面向短文本分类的特征提取与算法研究
2019-05-27刘晓鹏杨嘉佳田昌海
刘晓鹏,杨嘉佳,卢 凯,田昌海,唐 球
(1.华北计算机系统工程研究所,北京 100083;2.军事科学院 军事科学信息研究中心,北京 100142)
0 引言
在信息化时代背景下,各行业产生了大量的多源异构数据。对这些数据的信息挖掘,衍生出很多基于传统行业的新实践和新业务模式[1]。这些数据中存在着大量的超短文本,因此可以通过自然语言处理领域的知识方法,并结合已经提出的计算机科学方法,挖掘出许多高价值的信息。在某些短文本分类任务中,如通过标题划分可以避免对全文进行分类,可以节省大量计算资源;而在爬虫任务中,由当前页面附带链接的短文本分类,则避免了进入链接爬取数据,节省了大量网络资源。本文主要研究面向短文本分类不同的特征提取与算法差异。
1 特征提取方法介绍
1.1 独热编码
独热编码(one-hot encoding,one-hot),又称一位有效编码。在文本分类中,即每一位对应一个单词,以0代表该词没有出现,以1代表该词已经出现,通过固定顺序的词表,将每一个文本使用独热编码方式向量化。独热编码因为单词数量太多,在实际实验中,有时达到60 000以上的维度,直接导致了维度爆炸;而超短文本数据每条单词只有3~10个,又导致了数据的高度稀疏。
1.2 Word2Vec
Word2Vec[2]是一种Distributed representation生成词向量方法。Distributed representation最早由Hinton在1986 年提出。其依赖思想是:词语的语义是通过上下文信息来确定的,即相同语境出现的词,其语义也相近。
Word2Vec采用CBOW和Skip-Gram两种模型,以及Hierarchical Softmax和Negative Sampling两种方法,使用神经网络训练,将单词映射到同一坐标系下,得到数值向量。在实验中,用数据集训练出的模型泛化性能不好。分析得出,Word2Vec训练模型,文本需要大致在8 GB以上才会有较好效果。本文实验数据集只有200 MB。根据语料特征,最终采用已经训练好的谷歌新闻Word2Vec模型。
Word2Vec向量化采用300维度,避免了独热编码造成的维度爆炸、数据稀疏问题。在训练Word2Vec知识图谱过程中,引入大量数据,进一步提升模型的泛化能力。
1.3 词频-逆文件频率
词频-逆文件频率(Term Frequency-Inverse Document Frequency,TF-IDF)[3]是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一个词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。即一个词语在一篇文章中出现次数越多,同时在所有文档中出现次数越少,越能够代表该文章。
