PetroV分布式文件系统的设计与实现
2019-05-31盛秀杰金之钧
盛秀杰 金之钧 彭 成 景 妍
(中国石化石油勘探开发研究院,北京 100086)
0 引言
当前大数据技术对互联网行业的发展起着非常重要的推动作用,大数据时代对传统油气能源行业的影响亦不例外。PetroV[1-2]的软件架构设计与研发,需要进一步梳理行业大数据系统的技术体系及演进路线,全方位地重新理解并重构现有软件体系架构和构件,以满足大数据高效存储这一核心架构需求和促进行业内针对性深度学习解决方案的实施。在明确了“PetroV即计算机”的体系架构设计理念的前提下,PetroV重构、升级了可服务于端到端的大数据建模、分析与深度学习策略的体系架构。特别是,在保留支持不同类型专业软件二次开发的软件重用架构特点的基础上,全新设计并实现了基于地理网格剖分和地质信息编码的全新分布式文件系统(PetroV DFS)。
1 地质智能中间件
在考虑大数据4V(Volume,Variety,Velocity,Veracity)特征的前提下,以谷歌为代表的互联网公司提出、发展了系列大数据存储、分析与深度学习技术。在TB、PB、EB直至ZB规模的大数据背景下,利用统计分析、机器学习等算法分析诸如用户行为、社会舆情趋势,挖掘数据潜在的商业价值。2006年,机器学习领域专家Hinton等提出的深度学习为代表的人工智能技术,正以前所未有的速度改变人们的生产、生活和思维方式[3]。考虑大数据存储和深度学习为代表的新技术对油气发现将有重要影响,油气勘探开发行业的专业软件开发应及时紧跟大数据下人工智能技术的发展。
与互联网行业有所区别的是,油气勘探部署的大数据特征表现为5V:从大数据量(Volume)的数字岩心、叠前地震数据、基础地质图件等,到对应的多种结构化、非结构化数据存储机制(Variety),到叠前地震采集、油气田开发等系列新技术带来的快速数据更新(Velocity),到地下地质认识的不确定性对数据质量的影响(Veracity),到油气勘探研究特有的从地震解释、地质编图、油气藏模拟等学科间交叉形成的数据间关联与衍变(Variability)。
1.1 从软件重用到地质智能
在实践不同层次软件架构设计原则和系列设计模式为代表的软件重用技术方面,PetroV做了一些积极的尝试和探索。在延续具有较低耦合性、较高可重用性和可维护性的软件架构特点的基础上,PetroV的架构设计扩展了如何高效存储大数据量的行业核心基础数据,以及如何易于低成本构建大数据(Big Data)、大计算(Big Compute)、大模型(Big Model)下的地质智能(Geological Intelligence,GI)深度学习解决方案(图1)。PetroV的地质智能强调在数量巨大、结构复杂、类型众多的行业地震、测井等基础数据背景下,与基础研究成果充分结合,在高勘探程度层系应用针对性深度学习模型,即从基础数据中挖掘油气特征,整合关联关系,获得识别勘探目标的能力; 利用学习到的认知能力在低勘探程度层系识别新的勘探目标,并与盆地成藏演化与模拟、区带油气藏规模统计、油气藏复杂地质建模等油气定量评价数学模型实现高度耦合,客观、全面地推理模拟或恢复盆地演化、勘探目标形成、油气藏物性条件动态变化等关键地质过程。
1.2 新架构思考与应对策略
在原有本地空间数据库存储基础上,通过增加分布式文件存储层及配套的领域计算服务层,PetroV的新架构体现了“PetroV即计算机”的软件架构设计理念。与传统的高性能计算机部署方案有较大不同,PetroV可被部署于科研人员的非高性能(廉价)计算机上,计算和存储资源的配置对于科研人员而言是透明的,这样可显著降低软件部署的复杂度和成本,并提高资源使用的灵活性。新软件架构思考与应对主要表现在三个方面。

