一种基于语义的分布式云服务发现方法*
2019-05-27王文丰韩龙哲李沛武李岚刘天元
王文丰,韩龙哲,李沛武,李岚,刘天元
(1. 江西省水信息协同感知与智能处理重点实验室∥南昌工程学院, 江西 南昌 330099; 2. 南昌工程学院信息工程学院,江西 南昌 330099; 3. 南昌大学软件学院,江西 南昌 330047)
云服务是面向云计算提供的一系列服务程序,它可以为云计算用户解决其想要解决的问题。随着云服务的普及,云服务提供者便应运而生。云服务提供者能够让用户挑选出自己满意的云服务,但云服务的挑选过程却是相当费时和费力的[1]。因云服务规范是异构和非标准化的,导致了语义互操作性问题。此外,用户对云服务的QoS保证要求更加严格。因此,云服务技术的难点在于如何发布最有效且具有低成本的服务,而又能保证最佳的服务质量。向云用户提供令人满意的服务,是高可扩展的服务发现技术的根本。对于云服务发现,一个难点就是服务消费者的定位服务,尤其是当该服务独立发布的时候[2]。
在这种情况下,服务发现成功的关键是可用性、可访问性的有效服务注册。由于集中服务注册方法会存在单点失效、网络拥堵和性能瓶颈等问题,P2P网络必须探索一种有效的服务发现机制[3]。P2P的容错性和可扩展性解决了云环境中服务发现问题;同时,随着云服务的发展,分布式服务注册也促进了P2P的可扩展性和容错性发展。在P2P系统中,研究人员已经对目前主流的服务发现技术进行了一定的研究[4]。研究发现,在基于分布式的结构化P2P覆盖网络中发布和查询服务可以解决集中式注册的问题[5],这是因为在结构化P2P覆盖网络中存在一个分布式哈希表,它能够支持关键字的存储和检索,如put(key, value)和get(key)操作。因此,结构化P2P覆盖网中的用户能够更加有效地发现服务,并且发现服务的时间也可以减少到O(logn)。然而结构化P2P覆盖网络也存在一个缺点,即它只支持精确匹配的查询,而且维护其拓扑结构也是需要相当大的开销。如对等点和服务经常会频繁地加入和退出,占据了系统很大的开销[6]。另外,由于云服务描述没有任何标准格式,所以精确匹配的查询方式可能无法查询到相关的所有服务。与结构化P2P相比,非结构化P2P模型可以更好地模拟现实世界的问题。在非结构化P2P系统中,对等点加入时不需要事先了解它的拓扑结构[5]。非结构化P2P系统的拓扑结构存在一定的随机性[7],因此非结构化P2P系统的搜索方法不能采用Hash函数,但它可以采用灵活性的数据定位搜索方法并支持非精确搜索。泛洪技术及其变种[8-10]就是非结构化P2P系统中一种代表性的搜索方法,它被广泛用于处理非结构化P2P系统中的消息路由。然而非结构化P2P系统也存在一个主要的缺点,即如果对等点之间的联系经常改变,在本地索引存储的统计数据就会变得无效。为了克服结构化和非结构化P2P系统中的缺点,语义覆盖网络便应运而生。在语义覆盖网络中,相似的对等点之间建立语义边,以提高搜索精度,改善搜索结果[11]。语义覆盖网络是一种语义相关对等点相连的虚拟网络,通过集成语义,可以提供更有效的多维查询[12-15]。
