基于特征匹配的恶意代码变种检测∗
2019-06-01齐玉东孙明玮丁海强李程瑜
齐玉东 孙明玮 丁海强 李程瑜
(海军航空大学 烟台 264001)
1 引言
恶意代码分析方法有多种类型,一般地,传统恶意代码分析方法分为基于代码特征的分析方法、基于语义的分析方法、基于代码行为的分析方法三种[1~7]。随着恶意代码与反恶意代码的不断博弈,信息安全技术取得了长足进步,近年来出现的新技术有:
1)客户端蜜罐技术[8]
客户端蜜罐针对客户端软件可能存在的安全薄弱性,通过主动开启客户端软件访问服务器,监控有无异常行为出现,对未知恶意程序进行跟踪分析,进而达到研究学习并保障安全的目的[9]。客户端蜜罐主要针对Web浏览器和E-mail客户端,因此它需要数据源,面临着“如何达到大的网络覆盖面”等一系列问题的挑战。为解决这一点,客户端蜜罐将蜜罐和爬虫(spider)结合在一起,用爬虫爬取网络URL来寻找可能存在的通过客户端软件执行的恶意软件。
2)沙盒过滤技术[10]
在面对混淆加密后的JavaScript代码时,单纯通过关键字搜索来识别恶意网页的办法将会失败,这种情况下的有效办法就是通过内置的HTML以及JavaScript解析引擎在一个虚拟环境中对网页中的JavaScript进行实际解析执行,并在解析执行过程中跟踪JavaScript的代码行为,这种检测方式称为沙盒检测(Sandbox)。该方法理论上的检测正确率很高,但在实现中,检测程序内置的HTML以及JavaScript解析引擎有可能在功能上没有实现完整,或者一些行为与真实浏览器有偏差,而这些偏差却可以被恶意网页的编写者利用以躲避检测程序的跟踪检查。
本文借鉴搜索引擎的文本比较算法[11],应用Hash算法提出了基于特征匹配的恶意代码变种检测算法。该方法是基于恶意代码分析报告的文本特性进行特征匹配,有效地从恶意代码的“本源”进行探究,抓住恶意代码的行为本质,从而实现恶意代码变种检测。另外,利用海明距离和余弦相似度衡量特征匹配程度,根据不同应用设定阈值,利用“双保险”将待测恶意代码行为分析报告和原型库中报告进行特征匹配,实现变种检测目的。