图1 体现地质智能的PetroV新一代中间件架构关键需求

图2 PetroV新版软件架构设计
(1)持久化层:支持本地和远程两级文件系统。该层的设计认为大数据背景下,不存在“一刀切”式的存储机制能够满足所有类型的数据存储需求。如关系型数据库存储技术(Relational Database Management System,RDBMS)在面对大数据量的数字岩心、叠前地震数据时,除元数据层面的有效存储管理外,在数据内容方面并无有效的存储机制与索引技术[4-5]。新一代PetroV的软件架构在已有本地空间数据库存储机制(Spatial Database,SDB)和单一分布式文件存储机制的基础上,面对数字岩心、叠前(后)地震数据及测井等不同类型大数据,进一步统一了元数据建模思路,借鉴谷歌分布式存储技术(Google File System,GFS)[6-7]研发了从全球尺度到单井数字岩心厘米级尺度的、体现地理位置相近、存储位置相近的分布式存储文件系统(PetroV DFS)。
(2)领域层:支持深度学习服务与专业算法服务两级计算框架。该层的设计强调以深度学习服务并行计算框架为基础,开发系列油气勘探开发相关的领域计算、分析或模拟引擎,实现深度学习与专业模型的深层次耦合。开发不同类型的大数据下深度学习和专业算法并行计算框架。其中,面向空间数据库存储强调的是空间统计分析引擎的设计与开发;面向地震和测井以及数字岩心的分布式存储,更多关注批处理计算框架的代码实现,提炼面向地震、测井及数字岩心资料的MAP和REDUCE计算与分析范式,用于大数据下三维场景显示、地震解释和属性分析等。
(3)应用层:支持软件集成的通用二次应用软件开发框架。该层的设计强调借助系列大数据存储和分析引擎以及配套的基础设施二次开发接口,包括GIS图形和分析框架、统计信息可视化框架、三维建模和分析框架等,可快速开发、部署用于大型、分布式、对大量数据进行访问和分析的系列专业软件版本,同时提供容错功能。利用现有的软件架构基础设施,借助油气勘探领域专家及团队的力量和智慧,构建勘探开发专业软件生态系统,通过大数据集成、共享,各个软件版本交叉复用形成智力资源和知识服务能力,全面升级勘探部署规划水平,创新大数据下的勘探部署规划新模式。
2 PetroV DFS设计与关键技术
PetroV DFS核心设计在于其二级存储机制的建立: 基于ST-based KIDA建模技术的本地空间数据库集成,以及基于地理网格和地质信息编码的分布式文件存储(图3)。
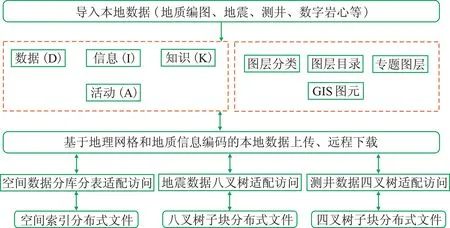
图3 PetroV DFS分布式文件系统架构
2.1 基于ST-based KIDA元数据建模技术的本地空间数据库集成
PetroV的ST-based KIDA建模技术(图3虚线框)包括两部分: ①在关注不同数据类型的本体分类及描述(如用途、数据范围、数据来源、上下文描述、可靠性描述等)的基础上,强调从源数据→信息→知识的衍变过程,突出“活动(A)”作为复合对象可很好地关联其他上下文活动(如构建作业流)以及自身所需三个数据层次的输入、输出; ②在编译(加载、清洗、规则化)不同形态(矢量、栅格、文本等)的行业基础数据的基础上,按区域背景类、沉积类等专业主题组织基础数据,以地理信息系统技术(GIS)的空间图形表征规范,以及图层数据组织模式进行内容呈现。
2.2 基于地理网格剖分和地质信息编码的远程分布式文件存储
急剧增加的井、震文件大小,给相关专业软件系统的研发带来艰巨挑战[8-10]。目前,业内以采用HDFS(Hadoop Distributed File System)存储方案居多。PetroV之所以未采用HDFS存储解决方案,而是强调自主研发,主要有以下几方面考虑:
(1)适宜HDFS存储的对象更多是网页为代表的非结构化明码数据,其文件管理与存储机制没有考虑井震数据的结构化存储特点;
(2)基于HDFS存储的数据分析解决方案,更多适合批处理而不是流模式的实时计算,数据实时访问能力有待提升;
(3)HDFS基于文件目录管理数据子块文件,ZB级子块文件数量形成的深层次目录结构的访问是个性能瓶颈。
对此,PetroV DFS侧重设计一种新的分布式子块数据文件编码机制,高效管理ZB级数量的分布式子块文件; 基于TB级井震数据特点,建立针对性分布式存储机制,实现快速存取(图4)。
2.2.1 全球空间网格编码(Location Code)
在全球范围进行网格划分,把经纬度按照16×16进行分割,形成256个格子,每个格子在下一级中又被分成16×16个格子,依此类推,共形成7级网格,最细一级网格精度达到厘米级。经度范围是-180°~180°,即从西经180°到东经180°;纬度范围与经度范围保持一致,也扩展成-180°~180°(图5)。