每条文本数据每个维度的词频-逆文件频率计算公式如下:
TF-IDF=TF×IDF
(1)
其中:
(2)
(3)
1.4 主成分分析
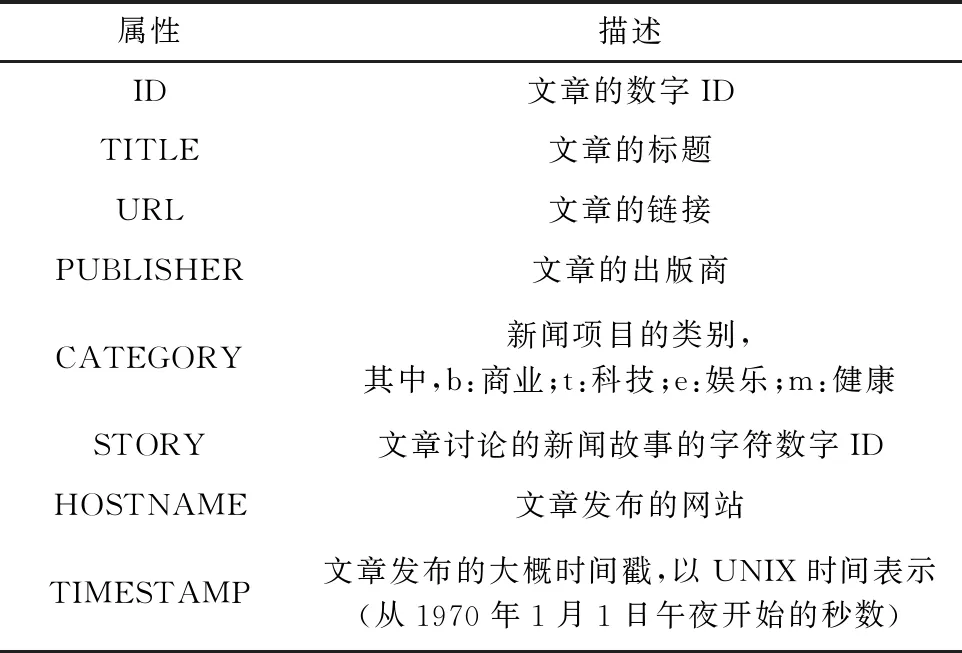
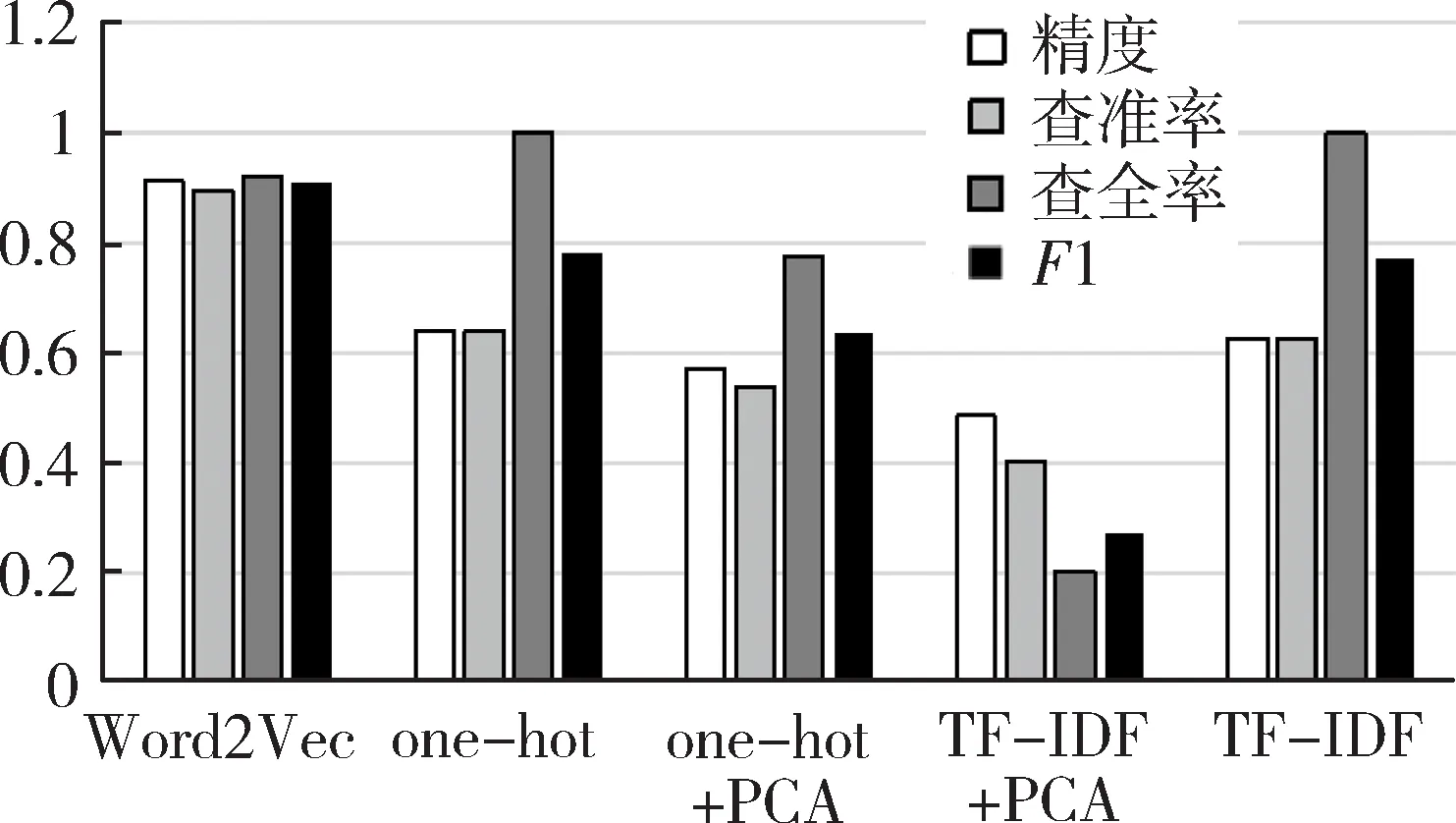
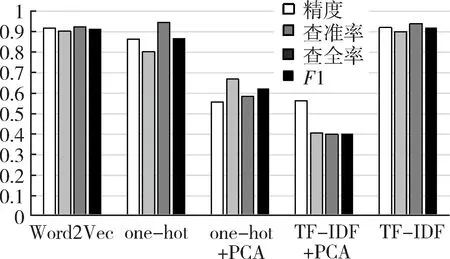
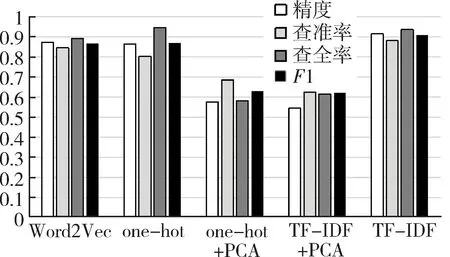
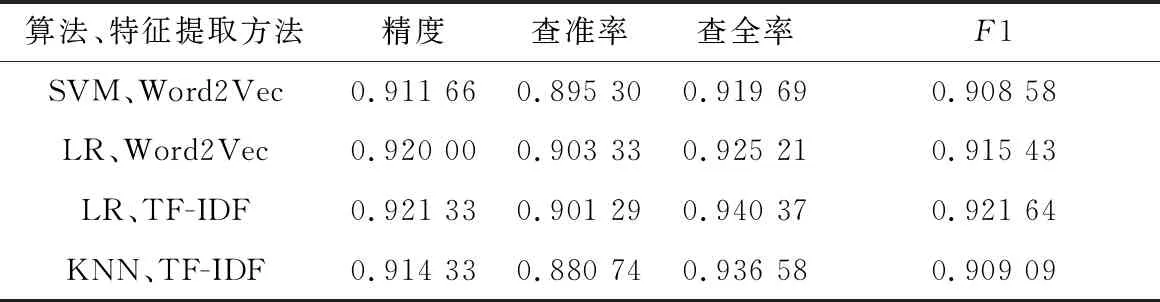
主成分分析(Principal Component Analysis,PCA)[4]是一种常用的数据降维方法。主成分分析通过矩阵变换,将n维特征映射到k维上(k< 在独热编码和词频-逆文件频率特征提取中,需要对每一个单词设立一个维度,导致向量化后的数据维度太高,模型训练对算力形成了较大的负担,经主成分分析,数据维度降低到原来的0.5%,大大降低了训练和测试的计算负担。 支持向量机(Support Vector Machine,SVM)[5]是AT&TBell实验室的Cortes和Vapnik在1995年提出的一种分类算法。SVM目标是在数据中找到一个分类超平面,达到分类目的。SVM自身可以正则化,分类超平面依赖于支持向量,因此在样本较少以及抽样不均衡的时候有较好结果。 SVM在文本分类和高维数据中拥有良好的性能,被选为机器学习十大算法之一,在2000年前后直接掀起了“统计学习”的高潮,是迄今为止使用最广的学习算法。 逻辑回归算法(Logic Regression,LR)[6]属于对数线性模型的一种,核心思想是利用现有数据对分类边界建立回归方程,以此进行分类。该算法简单高效。LR衍生出的Softmax将LR推广至多分类任务中。 逻辑回归算法因为其高效性及不俗的效果,是现在工业界应用最广泛的算法之一。 K近邻算法(K-Nearest Neighbor,KNN)[7]通过与最近K个点比较,投票选出类别。K近邻不具有显示的学习过程,分类中有计算量大的缺点。 K近邻算法简单成熟,在很多机器学习任务中有很好的效果,也是机器学习十大算法之一。 本文实验采用kaggle上公开的News Aggregator Dataset[8]作为测试数据集。News Aggregator Dataset包含2014年间40万条已经分类的新闻,数据集属性如表1所示。 表1 数据集属性描述表 此次实验主要采用TITLE属性作为超短文本的分类语料,类别标签采用CATEGORY属性。