基于K-means的LTE宏站小区场景聚类策略*
2019-05-31张喆
张 喆
(中国移动通信集团设计院有限公司,北京 100080)
0 引 言
随着中国移动近年来LTE网络的大规模建设及不断完善,中国移动全网LTE基站总数已达100多万,4G网络的覆盖优势已经初步建立。然而,庞大的网络规模使得网络优化的难度进一步增加,LTE网络设备中各设备厂家通用配置参数及私有参数总和已超过8 000个,仅依靠人工很难进行精细化配置[1]。此外,以往的人工覆盖场景划分(诸如医院、机场、写字楼等)[2]过于宽泛,未对小区特征进行量化,不能反映各小区间的本质差异,无法实现参数的自动化差异配置,对LTE网络优化工作的开展造成极大的阻碍。
聚类问题是机器学习研究中的热点。先前已有不少关于基站聚类方面的研究探索,但其应用领域主要局限在基站选址与节能方面[3-6]。针对上述问题,本文研究了一套基于K-means的LTE宏站小区场景聚类策略,并在某市试点实验中通过选取可量化小区特征,将该市现网全量宏站小区聚类为若干典型场景,可进一步对各个场景进行网络质量评价以及各场景内部参数最优配置,从而实现对不同聚类场景的小区自动化推荐LTE网络参数配置方案,极大提高网络优化中参数优化配置工作的效率。
1 特征选择
对某个特定对象来说,如何找到最佳的数据表示,这个问题被称为特征工程(Feature Engineering)。要实现LTE小区聚类,首先需要选择可量化的特征对小区进行精细化建模。对于如何选取合适的特征并无严格的规则可循,本文通过对TD-LTE网络优化指导书中网络优化指标进行仔细研究,同时借鉴参数优化实际工作经验,决定从小区工参(本邻区),网络性能,覆盖三个维度中选取若干典型可量化特征用于小区聚类建模,具体见表1。

表1 小区特征选择
2 数据预处理
2.1 数据清洗
