融合高低层多特征的显著性检测算法
2019-05-29孙君顶李海华
孙君顶, 张 毅, 李海华
(1.河南理工大学 计算机科学与技术学院, 焦作 454000;2. 河南理工大学 物理与电子信息学院, 焦作 454000)
1 引 言
图像显著性检测是计算机视觉研究中非常重要的方向,利用显著性检测提取目标图像的显著图,这对分析目标图像不同区域的显著程度至关重要,是图像处理的基础。目前,图像显著性检测广泛应用于目标定位检测[1]、图像分割[2]、视频压缩等领域。根据人类视觉机制,目前图像显著性检测算法主要分为自顶向下和自底向上的检测算法,自底向上的检测算法不依赖于预定义的任务或先验知识,而是基于目标图像本身的属性(颜色、边缘稀疏等)特征整合图像显著性,而自顶向下的显著性检测算法主要依靠任务或知识驱动进行先验显著性线索检测,其由于高层知识或任务的参加,检测算法较为复杂,检测时间较慢。在自底向上的检测算法中大多采用单一或组合的显著性特征线索表征显著目标,比如文献[3]提出了一种基于区域对比度的方法来对全局显著性进行建模检测;文献[4]提出了一种多尺度超像素显著性检测算法,利用局部对比度、图像完整性和中心偏差3个线索进行图像区域显著性度量;文献[5]根据局部区域背景-主体-背景的相邻颜色差值进行边缘化,提出了一种自适应阈值分割与局部背景线索结合的显著性检测算法;文献[6]结合局部及全局特征提出了一种显著性检测算法;文献[7]综合利用边界、全局和局部信息来提取多种显著性特征,并在随机场下进行融合以实现显著区域的检测;文献[8]综合考虑超像素区块局部对比度、全局对比度以及空间分布关系来计算每个区块的显著值,利用融合结果来检测图像;文献[9]提出了一种应用局部和全局特征对比的显著性检测模型,通过计算颜色和纹理特征的局部对比度得到局部显著图,利用全局、空间分布特性得到全局显著图;文献[10]在高层特征上重新定义了背景先验特征和中心先验特征,在低层特征上使用全局对比度和局部对比度,得到了高质量的显著图。
上述这些算法都是结合高层或底层几种特征来融合得到显著图,并且多采用线性融合策略。而单一或同类几种显著特征无法全面表达图像显著性,显著检测精度普遍不高,针对于此,本文提出了一种融合高低层多种特征的显著性检测算法。
2 底层显著性特征
2.1 边界稀疏性特征
边缘是图像属性与另一属性交界,是图像特征变化的集中区域,也是图像背景与边缘信息连通性最为紧密的地方。图像边界在图像显著性计算中起着至关重要的作用。设检测图像边界区域为字典D=[d1,d2,...dn]∈Rm×n含有n个基础信号,每个信号是m维。稀疏系数χ∈Rn可通过求解L1范数最小化问题:

(1)
上式中‖·‖1表示L1范数,λ1为正则化系数。所以x≈x′=Dχ*,其中x′是x的近似表示。
若使用该边界区域字典D进行重建时误差较小则该区域属于背景区域的可能性大,反之亦然。重建系数χi计算如下:
(2)
则边界稀疏重建误差εi计算如下:
(3)
根据文献[11]可知,图像显著空间遵循一定的规律,距离图像中心越近越能引起观察者的注意,基于此利用分割区域与图像中心点间距离来提取显著特征Tcenter(i):
(4)
(5)
μ=(0.5,0.5)表示图像中心的二维坐标,参数k为位置控制系数,c(i)表示分割区域Ri所有像素坐标中心,Lp表示像素p的空间二维坐标,Ui表示分割区域Ri所有像素个数。
结合以上边界稀疏重建误差εi和图像先验中心理论,则边界稀疏性特征Ti(1):
Ti(1)=εi·Tcenter(i),
(6)
2.2 全局对比度特征
几乎所有显著性检测算法都会利用不同的颜色体系计算颜色对比度,主要利用RGB或Lab两种颜色体系。文献[12]提出了一种利用RGB、Lab两种颜色体系与区域分割相结合的全局对比度特征提取方法。本文借鉴该方法对图像的分割结果{R1,R2,...,RNum}进行区域对比度特征计算:

