基于YOLO算法的多类目标识别
2019-06-03于秀萍吕淑平陈志韬
于秀萍, 吕淑平, 陈志韬
(哈尔滨工程大学自动化学院,哈尔滨150001)
0 引言
目标识别是计算机视觉领域中的一个新兴的应用方向,也是近年来的研究热点之一。随着中国城市化的进程不断加快,很多城市提出了要建设“智慧城市”,视频监控设备作为智慧城市的眼睛,将在未来发挥重要的作用。人们希望监控设备能够自动捕捉到视频中的异常情况,并能够最大限度降低误报和漏报现象,以最快、最佳的方式发出警报和提供有用信息。这就需要对视频中各种各样的目标进行快速、准确的识别。
早期的目标识别方法大多是利用尺度不变特征变换(Scale-invariant Feature Transform,SIFT)进行物体检测,利用方向梯度直方图(Hist Ogram of Oriented Gradients,HOG)进行行人检测等。例如利用 HOG+LBP特征处理行人遮挡,提高检测准确率[1]。上述方法都是将提取到的特征输入到分类器中来进行识别,本质上是由人手工设计的特征工程。手工设计特征工程存在费时费力,对专业领域知识要求高,泛化性能差等问题。由于卷积神经网络具有优异的特征学习能力,越来越多的研究者开始利用卷积神经网络来完成目标识别任务。
深层的卷积神经网络在不同的视觉识别任务中取得了巨大的成功[2-5]。在多类目标识别任务上,提出了 R-CNN[6]、 SPP-NET[7]、 Fast-RCNN[8]、 Faster-RCNN[9]、SSD[10]、YOLO[11]等多种算法。其中 YOLO是目前识别效果较好的算法之一。
本文以tiny-yolo为基础设计了一个包含15个卷积层的神经网络模型m-yolo,实现多个类别的目标进行识别。改进了tiny-yolo的网络结构,增加了3×3卷积层的数量,并在两个3×3卷积层中间加入了1×1卷积层 NIN[12](Network in Network),使用 voc2007 数据集对改进的效果进行了测试。
1 神经网络模型m-yolo设计
1.1 m-yolo的网络结构设计
