基于变分模态分解的语音情感识别方法∗
2019-05-22王玮蔚张秀再
王玮蔚 张秀再
(1 南京信息工程大学电子与信息工程学院 南京 210044)
(2 江苏省大气环境与装备技术协同创新中心 南京 210044)
0 引言
在多种通信方式中,语音信号是人与人、人与机器通信最快的自然方法。人类甚至可以从语音交流中感觉到说话人的情绪状态。语音情感是分析声音行为的一种方法,是指各种影响(如情绪、情绪和压力)的指针,侧重于语音的非言语方面。在这种情况下,语音情感识别的主要挑战是提取一些客观的、可测量的语音特征参数,这些参数可以反映说话人的情绪状态。近年来,语音情感识别在人机通信、机器人通信、多媒体检索等领域得到了广泛关注。语音情感识别研究主要是利用语音中的情感和语音特征的统计特性,进行一般定性的声学关联[1−2]。
语音情感识别的主要工作为语音情感特征提取和分类网络模型选择。当前国内外的研究方向多为分类网络模型选择,而情感特征提取方向研究内容较为匮乏,因此,提取有效的语音情感特征也是当前语音情感识别的关键任务。2004年,Ververidis等[3]从能量、基音和语音频谱的动态行为中提取出87个静态特征,并提出了谱平坦度测度与谱中心的比值作为说话人独立的特征,利用帧级特征、基音周期、能量和Mel倒谱系数(Mel frequency cepstral coefficents, MFCC)对性别和情感进行了层次分类。2011年,Sun 等[4]将Teager 能量中提取的小波系数引入到语音情感识别中。2008年,韩一等[5]将MFCC 参数作为特征对语音情感进行识别,也取得了较好的结果。
2011年,He 等[6]首先将经验模态分解(Empirical mode decomposition, EMD)引入到语音情感识别中。2015年,Sethu等[7]利用EMD将语音进行分解,以分解得到的固有模态函数(Intrinsic mode functions, IMF)分量进行语音分类。