(7)
ψ(Ri,Rj)=‖Averlab(Ri)-Averlab(Rj)‖+
η‖AverRGB(Ri)-AverRGB(Rj)‖,
(8)
其中:ϖ(Ri,Rj)表示分割区域Ri,Rj间的空间几何距离,ψ(Ri,Rj)表示分割区域Ri,Rj间的空间颜色距离,Averlab(·)和AverRGB(·)为计算平均颜色函数,pf表示像素p的颜色向量。参数η为控制颜色体系RGB、Lab在计算全局对比特征中的比重,本文将η设置为0.5。基于全局对比度特性得到的图像显著性特征图如图1所示。

图1 基于全局对比度的显著性特征图Fig.1 Saliency feature map based on global contrast
2.3 颜色空间分布特征

(10)
这里设置高斯混合模型中分量值g最大值为6,本文采用文献[13]中同样方法对高斯混合模型进行初始化,并使用EM算法训练高斯混合模型中的各参数。将高斯混合模型中第g过分割区域的水平方差Dx(g)定义如下:
(11)
(12)
(13)

(14)
则第g个高斯成分整体空间的分布方差Dxy(g)定义如下:
Dxy(g)=Dx(g)+Dy(g),
(15)
下面需要对公式(11)、(14)和(15) 3种方差进行归一化,计算如下:
(16)
通过上式可以看出分布方差大的区域颜色空间分布较为广泛,显著目标存在的可能性较小,分布方差小的区域颜色空间分布较为集中,显著目标存在的可能性较大。设置区域颜色空间分布控制权值δ,水平、垂直、综合区域颜色空间分布显著性特征计算如下:
(17)
(18)
(19)

图2 基于颜色空间分布的图像显著图Fig.2 Image saliency map based on color spatial distribution
2.4 超像素差异性特征
超像素分割(Simple Linear Iterative Clustering)是一种简单的、方便的分割方法,是图像处理过程中重要的技术手段[14]。本文基于超像素级来计算目标图像的差异性特征。
超像素差异性表现为超像素i在位置和颜色空间中相对于其他超像素分割的差别。d(i,j)表示超像素i与超像素j在位置和颜色空间中的距离:
(20)
上式中dc(i,j)表示超像素i与超像素j在Lab颜色空间归一化距离,dp(i,j)表示超像素i与超像素j的中心距离,β为调解参数,取值为2。计算全局的超像素差异性:

(21)
超像素差异性定义为:
(22)
上式中σu为高斯密度标准差。基于超像素差异性特征得到的显著性特征图如图3所示。

图3 基于像素差异的图像显著图Fig.3 Image saliency map based on pixel difference
3 高层先验特征及其融合
3.1 背景先验显著
利用超像素分割算法对目标图像进行超像素分割,通过粗选背景集、精选背景集和显著值计算3步得到背景先验显著图。
3.1.1 粗选背景集
从左至右、从上至下对目标图像进行扫描,取目标图像周边一圈20个像素作为边界区域背景混合区B0,背景混合区横纵坐标范围:
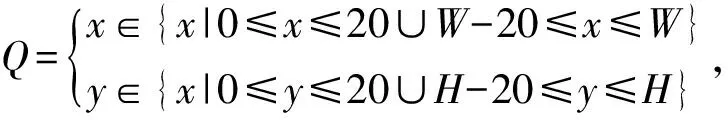
(23)
上式中W、H表示目标图像的宽和高,将这些边界定义为粗选背景集B0={pi|pi∈Q}。
3.1.2 精选背景集
由于显著目标不一定居于目标图像的中心,有可能接近于边界区域,为了进一步突出显著性目标,要对粗选背景集做进一步筛选,计算粗选背景集各超像素pi的Tboundary(i):
(24)
(25)