tiny-yolo是一种微型的YOLO,仅由9个卷积层和6个最大池化层构成,参数量仅有标准YOLO模型的22%[11]。为了提高识别的准确性和定位的精确性,对tiny-yolo的网络结构进行改进,改进后的模型用myolo表示。m-yolo的网络基于darknet框架实现,包括15个卷积层和6个最大池化层。m-yolo网络的结构如表1所示。
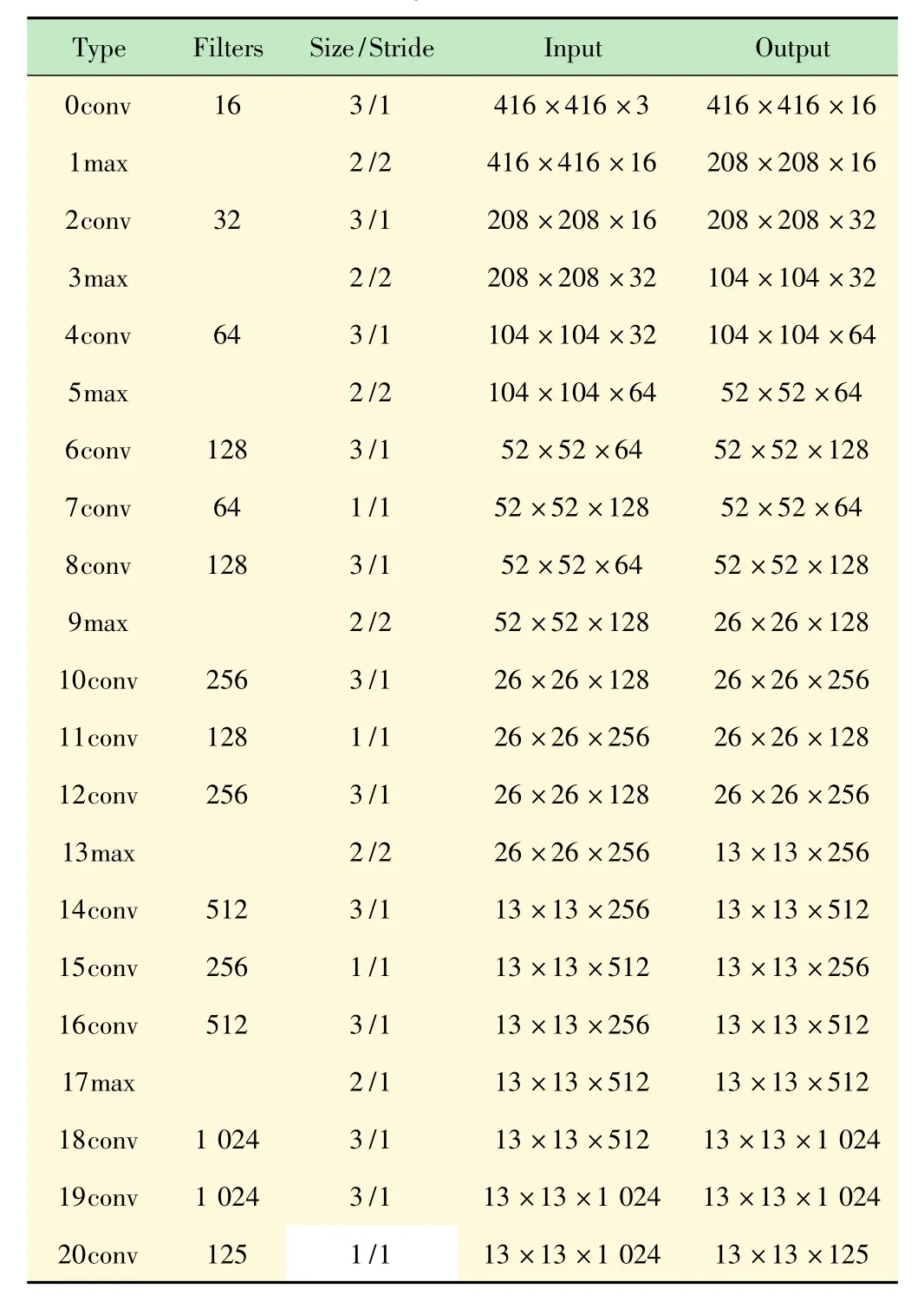
表1 m-yolo的网络结构
所有卷积层的激活函数都设置为Leaky函数:

由表1可以看到,改进后的网络增加了3×3的卷积层,加入3×3的卷积层可以提高特征提取的能力,但是使模型的参数量有所增加。为了保证模型的识别速度,需要让模型小型化,尽量压缩参数量。为此加入了1×1的卷积层。1×1卷积层不会改变输入图像的维度,它的作用是实现多个特征映射的线性组合,压缩或增加通道的数量,实现多通道的信息交互和整合。在3×3的卷积层的中间加入1×1的卷积层起到了降低参数量作用。例如,第8层输入图像的尺寸为52×52,通道数为128,卷积核尺寸为3×3,数量为128。在没有第7层1×1卷积层的情况下,第8层的参数量为128×3×3×128=147 456。加入卷积核数量为64的1×1卷积层之后,总的参数量为1×1×128×643×3×64×128=81 920。参数量降低为原来的55.6%。参数的降低使层与层之间的连接稀疏化,减轻过拟合的同时减少了计算的复杂度,降低了训练的难度。输出层的维度为13×13×5×(20+5)。
1.2 实验数据
使用voc2007和voc2012数据集进行m-yolo网络模型的训练和性能测试。数据集中包含有person,car,bicycle,motorbike,train,bus,cat,dog 等 20 类常见的物体,voc2007中包含了9 963张标注过的图片,一共标注了24 640个物体。voc2012的训练集包含了11 540张图片,一共标注了27 450个物体。
1.3 实验环境
