基于混合核极限学习机的多标签学习研究
2019-05-24钱萌唐家康
钱萌 唐家康
(1. 安庆师范大学计算机与信息学院, 安徽 安庆 246133;2. 安徽省高校智能感知与计算重点实验室, 安徽 安庆 246133)
多标签学习是指利用已知的样本标签训练来预测未知样本的标签集[13]。学者们就多标签学习提出了各种算法。其中,Zhang等人提出了一种多层ELM-RBF 分类算法(ML-ELM-EBF)[4]。传统极限学习算法采用的是单层策略,而该算法采用的是多隐含层策略,在性能上有一定优势。传统的ELM算法需要设置隐含层数目,且随机产生偏置和权值,由此会导致不可预期的结果波动。Luo等人使用核函数代替隐含层映射处理多标签问题,以保证并增强算法的稳定性[5-6]。单核函数往往可以满足算法在某一方向上的要求,但是对于其他方向基本上没有好的应对策略。本次研究提出了基于混合核极限学习机的ML-MKELM(ML-Mixtures Kernel Extreme Learning Machine)算法,所使用的混合核函数由RBF核函数与多项式核函数组合而成,克服了极限学习机中单个核函数的局限性。
1 基本理论
1.1 极限学习机理论
传统神经网络处理框架基本上需要进行较多并且复杂的网络参数设置,且难以得出全局最优解,容易陷入局部最优的境况。极限学习机框架是一种在求解单隐含层前馈神经网时非常高效的算法。该框架在第一次运行时,只需要给定隐含层节点数,初始化权值和偏置则随机给出,因为设置参数的简化还带来了泛化性能强、运行速度快的优点[7]。
