基于增强Tiny YOLOV3算法的车辆实时检测与跟踪
2019-05-24后士浩胡超超
刘 军,后士浩,张 凯,张 睿,胡超超
基于增强Tiny YOLOV3算法的车辆实时检测与跟踪
刘 军,后士浩,张 凯,张 睿,胡超超
(江苏大学汽车与交通工程学院,镇江 212013)
针对深度学习方法在视觉车辆检测过程中对小目标车辆漏检率高和难以实现嵌入式实时检测的问题,该文基于Tiny YOLOV3算法提出了增强Tiny YOLOV3模型,并通过匈牙利匹配和卡尔曼滤波算法实现目标车辆的跟踪。在车载Jetson TX2嵌入式平台上,分别在白天和夜间驾驶环境下进行了对比试验。试验结果表明:与Tiny YOLOV3模型相比,增强Tiny YOLOV3模型的车辆检测平均准确率提高4.6%,平均误检率减少0.5%,平均漏检率降低7.4%,算法平均耗时增加43.8 ms/帧;加入跟踪算法后,本文算法模型的车辆检测平均准确率提高10.6%,平均误检率减少1.2%,平均漏检率降低23.6%,平均运算速度提高5倍左右,可达30帧/s。结果表明,所提出的算法能够实时准确检测出目标车辆,为卷积神经网络模型的嵌入式工程应用提供了参考。
车辆;机器视觉;模型;车辆检测;车辆跟踪;Tiny YOLOV3算法;卡尔曼滤波
0 引 言
研究表明,驾驶员的驾驶行为是引发交通事故的主要因素[1],因此通过车载视觉传感器进行实时准确的车辆目标检测与跟踪,并在此基础上对车辆目标进行测距有利于发现潜在危险,从而及时向驾驶员发出警告或采取主动控制车辆制动、转向等措施以避免交通事故的发生[2-4]。车辆检测与跟踪是实现智能车辆和高级驾驶辅助系统环境感知的重要环节。
近年来国内外对车辆检测和跟踪算法的研究取得了一些进展,主要表现在基于卷积神经网络的车辆检测算法[5-7]和基于相关滤波的车辆跟踪算法[8-9]。Girshick等[10-12]提出了一系列基于卷积神经网络的通用目标检测算法,从区域提名、特征学习和构建分类器的三步法改进到基于anchor-box的端到端检测方法,在视觉目标检测领域取得了具有突破性意义的研究成果,例如Yang等[13]、宋焕生等[14]基于文献[12]中Faster R-CNN卷积神经网络提出了针对道路车辆的检测方法。李琳辉等[15]提出了一种基于车底阴影自适应分割算法的卷积神经网络分类候选分割区域的车辆检测方法。Lee等[16]提出了一种基于多尺度特征选择的卷积神经网络和Adaboost分类器的车辆检测方法。刘军等[17]提出了一种利用Haar-like特征训练的Adaboost级联分类器识别前方车辆并通过卡尔曼滤波算法对检测的车辆进行实时跟踪的方法。Danelljan等[18-19]提出了一系列基于判别相关滤波器先估计目标的最佳位置,再估计目标尺度的跟踪算法,对存在大尺度变化的目标取得了较好的跟踪效果。纪筱鹏等[20]提出了一种融合车辆轮廓拐点特征信息的扩展卡尔曼滤波车辆跟踪方法,改善了存在重叠遮挡时的车辆跟踪效果。
上述车辆检测和跟踪算法,一方面,基于深度学习的视觉车辆检测方法尤其是卷积神经网络,检测精度取得了很大提高[21],但由于车辆检测算法的复杂性往往需要利用昂贵的计算资源才可以实现实时检测,成为深度车辆检测算法商业化的瓶颈[22]。另一方面,车辆跟踪算法通常利用初始化的车辆位置估计车辆状态或者建立表观模型预测在连续视频帧中该车辆出现的位置,降低了每帧车辆检测的耗时,而面对复杂多变的交通环境,如车辆的快速移动、光照变化、道路环境干扰以及车辆在不同距离时的尺度变化等,使得车辆跟踪算法的鲁棒性面临挑战[23]。因此,如何实现实时鲁棒的车辆检测跟踪算法是一个亟需解决的工程问题。
针对车辆检测跟踪算法实时性和准确性难以两全的矛盾,本文在Tiny YOLOV3算法基础上提出了增强Tiny YOLOV3模型,在删减卷积层参数的同时,有效增强网络中小目标的语义信息,结合车辆检测框与跟踪框的重叠度(intersection-over-union,IoU)和匈牙利匹配算法提出卡尔曼滤波车辆跟踪算法,并将融合的检测跟踪算法在NVIDIA Jetson TX2嵌入式开发板上搭建实车试验平台,对本文提出的车辆检测和跟踪方法进行验证试验,以期实现实时车辆检测跟踪,有效缓解车辆检测跟踪的实时性和准确性矛盾。