实验在Windows10环境下实现,电脑的CPU型号为Intel(R)Core(TM)i5-7300HQ,GPU型号为NVIDIA GeForce GTX 1050Ti,显存为4 GB,内存8 GB。设置动量常数β为0.9,权值衰减系数为0.000 5,每个batch训练64个样本,采用分段调节学习率的策略,初始学习率为0.001,steps分别设置为100,25 000,35 000,最大迭代次数40 200 次,scales分别设置为10,0.1,0.1。
2 实验结果与分析
2.1 训练结果
实验的loss函数下降散点图如图1、2所示。图1是tiny-yolo模型的loss函数散点图,可以看到迭代40 200次时模型基本收敛,loss约在0.7~1.4之间。图2是m-yolo模型的loss函数散点图,loss约在0.6 ~1.2之间。从收敛情况来看,模型训练比较理想。
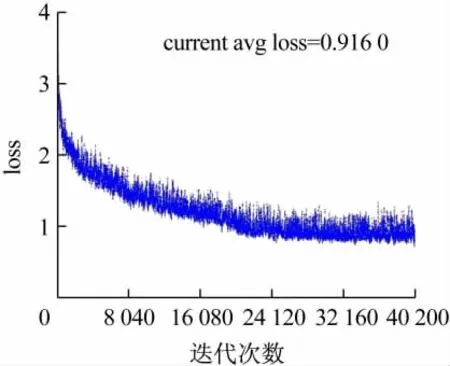
图1 tiny-yolo模型的loss函数散点图

图2 m-yolo模型的loss函数散点图
2.2 m-yolo模型和tiny-yolo模型的性能对比
两种模型在voc2007的20种物体上的识别准确率如表2、3所示。对比表2、3可以发现,m-yolo模型在所有的20类物体上的识别准确率都比tiny-yolo模型要高。提升最多的是对桌子(table)的识别,提高了14.36%。提升最少的是对瓶子(bottle)的识别,提高了 0.55%。
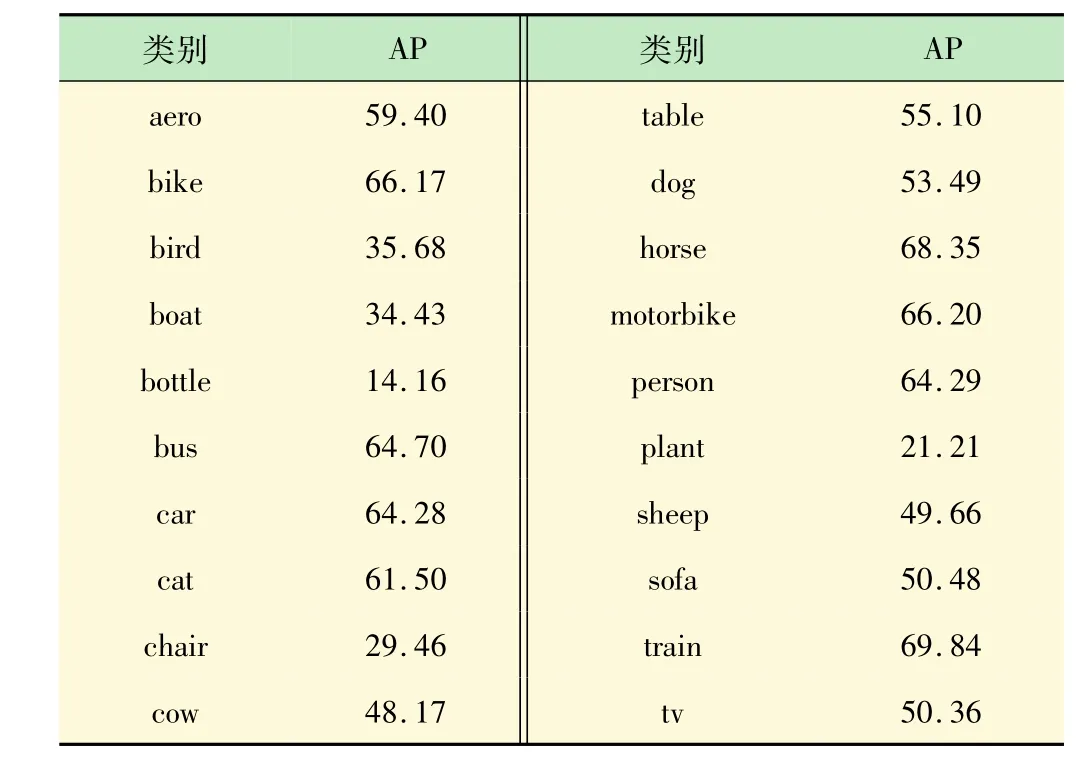
表3 m-yolo模型在voc2007数据集上的测试结果 %
3 讨论
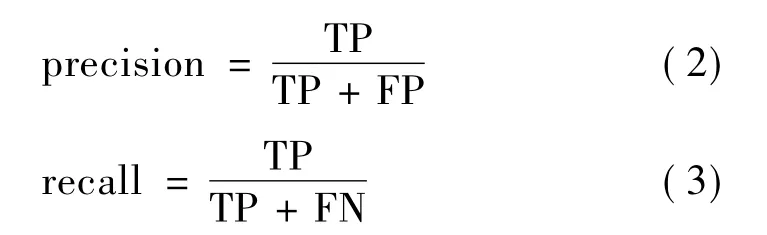
在目标识别中有一些重要的指标:平均准确率(mAP),识别速度,查准率(precision),查全率(recall),平均交并比(avg IOU),平均识别时间(avg time)等。计算预测边界框和实际边界框的交并比IOU。当IOU>0.5定义为真正例;IOU<0.5定义为假正例;IOU=0.5定义为假反例[13-14]。用TP代表真正例,FP代表假正例,FN代表假反例,则查准率和查全率[15]的计算公式为:
计算两个模型的查全率(recall)和查准率(precision),平均识别率(mAP),平均 IOU,平均检测时间等如表4所示。
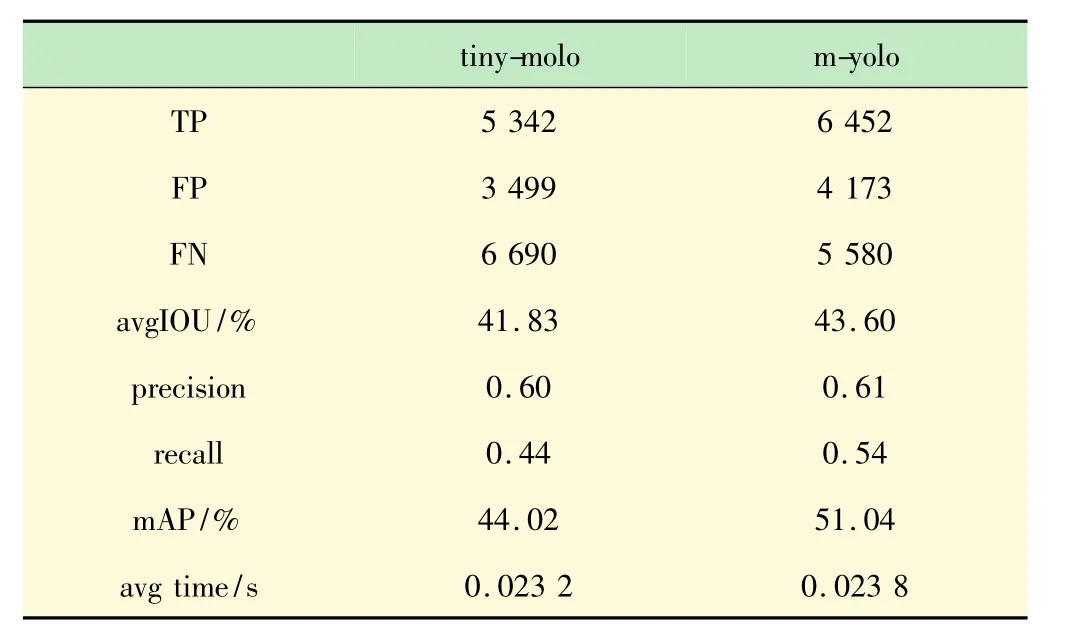
表4 查全率和查准率等指标
从表4可以看出,m-yolo模型的查准率(precision)提高了 0.01,查全率(recall)提高了 0.1。查全率提高的幅度比较大,说明m-yolo模型的漏检的数量明显减少(将正例判成反例,即假反例FN)。myolo模型的 mAP从 tiny-yolo的44.02%提高到了51.04%,平均交并比(avg IOU)从 tiny-yolo 的41.83%提高到了43.60%。在识别速度方面,测试共使用了4 952张图片,tiny-yolo模型识别一张图片平均用时23.2 ms,m-yolo 模型识别一张图片平均用时 23.8 ms。m-yolo的识别时间仅上升了0.6 ms。
实验表明,改进后的模型m-yolo在识别的准确性上,定位的精确性上与tiny-yolo相比均有了明显的提升,同时平均识别时间仅上升了0.6 ms,识别的速度几乎没有下降。说明在m-yolo模型中加入的NIN结构达到了预期的效果,改进的方案有效可行。
4 结语
在tiny-yolo网络结构的基础之上,m-yolo增加了3×3卷积层的数量,并在两个3×3卷积层中间加入了1×1卷积层。实验表明,改进的方法在提高了模型性能的同时,有效的避免了识别时间大幅度的上升。YOLO算法为了提高识别的速度放弃了Region Proposal策略,直接对输入图像划分格子导致对小目标识别效果差,可以尝试找寻更好的方法来代替对输入图像划分格子的方法。目前深度学习仍然处于快速发展的阶段,不断有新的算法提出,所以考虑对网络的结构进行修改和优化也是研究的方向之一。