假设N个不同的样本(xi,ti),其中,xi=[xi1,xi2,…,xin]T,ti=[ti1,ti2,…,tim]T,具有L个隐含节点和激活函数g(x)的单隐含层神经网络,L≤N,形式化定义为:
Hβ=K
(1)
(2)
设:β=[β1,β2,…,βL]T∈RL×d,为输出层权值矩阵;K=[t1,t2,…,tN]T∈RL×d,为样本输出矩阵;H为极限学习机的隐含层输出矩阵,它的第i列表示的是第i个隐含层神经元关于输入x1,x2,…,xN的输出。
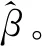
(3)
1.2 核函数
核函数的作用是使非线性变换Ø(·)满足式(4)所示一类函数:
K(xi,xj)=Ø(xi)·(xj)
(4)
核函数的最大作用就是避免高维空间的维数灾难问题,从而使ELM得以实用化。核函数的使用,将线性分类引入到高维特征样本中,使高维空间中的内积运算利用原函数来进行,在特征空间中分类样本集却不增加计算的复杂度。核函数应满足 Mecrer条件[8]。当前研究应用最多的核函数主要有3 类,即多项式核函数、RBF核函数和Sigmoid函数。
多项式核函数:
K(x,xi)=[(x·xi)+1]q
(5)
RBF核函数:
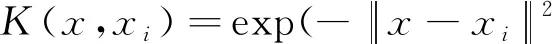
(6)
Sigmoid函数:
K(x,xi)=tanh(v(x·xi)+c)
(7)
以上各式中,q、σ、c均为常数参数,可根据具体问题选取合理的参数值。