进行小区聚类建模所用到的数据,包括工参结构数据,邻区配置数据,MR测量数据,小区TA数据,以及性能指标数据。从数据源提取的原始数据由于各种原因存在数据缺失,数据异常以及数据重复等一系列问题,因此首先需进行数据清洗,否则将会对聚类算法的效果产生不可避免的影响。通过对原始数据进行初步分析后,本文采用的数据清洗方法包括缺失值处理,剔除异常值,以及去重处理等,从而去除掉“脏数据”,确保算法结果的可靠性。
2.2 平均站间距计算
定义:服务小区基站和所有相邻基站距离的平均值。
算法:根据小区经纬度通过两种算法(泰森多边形算法和方向角算法)计算站间距,最终结果使用覆盖距离小的结果。
(1)泰森多边形算法
①根据全网所有小区生成泰森多边形(非所选小区);图1为某市现网全量LTE宏站小区生成的delaunay三角网。
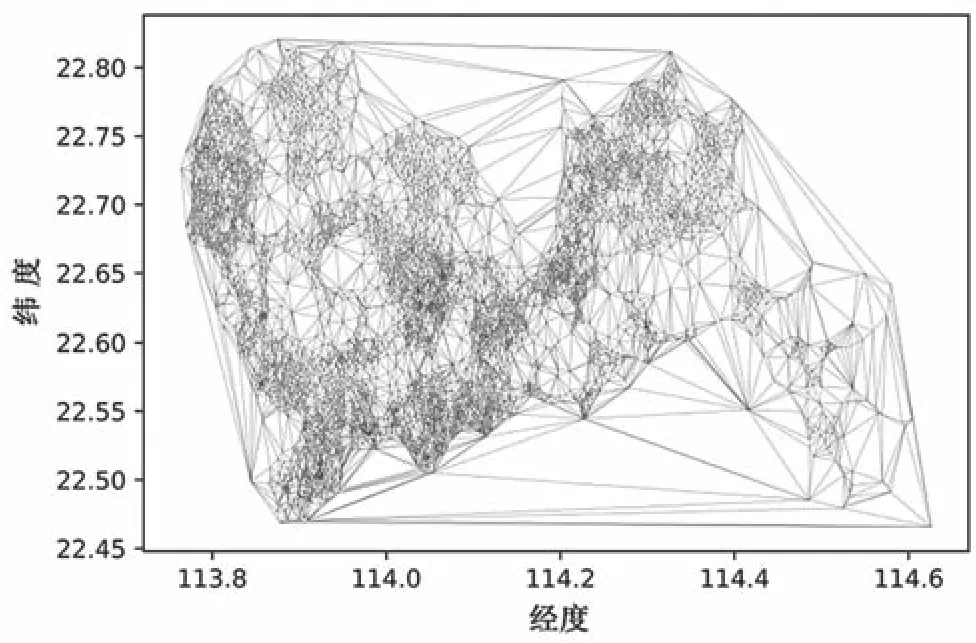
图1 某市现网全量LTE宏站小区delaunay三角网
②根据每个小区泰森多边形,找到它的所有泰森多边形(本网络内)相邻基站;注意:不计算自身基站。相邻概念为:泰森多边形共边;
③计算所有相邻基站到本小区的距离,平均值为本小区站间距(单位使用“米”,使用地球椭球体模型计算距离);
特殊情况处理:室内站不参与计算;小区无相邻基站,定义为“孤小区”,站间距结果为空;
(2)方向角算法
根据小区A方位角与搜索角宽度确认方向,以小区经纬度为圆心,以a为搜索半径,在搜索方向上画弧,如果所得扇区内存在基站X(1个或N个)则将该基站X到A的平均距离计做站间距,如果N>3 那么值取最近的3个纳入计算,如果N<1 那么将搜索半径由a升级到b,依次计算,如果在半径c所画的弧的扇区内仍未发现基站,则站间距计为空。
特殊情况处理:室内站不参与计算;扇形内无基站,定义为“孤小区”,站间距结果为空。
备注:全向站:搜索角宽度使用360度。

表2 站间距-方向角算法
2.3 过覆盖标签计算
从设备厂商网管平台提取的小区TA数据用于判断小区是否出现过覆盖现象,过覆盖判断步骤如下[7-8]:
(1)通过PRS获取小区TA值分布情况,累积由TA0~TA7的每一分段的用户数占比,将每TA分段百分比向后求和,该分段求和值大于90%时,取该分段的最远距离为T1;
