基于机器学习技术的口令脆弱性评估*
2019-05-31罗华容
罗华容,程 劲
(四川省科学技术信息研究所,四川 成都 610016)
0 引 言
随着互联网技术的不断发展,人们的日常生活不断网络化,资产不断数字化,身份认证逐渐成为保障用户信息安全的基本手段。基于口令的认证起源于20世纪60年代,主要被用于大型机的访问控制。口令因其应用简单有效,在互联网中广泛应用于身份认证。虽然目前已有其他大量用于身份认证的技术[1],如基于Key、基于生物特征指纹、行为认证等技术,但是基于认证成本和使用的便利性、用户的隐私等因素的考虑,越来越多的互联网服务如邮件、即时通信、网上购物等,大多采用了账号及口令的认证方式。
考虑到口令仍然是目前应用最多的身份认证方式,因此对口令的安全评估至关重要。口令脆弱性评估用于量化给定明文口令的强度,主要目的是及时评估网络用户的口令强度并提醒用户设置高安全等级口令,避免弱等级口令带来的安全隐患。口令强度因素包括口令长度、所采用的字符或符号集大小、字符排列顺序等。如果口令强度过低,意味面临的网络安全隐患越大[2]。
科技信息服务是一个重要的服务咨询类产业,必然涉及口令的脆弱性评估和口令的恢复或破解,如科技信息共享平台等都涉及到用户账号登录,因此账号安全是该平台安全的重要部分。口令的脆弱性评估能够根据用户设置的口令和附属信息判断该口令的强度。口令恢复包括操作系统口令恢复、邮箱口令恢复、加密文件口令恢复以及各种网络应用的口令恢复等。口令的脆弱性评估和恢复都属于信息安全服务领域的重要业务[3]。
1 问题描述
口令脆弱性评估是指对口令安全性进行量化评估的技术。给定训练集合S={xi|i=1,…,N},其中N为已有口令集合的数量;xi为第i个口令,其由Li个字符组成。N个口令长度不一定相等,xi=(xi1,xi2,…,xiLi)。每个口令对于新的口令x,有x=(x1,x2,…,xL)。判断x的脆弱性,并将该指标记为y。
考虑到密码口令脆弱性评判与先验知识,可以利用规则或人为判断等,为每个密码口令添加相应的脆弱性指标。因此,原问题变化为:给定口令集合S={(xi,yi)|i=1,…,N},其中N为已有口令集合的数量;xi为第i个口令,其由Li个字符组成;yi为第i个口令的脆弱性度量。N个口令长度不一定相等,xi=(xi1,xi2,…,xiLi)。每个口令对于新的口令x,有x=(x1,x2,…,xL),L为待评估口令的长度。
转换问题变为:给定S的情况下,判断口令x的脆弱性,并将该指标记为y。
针对上述问题,目前多采用基于规则的方法,予以解决,其他还有基于攻击概率的方法[4]和基于各种单模型进行组合的方法[5]。机器学习在大数据分析等领域应用广泛,特别是分类算法。考虑到上述问题的数学描述,可以采用基于机器学习算法中经典的分类算法进行问题求解。
2 相关基础介绍
口令脆弱性评估,或者称为口令强度评估,采用基于机器学习的聚类算法,主要需要文本处理和逻辑回归的相关技术。下面简要给出相关基础知识介绍,具体详细的介绍见参考资料[6-7]。
2.1 文本TF-IDF特征
特征提取是对特征空间降维最常用且有效的一种方法。特征提取的方法根据特征评分函数的不同可分为很多种,TF-IDF是一种最常见的文本特征提取算法,且提取效果相比其他方法好。TF-IDF通常用于衡量文本集中一个字或者一个词语对包含该字或者词语的文本重要程度。TF-IDF实际上是TF与IDF的乘积。TF-IDF的特征提取函数为:

特征项频率TF是指在一个文本中,某个特征项的出现次数和文本中所有特征项的出现总次数的商。特征项可以是字或者词。TF的主要思想是:如果某个特征项在一篇文本中出现的次数较多,则表明该特征项可能会较好地描述了该文本的主要信息,适合用于文本分类等处理。
2.2 逻辑回归模型
对口令强度评估分类,是一种典型的多分类问题。逻辑回归是一种可以用来进行分类的常用统计分析方法,特别是对于高维特征问题,能够得到概率型的预测结果,是一种典型的非线性分类模型。
对于具有n个变量的特征向量x=(x1,x2,…,xn),设条件概率P(Y=1|x)=p为根据观测量相对于某事件发生的概率,则逻辑回归模型可表示为:

其中,g(x)=β0+β1x1+β2x2+…+βnxn,β=(β0,β1,β2,…,βn)为自变量的回归系数。显然,π(x)的值域区间为[0,1],因此可以根据取值估计变量Y=1时发生的概率。对逻辑回归模型的参数进行估计,一般采用极大似然估计,设y是0-1型变量,m个训练样本标签值为{y1,y2,…,ym},于是m个观测值的似然函数为:

对式(3)两边求自然对数,即:
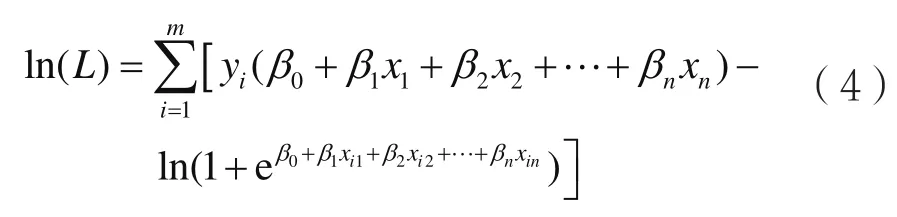
最大似然估计就是选取β0,β1,β2,…,βn的估计值,使得似然值ln(L)的值最大化。对式(4)求导,应用Newton-Raphson方法进行迭代求解,即可获得模型的回归系数。将求得的参数代入式(1),即可建立逻辑回归的分类模型。
3 方案介绍
3.1 方案概述
本方案采用基于机器学习的技术进行口令安全评估,具体采用有监督式的学习算法——逻辑回归算法建立分类模型。整个过程包括模型训练和模型评估两个阶段。模型训练阶段需要收集一定数量的真实口令和对应的口令强度标签,采用文本处理技术对口令进行数值化得到对应的特征向量和标签,采用逻辑回归算法建立分类模型;口令评估阶段对口令的特征向量输入到训练阶段建立的模型中,即可得到模型输出系数,即口令评估的强度信息。
3.2 标签信息获取
监督式学习的一个重要特征是带有标签信息。特征向量可以通过对应的文本处理技术得到,3.4节中将有相应的描述。需要在原始口令的基础上添加对应口令强度的信息,可以基于现有规则给出一部分口令的对应安全强度,以得到其标签信息。
3.3 口令分词
将明文口令进行数值化的重要前提是将口令分词。传统文本处理中,分词技术应用包括英文和中文两大类。英文分词直接以空格符作为分隔符,中文相对简单。口令分词应用与传统分词有区别。口令应用中,一般以字符编码单元进行分割,包括英文、特殊字符等各类字符。考虑到口令使用中的情况,一般口令均由英文大小写字母、数字及特殊字符组成,所以口令中暂不考虑中文字符的情况,即默认口令均为非中文。
3.4 文本特征提取
经过上述分词步骤后,采用常用的文本处理技术TF-IDF技术进行文本数值特征的提取。该特征在文本向量化的基础上进行词频统计,同时乘以逆文档频率。IDF在口令脆弱性评估上具有现实意义,在少的口令中出现,安全性越高。如一些特殊字符,越少出现的被采用,安全性就可能越高。
文本特征提取采用python语言中的scikit-learn库中的TfidfVector()函数实现,整个调用过程比较简单。TF-IDF文本特征实现了文本字符到数值特征的转换,使得可以运用数值特征进行相应机器学习模型的数据输入。
3.5 模型训练
口令明文经过上述过程预处理和TF-IDF处理后,将得到的数值特征向量和对应的标签信息一起作为模型训练的输入。模型采用逻辑回归算法,确定相应的模型参数,包括l2正则项等超参数。逻辑回归算法采用python第三方库scikit-learn实现。为了进行算法验证,采用交叉验证方式,将所有训练样本按0.7:0.3的比例进行随机选择,其中0.7部分作为模型训练使用,其余部分用于模型验证。验证的目的是防止模型训练不充分或者过拟合,得到一组合适的模型系数,从而提高口令评估阶段的性能。经过测试集验证后,准确率较高的模型系数即为对应口令评估模型的系数。将该模型系数进行保存,当口令脆弱性评估阶段需要时,再加载对应的模型系数。
3.6 口令评估
如图1所示,口令评估阶段主要需要三个阶段:分词、TF-IDF和逻辑回归模型分值计算。前两个过程在3.3、3.4已有较详细的描述,逻辑回归分值计算阶段则将经过TF-IDF步骤后的特征向量输入到3.5节中训练好的逻辑回归模型中,然后模型输出即为脆弱性评估值。

图1 基于机器学习的口令评估流程
4 实验及分析
在口令脆弱性评估中,由于用户隐私的原因,不可能收集大量的用户口令,因此官方没有标准的数据样本和公开算法供实验分析,很难做出和他人比较的详细对照。为了验证本文所提方案的可行性,本文设计并实现了所提方案和算法的仿真。
本文收集了1 000多个用户口令,考虑到用户隐私的保护,只采集了口令部分数据,账号只关联到用户名并被匿名化。同时,设计了简单的口令标签标注工作,仅仅设置了3个档,即弱、中、强三档。口令脆弱性评估和该准则对应,也有三个类别,即弱、中、强三个类别。
整个方案采用python语言编程实现,逻辑回归算法调用scikit-learn库中说的分类算法。具体配置如下:测试集划分占训练集总数的20%。逻辑回归分类模型采用多分类模型,同时采用了L2正则项惩罚项。测试验证集整体准确率为89.5%。同时,也给出了一些口令,在线进行口令脆弱性测试,结果如表1所示。

表1 口令测试结果表
表1中评估强度输出列中为三类数值0、1、2,因为模型建立中只采用了三个等级,即弱、中、高,所以模型输出也对应三个等级0、1、2与弱、中、高。从表1可以看出,评估结果比较能符合实际情况,最简单的同一个字母g组成的口令安全强度最低,其他口令强度为1的口令大致相同;而强度等级为2的口令包括一些特殊字符、数字和字母,与实际脆弱性等级比较一致。这一结果表明,基于机器学习技术的口令脆弱性评估方案是合理的。
5 结 语
本文提出一种基于机器学习的口令脆弱性评估方案,将用户口令结合口令先验知识(口令标签化工作)建立模型,目的在于运用成熟的机器学习技术学习已有的先验知识,避免传统靠规则进行安全口令评估的缺点。实验验证了一部分口令评估,说明本文方法能得出较合理的评估值。得到的训练样本越多,标签信息的完善程度越高,越有利于后期口令的脆弱性评估。在条件允许的情况下,收集大量的训练样本,基于相关统计规律的情况下生成新的特征向量,并依据该特征输入进行机器学习模型的训练进行口令脆弱性评估及其他机器学习模型用于脆弱性评估是下一步的研究方向。