2 算法原理
本文提出的基于特征匹配进行恶意代码变种检测,通过对分析报告与原型库文本比对,实现恶意代码特征匹配。如果直接比较两分析报告的特征词汇,将导致整个分析报告的向量维度过大,而使计算代价过大。为了减少算法的复杂度,本文利用降维思想[12],基于Hash算法将高维的特征向量映射成一个f-bit签名,通过计算两个分析报告f-bit签名的海明距离和余弦相似度来确定动态行为分析报告(恶意代码文本)是否相同或高度相似,进而判断恶意代码的类别,达到检测目的。
2.1 Hash算法
Hash算法[13]中Hash,一般翻译做“散列”,也可直接音译为“哈希”,是将任意长度输入(又叫做预映射,pre-image),通过散列算法,变成固定长度输出,该输出就是Hash散列值。该转换时一种压缩映射,即散列值空间通常远小于输入空间,不同输入可能会散列成相同输出,而不可能从散列值来唯一确定输入值。简单说就是一种将任意长度消息压缩到某一固定长度消息的摘要函数,它把一些不同长度的信息转化成杂乱的一定位编码,这些编码值叫做Hash值。因此使用Hash算法能极大地降低原文本向量维度,进而降低运算代价,提高运算速度[14]。Hash找到了一种数据内容和数据存放地址之间的映射关系。该算法实现原理如图1所示。
2.2 余弦相似度[15]
通过对代码分析报告比对实现恶意代码变种检测,最简单直接的方法是对文本进行分词后进行直接比对。但这种方法缺点十分明显:方法复杂,受到数据稀疏和数据噪声影响太大,运算代价太高,运算速度太慢。将文字比较转化为向量空间信息比较,可在保证准确性的前提下,实现分析报告高效比对。向量空间模型作为向量标识符,是用来表示文本文件的代数模型。