(2)根据2.2节中的方法计算平均站间距T2(只计算现网宏站站点之间的平均站间距);
(3)比较T2与T1,如果T1大于1.5倍T2,则判断该小区过覆盖。
如下举例(小区名以XXX代替):XXXFHLH-1在TA分段为区间(1092-2028)时,用户数占比累积大于90%,则此时T1取该分段的距离最大值2 028 m,弱覆盖小区距离最近宏站的平均站间距T2为880 m,由于T1>1.5*T2,故该小区存在过覆盖现象。详见表3。
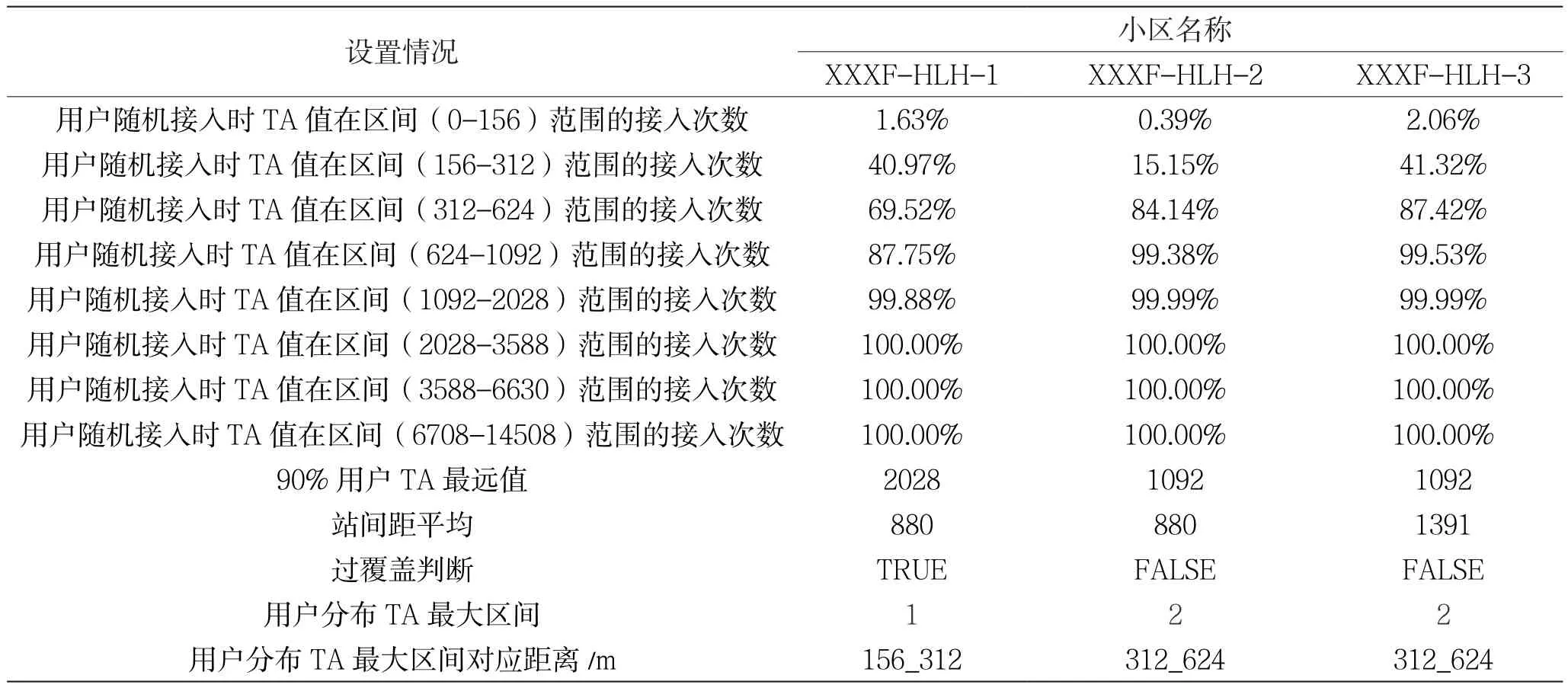
表3 XXX小区过覆盖判断示例
3 LTE宏站小区聚类
3.1 K-means聚类算法
常用的无监督机器学习聚类算法有K-means聚类算法,凝聚聚类算法以及DBSCAN算法,这三种算法均可用于大型的现实世界数据集并实现聚类成多个簇。通过对各种算法的优缺点以及适用场景进行仔细研究分析[9],并结合本次应用场景的实际情况,本文选择最著名的K-means聚类算法实现LTE宏站小区聚类。
K-means聚类算法试图找到代表数据特定区域的簇中心(cluster center),其可以发现k个不同的簇,并将每个簇的中心采用簇中所含值的均值计算而成,具体步骤如下:
(1)随机确定k个初始点的质心。
(2)将数据集中的每一个点分配到一个簇中,即为每一个点找到距其最近的质心,并将其分配给该质心所对应的簇。
(3)每一个簇的质心更新为该簇所有点的平均值。
算法将交替执行(2)、(3)两个步骤,直到簇的分配不再发生变化时算法结束。
3.2 聚类结果
完成数据预处理环节后,每个LTE宏站小区将会被抽象为一个P维特征的向量,从而将该市所有现网宏站小区表示为N*P的特征空间矩阵(N为小区数),实现对LTE小区的量化特征表示。同时为消除各特征之间的量纲影响,需分别对每个特征进行归一化处理,提高聚类算法的精度。
对特征空间矩阵归一化处理后,利用K-means聚类算法将该市现网约4.3万个LTE宏站小区划分为30个聚类场景,各场景的具体聚类情况如表4所示(表中展示了每个场景内各特征的平均值,以及该场景包含的小区数)。