1 车辆检测算法
1.1 Tiny YOLOV3模型简介
YOLO、YOLOV2和YOLOV3算法是Joseph等[24-26]提出的通用目标检测模型,Tiny YOLOV3是YOLOV3模型的简化,并且融合了最新的特征金字塔网络[27](feature pyramid networks,FPN)和全卷积网络[28]( fully convolutional networks,FCN)技术,模型结构更简单,检测精度更高。
Tiny YOLOV3算法模型网络主要由卷积层和池化层构成,如图1所示,网络中层的命名规则由其类别和在网络中第几次出现的编号构成,例如conv5表示网络中的第5个卷积层,maxpool1表示网络中的第1个最大池化层,upsample1表示网络中的第1个上采样层,网络中每层的输出特征图尺寸表示为“分辨率宽×分辨率高×通道数”,“+”表示特征图在通道维度的连接(concatenate)操作,“●”表示上采样(upsample)操作。池化层是一种图像下采样操作,虽然会减少卷积特征层的参数,加快模型运算速度,但是会对上一层的卷积特征图造成语义信息的损失。另一方面,浅层的卷积特征感受野包含的背景噪声小,对小目标具有更好的表征能力。另外,当目标被遮挡时,只存在目标的局部特征,由于浅层的卷积层通常对目标的局部或者小目标较为敏感,因此需要增加网络浅层的特征输出层,同时增加目标局部特征学习的样本,从而加强对遮挡目标和小目标的识别能力。

图1 Tiny YOLOV3模型的网络结构 Fig. 1 Network architecture of Tiny YOLOV3 model
1.2 增强Tiny YOLOV3模型
为了进一步说明Tiny YOLOV3模型由于没有合理利用网络浅层输出的特征信息而导致检测层对小目标不敏感的现象,以分辨率为416×416像素大小的输入图片数据为例,对网络中浅层卷积特征图的结构进行了研究,并分别对conv3、conv4和conv5层的感受野进行了可视化[29],如图2所示。由图2可知,conv4层包含表征小目标更有效的语义信息,而conv3层感受野太小,不能表征图2a中的车辆目标,conv5层则感受野太大,包含过多的背景噪声干扰,不利于小目标车辆的表征。
因此,为了强化Tiny YOLOV3模型浅层的卷积特征,提高上下层的语义信息和小目标的检测性能,同时为了更好的利用conv4层包含的语义信息,对Tiny YOLOV3模型的网络结构进行改进,将Tiny YOLOV3模型的maxpool3层修改为conv4层,增加conv5层将conv4层的特征通道维度压缩以减少无效参数;同时在Tiny YOLOV3模型的基础上增加一层上采样层upsample2,将conv6和upsample2在通道维度上进行连接操作,作为特征金字塔的一个特征图层,特征金字塔网络由原来的13×13和26×26像素变成13×13、26×26和52×52像素的3层结构。图3为增强Tiny YOLOV3模型结构,网络层的命名规则与图1一致。

a. 输入图像b. 卷积层3的增强感受野 a. Input imageb. Receptive field of conv3 c. 卷积层4的增强感受野d. 卷积层5的增强感受野 c. Receptive field of conv4d. Receptive field of conv5
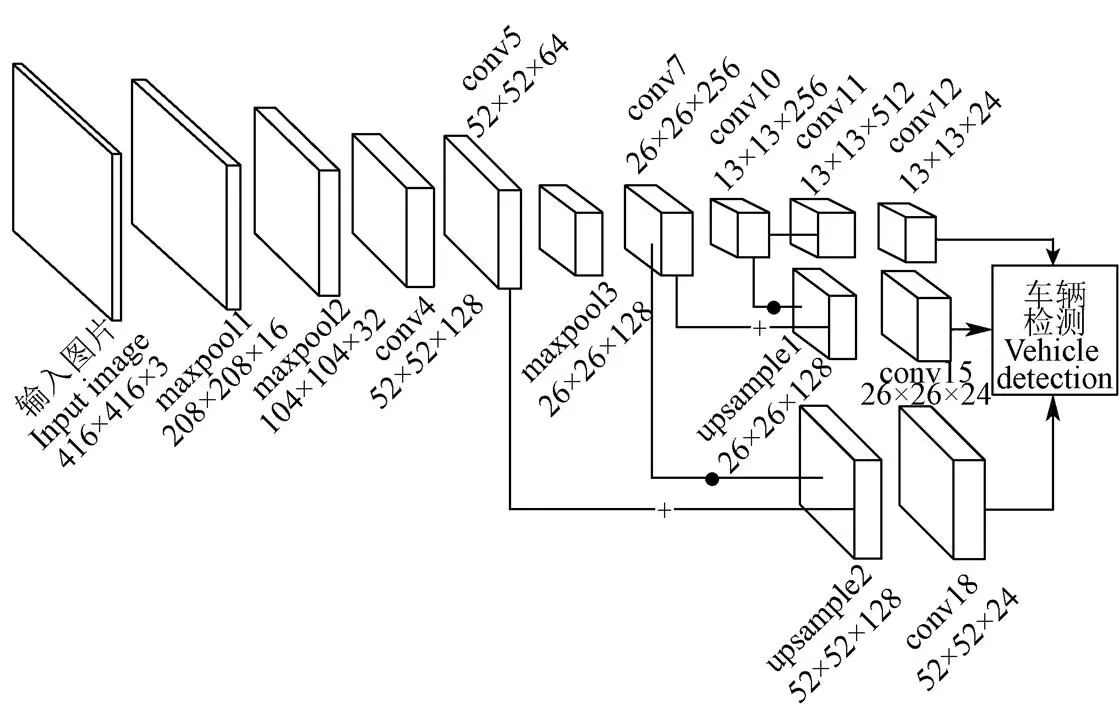
图3 增强Tiny YOLO V3模型的网络结构Fig.3 Network structure of enhancement-Tiny YOLO V3 model
改进之后,新增的conv18层上需要生成车辆目标候选框,与Tiny YOLOV3算法相同,可通过k-means聚类算法确定anchor个数并生成新的anchor尺寸,图4为平均重叠度随着聚类数变化的关系曲线。由图4可知,随着聚类数的增大,平均重叠度逐渐增大,但是当聚类数大于9之后,平均重叠度上升很小而基本趋于稳定,因此增强Tiny YOLOV3模型采用9个anchor,并通过-means算法确定相应的尺寸。