TITLE属性中包含的文本,长度大部分集中在3~15个单词之间,符合超短文本范畴;CATEGORY包含4种属性:商业、科技、娱乐、健康,比例大致为27%、25%、36%、10%,类别基本均衡,符合实验要求。 本次实验采用4个机器学习中分类常用的评价指标:精度、查准率、查全率与F1值。 在二分类问题中,根据样本真实类别与模型预测结果的组合定义真正例(True Positive,TP)、假正例(False Positive,FP)、真反例(True Negative,TN)、假反例(False Negative,FN),分类结果混淆矩阵如表2所示[9]。 表2 分类结果混淆矩阵 3.2.1 精度 精度是分类正确的样本数在总样本数中的比例。精度acc定义为: (4) 精度是分类任务中最常用、最基本但同时也是最重要的一个评价指标。 3.2.2 查准率 查准率P定义为: (5) 查准率反映了分类为正例中被正确分类的概率。 3.2.3 查全率 查全率R,也叫召回率,定义为: (6) 查全率反映了正例中被正确分类的概率。 3.2.4F1值 F1值是基于查准率与查全率的调和平均,定义为: (7) 查全率与查准率是一组相反的指标,相同模型下,查准率越高,查全率越低;F1值是对查准率和查全率的均衡反映。 系统环境:Ubuntu16.04LTS。 Python版本:Python3.6。 编码格式:utf-8。 首先,删去实验中不需要的属性ID、URL等,只保留CATEGORY和TITLE,以CATEGORY为标签,以TITLE为文本数据。接着对文本数据进行分词,分词过程中,去除无实际含义的停词、特殊符号、标点。最终生成的文本文件,每一行为一条数据,格式为“类别标签,分词”。最后,将生成的文件分成两个文件:训练集和测试集。 使用支持向量机、逻辑回归算法、K近邻算法三种算法,对独热编码、词频-逆文件频率、Word2Vec以及对独热编码和词频-逆文件频率结果分别进行主成分分析降维这五种特征提取方法得到的训练集特征向量进行训练,然后用测试集进行测试。 将每种算法所对应的所有特征提取方法的实验视为一轮实验。每一轮实验主要包含特征提取和模型训练两个部分。 3.5.1 特征提取 建立词表,词表中包含所有文本数据中出现的分词,大致60 000个。分别用独热编码、词频-逆文件频率和Word2Vec提取训练集特征,Word2Vec采用训练好的谷歌新闻知识图谱,为300维;个别模型需要对独热编码和词频-逆文件频率提取的特征向量进行主成分分析,再进行模型训练。根据不同算法模型,每次提取特征的训练集大小不同。 3.5.2 模型训练 本数据集有四个类别,是一个四分类问题,查准率、查全率和F1值对应的是二分类问题中的评价标准,因此,将四分类问题转换为二分类问题。在每一轮实验中,将四种类别两两作为一类,共有三种组合,对所有组合进行模型训练测试。