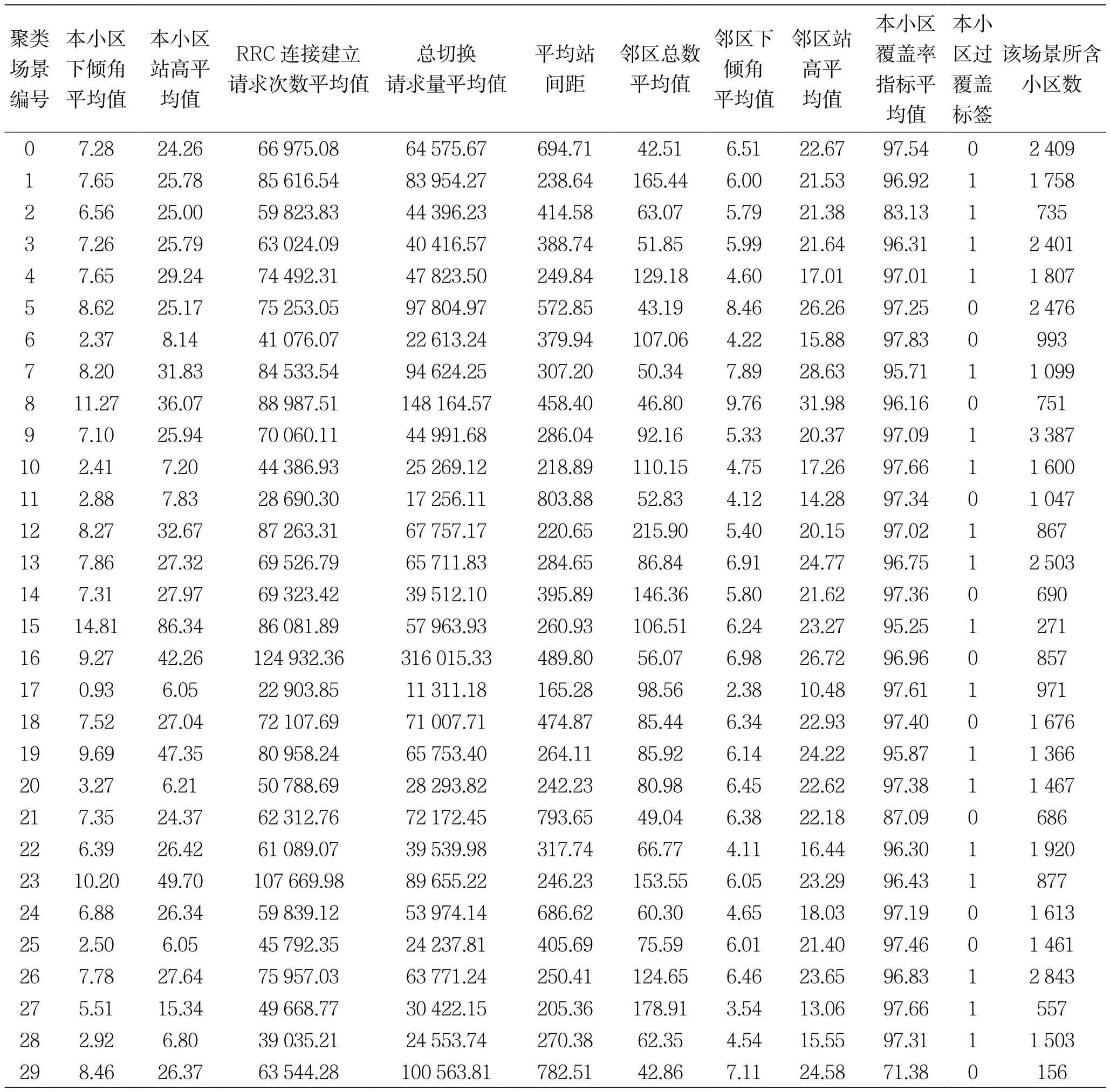
表4 LTE宏站小区聚类结果
3.3 典型场景分析
通过分析比较表4各聚类场景内每个特征的平均值,列举其中典型场景并提供相应的优化建议[10],具体如下:
场景8:本邻区下倾角较大,站高较高,RRC连接建立请求次数及总切换请求量均较高,邻区数较少,无过覆盖现象。该场景属于市区楼宇及人流密集区域(商业中心,CBD等),业务量较高,建议适当降低异频切换A2门限,并检查是否存在邻区漏配现象。
场景17:本邻区下倾角较小,站高较低,RRC连接建立请求次数及总切换请求量均较低,平均站间距较小,存在过覆盖现象。该场景属于市区楼宇及人流密度较为稀疏的区域,业务量较低,建议适当降低小区RS功率,增大本邻区下倾角,并提高异频切换A2门限。
场景29:平均站间距较大,邻区数较少,覆盖率指标较差,无过覆盖现象。该场景的覆盖区域为郊区,建议适当提高小区RS功率,减小本邻区下倾角,对基站稀疏的覆盖薄弱区域增加规划站建设,提高覆盖率指标。
4 t-SNE聚类可视化
4.1 t-SNE流形学习算法
流形学习算法(Manifold Learning Algorithm)自2000年在著名的科学杂志《Science》被首次提出以来,已成为信息科学领域的研究热点。流形学习主要用于高维数据降维及可视化,就是从高维采样数据中恢复低维流形结构,即找到高维空间中的低维流形,并求出相应的嵌入映射,以实现维数约简或者数据可视化。它是从观测到的现象中去寻找事物的本质,找到产生数据的内在规律。
t-SNE是流形学习中一种非线性数据降维与可视化算法,几乎可用于所有高维数据集,广泛应用于图像处理,自然语言处理,基因组数据和语音处理。其主要思想是找到数据的二维表示,尝试让在原始特征空间中距离较近的点更加靠近,相距较远的点更加远离[11]。算法具体步骤如下:
(1)随机邻接嵌入(SNE)通过将数据点之间的高维欧几里得距离转换为表示相似性的条件概率而开始,数据点xi、xj之间的条件概率pj|i由下式给出:
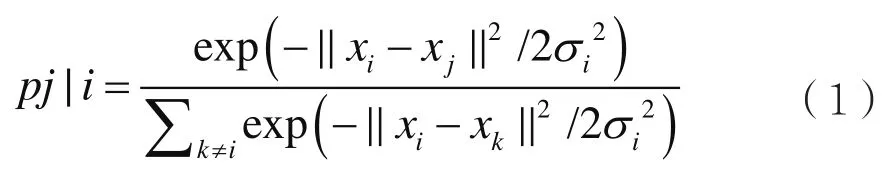
其中,σi是以数据点xi为中心的高斯方差。
(2)对于高维数据点xi和xj的低维对应点yi和yj而言,可以计算类似的条件概率q j|i:
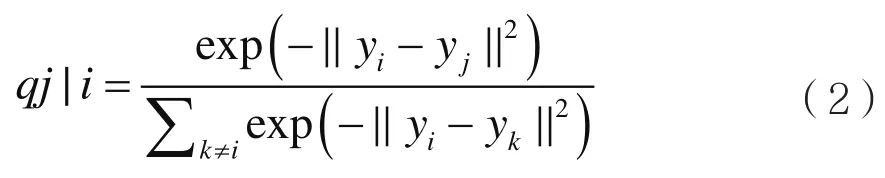
SNE试图最小化条件概率的差异。
(3)为了测量条件概率差的和最小值,SNE使用梯度下降法最小化KL距离。而SNE的代价函数关注于映射中数据的局部结构,优化该函数是非常困难的,而t-SNE采用重尾分布,以减轻拥挤问题和SNE的优化问题。
(4)定义困惑度:

其中,H(Pi)是香农熵:
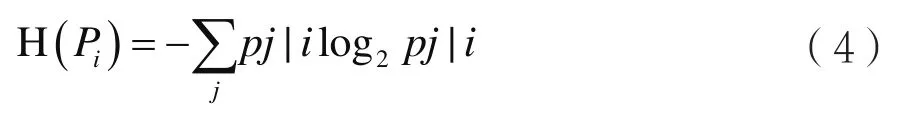
另外需注意,虽然t-SNE对于数据降维及可视化能够取得良好效果,但由于算法计算对应的是条件概率,并试图最小化较高和较低维度的概率差之和,这涉及大量的计算,运行算法时间较长,占用内存较大,对系统资源要求高。
4.2 聚类可视化
利用t-SNE变换将N*P的特征空间矩阵映射至2维空间后,对3.2节的聚类结果进行可视化展示,效果见图2(图中每个数字文本代表该小区所属聚类场景编号)。
从图2中可以看出,通过t-SNE聚类可视化显示K-means聚类算法效果良好,所有类别都被明确的分开,虽然部分类别(诸如聚类6、聚类11、聚类19、聚类28)存在被分隔开的现象,但大多数类别都能形成一个密集的簇。同时也表明本文的聚类算法对LTE宏站小区聚类取得了较为理想的结果。
5 结 语
本文提出的基于K-means的LTE宏站小区场景聚类策略,可对小区进行量化特征建模并聚类为若干典型场景,从而对不同聚类场景的小区可实现自动化推荐LTE网络参数配置方案,极大提高网络优化中参数优化配置工作的效率。后续研究工作可根据算法的实际效果对算法进行优化改进,包括小区覆盖范围的无线环境建模,进一步深入分析能够表征小区间本质差异的可量化特征,以及提高聚类算法和t-SNE算法的运行效率等。