增强Tiny YOLOV3和Tiny YOLOV3模型对图2a车辆的检测效果对比如图5所示。由图5可知,增强Tiny YOLOV3模型成功检测出右后方被沙石遮挡的小汽车,而Tiny YOLOV3模型漏检了该目标,结果与图 2一致。

a. Tiny YOLOV3模型b. 增强Tiny YOLOV3模型 a. Tiny YOLOV3 modelb. Enhanced Tiny YOLOV3 model
2 基于车辆检测的跟踪算法
2.1 基于IoU的匈牙利匹配算法
图6为车辆检测和跟踪包围框示意图。如图6所示,矩形框表示车辆检测包围框,矩形框表示车辆跟踪包围框,跟踪框和检测框的重叠度由式(1)表示,重叠度越接近1,说明检测框和跟踪框的重叠度以及相关性越大。
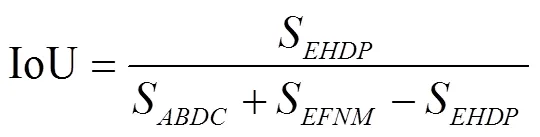
式中S表示面积,下标表示包围框,即表示包围框EHDP的面积。
匈牙利匹配算法根据IoU的先验关系建立车辆检测包围框与车辆跟踪包围框之间的匹配对应关系,由式(2)表示。


式中thresh为试验中确定的经验值,用于去除相关性很低的检测框和跟踪框之间的匹配。
2.2 基于卡尔曼滤波算法的车辆跟踪
卡尔曼滤波算法是一种自回归优化算法,广泛运用于动态测量系统中。视频流中的车辆检测通常存在着包围框的跳动、车辆漏检和误检等问题,因此本文运用卡尔曼滤波相关理论对车辆跟踪进行优化。由于车载摄像机满足高帧率,视频序列之间车辆目标的位置变化很小,可视为匀速运动[30]。因此假设视觉车辆检测跟踪系统随时间变化是线性相关的,满足式(4)和(5)。

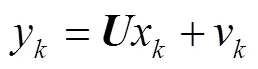
1)预测部分:根据系统的车辆检测包围框,当连续min帧及以上检测出该目标时,说明该目标是非误检车辆,需要根据车辆检测包围框坐标预测对应的车辆跟踪包围框坐标和其协方差矩阵,由式(6)和(7)表达。
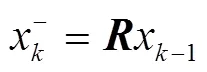
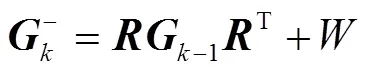
2)更新部分:当系统中建立了车辆检测包围框和跟踪包围框的匹配关系且连续丢失的车辆检测目标不超过max帧,说明车辆目标没有真正丢失,需要对车辆跟踪包围框的坐标及其协方差矩阵进行每帧更新,由式(8)~(10)表达。
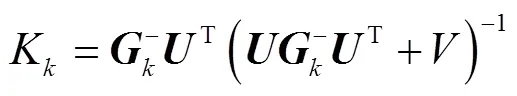
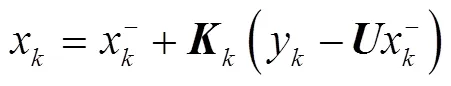

3 车辆检测跟踪效果验证与分析
通过搭建一个实车试验平台,验证本文提出的车辆检测和跟踪方法。试验设备主要包括奥迪试验车、12 mm焦距镜头、OV10635芯片的USB摄像头、Jetson TX2开发板和显示屏,其中Jetson TX2为试验平台的处理核心。如图7所示,摄像头安装在车内后视镜位置。
外界环境的稳定情况直接影响着测量精度和数据的可靠性。因此,在实际测量过程中,应尽可能控制好外界条件,避免外界干扰,建议采取的措施有:(1)避开卫星周期性的误差影响,选取信号强的时间段进行测量;(2)选取适宜的天气进行测量,降低气候变化、温差变化、大风大雨等天气对测量的影响;(3)使用稳定性强的电源进行设备供电,同时配备备用电源,谨防电源电压不稳对测量精度产生不必要的影响。

图7 实车试验平台 Fig. 7 Real vehicle test platform
在车辆检测方面,本文中的车辆目标包含所有类型的轿车、卡车以及公共汽车等机动车辆,通过安装在试验车前方、侧方以及后方的车载摄像机采集江苏省各市区和高速道路交通的行驶视频,并通过智能标注方法建立如图8所示的训练数据集,分为白天和夜晚2种主要场景,总共50 000张图片,通过基于Tensorflow后端的Keras框架实现增强Tiny YOLOV3和Tiny YOLOV3模型,并通过配有NVIDIA GTX 1060显卡的计算机训练出增强Tiny YOLOV3和Tiny YOLOV3模型的权重,根据网格搜索算法设置网络中的最优超参数为初始学习率0.001,权重衰减系数为0.000 5,训练策略采用动量项为0.9的动量梯度下降算法,训练过程中使用与Tiny YOLOV3相同的图像扩充方法以及多尺度训练策略。

