一种领域自适应的Web服务分类方法∗
2019-06-01彭密赵恒
彭密 赵恒
(武汉数字工程研究所 武汉 430000)
1 引言
经典的基于机器学习的分类应用过程,通过使用某个领域(源域,Source Domain)的数据集训练模型,再对目标域(Target Domain)分类[1]。该分类方法有效的前提是目标域数据集分布与源数据集分布相似。如果实际应用中目标域数据集与源域数据集的分布差异较大时,分类准确性就会下降[2~3]。针对上述问题,本文结合KNN(K-NearestNeighbor)算法惰性学习的特点[4],设计和实现了一种Web服务分类方法,能够在运行时对输入数据进行筛选复用,使分类结果反馈到下一次分类计算,通过不断累积样本,动态调整源域数据分布,从而达到领域服务自适应分类和提高分类准确性的目的。
2 相关研究工作
2.1 Web服务分类
目前Web服务的实现方式一般有两种,一种基于SOAP的Web服务,采用WSDL结构化文档描述,提供的信息丰富;一种是基于HTTP的轻量级服务,一般被称为Web API,通常没有或者只有简单的描述信息,如REST API,至今没有标准的接口描述文档[5],有研究提出过 WADL[6]等用于基于RESTful的Web API接口描述的规范,但未能推广[7]。现在对RESTful的描述由提供者自已定义,比如ProgrammableWeb网站收录的服务描述就由自然语言短文本组成。
由于轻量级RESTful服务在互联网行业的大规模应用,具有很高的实用价值,因此RESTful的服务分类是现在服务分类研究的热点。目前最常见的分类是根据服务描述文档进行分类,由于部分RESTful服务使用简单文本描述,因此,这一类RESTful服务分类问题,通常直接转化为简单文本分类问题处理。
2.2 基于机器学习的文本分类算法比较
目前常用的基于机器学习的文本分类算法有朴素贝叶斯、SVM(Support Vector Machine)和KNN算法等[8]。这三种经典的分类算法各自具有不同的特点,如表1。

表1 三种算法的优缺点
由于基于KNN的文本算法基于实例分类的特点使基于样本的自适应更易实现,所以本文的研究基于KNN进行。
2.3 KNN算法
KNN算法基于距离相似度分类。KNN算法过程如下:首先,对于一个待分类文本,计算其与已标记实例数据集中每个文本的距离,找出K个距离最近的已标记训练文本,然后在这个基础上对每一个待分类文本投票;投票过程为,有K个训练文本中,如果属于A类的训练文本最多,就认为分类结果为A类。KNN利用距离/相似度分类的形式化表示为
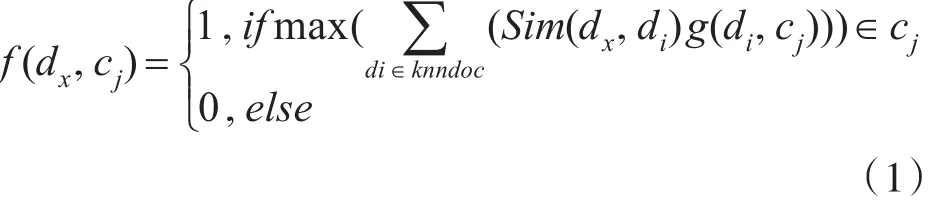
其中c是训练集中的类别,di,Sim(dx,di)为dx和di之间的相似度[10];knndoc是指在训练集K个最相似(近邻)训练文本所组成的训练文本子集;di∈knndoc表示di为训练文本子集中的一个训练文本;g(di,cj)的取值为1或者0,代表di是否属于cj类,当训练文本di属于cj类时取1,否则取0。为如果在dx与最相似的k文本中属于cj类的训练文本最多,则认为dx属于cj类,此时f(dx,cj)等于1,否则不属于,f(dx,cj)等于0。
KNN算法近邻计算方法通常基于空间坐标系的距离计算。现有的KNN距离计算有很多种,常用的有欧式矩离(Eucledian Distance)和曼哈顿距离(Manhattan Distance),余弦相似度(Cosine Similarity)等[11]。
3 自适应Web服务分类方法设计