Shahnaz 等[8]将EMD 和小波分析相结合,通过选取主导IMF 分量,不仅减少了计算负担,而且避免包含冗余或信息量较少的数据,得到了80.55% 的语音情感识别准确率。向磊[9]将集合固有模态函数(Ensemble empirical mode decomposition, EEMD)和希尔伯特(Hilbert)边际谱相结合,有效地解决了传统EMD分解带来的模态混叠问题。
为了提高语音情感特征识别性能,解决基于EMD 和EEMD算法的语音情感特征模态混叠和计算量过大的缺点,本文将变分模态分解(Variational modal decomposition, VMD)方法引入到语音情感特征提取中[10],提出基于VMD 分解的语音情感特征,采用极限学习机(Extreme learning machine,ELM)将本文特征与语音基音特征、谱特征作为分类特征进行实验。结果表明,相较于传统语音特征以及基于EMD、EEMD的语音情感特征,本文提出的特征能更好地表示语音的情感特征,提高了语音情感的识别准确率。
1 特征提取
1.1 VMD分解
VMD 方法与反复循环剥离进行模态函数分解的EMD 方法不同,VMD 通过对变分模型的最优极值求解,实现自适应地获取IMF,在迭代过程中不断更新每个IMF分量的中心频率和带宽[10−11]。
IMF分量表达式为

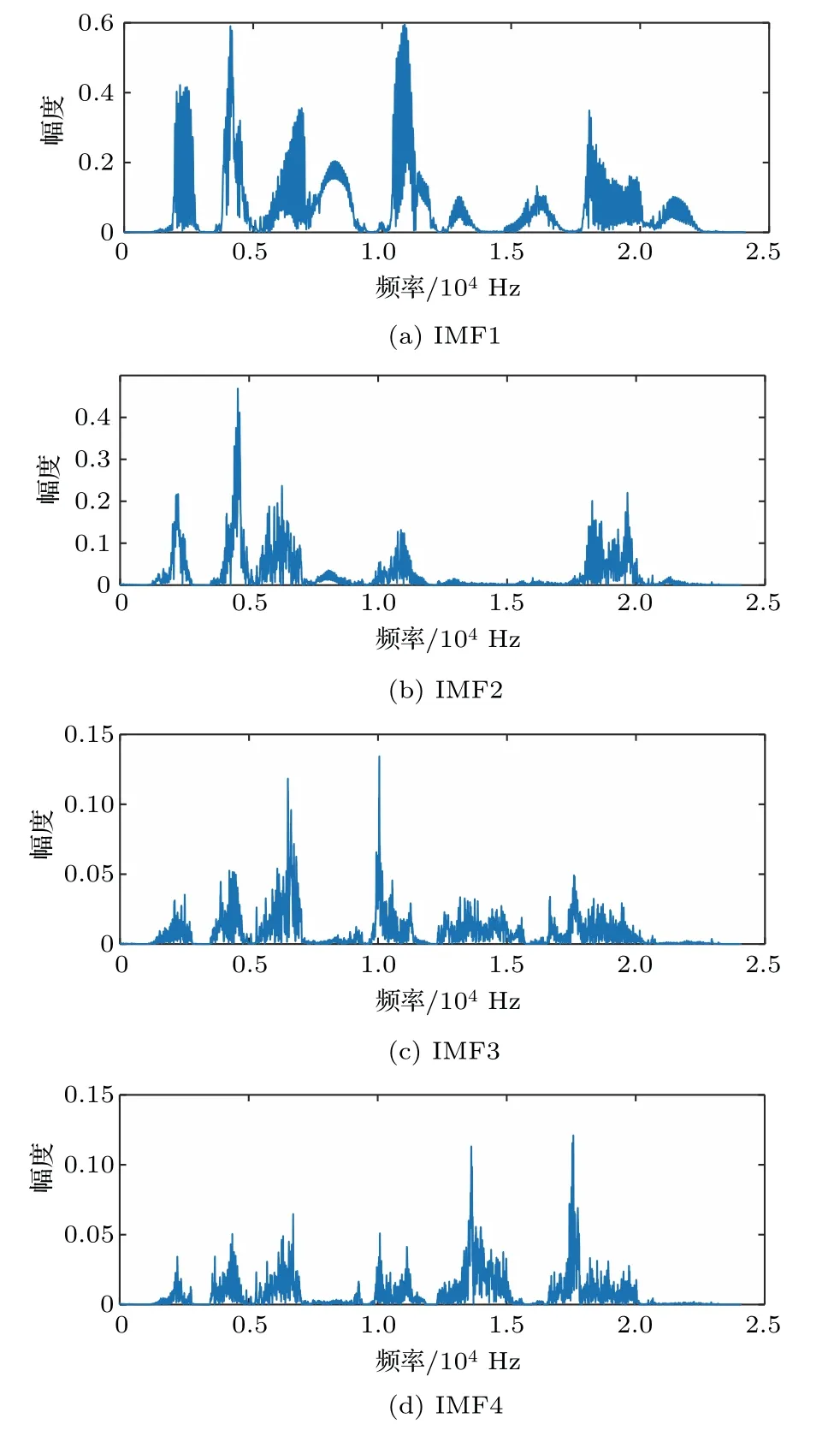
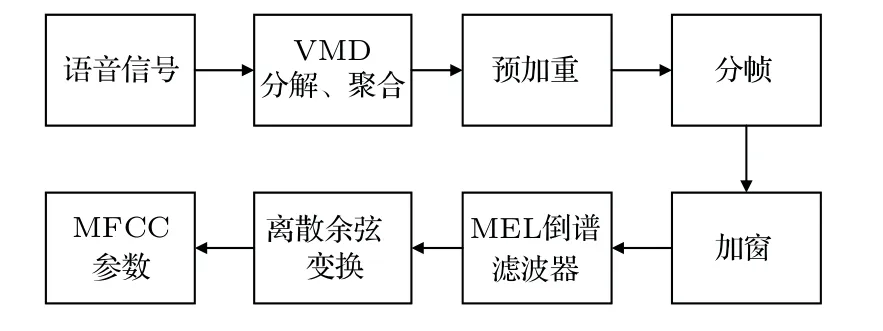
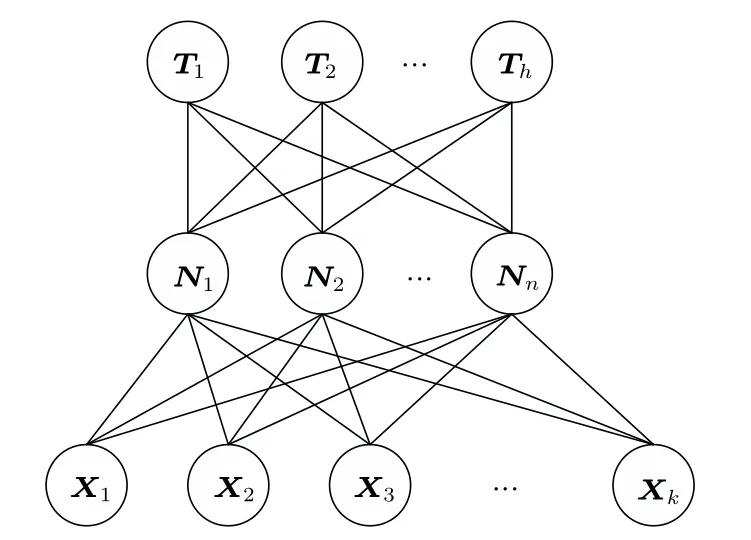
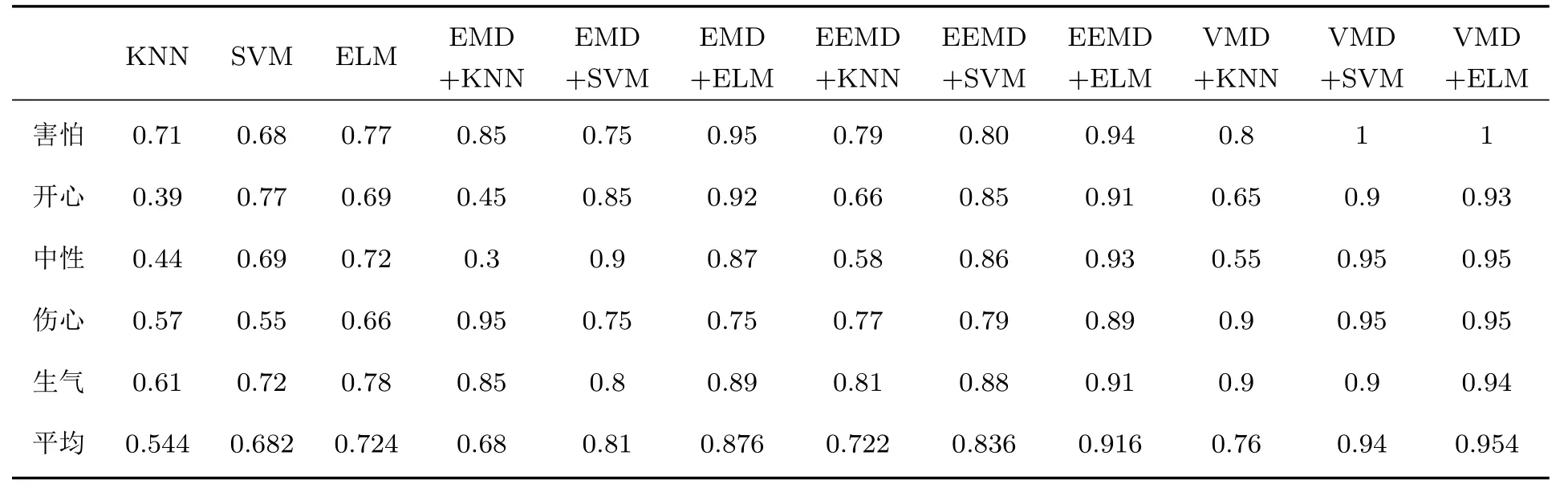
其中,uk(t)为第k个IMF分量,0 约束条件为 式(2)中,{uk}:={u1,··· ,uK},uk(t)记为uk,{uk}为分解到的K个有限带宽的IMF 分量的集合,uk表示分解到的第k个有限带宽的IMF 分量,∂t为微分算子,δ(t)为狄利克来函数,j为虚数符号,e 为自然常数,f(t)为约束函数,{ωk}:={ω1,··· ,ωK},{ωk}为K个IMF 