核函数的种类主要分为局部核函数与全局核函数。RBF函数是一种局部核函数,它对数据中存在的噪声有着较好的抗干扰能力;但其抗干扰能力具有很强的局部性,其参数决定了函数作用范围有限,缺乏全局抗干扰能力。多项式函数是一种全局核函数,它一般允许相距很远的数据点对核函数产生影响。多项式核函数的参数q取值越大,映射的维度越高,计算量就会越大。当q过大时,由于学习的复杂性过高,易出现过拟合现象。因此,考虑将两者结合起来,构造一种新的兼具两者共同优点的混合核函数,应用于极限学习机中。
1.3 混合核函数
局部核函数的学习能力明显强于全局核函数,而其泛化能力则相对较弱。可结合二者优势来构造一种兼顾学习能力和泛化能力的混合核函数(Mixed Ernel Function),以提升极限学习机的分类性能。由核函数的构成条件可知,二者混合后依然满足Mecrer条件,基于此提出以下新的混合核函数:
Kmix=λKpoly+(1-λ)KRBF
(8)
式中,参数λ是用来调节多项式核函数和RBF核函数在混合核函数中贡献值的常数,通过实验得出,一般为 0.50~0.99 。这里还需要确定最优混合系数,且当λ值较大时 (例如取0.98),更能体现混合核函数的性能。为了保证混合核函数具有更好的学习能力和泛化能力 ,RBF核函数中的σ2应该取值0.01~0.50,多项式核函数中的q值一般取1或2 。
2 多标签学习
2.1 多标签学习的定义
通常,应用传统的单标签学习无法对真实世界对象的多语义性、概念复杂性进行处理,也无法满足目前机器学习的高要求。在此,建立多标签学习框架。该框架中,可对任意一个对象的某一特征向量进行描述,然后根据特征向量对各对象进行精准分类,赋予类别标签。