在KNN算法中,首先将待分类文本dx与训练集所有文本分别计算,计算结果相似度数组使用similarity[]表示,得到相似度排序之后选取其中的K个对应的文本做投票分类[12],如果dx属于cj类,结果表示为f(dx,cj)值为1,否则为0。如果待分类文本与训练集文本词频、词组的差别较大,相似度计算可能不准确,投票也可能不准确。解决方法是在样本上做出反馈和调整:由于KNN采用惰性学习,KNN每一次运行时对目标与测试样本的相似度计算,如果在每一次计算时通过不断对KNN的训练样本调整,可以从样本上实现自适应。
调整训练集的目的是将测试集与训练集的数据分布、特征尽量靠近,这样在分类计算的时候,相似度最高的K个样本就会更准确。
为保证训练集在加入新样本后的准确性,在分类的基础上,需要对加入样本的分类的效果进行评估,评估标准为最大得票数的数量是否大于某个预设值。在dx已分类为cj类的前提下,分类票数为统计cj类得到的票数。di属于K个最相似文本Knndoc中的一个样本,Sim(dx,di)表示dx与di的相似度值;g(di,cj)解释为di如果属于cj类则值为1, 否 则 为 0, 所 以 票 数 表 示 为阈值使用 threshold 表示,如果得票数大于这个阈值,则认为这是一个可复用的样本,此时h(dx)值为1,否则,就不将其作为可复用样本,h(dx)值为0。
由此,本文对普通的基于KNN的文本分类方法进行了改进,通过在KNN分类的基础上,增加数据筛选和复用的过程。在基于式(1)的基础上改进,分类和复用算法形式化表示为式(2):

分类流程如图1分类流程图所示。
未分类服务文本dx作为输入开始,预处理得到此服务文本的词频向量,并与所有训练集文本的词频向量作1∶1相似度计算,得到相似度数组Similarity[];从Similarity数组中找到K个最大的相似度值,并找到这K个相似度所对应的训练服务文本;K个文本中,统计K个文本属于每一个类别的数量,dx的分类为统计量最高的类cj。服务文本dx分类确定以后,判断dx是否满足可复用的条件,条件为dx的分类票数是否大于设定的阈值threshold,如果大于,则可以复用,将dx插入到训练样本集中;否则不可复用。最后无论结果如何,都要输出分类的结果cj,此时分类过程结束。
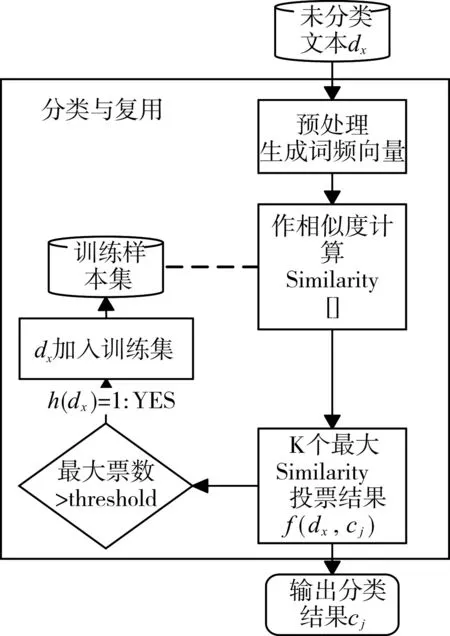
图1 分类流程图
3.1 获取文本间相似度
计算文本间相似度是基于KNN分类的第一步。本文对于文本间相似度的计算采用百度短文本相似度计算处理。所以,调用百度短文本相似度计算接口,将描述服务的两个短文本作为输入,就可以得到返回值为两个短文本的相似度。
基于KNN的分类中,待分类文本需要与训练集中每一项样本数据进行相似度计算,得到一个相似度数组:如果训练集有N个文本样本,就要调用N次接口,得到一个长度为N相似度数组。
3.2 根据文本相似度的投票与分类
待分类数据分别与所有已标记训练集中数据计算后,相似度计算结果分别保存在数组中。投票即从这些保存有相似度的数组中找到K个最大相似度的过程。
具体投票过程如下:假设有已标记训练数据集合为 A∪B ,有待分类数据集 D;Ai∈A,Bj∈B,dx∈D ;dx分别与 Ai,Bj计算相似度(1≤i≤N,1≤i≤M ,N为A的数据量,M为B的数据量);计算结果存放在数组Similarity[N+M]中。在Similarity[N+M]取出K个最大的相似度形成数组maxSimilarity[K],结合式(1),式中knndoc就是这K个最大值对应的数据组成的集合,也就是maxSimilarity[K]中数据对应的A和B的子集合;knndoc中数据项对应的与 dx的相似度maxSimilarity[K]为式(1)中的 Sim(dx,di);di∈knndoc表示 di为训练文本子集knndoc中的一个训练文本;g(di,ci)的取值为1或者0,当训练文本di属于cj类时取1,否则取0。最后找出这K个最大相似度子集对应的训练文本中属于最多的一个类别,比如maxSimilarity[K]中,对应的训练文本属于A类的数量为a,属于B类的数量为b(a+b=k)。如果a>b,则 dx∈cA表示为dx属于A类,否则dx∈cb,表示dx属于B类。