a. 夜晚前车b. 白天前车 a. Preceding vehicles at nightb. Preceding vehicles in daytime c. 夜晚相邻车辆d. 白天相邻车辆 c. Adjacent vehicles at nightd. Adjacent vehicles in daytime
在车辆跟踪方面,试验中根据网格搜索算法设置经验参数的最优值分别为min=2,max=8,thresh=0.3,式(11)~(12)为跟踪系统的参数矩阵和初始化值。


Algorithm vehicle tracking Inputs: Initialize: For to : For : where If where : Add to Remove from Else if where : Add to Remove from For and and : Start new track with and insert into For : Add to Return
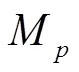




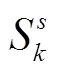
在白天和夜间分别进行了8组试验,试验中TN的值设为10 000,分别计算Tiny YOLOV3车辆检测模型、增强Tiny YOLOV3车辆检测模型以及本文车辆检测跟踪算法模型(融合算法模型)的评价指标值,结果如表1所示。由表1可知,与Tiny YOLOV3车辆检测模型相比,增强Tiny YOLOV3车辆检测模型的平均准确率提高了4.6%,平均误检率减少了0.5%,平均漏检率降低了7.4%,算法平均耗时增加了43.8 ms/帧。增强Tiny YOLOV3模型通过浅层输出的特征金字塔层增加了候选框的数量,所以网络的漏检率指标得到了显著改善,同时伴随着浅层特征的强化和利用,提高了模型的平均准确率,但增加了计算量,所以提升车辆检测性能的同时增加了算法的平均耗时,这也为下一步本文车辆检测跟踪算法模型的运用创造了良好的条件。在增强Tiny YOLOV3车辆检测模型基础上加入本文跟踪算法之后,相比Tiny YOLOV3车辆检测模型,本文的融合算法模型平均准确率提高了10.6%,漏检率降低了23.6%,且误检率降低了1.2%,误检主要有2方面原因,一是由于没有连续2帧出现误检而真正减少了检测器的误检,二是跟踪过程中在车辆真正消失的时候,车辆的跟踪图像没有被及时删除而造成误检,2个因素叠加在一起,本文融合算法的误检率仍然降低了1.2%,相对于Tiny YOLOV3车辆检测模型的运算速度提升显著,平均运算速度为33.4 ms/帧,比Tiny YOLOV3车辆检测模型的运算速度快5倍左右,可达30帧/s。

表1 不同车辆检测与跟踪模型的性能对比Table 1 Performance comparison between different vehicle detection and tracking models
注:M为平均准确率,%;M为平均误检率,%;M为平均漏检率,%;M为平均运算速度,ms·帧-1。
Note:Mis the mean precision rate, %;Mis the mean detection error rate, %;Mis the mean missing detection rate, %;Mis the mean operation speed, ms·帧-1.
图9为增强Tiny YOLOV3模型与Tiny YOLOV3模型对实际交通环境车辆的检测效果对比,可以看出增强Tiny YOLOV3模型对小目标车辆具有更好的检测效果。