在这种多标签框架下,我们用(xi,yi)表示一个样本集中的输入输出对。其中,yi是二进制向量(yi1,yi2,…,yiq),yij代表第i个样本的第j个标签,yij=0表示该类别为负,yij=1表示该类别为正。假设一个问题的类别标签有蓝天、白云、大海,那yi就是一个三维的行向量(yi1,yi2,yi3)。如果输入图片只有蓝天和白云,则yi=(1,1,0)。这便是多标签学习的定义。
2.2 多标签学习评价指标
在多标签学习评价中,常使用以下5 种评价指标:海明损失(Hamming Loss)、1-错误率(One-Error)、覆盖率(Coverage)、排序损失(Ranking Loss)、平均精度( Average Precision)。
(1) 海明损失。海明损失(Hamming Loss)是用来表示没有能够被正确分类的标签的情况。当该指标的数值为0时,算法结果最优,即该指标数值越小表示算法性能越好。其算式为:
(9)
式中Δ代表两个集合之间的对称差异。
(2) 1-错误率。1-错误率(One-Error)是评估对象最高排位标记没有被正确标记的次数。当该项指标数值为0时,性能最优。其算式为:
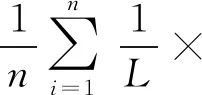
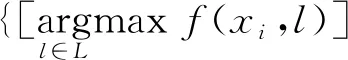
(10)
式中实值函数f(xi,l)对应多标签分类器h(x)。
(3) 覆盖率。覆盖率是评估对象序列中所需标记数达到覆盖全部标记的指标,该项数值越小表示算法性能越好。其算式为:
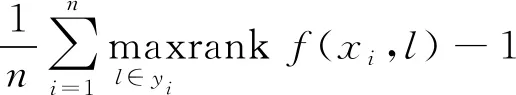
(11)
(4) 排序损失。排序损失是评估对象非属标记的排位高于所属标记的次数。当该项数值为0时为最优。其算式为:
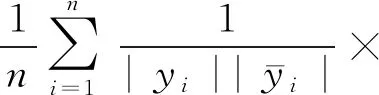