训练过程中,对于类别的轻微不均衡,通过调参均衡数据。四个评价指标中,精度为首要指标。在每一轮实验中,选取最好的分类结果作为这一轮实验的最终结果。 3.6.1 支持向量机各特征提取方法的结果 图1从精度、查准率、查全率和F1四个维度来对比Word2Vec、one-hot、one-hot+PCA、TF-IDF+PCA和TF-IDF的性能。可以看出,在最重要的衡量指标精度方面,Word2Vec表现最为优异。而且从所有指标的均衡性来看,Word2Vec的性能最为稳定,明显优先于其他特征提取方法。因此,以支持向量机为基础算法,组合Word2Vec特征提取算法能获取最佳效果。 图1 SVM实验结果 3.6.2 逻辑回归算法各特征提取方法的结果 从图2可以看出,以逻辑回归算法为基础,Word2Vec、词频-逆文件频率等提取特征方法的效果较为显著且差别不大,独热编码略次于前两种方法。因此,以逻辑回归为基础算法,组合Word2Vec、独热编码以及词频-逆文件频率等提取特征方法能获取最佳效果且精度、查准率、查全率和F1四个衡量指标较为稳定。 图2 LR实验结果 3.6.3 K近邻算法各特征提取方法的结果 K近邻算法在Word2Vec、one-hot和TF-IDF上性能较好,且明显优于one-hot+PCA、TF-IDF+PCA,如图3所示。以K近邻算法为基础算法,组合Word2Vec、独热编码以及词频-逆文件频率等提取特征方法能获取最佳效果且精度、查准率、查全率和F1四个衡量指标较为稳定。但由于K近邻算法需要与各个数据进行相似度计算,其计算开销很大,不适合应用于对计算时间复杂度有要求的场景。 图3 KNN实验结果 在支持向量机算法中,Word2Vec的特征选择方法明显是最优异的,各项指标较为均衡,大部分评价指标均远好于其他方法;在逻辑回归算法中,Word2Vec与TF-IDF优于其余特征提取方法,TF-IDF查全率有少许优势,综合来说,Word2Vec与TF-IDF在该文件逻辑回归算法中,均有较好表现;在K近邻算法中,Word2Vec与独热编码方法较好,效果较一致,Word2Vec各指标更加均衡,TF-IDF更加优于前两种方法。四种表现最佳模型最终结果如表3所示。 表3 四种最优模型实验结果 表3中给出的四种最优的方法,精度相差无几,而结合其他评价指标,以词频-逆文件频率为特征提取方法、以逻辑回归为算法的模型为最优的算法。Word2Vec特征提取方法对于大多数算法都有不错的效果,同时,在个别算法中词频-逆文件频率也有着很好的效果。2 机器学习算法介绍
2.1 支持向量机
2.2 逻辑回归算法
2.3 K近邻算法
3 算法设计及实现
3.1 数据集介绍
3.2 评价指标

3.3 实验环境
3.4 数据预处理
3.5 实验过程
3.6 实验结果
4 结果分析
5 结论