图4 PetroV DFS的子块文件编码与转换

图5 全球空间网格划分方案
不同分层下的空间网格需要有唯一空间信息编码。该码第一位和第二位分别是第一层级网格下的经向标识和纬向标识,第三位和第四位是第二层级网格下的经向标识和纬向标识,依此类推。即定位网格编码共14位,奇数位编码为经向编码,偶数位编码为纬向编码,取值范围均为十六进制的0~F。
2.2.2 不同类型地质信息编码(Geological Code)
对于要存储的数据,分配分布式文件时,除了空间网格编码,还需进一步补充其它类型地质信息,形成最终的分布式子块文件对应的文件编码(Data Chunk File Code)。补充地质信息包含多项基础数据地质描述信息,包括方位或形状,数据长度,数据类型等。地震类型的基础数据,编码信息体现的主要是地震测网描述信息;测井类型基础数据包括测井曲线类型、井眼方位、测井深度等描述信息。如增加井眼的方位编码,值为0~F,对应360°分割为16等分后的每一份。
2.2.3 以空间网格为聚簇单元,分配、定位分布式子块文件
将需要进行分布式存储的基础数据,考虑其所在地域位置及地质信息,在它被赋给子块文件编码后,再将其传给分布式服务器。分布式服务器根据编码解译出具体的地理网格信息,然后通过空间网格定位的规则决定数据要存放于哪个空间网格以及要存储的数据要切割成多少子块。同时,利用一致性散列算法,将不同的网格中的数据存储到不同的机器中实现分布式存储。分布式服务器中的地理位置服务维护空间网格相关信息,记录了已有数据的各个网格,并且记录了每个网格中含有哪些数据。其中,每个网格可能含有多个分布式子块文件,每个分布式子块文件中可能含有多组分布式数据,当一组分布式数据大小超过文件容量限制时,一组分布式数据也会进一步切分,分段存到多个分布式子块文件中(图6)。

图6 PetroV DFS的子块文件分配
3 原型验证
PetroV DFS分布式子块文件的内容有键值对存储的测井、八叉树子块存储的地震数据、空间索引存储的地质编图三种种类型。在2017年发表相关研究成果[2]的基础上,本文继续重点阐述基于八叉树切分的子块数据文件的读写过程。地震数据文件的上传,是指将SEGY源文件切分成多份小文件,发送到不同机器上进行存储。子块的参数配置包括最终子块的长宽高、存储节点地址、子块备份数量。通过八叉树切分的算法,可计算出总切分层级数,以及不同子块所包含的数据在源地震文件中的对应位置。各个子块发送到哪个存储节点,在图6中已经约定。读、写地震类数据(动辄几百GB),其读(对应的子块文件合并为SEGY文件)、写(SEGY文件切分成具体子块文件)分布式,速度优化是关键。地震数据体分布式切分与合并的速度有几个优化方向: 将更多的工作交给存储节点而不是本地来做; 尽可能做到顺序读写文件; 降低读写对象切换的频率。
3.1 SEGY到子块文件
将源地震数据预切割成多份中间文件,每份中间文件对应一个存储节点。然后将中间文件传输到对应的存储节点中。如图7左所示,以顺序读源文件、顺序写中间文件的方式来最大限度地减少本地时间耗费,将中间文件传输到存储节点后,本地数据文件的切分就已完成。
(1)确定所需的远程存储节点及对应的本地中间文件。每个地震道数据中包含此道的线号和道号,据此可以得到其位于源数据立方体对应的地震测网的平面位置;地震道在深度方向上按照子块文件的时窗的大小进行分割,分割后的数据分别属于不同的子块,也是每次写入中间文件的最小数据单元。根据最小单元的线号道号以及深度得到其在源数据立方体中的空间位置,从而通过八叉树切分算法计算出此最小单元所属的子块号以及其在子块中的位置,通过子块号获取此最小单元所属的存储节点和对应的中间文件。
(2)快速切分并写入本地中间文件。源地震数据以地震道为单位,每个地震道相当于源立方体高方向上的一整条,每次读取若干个地震道,PetroV默认读取的地震道数为合起来超过100MB的最小的道数量,大小也可由用户通过自己的硬件配置和内存大小做出调整。然后顺序遍历各个存储节点对应的中间文件,将这批地震道数据中属于当前存储节点的数据写入当前中间文件。数据与存储节点的对应关系通过八叉树的切分方法来计算得到。
(3)异步传输本地中间文件,根据图6揭示的存储网格情形,生成子块文件。每个存储节点对应的中间文件生成完毕后,将这些中间文件依次传输到各个存储节点。在存储节点中,对接收到的中间文件,每次顺序读取约100MB数据,大小可配置,数据量具体大小为最小单元加上两个整型数据的整数倍,将数据写入到各个子块中。如图7右所示,遍历此100MB数据,每次读取最小单元的子块号和在子块中的位置,然后将最小单元数据写入到对应的子块文件中。该步骤实现了中间文件的顺序读。