|{(l,l)|f(xi,l1)≤
(12)
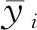
(5) 平均精度。平均精度是评估特定标记l∈yi排序的正确标记平均分数。当该项数值为1时最优,该项数值越大表示算法性能越好。其算式为:
(13)
在上述5个指标当中,前4个指标的数值越小,表示算法性能越好;而平均精度的数值越大,说明算法性能越好。
3 多标签学习下的极限学习机
3.1 多标签学习下的极限学习机
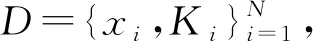
多标签极限学习机的输出函数fi(x)为:
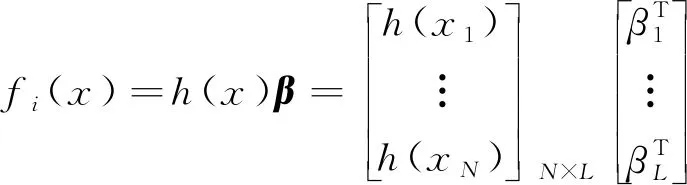
(14)
由式(5)(6)求解输出权值β:
(15)
多标签极限学习机的输出函数为:
(16)
3.2 混合核极限学习机
传统 ELM 算法需设置隐含层节点数,每次需要随机设定权值和偏置,因此计算结果并不稳定,容易受到随机设定值的影响。采用核 ELM 则可以解决这一问题。当映射函数(x)未知时,引入混合核函数,即利用RBF核函数和多项式核函数构造的混合函数Kmix=λKpoly+(1-λ)KRBF代替特征矩阵运算HHT。
Ωelm=HHT:Ωelm(i,j)=h(xi,xj)
(17)
k(xi,xj)=λKpoly+(1-λ)KRBF
(18)
(19)

3.3 混合核极限学习机的多标签学习算法
(2)输出。预测分布K算法如下:
①初始化正则参数C,混合核参数λ、q、σ;
②for多标签训练集Sxi∈D;