语义覆盖网络(SONs)[11]提高了P2P系统的搜索质量,在语义覆盖网络中,把服务描述相似的对等点组织在一起,提供一组服务描述,以确保服务发现的成功。因此,在搜索时查询只需转发到相应的对等点即可,从而减少了通信开销,提高了成功率。本文旨在探讨云服务发现方法,通过探索云本体(cloud ontology, CO)来描述云服务,提高语义覆盖网络的服务发现成功率。同时,本文也研究了使用语义覆盖网络在非结构化P2P网络中高效转发查询机制。本文提出了基于语义覆盖网络的服务发现方法(SD-CSR),该具有良好的可扩展性和适应性。由于它的分布式特性,所以在服务发现过程中,对等点只考虑其本地信息和它的邻居信息。并根据对等点之间的相似性,利用语义描述的服务来计算这种相似性。
1 基于语义的分布式云服务发现方法
一般地,云本体是利用网络中的所有对等点来存储和检索的云服务描述。云本体CO由云概念C= {C1,C2,C3, ,Cn}组成,其中包括n个概念和与这些概念有关的联系。服务注册根据不同的服务类别分散到各个区域中,每个区域保持本地本体的副本。用户查询被转发到最相关的区域,由能力表添加到每个区域。能力表中保存了服务类别的兴趣点。
1.1 对等点聚类
为了减少查询处理时间和网络流量,提出了聚类服务的概念,它产生于基于语义描述的每个区域[11]。在本文中,用本体论的概念作为对等聚类的基础。具有语义描述服务的对等点,最初聚集到一些代表不同层次服务集的固定簇数Ci(1≤i≤m)中。随后,每个区域都存在对等点的簇。一个服务描述D由以下部分组成:类别、服务描述属性、供应商信息和QoS,可以表示为D= {CCi,SD_Attributes,Provider_info,QoS_facets}。其中,CCi∈Service_category_class。每个集群管理节点中存在一个集群信息表{Peer_id,current_status,last_update_info},它表示集群注册的云服务,并构建集群内和集群之间的路由。集群管理节点还保存另外一个表,称为邻居集群表。它提供了另一个相关集群中对等点的信息,该信息与该集群中的对等点具有语义相似性。该表用一个三元组{neighbor_cluster_manager_id,neighbor_peer_id,stauts}表示,它保留了一组集群描述(CD),CD包括了簇标识符Ci、属性向量Ai,属于集群的对等点{P}和集群M,例如:CDi=(Ci,Ai, {P},M)。而,M中的对等点作为每个集群的质心。
1.2 语义覆盖网络的创建与维护