a. 原图1 a. Raw image 1b. 原图2 b. Raw image 2c. 原图3 c. Raw image 3d. 原图4 d. Raw image 4 e. Tiny YOLOV3模型检测结果1e. Detection result 1 of Tiny YOLOV3f. Tiny YOLOV3模型检测结果2 f. Detection result 2 of Tiny YOLOV3g. Tiny YOLOV3模型检测结果3g. Detection result 3 of Tiny YOLOV3h. Tiny YOLOV3模型检测结果4h. Detection result 4 of Tiny YOLOV3 k. 增强 Tiny YOLOV3检测结果1k. Enhanced Tiny YOLOV3 result 1l. 增强 Tiny YOLOV3检测结果2 l. Enhanced Tiny YOLOV3 result 2m. 增强 Tiny YOLOV3检测结果3m. Enhanced Tiny YOLOV3 result 3n. 增强 Tiny YOLOV3检测结果4n. Enhanced Tiny YOLOV3 result 4
图10为本文车辆检测跟踪模型的应用效果,第一列为原图,第二列为增强Tiny YOLOV3模型的车辆检测效果图,第三列为本文融合算法模型的检测效果图,可以看出当增强Tiny YOLOV3模型出现漏检和误检时,本文融合算法模型可以根据一定的置信度估计车辆目标的位置,减少误检和漏检现象,在视频序列的车辆检测中具有更好的连续稳定性能。

a. 原图b. 增强Tiny YOLOV3模型c.本文模型 a. Raw imageb. Enhanced Tiny YOLOV3 modelc. Model in this paper
进一步分析可知,增强Tiny YOLOV3模型的性能主要受以下几个因素影响:
1)交通环境的影响。实际行驶过程中的目标车辆经常会出现部分遮挡和光照变化等情形,虽然本文模型对较小和部分遮挡的目标车辆检测提出了改进,但是对于光照严重不足和遮挡面积很大的目标车辆可能会出现漏检。
2)检测模型的影响。增强Tiny YOLOV3模型是在Tiny YOLOV3模型基础上改进的优化模型。但是在训练的过程中,超参数的选择、训练集的大小以及训练的策略都会影响模型的性能,因此模型在训练过程中很难保证达到最优性能。
3)跟踪模型的影响。跟踪系统包含部分经验参数,经验参数的选择具有试验性,对跟踪系统的性能有直接影响;跟踪系统假设目标车辆都是匀速移动,没有考虑车辆的动力学特性,对于快速移动的目标车辆在跟踪过程中会出现轻微的漂移现象。
上述因素中1)属于固有的外部因素,试验中保持不变;2)和3)可以通过优化检测和跟踪模型取得更好的试验性能,车辆检测模型的好坏对本文算法平均准确率有着直接且重要的影响,因此如何保证训练模型取得最优的泛化能力是后期研究的主要内容,尤其是通过一系列的智能搜索算法得到更好的模型泛化性能;另外如何将车辆的动力学特性考虑到跟踪模型中建立更符合实际的运动模型是3)改进的关键。
4 结 论
1)在对Tiny YOLOV3网络的浅层感受野进行可视化分析的基础上,本文对Tiny YOLOV3的浅层语义信息进行强化重构,同时对其进行有效利用,提出了增强 Tiny YOLOV3模型,对小目标车辆的检测具有更好的性能,平均准确率提高了4.6%,平均漏检率、误检率分别降低了7.4%和0.5%。
2)根据车辆检测包围框的位置信息提出了基于重叠度的卡尔曼滤波跟踪算法,提高了车辆检测跟踪系统的准确率和实时性。在增强Tiny YOLOV3模型基础上增加车辆跟踪算法,提出了车辆检测跟踪算法模型(融合算法模型),相比Tiny YOLOV3模型,融合算法模型的平均准确率提高了10.6%,平均漏检率降低了23.6%,平均误检率减少了1.2%,平均运算速度可达30帧/s。试验结果表明,基于增强Tiny YOLOV3模型的目标检测与匈牙利匹配和卡尔曼滤波的目标跟踪算法搭建的嵌入式车辆视觉检测系统能够满足嵌入式智能车辆和高级驾驶辅助系统准确性和实时性的要求,具有较好的工程应用价值。