向量空间模型中每一维都相当于一个独立词组,每个分词有一个权重,即每个分词的重要程度[16]。因此,本文首先将分析报告中的信息映射成不同Hash值,通过加权求和得到能够表示该文本的特征向量。求该向量与已知原型库文本的余弦相似度,进而判断两文本相似度。余弦值越接近1,就表明夹角越接近0°,也就是两个向量越相似,即“余弦相似性”,其公式为
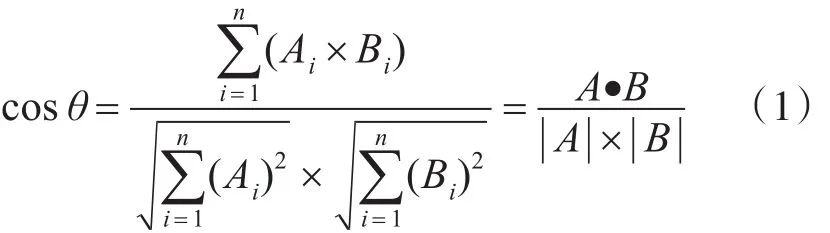
其中,Ai为分析报告的特征向量,Bi为原型库的特征向量。
2.3 海明距离[17]
将分析报告转化为一个向量后,要进行两个向量的相似程度比较。两个向量的相似程度比较要通过对两个向量的海明距离实现。海明距离的数学公式为

其中⊕表示模二加运算,xk={0,1},yk={0,1}。海明距离即两个二进制向量位数的不同个数,例如11001与11110,不同个数为3,即海明距离为3。海明距离反映两个码字在同一位置出现不同符号的次数,为整个分析报告的相似度比较提供了支持。它定量表示两个分析报告的不同程度,一般情况下,认为海明距离小于等于3为相同或高度相似。
以上述三种关键技术为基础,本文的设计思路如图2所示。
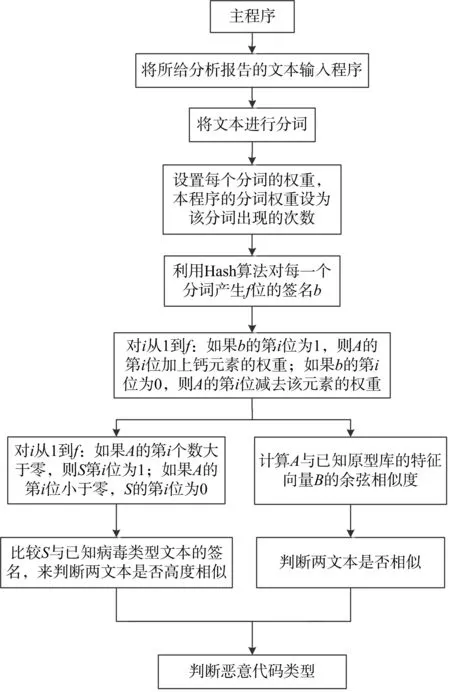
图2 设计思路图
3 算法实现
首先将每一个分词采用Hash算法映射成f维空间的一个向量,映射规则只要求在很多不同特征下对应向量为均匀随机分布,且在相同特征下对应向量唯一;然后将一个文档中包含的各个特征对应的向量加权求和,系数等于该特征权重,权重即该分词出现次数,得到的和向量表示这个文档,最后进行特征匹配。下面进行匹配算法计算阶段。
1)海明距离计算。为提高运行速度,将向量进一步压缩,如果和向量的某一维大于0,则最终签名对应位为1,否则为0。通过一系列步骤后,可得到该报告在整个向量空间的方向信息,省略了在向量空间各个方向的大小信息,这样每个分析报告都能产生一个自己专属的签名,这个签名便能代表这个分析报告。通过对该签名的比较,便可实现目的。