③计算核矩阵Ωtrain,Ωtrain=Ωelm(i,j)=h(xi,xj);
④end;
⑦计算核矩阵Ωtest,Ωtest=Ωelm(i,j)=h(xi,xj);
⑧end;
⑩P←f(x*)。
4 多标签学习实验方案及结果分析
为了验证本算法的有效性,实验中采用了几种在多标签学习中被广泛使用的数据集(见表1)。
4.1 实验方案
实验硬件平台配置为Intel(R) core(TM)i5-6300HQ 3.2GHz CPU,8G RAM,软件为Matlab2016a。为了减少随机误差的产生,对于每一种算法用相同的数据集进行 10 折交叉实验,最后实验得到的评价指标求取平均值。将5个评价指标记为 HL、OE、CV、RL 和 AP。
4.2 实验结果
对照5种现有算法,分别以5种评价指标进行比较,实验结果如表 2 — 表8 所示。其中,表2、表3分别是酵母基因与自然场景数据集实验结果,表4 — 表8 是雅虎网页数据集的实验结果。
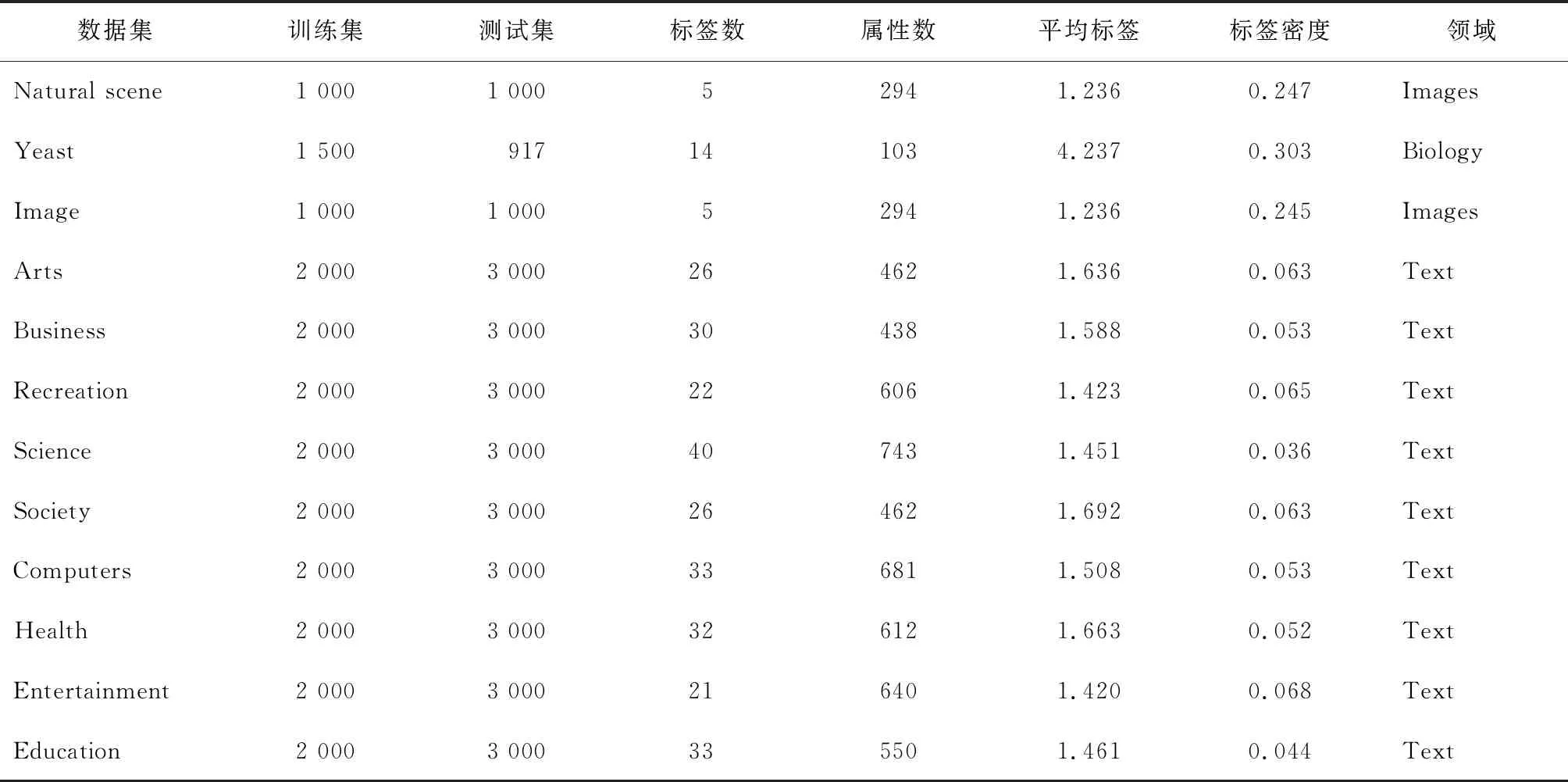
表1 数据集特征描述
注:数据来自http://mulan.sourceforge.net/datasets-mlc.html。
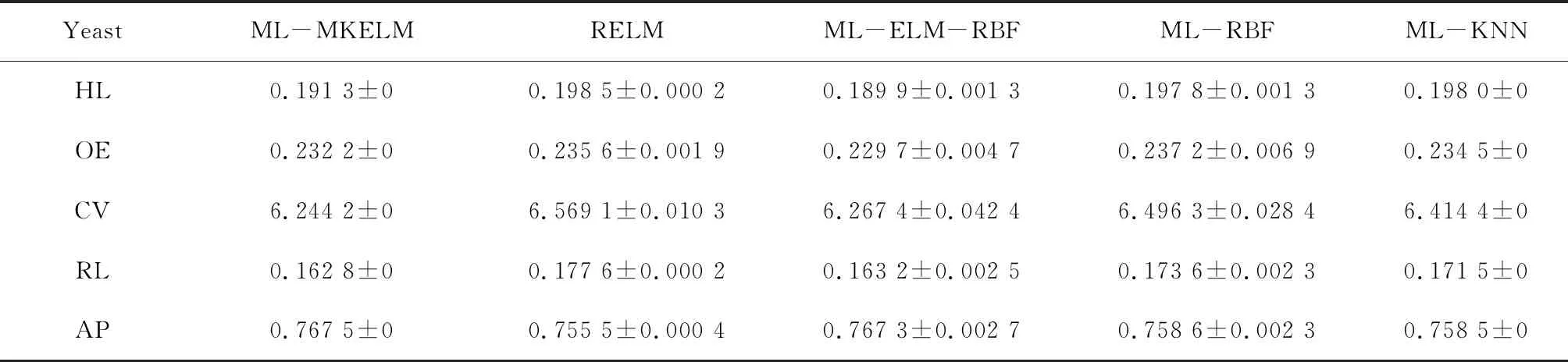
表2 酵母基因数据集测试结果
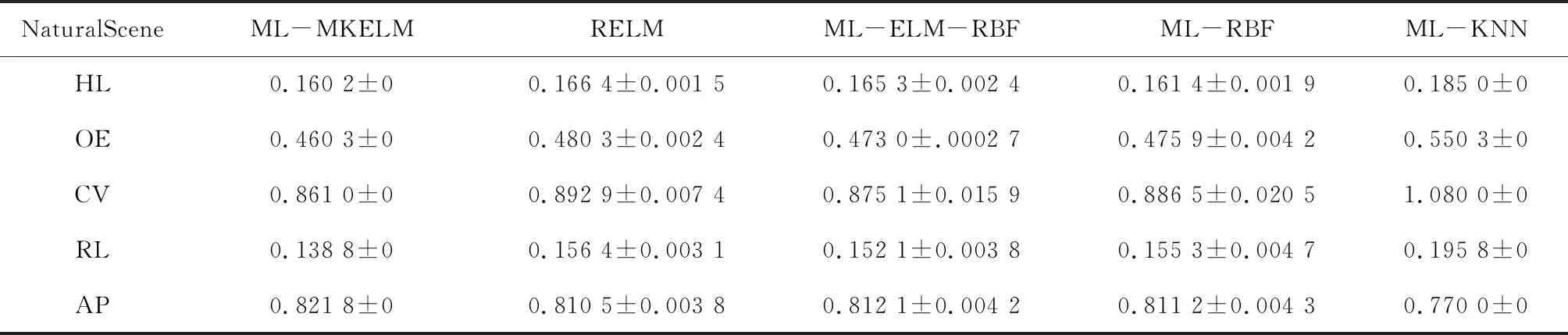
表3 自然场景数据集测试结果
酵母基因数据集与自然场景数据集测试结果显示,ML-MKELM算法在覆盖范围、排名损失和平均精度方面全部取得最优结果。