3.1.3 计算显著值
对目标图像中的每个超像素pi在背景超像素集B下计算显著值:
(26)
(27)

3.2 中心先验显著
一般拍摄者都希望将所拍摄的目标放在图像的中心区域,但实际并非都如此,若直接将目标图像的中心作为显著目标的中心会导致显著性目标检测出现偏差。本文将前节得到的背景先验显著图中的质心作为显著目标的中心,提出一种新的中心先验显著方法。本方法将越靠近显著目标中心的超像素设置越高的显著值,对所有超像素显著值使用高斯分布求解中心先验。超像素pi中心显著值计算如下:

(28)
(29)
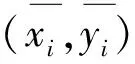
3.3 不同显著特征融合
文章分别求出4种低层显著特征值和2种高层先验特征值。但某些性质相似的分割区域在不同求取方法下得到的显著特征值差异较大,为了降低各显著特征在融合时的差异,需对不同显著特征进行归一化处理。
首先将Ti(1)、Ti(2)、Ti(3)、Ti(4)、TB(i)、TC(i)这6幅显著图统一归一化到区间[0,1]内,利用最大类间方差法(Ostu)对得到的6幅显著图所有显著值进行阈值求解,得到类间差异最大的阈值T′,对于第m个显著图中的像素(x,y),当其显著值TN(x,y)在6幅显著图中均大于类间差异阈值T′时,表示像素(x,y)确处于显著区域,融合采用线性策略;反之,则表示像素(x,y)并不处于显著区域,融合采用非采用线性策略。设像素(x,y)最终的显著值为T(x,y),则:
(30)
(31)

(32)
公式(31)中γN为非线性融合时的融合系数,其表示第N个显著特征图中水平和垂直方向标准差加权之和,公式(32)分别为第N个显著特征图中横纵坐标在水平和垂直方向上的加权平均值。
4 仿真实验及结果分析
4.1 实验环境与评价
为验证本文所提算法的性能,将本文算法与AC算法[15]、CA算法[16]、LC算法[17]、HC算法[18]、GC算法[3]、SF算法[19]、文献[20]、文献[6]进行显著性检测实验。上述对比算法中LC、HC、GC、SF是基于全局特征对比类型,AC和CA属于局部特征对比类型,文献[6]和[20]属于多特征融合类型算法。本文从主观视觉和定量对比两方面分析实验结果。
实验硬件环境为Intel(R) Core(TM) i7-7700U@3.6GHz,RAM:8GB,软件编程环境为:Windows 7操作系统,Visual Studio 2013 开发工具,使用C++进行编程实现。实验在MSRA-1000[22]、SED[23]和SOD[24]3个国际公开的显著性检测数据集上进行。
本文采用PR曲线(查全率-查准率曲线)、平均绝对误差(MAE,Mean Absolute Error)、F-measure值和AUC值(Area Under the ROC Curve)等4种评价指标对各显著性检测算法进行定量分析。
4.1.1 PR曲线
查全率(Recall)和查准率(Precision)被广泛应用于显著性检测算法的结果评价中。经显著性检测算法得到显著图T(x,y),采用固定阈值将其转化成二值图像M(x,y),利用二值图像M(x,y)和人工标记G(x,y)计算查全率R和查准率P,查全率R和查准率P计算公式如下:

(33)
PR曲线是以固定阈值转化后的二值图像计算得到查全率R和查准率P,并以此画出曲线,如果曲线起始高,后期曲线越平稳检测算法越好。
4.1.2 F-measure值
F-measure值就是查全率R和查准率P的加权调和平均,本文采用文献[21]提出的动态阈值二值化显著图T(x,y),动态阈值ψ及F-measure计算如下:
(34)
(35)
上式中参数β2一般取值为0.3。数据集中的F-measure值为数据集中每幅目标图像的平均值,其值是对查全率R和查准率P的综合,越大越好。
4.1.3 AUC值
AUC被定义为ROC曲线下的面积,是一种度量分类模型好坏的标准。又由于ROC曲线一般都处于y=x的上方,所以AUC的取值范围一般在0.5~1之间。通俗的说AUC值越大显著性检测的正确率越高。
4.1.4 MAE值
KMAE是算法得出的显著图与人工标记间的平均绝对误差,计算公式如下:
(36)
通过上式可知KMAE值描述的就是显著图与人工标注的相似程度,其值越小越好。
4.1 主观视觉对比
本文选取的3个数据集可分成两组,MSRA-1000和SED数据集为一组主要包括单个显著性目标,目标边缘清晰、语义明确,显著性识别相对较易;另一组SOD数据集显著目标纷杂,目前显著性检测算法对此数据集的检测效果与前两种数据集相比较差。首先将本文算法与其他8种算法在MSRA-1000数据集上进行显著性检测,MSRA-1000数据集含有1 000幅自然图像,是现阶段图像显著性检测的默认数据库,人工标记的分割结果由文献[21]提供,检测结果如图4所示。

