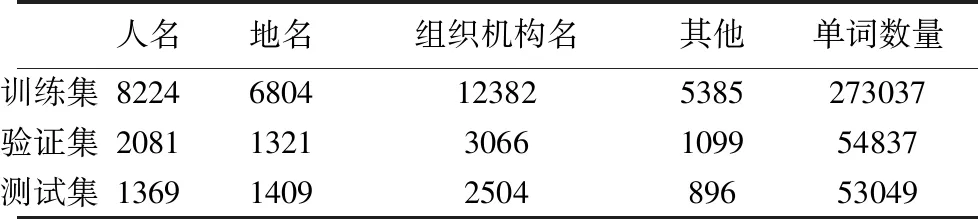
人名地名组织机构名其他单词数量训练集82246804123825385273037验证集208113213066109954837测试集13691409250489653049
CoNLL-2003 NER任务数据集由路透社RCV1语料库的新闻专线组成.它标有四种不同类别的命名实体类型:人名(PERSON),地名(LOCATION),组织机构名(ORGANIZATION)以及其他命名实体(MISC).该数据集包括标准的训练集,验证集和测试集.如表2所示.
表2 CoNLL-2003 NER任务英文数据集规模表
Table 2 CoNLL-2003 NER Task English dataset scale table

人名地名组织机构名其他单词数量训练集111358297100274593204568验证集315020942092126851597测试集27771925249691846667
采用NLP任务中常用的评测指标F-1测度值对实验结果进行评价分析,F-1测度值是对准确率和召回率的一种平均加权,它能够体现整体测试效果.它的计算方法为:
(11)
其中,P代表准确率,P=正确识别的命名实体个数/识别的命名实体总数×100%,R代表召回率,R=正确识别的命名实体个数/数据集中命名实体总数×100%.
4.2 实验设置
1)预训练的词向量.与随机初始化的词向量相比,使用预训练的词向量可以取得更好的效果.
本实验使用了两种预训练的词向量:Word2vec5和GloVe6.GloVe与Word2vec都是基于词共现结构以无监督的方式学习单词的向量表示.不同的是,GloVe是对“词-词”矩阵进行分解从而得到词表示的方法,属于基于矩阵的分布表示,它相比Word2vec充分考虑了词的共现情况.
由于两者都具有比较优秀的准确性,并且这两种词向量是当前使用比较广泛的两种词向量,所以,此次实验采用了这两种方法生成的向量作为实验的输入.本实验中使用300维的实值向量表示单词的词向量,word2vec和GloVe训练词向量时使用的参数如表3所示.
表3 词向量训练参数表
Table 3 Word vector training parameters table

词向量工具词向量维度窗口大小学习率采样阈值Word2vec30030.011e-4GloVe30030.01—
2)参数设置.本文在训练时使用三折交叉验证法调整模型.用网格搜索法来确定最优参数,并指定参数空间子集为:窗口大小w∈{1,2,3…7},过滤器数量n∈{64,128,256,512},生成器梯度裁剪阈值∈{8,9,10,11,12},随机梯度下降学习率λ∈{0.1,0.01,0.001,0.0001},使用 Adam优化器更新参数.本文实验使用的参数如表4所示.
表4 实验参数表
Table 4 Table of experimental parameters