2)余弦相似度计算。将所得的和向量带入计算式(1)进行计算,即可得到该向量与已知原型库文本和向量的余弦相似度。余弦值越接近1,表明夹角越接近0°,相似程度越高;余弦值越接近-1,表明夹角越接近180°,相似程度越低。利用向量相似度反映文本相似度,进而判断恶意代码类型。具体软件实现流程图如图3所示。
若所测恶意代码与某已知恶意代码类型的海明距离小于等于3,同时二者的预先相似度在0.90以上,则说明其为该类型;若海明距离在3~10之间,同时预先相似度在0.5~0.9之间,则说明其为该类型下的恶意代码变种;若未知恶意代码与各已知类型均不贴近(海明距离大于10、余弦相似度小于0.5),说明其为新型恶意代码。
4 实验结果分析
4.1 实验过程
1)实验一
将已知恶意代码产生的分析报告分别导入程序中,统计各类分析报告的海明距离、余弦相似度,验证该方法准确性。其中典型恶意代码包括:Koobface、Bagel、Jessica Worm为蠕虫;九天为后门;Trojan.PSW.QQGame、Trojan.PSW.Misc为 木 马 ;Macro Virus、File Infector Virus为计算机病毒;单片机逻辑炸弹为逻辑炸弹。
2)实验二
将未知恶意代码产生的分析报告分别导入程序中,统计各类分析报告的海明距离、余弦相似度,判断所属类别,检测变种。在实验一的基础上,随机选取5个未知类型的恶意代码进行恶意代码归类及变种检测。
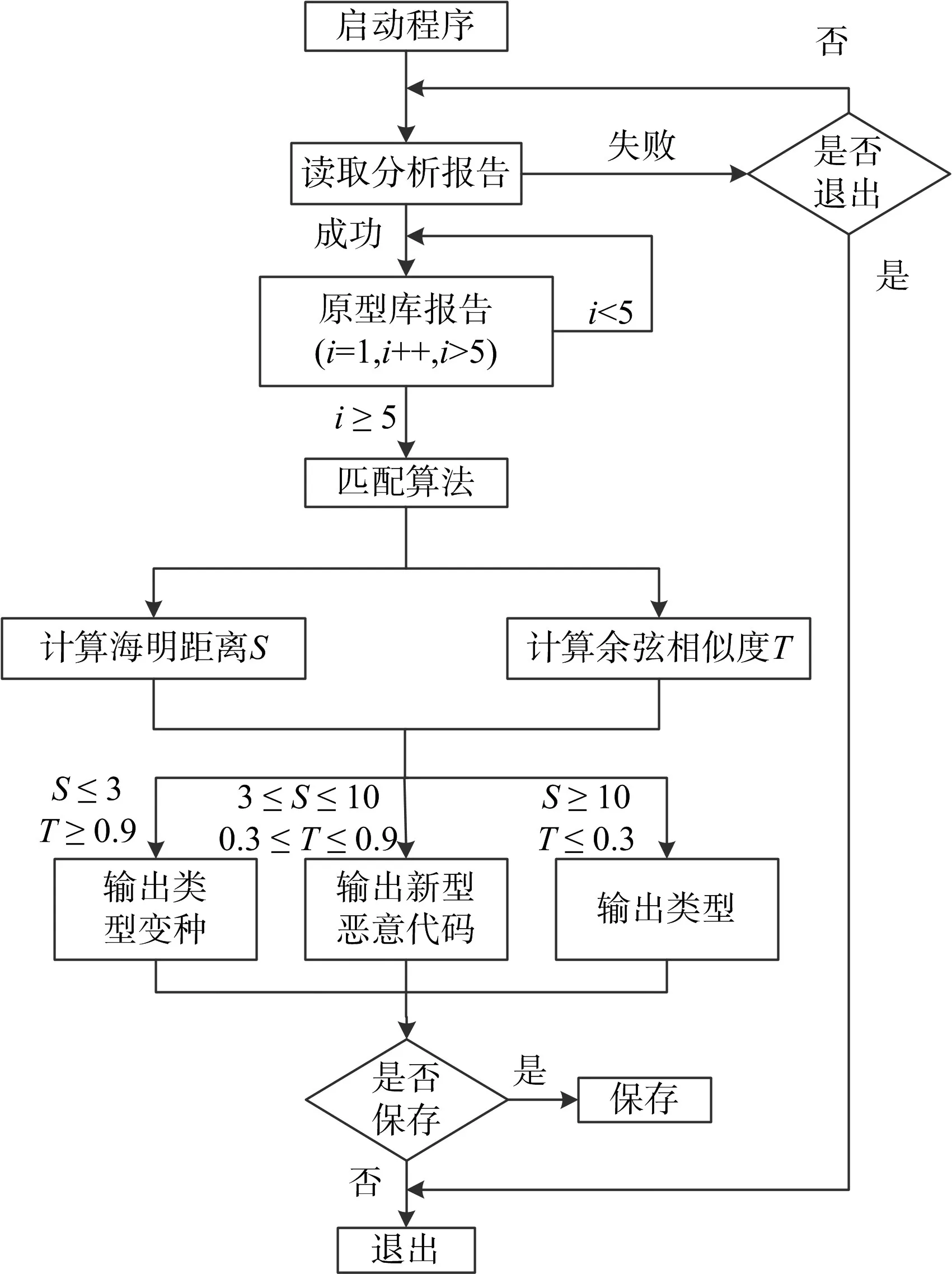
图3 软件流程图
4.2 结果分析
实验一中对已知恶意代码的分析统计:已知典型恶意代码的海明距离计算数据结果如表1所示,已知典型恶意代码的余弦相似度计算数据结果如表2所示。