图7 地震数据子块文件切分与存储
3.2 读取子块文件合并为SEGY文件
对于分布式的数据体,可再转换回本地SEGY数据体。如图8所示,其具体流程与生成相反。首先对于各个存储节点,将子块合并回中间文件,然后将中间文件下载到本地,本地再将这些中间文件合并为本地数据体。
(1)写入存储节点对应的中间文件。中间文件生成方法为在存储节点按照源数据体的线、道方向来进行遍历,处理每个地震道时,按照子块的时窗进行分割,得到各个最小单元,最小单元如果属于当前的存储节点,则从对应的子块中读取数据,存到中间文件中。八叉树参数与生成时相同,写入时省略掉子块号和在子块中的位置这两个整型数据。
若有多副本,则只有子块第一次生成所在的存储节点才写这个子块的数据到中间文件,如果存在存储节点掉线的情况,则再从其他副本中获取数据。同时本地端记录下各个子块是从哪些存储节点中获取的,用于后面合并中间文件成为数据体时判断从哪个中间文件中取数据。此步骤做到了中间文件的顺序写,同时减少了本地的工作量。

图8 地震数据合并流程
(2)异步存储节点的中间文件。依次下载,并按照线、道方向来进行遍历,生成各个地震道。每次要从中间文件默认读取总和约100MB数据,大小可以配置,具体大小为生成数据体地震道长度的整数倍。本地遍历和存储节点遍历的方式完全相同,所以合并时所需的数据顺序与中间文件中的数据顺序一致,只是这些数据需要从不同中间文件去获取。为了做到中间文件的顺序读,PetroV遍历中间文件,对每个中间文件,读取属于此100MB的内容,再切换到下一个中间文件进行读取。每次读取的最小单元为子块的高。此步骤实现了源文件的顺序写、中间文件的顺序读。
(3)合并本地文件为SEGY文件。
3.3 代码实现
PetroV的代码实现主要采用C++泛化编程,目的就是希望以最小软件开发代价获得足以与需要多数人精心编写的代码相匹敌的专用性、高度简洁和效率。PetroV DFS的泛化编程始于梳理服务大数据存储与分析的每个算法的模板函数定义,分析调用参数顺序对函数执行的影响; 基于编译时推导不同标签(Tag)类型,分发、调用匹配的算法具体实现; 在算法实现函数中,进一步区分是否有不同的算法策略; 在不同的算法策略中,会调用到具体功能类的实现,这些功能类可以被不同的、且被证明成功的系列远程过程调用(Remote Calling Function,RCF)开源接口替代(图9)。

图9 PetroV DFS泛化接口设计的
3.4 440GB叠前地震数据的切分与合并
本文采用某工区的全方位共反射角道集,进行了多次分布式文件的生成与读写操作,目的在于验证:普通廉价计算机和低带宽网络环境下,相对于单机本地访问SEGY文件,PetroV DFS的网络数据传输时间增加并不明显,但新建的分布式文件对后续系列高计算强度要求的解释算法的支撑,是单机本地文件无法做到的。试验选定的叠前地震道集是通过广义Kirchhoff偏移获取的深度域共成像点道集,大小为440GB,Inline范围是1332~1732,共401条纵测线; Crossline范围是1002~1402,有401条联络测线; 共计160801个CDP点,每个CDP点处为一个1000道的叠前道集,因此总共有160801000道,每道有751个采样点。测试对象是24台2010年购买的服务器(图10),远低于现今主流服务器配置。
经过多次试验,440GB地震文件的分布式存、取稳定。以分布式文件的写入为例,总体时间约为9h40min,包括三步: ①扫描整体道头的时间为5h10min,这是不同类型软件应用SEGY地震数据必须的一步[11-13],后续道头扫描会基于第一次扫描建立的索引文件,在5min内完成所有道头扫描; ②按照八叉树算法切割SEGY文件,形成本地中间文件,异步上传对应存储节点,时间为4h7min; ③每一存储节点最终形成440GB对应的分布式子块文件的时间为21min。
基于PetroV DFS文件系统,PetroV持续开发了系列基于MapReduce编程模型为代表的地震属性分析、储层解释算法,使得普通工作计算机运行大数据量地震解释算法变为可行。同上配置,以新产生的440GB分布式文件为输入,做440GB的全时窗频率振幅属性计算,所需时间仅为2h51min。基于该分布式文件系统,PetroV开发了系列地震解释算法(表1)[14-17]。