在表4中,ML-ASRKELM算法在 Business、Education、Entertainment、Society、Image 数据集上的指标最优,其他数据集指标稍差。在表 5中,ML-MLELM算法只在Business数据集上为第3,在其他剩余的9个数据集的表现上均为最优。在表6中,ML-MKELM算法在 Computers、Entertainment、Health、Recreation、Image 数据集上覆盖率测试指标性能最优,在Arts、Business、Education、Recreation、Science、Society数据集上性能排第2。在表 7中,ML-MKELM算法在Arts、Business、 Computers、Entertainment、Recreation、Image 数据集上,排序损失测试结果指标性能最优,在Education、Recreation、Science、Society数据集上性能排第2。在表8中,ML-MKELM 算法在各个数据集上的平均精度测试指标性能均为最优。
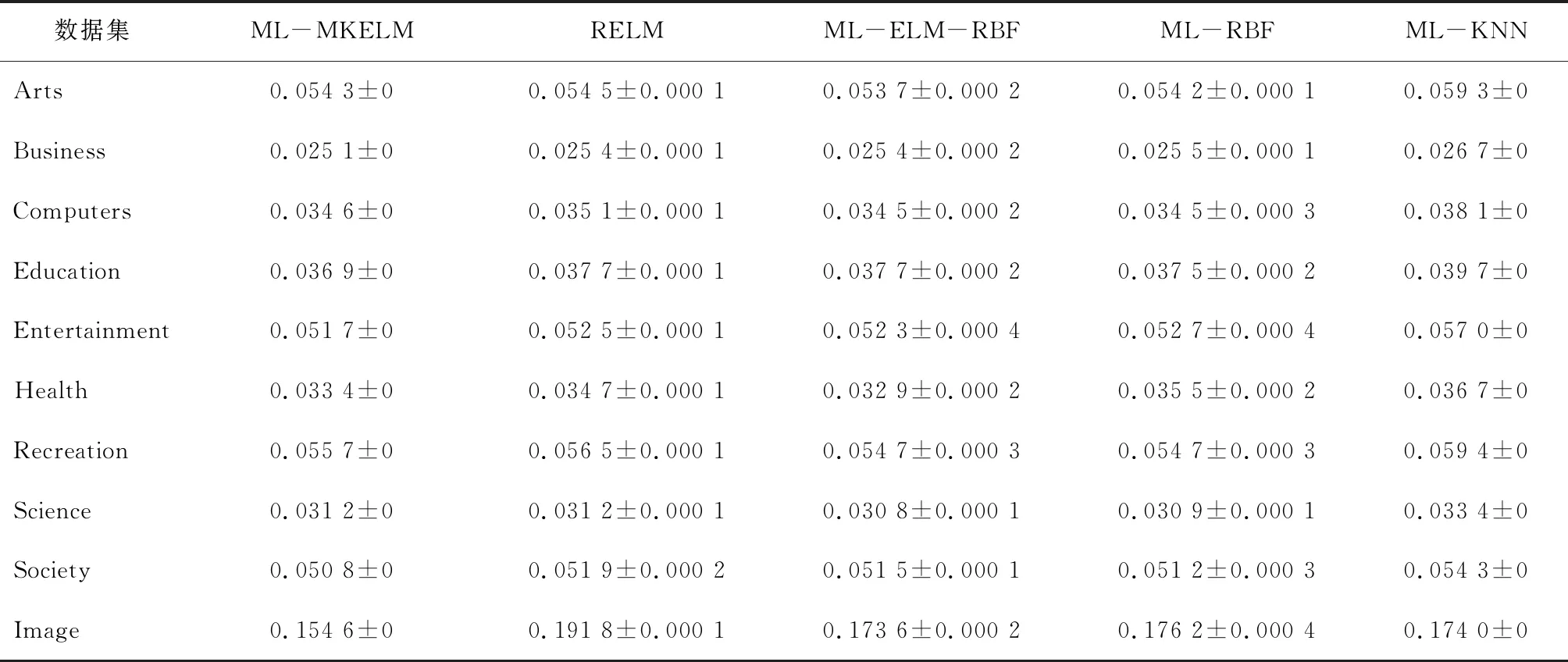
表4 雅虎网页数据集海明损失测试结果
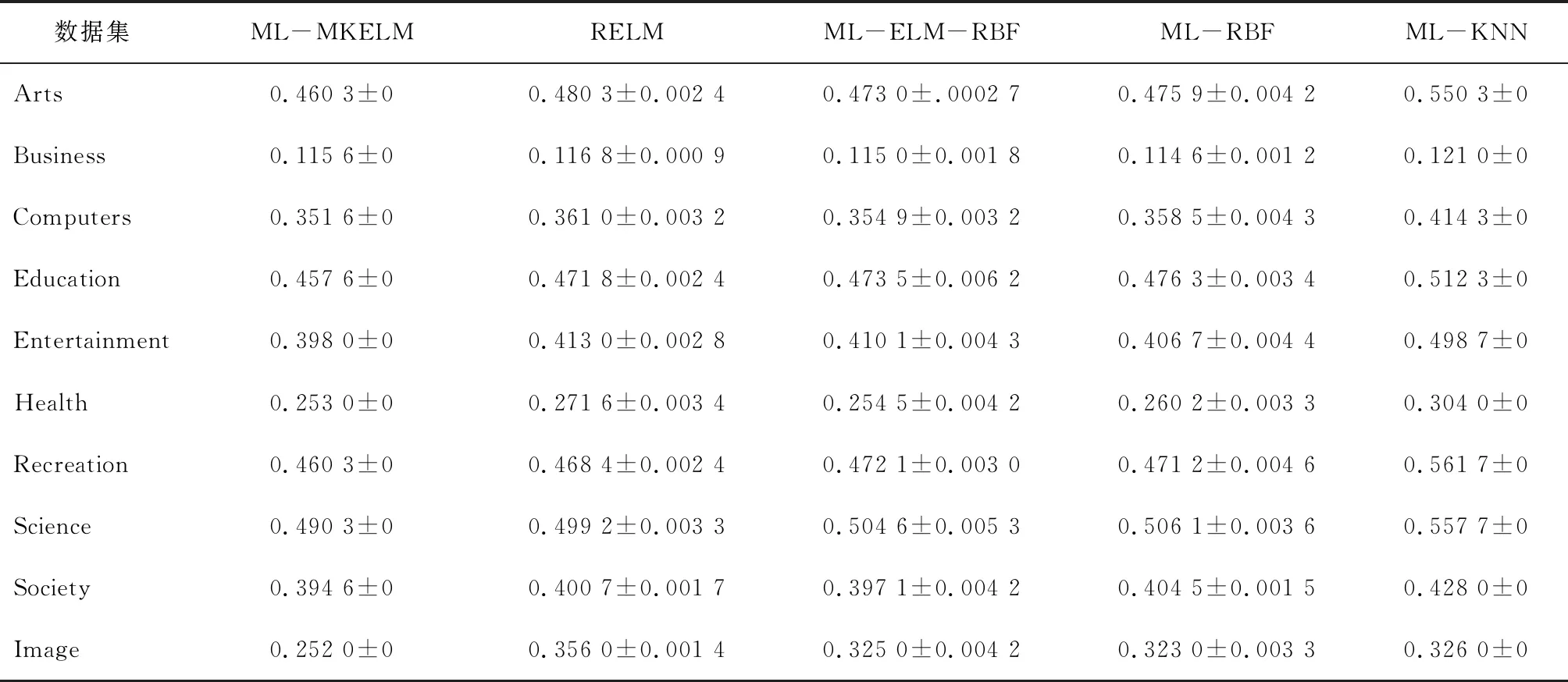
表5 雅虎网页数据集 1-错误率测试结果
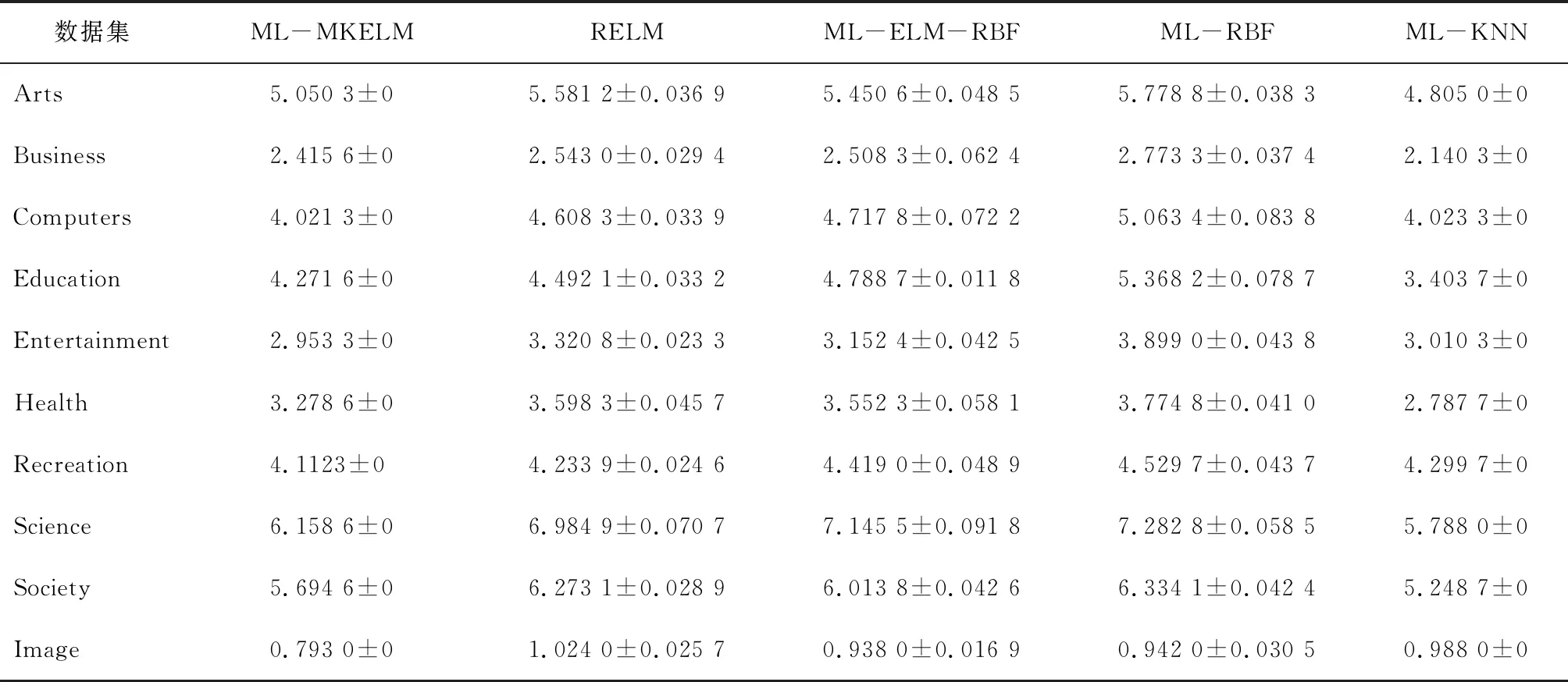
表6 雅虎网页数据集覆盖率测试结果
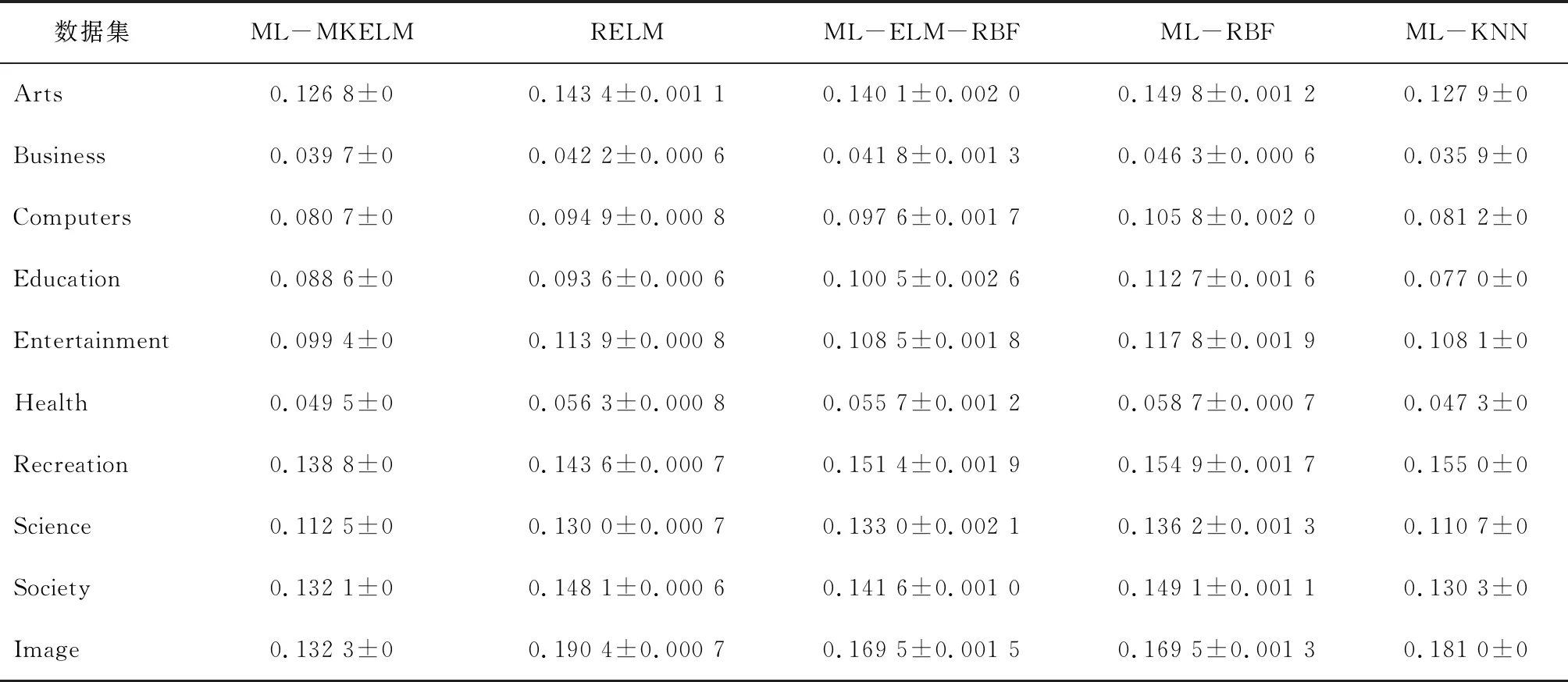
表7 雅虎网页数据集排序损失测试结果
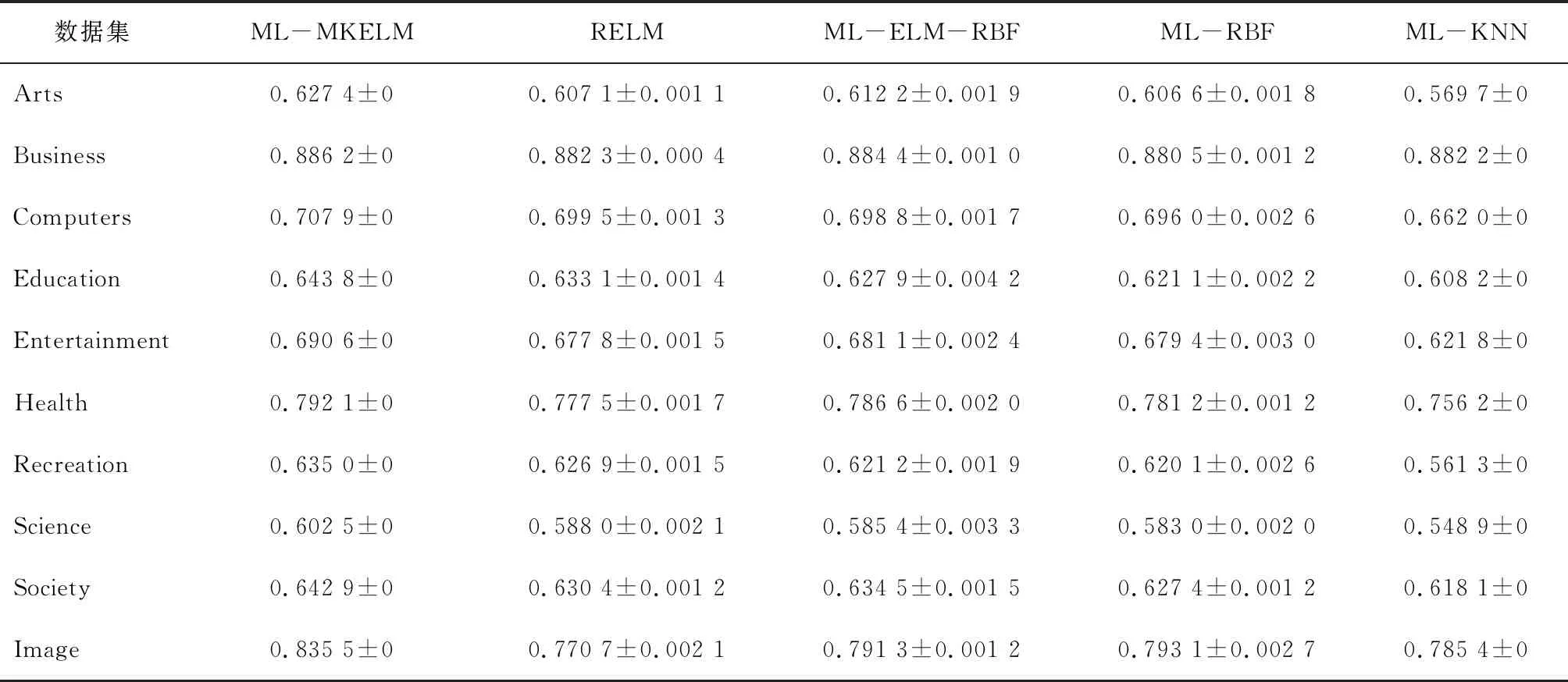