在集群中,可以通过查找语义相关的对等点来降低查询成本,并提高服务发现的质量。一般情况下,其他集群的对等点可以提供相应的响应服务请求。由于其他集群的对等节点能够提供相应的响应服务请求,因此在语义覆盖网络中,可以很方便地查询所有相关的对等点,并保证簇间的连通性,从而实现每个对等点获得其邻居的信息。对等点保持两种与邻居相连的语义边:① 内部节点的语义边:连接属于同一个群集内的对等点;② 外部节点的语义边:连接属于不同集群的对等点,实现语义可达节点之间的语义联系。特别地,内部对等语义边涉及在同一集群上发布的一对类似服务。内部对等边定义为元组{peer_id,semantic_similarity,status,time}。外部对等边定义为元组{cluster_id,neighbor_peer,semantic_similarity,status,time}。这里,链接的对等点被称为语义邻居。一个对等的语义边连接着一个本地服务与对等的语义邻居上发布的服务。一个对等点Pi是对等点Pj面向服务描述Si的语义邻居,如果对等点Pj有一个服务描述Sj,则Si和Sj通过对等点间的语义连接。在任意两个对等点间存在以下四种关系:
(1)精确:两个对等点提供相同的功能。如,sim(Px,Py)=1。
(2)延伸:一个对等点提供额外的功能给其他对等点。如,sim(Px,Py)∈(0, 1),如果S1提供了额外的功能给S2,则S1延伸S2。
(3)相交:在对等点提供的功能之间存在一个非空的交集(重叠)。如,sim(Px,Py)∈(0, 1)。
(4)失配:没有共同之处。如,sim(Px,Py)=0。每个区域都可以表示为一个元组(C,P,LL,NL),其中C= {c1, .,cn}是一组有限的集群,每个集群是一组有限的自治节点P。LL⊆P×P是一组本地边的集合,每条边(Pi,Pj)∈LL表示同一集群内的对等点Pi和Pj之间存在直接连接。NL⊆P×P是一组邻居边的集合,其中每条边(Pi,Pj)∈NL表示不同集群内的对等点Pi和Pj之间存在间接连接。图1给出了一个区域的元素。

图1 区域的元素Fig.1 Elements of zone
外部语义边根据探测请求的答复情况进行连接,如果对等点Px发送到Py一定数量的探测请求没有应答,则认为语义邻居Py是不可达的。在这种情况下,移除连接Px和Py的外部边。发布/取消服务就是采用类似的方式进行管理的。表1展示了对等点内部边的建立过程,表2则显示了对等点外部边的建立过程。

表1 对等点内部边的发现算法Table 1 Algorithm of intra-peer link discovery of peer

表2 对等点外部边的发现算法Table 2 Algorithm of inter-peer link discovery of peer
在语义覆盖网络有效地创建后,主要关心如何利用他们在规定时间内提高搜索性能。获取满足用户请求的一组服务的过程称为服务发现。服务请求被发送到区域管理器能力表上。它是对发布在集群上的语义服务接口进行匹配和转发给潜在的集群Cx的服务描述进行查询。内部节点的语义边在对等点Px∈Cx上匹配服务描述的请求,用来修剪相关服务集和减轻服务比较的数量。外部对等语义边用于转发请求给远程相关的语义邻居对等点Px。在这种方式中,只有相关的节点进行并行搜索,从而减少网络拥堵和寻找的服务时间。表3和表4分别显示了对等点内部语义边和外部语义边的建立过程。