根据表1、表2数据显示:Koobface、Bagel、Jessica Worm为蠕虫;九天为后门;Trojan.PSW.QQGame、Trojan.PSW.Misc为 木 马 ;Macro Virus、File Infector Virus为计算机病毒;单片机逻辑炸弹为逻辑炸弹。实验结果均正确。
在实验二中,对未知恶意代码的分析并判断类型。未知恶意代码海明距离计算如表3所示。未知恶意代码余弦相似度计算如表4所示。未知恶意代码类型判断如表5所示。
根据表3、表4、表5数据显示:未知恶意代码1、5为蠕虫(其中5为该类型变种);未知恶意代码3为后门;未知恶意代码2为木马;未知恶意代码4为计算机病毒。
通过以上两组实验可以发现,该设计的检测准确率较高,与理论结果相符合。
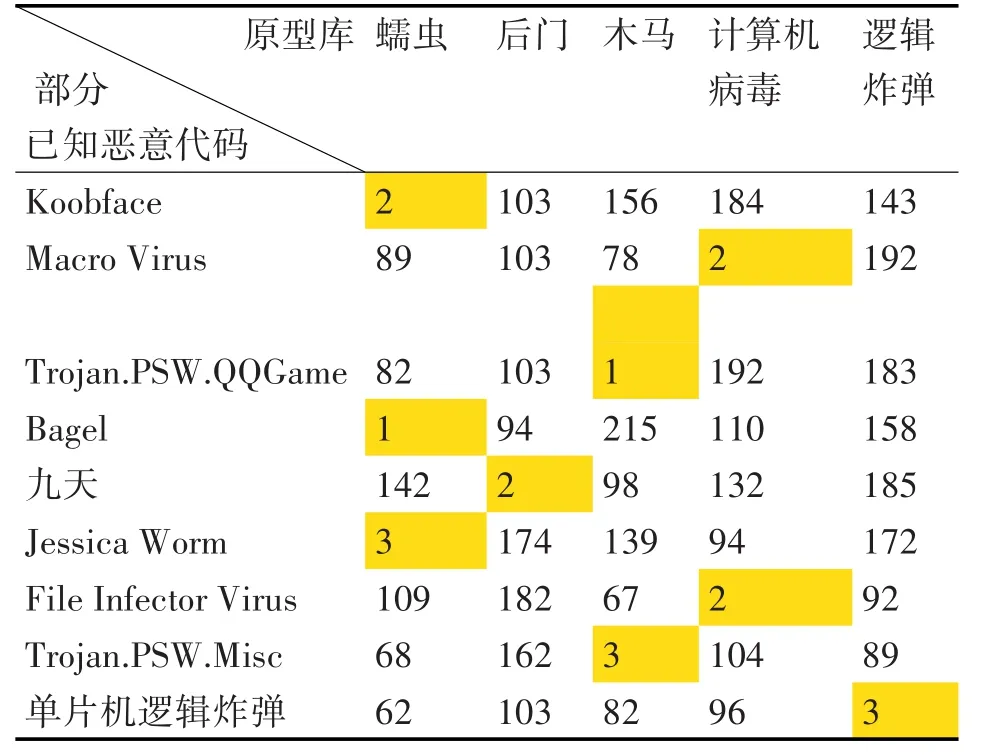
表1 实验一海明距离计算结果
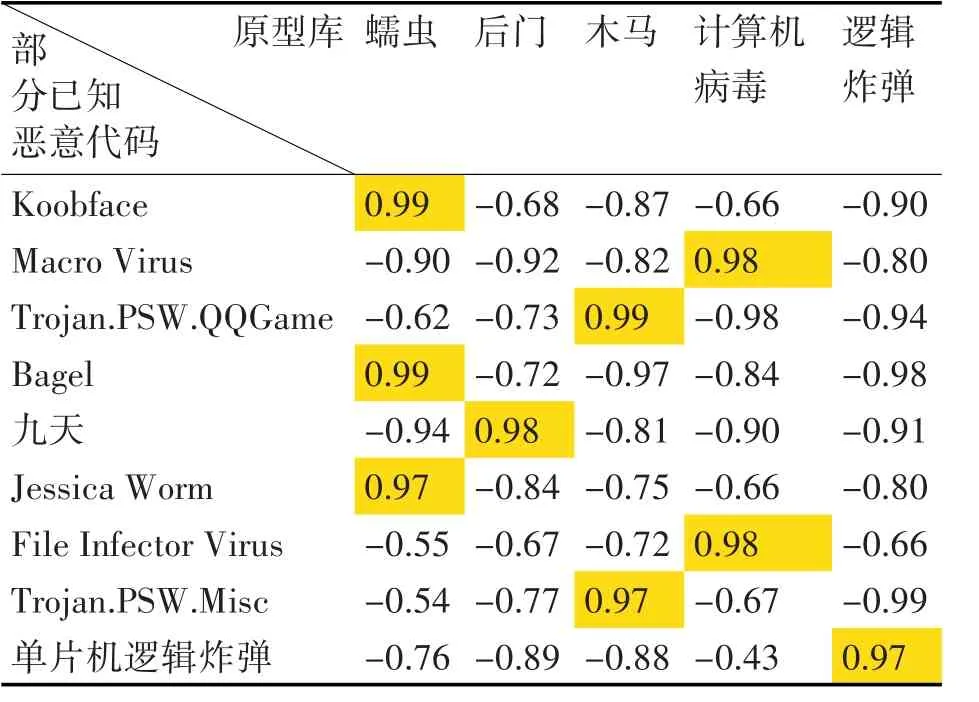
表2 实验一余弦相似度计算结果
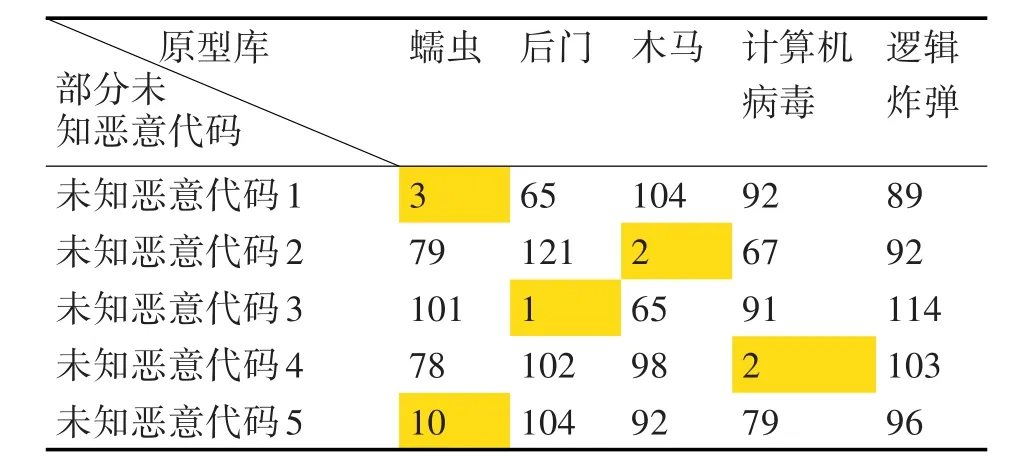
表3 实验二海明距离计算结果

表4 实验二余弦相似度计算结果

表5 实验二恶意代码类型判断
5 结语
本文基于分析报告的文本特征匹配,运用降维思想,以海明距离和余弦相似度为理论依据,实现了对恶意代码的归类及变种检测,可应用于木马防治、病毒免疫和入侵检测等计算机网络安全技术领域。
采用直接比对的工作模式使得本文与恶意代码前期检测软件能进行无缝链接,亦即可成为其他测试软件的结果分析模块,使其应用范围更加广泛;另一方面,直接处理更能体现报告的真实内容,不存在丢失重要信息的可能性,也不会增加冗余信息。
此外,本文采用模块化设计,整体架构灵活多变,可在今后完善工作时新增其他更高效特征匹配衡量方法,在保证程序正确、高效运行的前提下,使得恶意代码的变种检测更加快速、准确。