表8 雅虎网页数据集平均精度测试结果
4.3 统计检验
对于每种算法,都有20种实验对比结果(4种对比算法,5种评价指标)。本次提出的ML-MKELM算法,各指标性能良好,有40%的比例与其他算法无明显差异。根据不同的指标来对比算法性能,如图1所示。其中,ML-MKELM与ML-RBF相比,在AP指标上无明显的性能差异。ML-MKELM与ML-RBF、ML-KNN相比,在HL指标上无明显的性能差异。ML-MKELM与ML-RBF、ML-ELM-RBF相比,在CV指标上无明显的性能差异。ML-MKELM与ML-RBF相比,在OE指标上无明显的性能差异。ML-MKELM与ML-RBF、ML-KNN相比,在RL指标上无明显的性能差异,有60%的比例优于其他算法。对于ML-RBF算法,有60%的比例在统计指标上与其他算法无明显的性能差异,有30%的比例优于其他算法。对于ML-ELM-RBF算法,有65%的比例在统计指标上与其他算法无明显的性能差异,有5%的比例优于其他算法。
5 结 语
在本次针对极限学习机中核函数的研究中,考虑不同核函数的优势,将多项式核函数和RBF核函数进行组合,提出基于混合核的多标签学习算法。在极限学习机算法中通过混合核函数将特征映射到高维空间,对原标记空间建立模型预测未知样本的标记。实验表明,采用混合核计算效率高、鲁棒性强,能够有效提升多标签分类的性能,算法具有较好的稳定性,但是核函数在不同数据集上的效果并不相同。如何针对数据集提出更加有效的混合核极限学习机算法,将是今后学习机研究的重要方向。
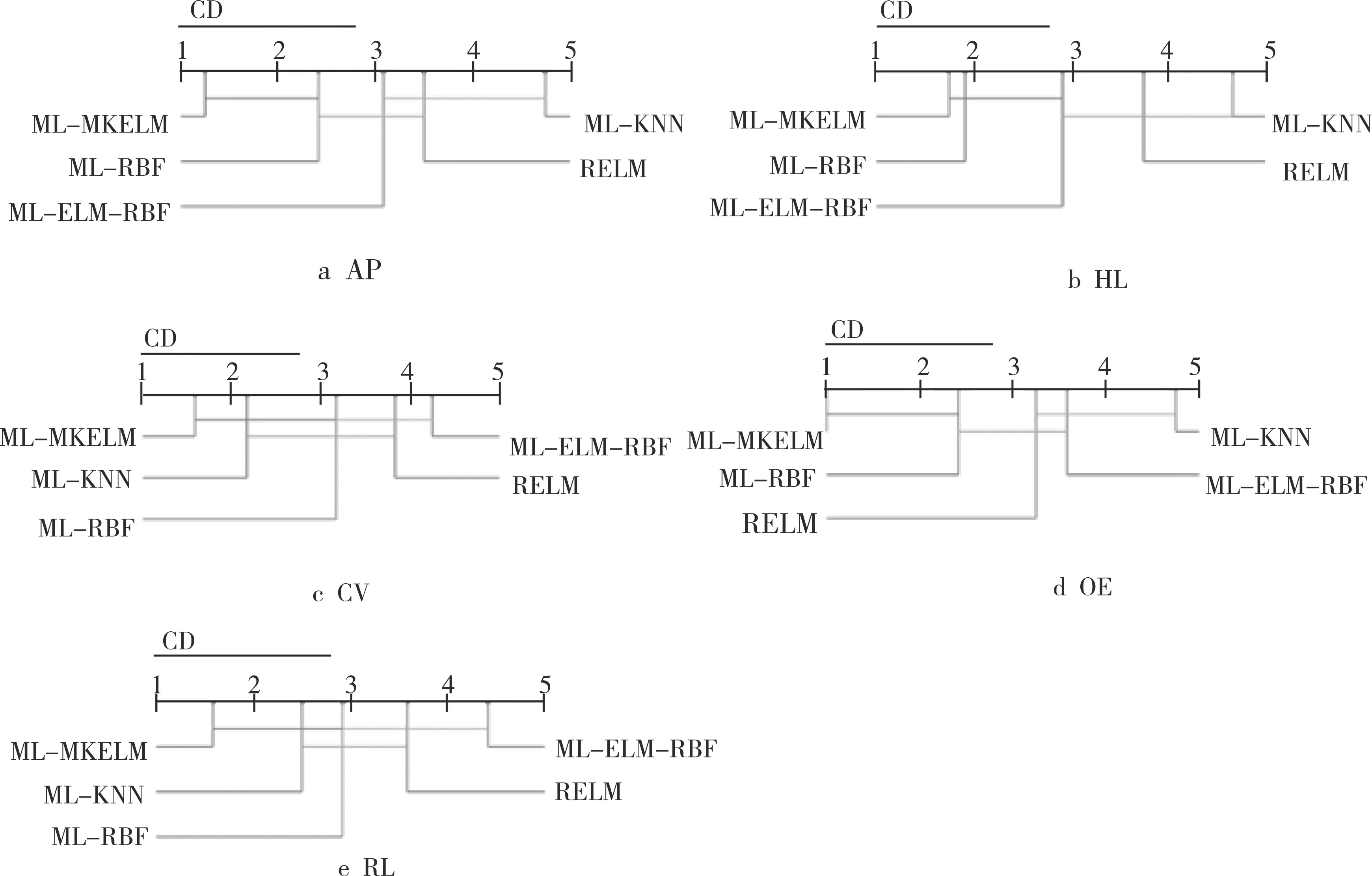
图1 算法综合性能比较
