并行计算视域下大数据挖掘技术及其在锅炉性能升级中的应用实践
2019-05-28李春晓李艳红
李春晓,李艳红
(1.西安外事学院工学院计算机系,陕西西安,710077;2.西安外事学院工学院计算机公共教学部,陕西西安,710077)
当前社会环境下互联网的发展数字化的时代特征越来越明显,也使电力行业紧跟时代潮流逐渐的信息化[1-2]。最为明显的就是监控信息系统(Su-pervisory Information System,简称SIS)与分布式控制系统(Distributed Control,简称DCS)两者在电力行业中被运用,以便于电力行业中的大量数据能够完好存储,数据挖掘也逐渐在电力行业中慢慢被重视,越来越多是相关研究人员在电站机组中碰到难题时选择运用数据挖掘的方式来进行处理[3]。因此电站在提升锅炉效率与解决NOx排放等问题时均将数据挖掘聚类分析运用到其中。
1 相关工作背景
1.1 粗糙集理论
在1982年波兰数学家Pawlak提出了粗糙集理论,为解决难以确定以及难以做到精确时的数据研究理论,主要的研究主体为信息数据系统,以更加简约的形式来完成数据的分类,且能够维持信息数据分类的相应能力不被改变。相较于其余的同类型解决数据不能精确的理论而言,此理论最具突出的特点为不必要为待解决问题提供除数据库的其余任意相关先验知识,能够与其余理论形成互补。如今,在临床医学、模糊识别以及预测控制等多种行业中得到运用。
粗糙理论的最大优点为其属性约简,首先最佳子集从原始特征中来进行筛选,而后在其中选出最为重要的特征,将多余无用的数据删去,以使数据维度缩小,以此进一步提升数据的研究效益。本文主要在Pawlak属性基础之上的决策表属性约简算法中完成属性约简,具体的属性约简主要框架见图1。
1.2 Hadoop平台
在Hadoop平台,需要在MapReduce的主要框架下完成数据的分析,该框架能够满足大数据的问题处理模式。且在MapReduce框架下主要运用Map和Reduce两种函数,即映射与归约函数来完成数据处理。按照实际情况对数据源分散处理,通过<key,value>键值对来完成Map与Reduce两个函数的输入输出。Key为聚类类别、value主要是数据维度和主体数据的数量累加。每个数据块都以分别对应的各自的Map函数同时完成数据的计算输出,而后进行输出数据的顺序排列与整合,并且对key值一样的数据来形成Reduce函数的输入值,而后继续完成计算。MapReduce框架的具体运作流程见图2。
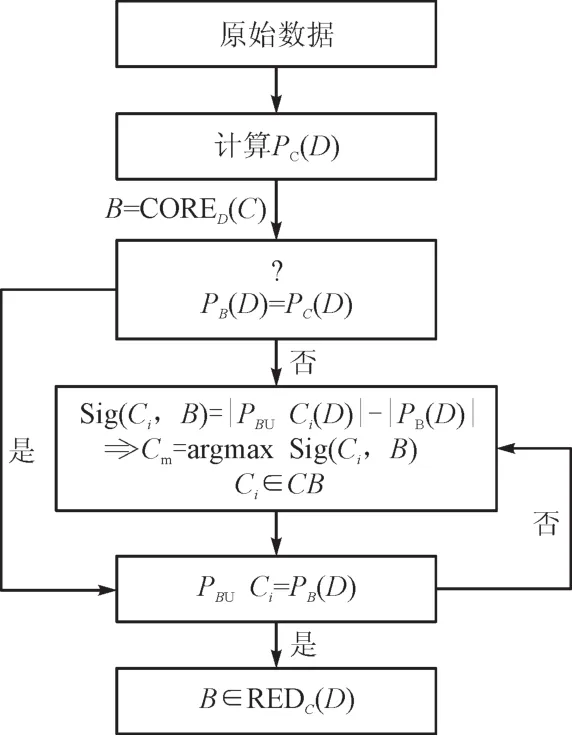
图1 属性约简的基本框架
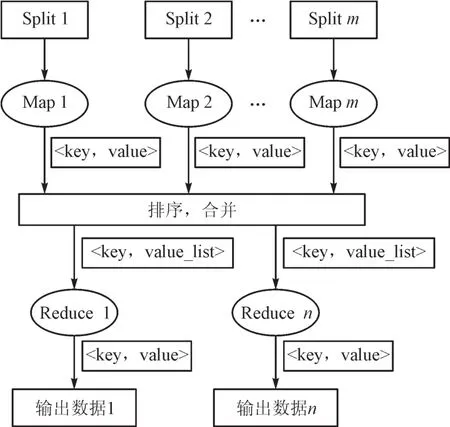
图2 MapReduce工作流程
2RCK-means新算法流程
在MapReduce的基础之上进行顺序组合而形成的程序则为RCK-means算法,首先同样需要对数据的原件进行属性约简处理,而后根据其顺序可分为Canopy与K-means两个子框架来继续进行计算。详细顺序流程可见图3。
(1)首先创建最初的决策表通过粗糙集理论来完成,而后进行条件与决策属性的判定,再根据两者属性的依赖度来完成下一步的属性约简,将无关的数据删去,留下的有用数据组成集合。
(2)在Canopy算法中进行Map函数时,将有用的新数据集合换为<key,value>键值对的方式,并将其放入m个Map函数继续进行计算。当每个数据块的距离阀值,并且需将计算出的数值与D1、D2完成对比之后分类处理,最后迭代形成一个集合,即Canopy集合。
(3)在Canopy算法中进行Reduce函数时,首先需要对Map中完成的结果进行并集处理,组合成一个新的Q集合。之后对该新集合实行Canopy流程,不断的进行程序处理,直至该集合为空,可以计算出聚类簇K,而后才可将其当做输入值进行K-means框架的处理。
(4)K-means算法中Map函数时,将Canopy程序处理得出的聚类簇以<key,value>键值对输入,之后计算节点与中心点之间的距离计算,而后汇总,进行类别的分类处理,最后用同样的方式输出。
(5)通过Combine函数来完成上一阶段输出值的分类处理,之后本地进行数据归集,对各数据的维度值做总和计算,且需得出数据的数量,最后输出以<key,value>键值对的方式。