图4 各种算法在MSRA-1000数据集上的实验结果Fig.4 Comparison of the indicators of the algorithms on MSRA-1000 data set
通过对比以上检测结果看出:各显著性检测算法都能大概检测出目标图像的显著性目标,CA算法总体较差,显著性目标检测结果边缘较为模糊;LC、AC、GC、SF等算法或多或少在显著性目标检测时会将背景信息误检测为显著目标区域;文献[21]在检测背景与目标颜色差别较大的目标检测图(如第1、2、4、5、6、8幅图)时能准确地检测出显著目标,但对于背景与目标颜色差别较小的目标图像,显著性检测效果稍差;文献[6]能大部分检测出目标图像的显著性目标,但在处理颜色空间对比度较高的背景区域时有时会误凸显,这是由于算法虽然融合了多种显著特征,但其只注重于底层特征的融合,对于高层先验信息并没有有效融合;本文显著性检测结果与人工标注的重合度比较高,不仅能有效的将图像中的显著性目标检测出来,还能与人眼的视觉注意点吻合。各算法在SOD数据集上的显著性检测结果如图5所示。
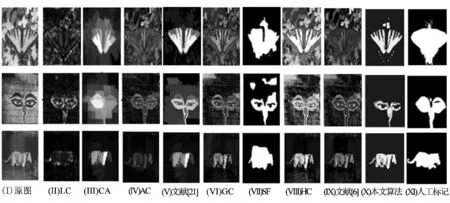
图5 各种算法在SOD数据集上的实验结果Fig.5 Experimental results of various algorithms on SOD datasets
LC算法显著性检测结果较差,在抑制背景的同时,目标也被抑制了;SF算法虽然能将背景抑制彻底,但是目标轮廓提取较宽泛;CA算法能基本检测到显著目标,但是在目标和背景相似的显著区域检测效果不佳;AC、GC、HC、文献[20]和文献[6]都能基本检测出显著性目标,但在背景和目标相近的颜色区域,算法或多或少将背景信息误检测成目标;本文算法能在复杂背景下较好的检测出显著性目标,边界轮廓基本清晰。
4.2 定量指标评价分析
视觉对比因观察者的感官而有差别,不能作为评价显著性检测算法好坏的唯一标准。为了定性的比较各显著性检测算法的检测效果,将本文算法与其他显著性检测算法进行定量计算。
4.2.1 不同算法在MSRA数据集上的性能
将不同显著性算法在单个显著性目标数据集MSRA上进行定量计算,图6为各算法4种评价指标对比结果,(a)为PR曲线,(b)为F-measure值,(c)为MAE值,(d)为AUC值。
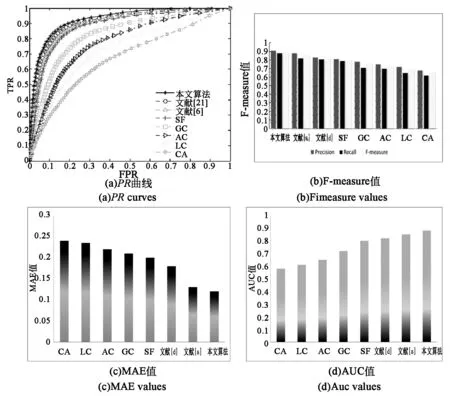
图6 各算法在MSRA-1000数据集上的指标对比Fig.6 Comparison of the indicators of the algorithms on MSRA-1000 data set
从图6各评价指标的对比中可以看出,对于单个显著性目标MSRA数据集,各显著性检测算法检测效果普遍较好,指标评价情况与图5视觉显著性检测结果一致。与效果较好的文献[20]相比,查全率、查准率至少提高了3.4%。
4.2.2 不同算法在SOD数据集上的性能
将不同显著性算法SOD数据集上进行定量计算,图7为各算法4种评价指标对比结果。
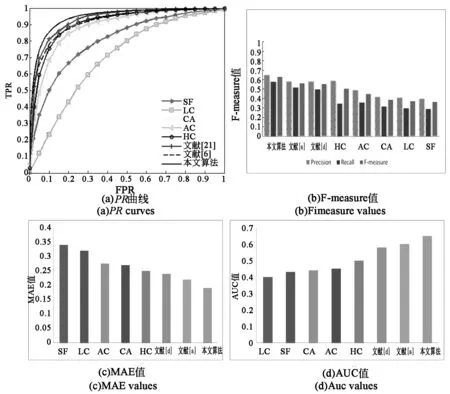
图7 各算法在SOD数据集上的指标对比Fig.7 Comparison of indicators of algorithms on SOD data set
从图7各评价指标的对比中可以看出,对于识别图像比较复杂的SOD数据集,各显著性检测算法检测效果普遍较差,但本文算法融合了多种显著特征,总体上较其他算法有较大的提高,查准率为65%,相较于在其他算法至少提高了12%,这与视觉显著性检测结果也是基本一致的。
综合两个数据集上的定量指标对比,我们可以看出本文算法无论对边缘清晰、颜色分明的单目标数据集还是对颜色相近、目标难辨的复杂数据集都能有较好的显著性识别结果,这是由于算法融合了底层和高层显著特征,针对差异较大的显著特征值,为了降低各显著特征在融合时的差异,本文采用线性和非线性融合策略,确保显著目标识别的精确。
4.2.3 时间复杂度对比
将各算法在MSRA-1000数据集上运行,硬件环境如前节所述,各算法的平均运行时间如表1所示。

表1 各算法平均运行时间Tab.1 Average running time of each algorithm
由于是多特征融合进行显著特征提取,使得本算法的计算开销相对较大,相对比文献[6]、文献[20]、AC、SF等算法,本文的计算运行时间较短,但与LC、CA、GC算法相比,运行时间略长,针对于此,后期可以通过并行计算策略降低运行时间。
5 结 论
针对单一或同类几种显著特征无法全面表达图像显著性,显著检测精度不高等问题,本文提出了一种融合高低层多种特征的显著性检测算法。算法利用类间差异阈值以线性和非线性策略融合2种高层先验特征4种低层图像特征,从而获得高质量的目标图像显著图。通过实验对比可以得出本文算法在有效抑制背景信息的同时所得显著图像视觉感知更好。但算法运行所需时间稍长。利用并行策略进一步降低运行时间是本文下一步的研究重点。