[1] Mukhtar Amir, Xia Likun, Tang Tongboon. Vehicle detectiontechniques for collision avoidance systems: A review[J]. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(5): 2318-2338.
[2] Song Wenjie, Yang Yi, Fu Mengyin, et al. Real-time obstacles detection and status classification for collision warning in a vehicle active safety system[J]. IEEE Transactions on Intelligent Transportation Systems, 2018, 19(3): 758-773.
[3] 刘庆华,邱修林,谢礼猛,等.基于行驶车速的车辆防撞时间预警算法[J].农业工程学报,2017,33(12) :99-106.Liu Qinghua, Qiu Xiulin, Xie Limeng, et al. Anti-collision warning time algorithm based on driving speed of vehicle[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(12): 99- 106. (in Chinese with English abstract)
[4] 刘军,后士浩,张凯,等. 基于单目视觉车辆姿态角估计和逆透视变换的车距测量[J]. 农业工程学报,2018,34(13):70-76. Liu Jun, Hou Shihao, Zhang Kai, et al. Vehicle distance measurement with implementation of vehicle attitude angle estimation and inverse perspective mapping based on monocular vision[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(13): 70-76. (in Chinese with English abstract)
[5] He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 37(9): 1904-1916.
[6] He Kaiming, Gkioxari Georgia, Dollar Piotr, et al. Mask R-CNN[C]// IEEE International Conference on Computer Vision. IEEE, 2017: 2961-2969.
[7] Manana Mduduzi, Tu Chunling, Owolawi Piusadewale. A survey on vehicle detection based on convolution neural networks[C]// IEEE International Conference on Computer & Communications. IEEE, 2017: 1751-1755.
[8] Henriques Joaof, Caseiro Rui, Martins Pedro, et al. High-speed tracking with kernelized correlation filters[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3): 583-596.
[9] Tang Ming, Feng Jiayi. Multi-kernel correlation filter for visual tracking[C]// IEEE International Conference on Computer Vision. IEEE, 2016: 3038-3046.