对于K值的取值方法,本文采用最常用的多次验证求值法[13]。具体为,K取值从1开始取单数,K值不断的增加,比如K分别取1、3、5、7…,验证K取不同值时分类性能,取分类稳定之后的第一个值。
3.3 样本筛选复用
经过投票,确定了具体的分类,随后需要对已分类文本筛选。筛选即选取具有超过设定阈值的测试样本插入到训练样本,所以需要定义阈值。
阈值定义为得票率,得票率超过80%则认为分类是正确的,所以阈值设定为分类得到超过80%的投票。计算分类正确可能性可直接统计票数比率,如分类结果dx∈A,当K取7时,得到的票数分别是A=5,B=2,此时结果得票率为5/7≈71%。
经过得票率计算,如果dx∈A的得票率为71%,结果不符合本文对阈值的定义就不对这种数据进行任何额外操作;而如果当K取7时,得到的票数分别是A=6,B=1,那么得票率为6/7≈85%,超过阈值,则将Ck插入A集合中,形成新的集合,表示为A=AUCk,A的数据量由N变为N+1。
由于训练集A已经更新,在接下来的一次对dx+1的分类计算时,对实例比对的时候,就不再是对原来A中的N个数据进行对比,而是对N+1个数据对比。对数据集D的数据di,(i=1,2…I)进行和上述dx相同的筛选和复用过程为完整的分类过程。
随着 di,i∈[1,I]增量的输入,A集合的数据持续增加。由于目标域数据的扩充,源域A,B分布与目标域D的分布会越来越接近,正确找到的K个最相似的样本可能性更高,投票的正确性就越高,分类的准确率就有可能更高。
4 实验与验证
实验数据以https://www.programmableweb.com/网站上的REST服务描述文本作为数据源。从数据中随机选取了其中的两大类,一共180个不同的服务接口作为数据,其中作为训练集的每一个大类包括60个服务,一共有120个服务;剩下的60个服务作为服务测试集,具体如表2所示。

表2 数据统计列表
通过使用两种不同分类方法在基于以上得到的相似度的情况下对REST服务分类;两种方法分别是基于普通KNN的服务分类和本文提出的自适应KNN服务分类方法。
实验以分类正确率和查全率作为判断依据。预期的结果为相同条件下,采用本文方法的Web服务分类正确率和查全率高于或等于作为对比组的普通服务分类方法。
在正式开始实验之前,应首先找到最优K值,实验中K值由多次验证求值法找到最优K值。测试数据为表2中的数据测试Mapping分类查全率,基于普通KNN算法。选择过程如表3所示。
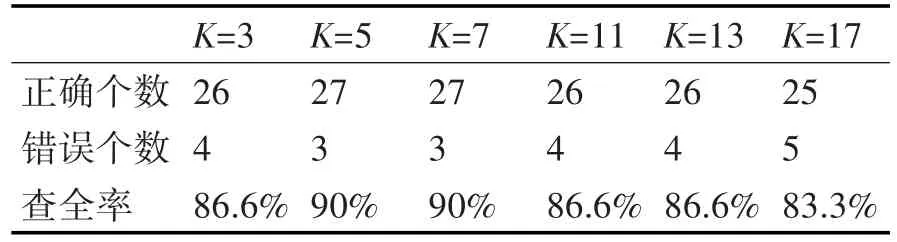
表3 K值与性能统计
根据表3统计结果,K取7时具有稳定的分类效果,所以认为本实验中,K是最优的K值,所以接下来的实验K值取7。
以测试服务集中属于Map类的测试服务“Air-Map Status API”为例,实验具体过程如下。
1)本示例目标是要对AirMap Status API分类,判断是Map服务还是Music服务。
本例中AirMap Status API的服务描述为自然语言短文本形如:The AirMap Pilot REST API allows developers to access and integrate…