词嵌入维度隐藏层神经元个数窗口大小批大小丢弃率学习率梯度阈值dw=300n=256w=3B=16p=0.5λ=0.000110
4.3 实验对比及分析
本文提出的CWGAN模型与BiLSTM模型[12]的性能进行了对比.表5是BiLSTM与CWGAN的基于西班牙文数据集的对比实验的结果.表6是BiLSTM、CWGAN的基于英文数据集的对比实验结果.CWGAN代表生成器和判别器都使用BiLSTM.由于西班牙用于预训练的数据不充足,导致实验效果不是很好,但是,实验的对比效果并没有因此受到影响.
表5 基于CoNLL-2002的CWGAN模型效果表
Table 5 CWGAN Model base CoNLL-2002 effect table
从表5中可以看出,在对于基于CoNLL-2002的实验上,无论是在验证集Test_a上还是测试集Test_b上,CWGAN模型的F1值都比BiLSTM模型的F1值有所提高.在验证集Test_a上,CWGAN模型比BiLSTM模型提高0.49%;在测试集Test_b上,CWGAN模型比BiLSTM模型提高1.20%.这说明CWGAN模型将生成对抗式网络用于命名实体识别任务是成功的,判别器能够指导生成器学习.
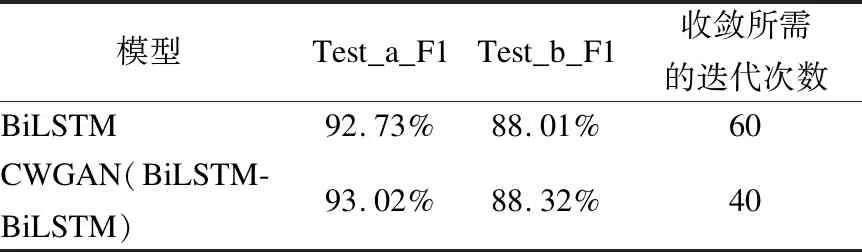
表6 基于CoNLL-2003的CWGAN模型效果表
Table 6 CWGAN Model effect base CoNLL-2003 table
模型Test_a_F1Test_b_F1收敛所需的迭代次数BiLSTM92.73%88.01%60CWGAN(BiLSTM-BiLSTM)93.02%88.32%40
从表6中可以看出,对于基于CoNLL-2003数据集的实验上,无论是在验证集Test_a上还是测试集Test_b上,CWGAN模型的F1值比BiLSTM模型的F1值有所提高.在验证集Test_a上,CWGAN模型比BiLSTM模型提高0.29%;在测试集Test_b上,CWGAN模型比BiLSTM模型提高0.21%.这说明CWGAN模型将生成对抗式网络用于命名实体识别任务是成功的,判别器能够指导生成器学习.
从收敛迭代次数方面比较,CWGAN模型的效果也优于BiLSTM模型,CWGAN模型在迭代40次上下时达到收敛,而BiLSTM模型则需要迭代60次上下.
4.4 预训练词向量和dropout的影响
为了验证预训练的词向量以及dropout对于命名实体识别模型的影响,本小节做了以下对比实验.“dropout”是指在训练的时候,按一定的概率p来对权重层的参数进行随机采样.
表7 基于CoNLL-2003数据集的不同设置下的CWGAN
模型效果对比表
Table 7 CWGAN model effect comparison table under different
Settings base CoNLL-2003 database

模型Test_a_F1Test_b_F1CWGAN84.17%80.45%CWGAN+dropout85.81%81.38%CWGAN+pretrain(word2vec)91.85%86.99%CWGAN+pretrain(GloVe)73.60%69.44%CWGAN+pretrain(word2vec)+dropout93.02%88.32%CWGAN+pretrain(GloVe)+dropout74.62%70.67%
表7显示了使用预训练的词向量和使用随机初始化的词向量的结果对比,表中“dropout”代表训练时设置丢弃率,“pretrain(word2vec)”代表使用word2vec工具预训练的词向量,“pretrain(GloVe)”代表使用GloVe工具预训练的词向量,CWGAN和CWGAN+dropout代表使用随机初始化的词向量.结果显示,使用预训练的word2vec词向量比使用随机初始化的词向量F1值提高了6.99%到7.16%,说明与随机初始化的词向量相比,使用预训练的word2vec词向量可以获得更好的效果.而使用GloVe词向量F1值反而比随机初始化的词向量效果更差了,因此建议预训练词向量时使用word2vec词向量.表7中可以看出,在训练时使用“dropout”比不使用F1值提高了1.17%到1.02%,说明在训练时使用“dropout”可以提高模型的性能,这是因为“dropout”在训练阶段可以阻止神经元的共适应.
5 结 论
本文提出了一个生成式对抗网络模型(CWGAN)用于命名实体识别任务.该网络模型借鉴CGAN以文本描述为条件的图像概率分布的思想,来完成命名实体识别以句子序列为条件获得标注序列概率分布的任务.另外,该模型采用WGAN-GP中的梯度惩罚来保证梯度在后向传播的过程中保持平稳.实验证明,本文提出的CWGAN模型在命名实体识别任务中是有效的,在对抗学习的过程中判别器可以指导生成器进一步提高自己的性能.