[10] Girshick Ross, Donahue Jeff, Darrell Trevor, et al. Region-based convolutional networks for accurate object detection and segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 38(1): 142-158.
[11] Girshick Ross. Fast R-CNN[C]// IEEE International Conference on Computer Vision. IEEE, 2015: 1440-1448.
[12] Ren Shaoqing, He Kaiming, Girshick Ross, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149.
[13] Yang Biao, Zhang Yuyu, Cao Jinmeng, et al. On road vehicle detection using an improved Faster RCNN framework with small-size region up-scaling strategy[C]// Pacific-Rim Symposium on Image and Video Technology. Springer, Cham, 2017: 241-253.
[14] 宋焕生,张向清,郑宝峰,等. 基于深度学习方法的复杂场景下车辆目标检测[J]. 计算机应用研究,2018,35(4):1270-1273. Song Huansheng, Zhang Xiangqing, Zheng Baofeng, et al. Vehicle detection based on deep learning in complex scene[J]. Application Research of Computers, 2018, 35(4): 1270-1273. (in Chinese with English abstract)
[15] 李琳辉,伦智梅,连静,等. 基于卷积神经网络的道路车辆检测方法[J]. 吉林大学学报:工学版,2017,47(2):384-391. Li Linhui, Lun Zhimei, Lian Jing, et al. Convolution neural network-based vehicle detection method[J]. Journal of Jilin University (Engineering and Technology Edition), 2017, 47(2): 384-391. (in Chinese with English abstract)
[16] Lee Wonjae, Dong Sungpae, Dong Wonkim, et al. A vehicle detection using selective multi-stage features in convolutional neural networks[C]// International Conference on Control. IEEE, 2017: 1-3.
[17] 刘军,高雪婷,王利明,等. 基于OpenCV的前方车辆检测和前撞预警算法研究[J]. 汽车技术,2017(6):11-16. Liu Jun, Gao Xueting, Wang Liming, et al. Research on preceding vehicle detection and collision warning method based on OpenCV[J]. Automobile Technology, 2017(6): 11-16. (in Chinese with English abstract)
[18] Danelljan Martin, Häger Gustav, Khan Fahad, et al. Accurate scale estimation for robust visual tracking[C]// 2014 British Machine Vision Conference. BMVA Press, 2014: 1-11.
[19] Danelljan Martin, Häger Gustav, Khan Fahad, et al. Discriminative scale space tracking[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(8): 1561-1575.
[20] 纪筱鹏,魏志强. 基于轮廓特征及扩展Kalman滤波的车辆跟踪方法研究[J]. 中国图象图形学报,2011,16(2):267-272. Ji Xiaopeng, Wei Zhiqiang. Tracking method based on contour feature of vehicles and extended Kalman filter[J]. Journal of Image and Graphics, 2011, 16(2): 267-272. (in Chinese with English abstract)
[21] Lecun Yann, Bengio Yoshua, Hinton Geoffrey. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[22] Liu Wei, Anguelov Dragomir, Erhan Dumitru, et al. SSD: single shot multiBox detector[C]// European Conference on Computer Vision. Springer, Cham, 2016: 21-37.
[23] Smeulders A, Chu D, Cucchiara R, et al. Visual tracking: an experimental survey[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 36(7): 1442-1468.
[24] Joseph Redmon, Divvala Santosh, Girshick Ross, et al. You only look once: Unified, real-Time object detection[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2015: 779-788.
[25] Joseph Redmon, Farhadi Ali. YOLO9000: Better, faster, stronger[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2017: 6517-6525.
[26] Joseph Redmon, Farhadi Ali. YOLOv3: An Incremental Improvement[EB/OL].[2018-04-08].https://arxiv.org/pdf/1804.02767.pdf.
[27] Lin Tsungyi, Dollár Piotr, Girshick Ross, et al. Feature pyramid networks for object detection[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2017: 936-944.
[28] Long Jonathan, Shelhamer Evan, Darrell Trevor. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 39(4): 640-651.
[29] Yosinski Jason, Clune Jeff, Nguyen Anh, et al. Understanding neural networks through deep visualization[EB/OL]. [2015-06-22]. https://arxiv.org/abs/1506.06579.