2)以AirMap Status API服务为例,把服务文档进行清洗,主要是删除多余符号,比如空格、换行符,标点符号,介词,不标准的符号等。
3)调用百度AI提供的接口(http://ai.baidu.com/tech/nlp/simnet)计算百度相似度,输入为<Air-Map Status API描述文本,测试训练文本 i>,i为训练文本在训练集中的序号。
通过对生成的AirMap词频向量<AirMap,airspace,API,developers,pilots,retrieving,access…>,<4,2,2,2,2,2,1…>与训练集的词频向量作相似度计算。得到的相似度作为返回结果存放在总长度为240的相似度数组Similarity[M+N]中。
4)取出以上相似度数组Similarity[M+N]中,相似度最高的7个(K=7)数据maxSimilarity[K],分别为{0.9614,0.9501,0.9454,0.9012,0.9011,0.8721,0.8620},而相似度与文档分类分别对应的集合为{<19,Map>,<42,Map>,<5,Map>,<17,Map>,<60,Map>,<51,Map>,<94,Music>},所以,根据投票结果,其中6票为Map,1票为Music,根据多数票的结果,AirMap Status API属于Map类。
5)最后判断是否复用:AirMap Status API已经正确分类为Map类,投票数为6:1,根据复用阈值(本文取80%)的计算,6/7>80%,所以将AirMap Status API插入到训练集中的Map类中。
6)此时训练集由原来的120个变为了121个,新增了AirMap Status API服务作为训练集,在下一次的对其他服务的计算中,新的训练集就可能发挥作用。
对本文60个测试服务执行上述2)~5)同样的过程,得到结果如下:
从数据可以看出,本次实验针对的是二分类问题。分类结果只有两种,Mapping类或者Music类。其中Mapping和Music的训练数据各60条,总共120条。而测试数据分别包含Mapping类数据30条和Music数据30条,测试数据总共60条。
结果统计如表4、表5。

表4 普通方法测试结果

表5 本文方法测试结果
对比组为基于普通KNN的服务分类方法,实验组为基于本文方法的服务分类方法。两种方法唯一区别在于本文第3节中提到的投票与分类中,样本筛选复用的过程实现不同。
实验结果表4为基于普通KNN方法的服务分类统计,表5为采用本方法的服务分类统计。通过两表对比,首先是对于Mapping和Music类的平均正确率有所提高,提高大约3%;然后对于这两种类的平均查全率也提高了大约3%。
通过结果来看,针对同样的数据,使用本文方法比使用普通KNN方法分类的准确率更高,两种方法唯一的不同是计算的时候样本集是否变化,如果没有变化,准确率和查全率应该完全一样,显然条件相同的情况下动态调整样本影响到了分类准确率。
本次实验结果符合预期,同时结合本文3.2节中关于领域自适应的分析,本文通过将样本筛选复用,实现了自适应服务分类,达到提高服务分类性能的目的。
5 结语
本文将KNN算法与Web服务分类结合,通过动态复用目标域数据到源域数据集,调整源域数据分布,解决了由于源域和目标域分布差异过大而导致的服务分类准确性下降的问题。本文基于朴素KNN实现,计算复杂度上仍存在改进空间,后续工作可以从减少计算复杂度方面改进:结合G-Tree[14]、V-Tree等优化算法,对词频向量建立搜索树,减少搜索计算量,以改善服务分类计算过多的问题。