在表5的算法中,当发现满足请求的服务后才停止搜索,而请求转发到语义邻居实现相应的服务。重复这一过程直到:1)没有其他对等点的请求可以被传播;2)请求消息的生存时间(Time-To-Live)下降为零。区域管理器为每个服务请求分配一个唯一标识符和时间。为了避免重复请求的泛滥,每当对等点收到请求时,它会将服务标识符存储在指定的生存时间内。已被匹配的群集管理器在TTL时间周期内处于封闭状态,并将所有相关服务的列表转发给区域管理器。每个区域管理器有一个QoS过滤器,以更进一步过滤掉不相关的服务。当来自不同群集的一组服务到达区域管理器时,它将根据QoS和信任程度对服务描述和用户请求进行第二级筛选。将不同的列表组合成一个列表,其中包含降序排序的服务,并将结果提交给用户。

表3 对等点内部语义边的维护算法Table 3 Algorithm of intra semantic link maintaince of peer

表4 对等点外部语义边的维护算法Table 4 Algorithm of inter semantic link maintaince of peer

表5 服务发现算法Table 5 Algorithm of discovery of services
2 实验结果与分析
本节通过实验分析SD-CSR方法的基本性能。所有的模拟实验在模拟器Neurogrid[16]进行,该模拟器随机生成一个了N个对等点和NS个服务的P2P网络。服务S1和S2之间的匹配根据以下概率分布进行设置:P(S1精确S2)= 5%,P(S1不匹配S2)= 45%,P(S1扩展S2)= 15%,P(S2扩展S1)= 15%和P(S1相交S2)= 20%。为证明本文SD-CSR方法的有效性,我们与Gnutella协议[17]进行了实验对比。Gnutella是一个用于分布式搜索和数字资源共享的协议,尽管支持传统的客户机/服务器架构,但Gnutella协议是点对点、非中心的模型。为了体现Gnutella协议的简单性,采用了一种盲目的搜索机制—洪泛。在该机制中,对等点在TTL时间半径内进行洪泛查询。
TTL决定了一个查询可以被转发到网络的最大次数。TTL值越高,响应请求的对等点的数量就越高。在模拟实验中,TTL被设置为1和15之间。设T∈N+为TTL初始值。如果所有潜在的对等点,提供相关的服务在TTL时间内不能被导航,结果就可能不完整。在具有N个对等点的非结构化P2P语义网络中,所有相关服务匹配的查询请求能够通过对等点集P在T内被导航。设v是被转发到对等点集P中一个对等点的请求概率|P≤T|,则在T内到所有相关节点的概率(Pt)[18]为:
V|P|·(1-v)j-|P|+V|P|;
otherwise,Pr=0
(1)