(6)在K-means算法中进行Reduce函数时,首先需要对上一阶段Combine函数的输出结果进行分析,对各数据的维度值做出总和计算,且需得出数据的数量,最后形成新的聚类中心,之后继续进行重新的迭代,直到收敛。

图3RCK-means算法流程
3 在锅炉效率优化中的运用改进RCK-means算法
3.1 电站锅炉效率优化中运用大数据技术的意义
电站机组一直将电站锅炉的能源节约作为其优化的重点,这是由于锅炉的效率是电站经济与环保性的重要参考数值。如今,优化方式有以下两种,其一为对燃烧器与受热面进行升级整改处理,以此优化效率,亦或引进更为先进的相关设备来实现锅炉使用时的参数监测。然而此类方式虽能够产生很好的效果,但同样需要花费的人力财力也非常高。其二为以DCS为基准,加上数据挖掘来完成锅炉使用最佳参数的选择,这一方式的不足之处在于需要较多的依靠模型优化以及算法升级来完成,因此会在模型优化中出现建模过程难以得到样本的问题,实用度不强。以电站DCS系统拥有的大量数据作为大数据挖掘技术做铺垫,加之严密的计算流程,将影响锅炉效率的参数从热力系统的大量数据中挖掘出来,即使实际得出的参数值会与理论上参数最佳值之间有些误差,但得出的这一参数值能够成为至今最佳的参数值。本文运用K-means聚类算法的优化加之Hadoop框架,在大量的数据中依据集(簇)聚类中心点来挖掘锅炉效率的影响参数,以形成最佳集合,之后结合实际理论以及数理检测来验证最佳的适用参数,以此保证所得参数符合实际可用性,具有真正的现实意义,能够被应用于使锅炉效率提升的参数挖掘,提升整体锅炉效率。
3.2 大数据挖掘对象
研究以某一600 MW燃煤机组锅炉作为主体,此锅炉的燃烧器为摆动四角切圆形,选取分析研究数据一共129 600条,主要数据选取区间为2018-10-01~2018-12-31。
3.3 确定大数据挖掘目标
将锅炉效率当作本次分析研究的主要目标,运用RCK-means算法来寻找会对锅炉效率产生影响的数据,在处于一般情况下,运用集(簇)聚类中心点于锅炉效率之间的联系来确定最佳的参数,为实际操作确定方向。在能够影响锅炉效率的相关参数中,选出以下几项来分析研究,即排烟氧量,燃烧器摆角,排烟温度,磨煤机给煤量以及飞灰含碳量。
3.4 大数据预处理
粗糙集理论只能够对离散型的数据进行分析,因为其具有不能辨别数据关系的这一缺点,然而运用DCS所归集的大部分均属于连续而非离散的信息,由此可知在事前需要对DCS归集的相关信息进行分散处理。能够分散数据的方式有许多,若运用传统的方式,则会出现数据分割点难以寻找,且若没有对数据进行准确的分散,会影响后面的数据处理,进行数据分散较易出现有用数据被排除可能。因此本文选择运用模糊粗糙集分散方法,顾名思义即为模糊集与粗糙集两种方式相结合来进行数据分散,运用两种均具有不确定性质的方式对归集的数据完成“柔化分”与属性约简处理。这样的分散方式能够在一定程度上弥补单独运用粗糙集时存在的不足之处,也降低有用的重要数据被排除的可能性。
3.5 大数据挖掘算法应用及结果
对约简后的数据运用RCK-means算法来继续完成数据的挖掘。将Hadoop平台的支持度设定一个最小值2%。而后依据标准的数据计算处理顺序对约简后形成的集合进行处理,挖掘有用的参数,找到在大量的数据中聚类中心点和锅炉效率之间最佳的参数值。
据实际分析可知,运行出的排烟氧量最佳优化值与设定的实际值之间会存在着较大差异。当出现低负荷的情况时,设定值会小于最佳优化值,这是因为在此环境下锅炉较难燃烧,一定程度上使排烟氧量增多会有助于降低不燃烧热而引起的不利影响,提升整体效益。而当负荷值较大,达到500 MW之上则有助于锅炉的燃烧,相应的排烟氧量最佳优化值会降低,出现设定值大于最佳优化值的情况。由此可知,在实际运用中,以便于更好的在不同情况下均可达到效率最大化,则不可运用设定值进行操作,需要对不同运行情况下的数据进行更新优化,以找到最适的参数值,达到实际效用。
4结语
运用大数据技术对影响锅炉效率的数据进行挖掘,寻找最佳的参数值,使锅炉效率得到最大化。RCK-means新算法的运用将无效数据进行排除,形成最佳的集合,从整体上提升了聚类准确率。在实际运用中,为了更好的在不同情况下均可达到效率最大化,则不可运用设定值进行操作,需要设定一个最佳区间,而后针对不同情况进行数据优化,以找到最合适的参数值。