图10 PetroV的分布式存储(计算)节点配置

模块名称输 入Map计算Reduce计算输 出切片1个叠后地震数据体、1个属性体按照面元获取整道数据,并计算切片计算时窗内取平均1个切片三角时频分析1个叠后地震数据体按照面元获取整道数据,并运算三角滤波按照面元内CDP序号顺序存放4个属性体和6个切片4个属性体、6个切片瞬时属性1个叠后地震数据体按照面元获取整道数据,并运算瞬时属性按照面元内CDP序号顺序存放1-13个数据体1~13个属性体,索引文件记录输出哪些属性倾角、方位角1个叠后地震数据体按照立方体获取数据体,并运算倾角、方位角按照面元内CDP序号顺序存放2个数据体1个倾角体、1个方位角体α滤波1个叠后地震数据体按照面元获取整道数据,并运算Alpha滤波按照面元内CDP序号顺序存放1个数据体1个叠后地震数据各向异性反演1个360道集按照面元获取360道集,并运算各向异性反演按照面元内CDP序号顺序存放4个数据体1个各向同性属性、2个各向异性属性及1个裂缝发育方向椭圆拟合1个CMP道集、2个速度体按照面元获取CMP道集和速度体,运算椭圆拟合按照面元内CDP序号顺序存放2个数据体1个各向异性属性、1个裂缝发育方向贝叶斯三参数反演3个角度部分叠加数据体、3个弹性参数低频模型体按照面元获取6个数据体,并运算三参数反演按照面元内CDP序号顺序存放3个数据体3个弹性参数反演结果基追踪反演1个叠后地震数据体、1个弹性参数低频模型体按照面元获取2个数据体,并运算基追踪反演按照面元内CDP序号顺序存放2个数据体1个反射系数反演结果、1个波阻抗反演结果页岩物性参数反演3个弹性参数反演体、3个物性参数低频模型体按照面元获取6个数据体,并运算页岩物性参数反演按照面元内CDP序号顺序存放3个数据体3个物性参数反演结果脆性反演3个角度反射系数体、3个弹性参数低频模型体按照面元获取6个数据体,并运算脆性指数反演按照面元内CDP序号顺序存放3个数据体3个弹性参数反演结果相干体1个叠后地震数据体按照立方体获取数据体,并运算相干体按照面元内CDP序号顺序存放1-3个数据体1~3个相干属性曲率1个倾角属性体、1个方位角属性体按照立方体获取数据体,并运算曲率按照面元内CDP序号顺序存放1-10个数据体1~10个曲率属性体角道集1个CMP道集、2个速度体按照面元获取CMP道集和速度体,并运算角道集按照面元内CDP序号顺序存放1个数据体1个角道集时窗属性1个叠后地震数据体、1个速度体按照面元获取数据体,并运算时窗属性按照面元内CDP序号顺序存放1个点1个切片三维地震数据的雕刻与蚀刻1个叠后地震数据体、1个属性体按照面元获取数据体存储各个点和面1个mesh网文件,文件头中记录点和面的个数三维数字岩心的雕刻与蚀刻1个岩心数据体按照面元获取数据体存储各个点和面1个mesh网文件,文件头中记录点和面的个数
4 结论
区别于HDFS为代表的分布式文件系统,PetroV DFS充分考虑测井、地震等行业基础数据存储与应用特点,突出了ZB级文件数量的分布式高效管理和TB级文件大小的分布式低延时读写等关键技术实现,体现地理位置相近、存储位置相近的分布式存储与应用特点:
(1)基于全球地理网格剖分编码和不同类型基础数据的地质信息编码,分布式数据子块文件数量的分配没有上限、文件命名不会有冲突,可快速定位或创建分布式数据子块文件;
(2)设计空间索引子块存储,八叉树切分子块存储、空间键值对子块存储三种存储机制,快速读写大数据量的地质编图与二维数字岩心、三维地震数据和测井数据;
(3)基于ST-Based KIDA元数据建模技术的本地空间数据库集成方案,可实现以自主GIS平台技术为中心的数据集成、以自主分布式大数据存储为中心的数据管理和以解决实际勘探问题为中心的数据分析与挖掘(深度学习解决方案)。