在最坏情况下,|P|=T,且对于任意的p∈P,都有一个相关的服务匹配查询,这将产生一个通用下界v(|P|)。命中率是由分布式搜索策略检索到的服务数量的比率,如果所有的服务都在一个对等节点上可得。当命中率较高时,分布式搜索将更加成功。命中率取决于TTL值,命中率的结果如图2所示。通过设置TTL参数的不同值,可以改善命中率;当TTL增大时,命中率值会合理上升。从图2可以看出,即使在低的TTL值,SD-CSR方法也要优于Gnutella。这是因为与对等点的语义联系有助于低数量的请求转发到潜在的对等点。
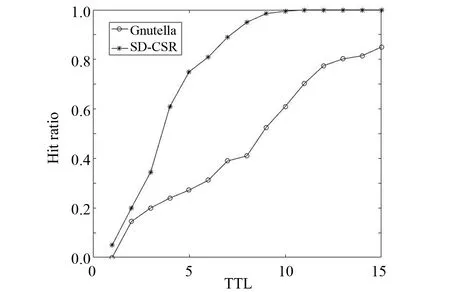
图2 命中率与TTLFig.2 Hit ratio and TTL
召回是现有相关结果数和相关结果总数的比率。图3显示了一个召回与不同数量的服务返回时的情形。与TTL类似,SD-CSR的召回率明显高于Gnutella,因为所有潜在的对等点都通过语义边聚集在同一个语义覆盖网络中。
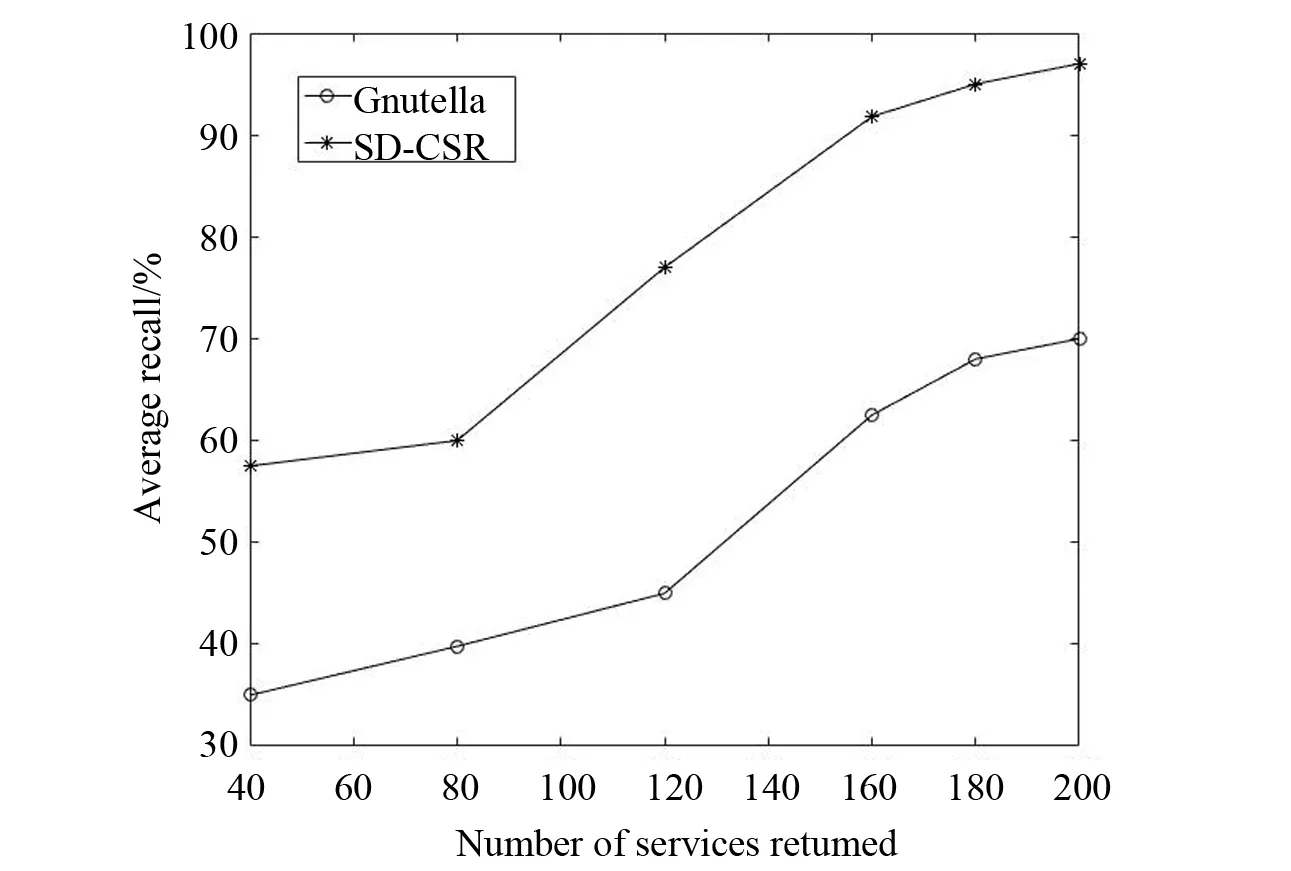
图3 召回率分析Fig.3 Analysis of recall ratio
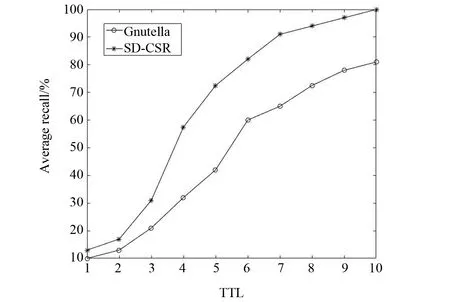
图4 召回率与TTLFig.4 Recall ratio and TTL
从图4可以看出,召回率随着跳数的增加而上升。当TTL大于7,对SD-CSR系统的召回率均在90%以上,满足要求。
执行时间是用户接收到请求服务并进行应答所需的时间。分析表明:SD-CSR与Gnutella协议相比,在执行时间上明显减少;且,Gnutella协议执行时间随着对等点的数量呈线性增长。这是因为Gnutella协议利用的是基本的洪泛算法,执行时间较大。如图5所示,SD-CSR的执行时间较小。这是由于语义匹配技术大大减少了执行时间。SD-CSR和Gnutella的效率,如图6所示。因对等点基于语义链接被聚集到一组中,这样服务匹配可以限制到相关组中,所以SD-CSR可以减少大量的发现时间。
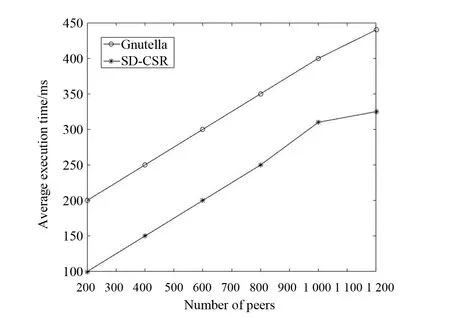
图5 执行时间比较Fig.5 Comparison of execution time

图6 执行时间和返回服务的数量Fig.6 Execution time and number of sevices returned
3 结 论
如何在分布式和异构环境中发现云服务是解决云计算的主要挑战之一。本文采用语义覆盖网络实现了云服务发现的探索性研究,通过分布式服务注册表,把服务定制在基于语义概念和本体共享边的覆盖网络中,并在对等点间建立语义链接,由对等点提供语义丰富的服务和对等点之间持有类似服务的链接,保证快速探索语义覆盖网络的目标和合法传播查询给合适的对等点。最后,利用基于本体的查询策略,以提高发现结果。实验结果表明:与Gnutella相比,无论是在发现过程的性能和效率方面,SD-CSR都具有明显的优势。