[30] Bochinski Erik, Eiselein Volker, Sikora Thomas. High-Speed tracking-by-detection without using image information[C]// IEEE International Conference on Advanced Video & Signal Based Surveillance. IEEE, 2017: 1-6.
Real-time vehicle detection and tracking based on enhanced Tiny YOLOV3 algorithm
Liu Jun, Hou Shihao, Zhang Kai, Zhang Rui, Hu Chaochao
(,,212013,)
For intelligent vehicles and advanced driving assistant systems, real-time and accurate vehicle objects detection and tracking through on-board visual sensors are conducive to discovering potential dangers, and can take timely warning to drivers or measures to control vehicle braking and steering systems to avoid traffic accidents by active safety system. In recent years, vehicle detection based on deep learning has become a research hotspot. Although the deep learning method has made a significant breakthrough in vehicle detection precision, it will lead to high missed detection rate of small vehicle targets and rely on expensive computing resources in visual vehicle detection tasks, which is difficult to achieve in embedded real-time applications. Further analysis shows that the main reason for the above problems is that deep convolution neural network cannot reasonably prune network layer parameters, especially cannot reasonably utilize the shallow semantic information. On the contrary, a series of operations at the lower sampling layers will lead to the loss of vehicle information, especially for the small vehicle objects. Therefore, how to effectively extract and utilize the semantic information of small vehicle objects is a problem to be solved in this paper. On this basis, the problem of pruning network layer parameters reasonably was discussed. For the detection algorithm, on the one hand, based on visual analysis of receptive field of Tiny YOLOV3 network shallow layers, the use of shallow semantic information was enhanced by constructing a shallow feature pyramid structure, on the other hand, the shallow down sampling layer was replaced by convolution layer to reduce the semantic information loss of shallow network layers and increase the shallow layer features of vehicle objects to be extracted. Combine the above 2 aspects, the enhanced Tiny YOLOV3 network was proposed. For the tracking algorithm, because of the high frame rate of the vehicle-mounted camera, assuming that the vehicle objects in the adjacent frame moving uniformly without considering the image information, Kalman filter algorithm was used to track the vehicle target, and its observation position was estimated optimally. The proposed enhanced Tiny YOLO V3 network was trained by using 50 000 images collected by the on-board vehicle camera during the day and night. The training strategy included pre-training model, multi-scale training, batch normalization and data augment methods, which same as Tiny YOLOV3 network. On the vehicle Jetson TX2 embedded platform, 8 groups of comparative experiments were carried out with Tiny YOLOV3 model, including day and night traffic scenes. The experimental results showed that compared with Tiny YOLO V3 model,the mean precision rate of the enhanced Tiny YOLOV3 model proposed in this paper was improved by 4.6%, the mean detection error rate was reduced by 0.5%, the mean missing detection rate was reduced by 7.4%, and the mean time consumption was increased by 43.8 ms/frame without tracking algorithm. After adding the vehicle tracking algorithm, the mean precision rate was improved by 10.6%, the mean detection error rate was reduced by 1.2%, the mean missing detection rate was reduced by 23.6%, and the mean operation speed was 5 times faster than that of the Tiny YOLOV3 model, reaching 30 frame/s. The study provides an important guidance for embedded vehicle detection and tracking algorithm application in intelligent vehicles and advanced driving assistant systems.
vehicles; computer vision; models; vehicle detection; vehicle tracking; Tiny YOLOV3 algorithm; kalman filtering
2018-11-22
2019-01-20
国家自然科学基金项目(51275212)
刘 军,教授,博士,主要研究方向为汽车主动安全。 Email:Liujun@ujs.edu.cn
10.11975/j.issn.1002-6819.2019.08.014
TP391;U491.6
A
1002-6819(2019)-08-0118-08
刘 军,后士浩,张 凯,张 睿,胡超超. 基于增强Tiny YOLOV3算法的车辆实时检测与跟踪[J]. 农业工程学报,2019,35(8):118-125. doi:10.11975/j.issn.1002-6819.2019.08.014 http://www.tcsae.org
Liu Jun, Hou Shihao, Zhang Kai, Zhang Rui, Hu Chaochao. Real-time vehicle detection and tracking based on enhanced Tiny YOLOV3 algorithm[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(8): 118-125. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2019.08.014 http://www.tcsae.org