分量所对应的中心频率的集合,ωk表示第k个IMF 分量所对应的中心频率,∥·∥22表示范数;通过拉格朗日函数求该约束条件下的最优解,生成的拉格朗日表达式为 式(3)中,L({uk},{ωk},λ)为拉格朗日函数,α为惩罚系数,λ(t)为拉格朗日乘子,表示内积。 采用乘法算子交替的方法求式(3)的鞍点,就得到IMF 分量,求解过程中unk+1的值会不断更新。公式(4)取得最小值时,unk+1与unk的误差小于预设值,unk+1为第n+1次迭代的第k个IMF分量,其表达式为 式(4)中,X为uk的集合,wn+1k为第n+1次迭代的第k个IMF分量的中心频率,表示将第n+1次迭代的除了第k个IMF 分量之外的分量进行求和。 利用Parseval/Plancherel 傅里叶等距变换可将式(4)转换到频域进行计算,可得到各模态的频域更新,就可将中心频率的取值问题转换到频域,得到中心频率的更新方法;同时更新λ,表达式如下: 1)因指导教师精力有限,在讲解和示范过程中,认真听讲的学生少,围观的学生多,而且不同教师的授课效果也有差异; 每个IMF 分量的频率中心及带宽在模型求解过程中,随着迭代次数不断更新,直到满足迭代条件即可根据相应的频域特征得到K个IMF 分量。该分解模式可以自适应地对信号频带进行切割,有效避免模态混叠,且IMF 分量被固定划分为K个,消除了EMD 算法大量的无效分解分量,使得计算量大幅下降[10]。 对语音信号进行VMD 分解得到IMF 分量后,为了得到能对语音情感分析的特征,利用IMF 分量为平稳信号的特点[6],对VMD 各分量进行Hilbert变换,得到IMF 的瞬时频率和幅值[12],特征提取流程如图1所示。 式(8)中,Hk(t)为IMF 分量的Hilbert 变换函数,uk(t′)为基于时间常数t′的第k个IMF分量。 图1 VMD-HT 特征提取流程图Fig.1 VMD-HT feature extraction flow chart 式(9)中,Zk(t)为解析函数为第k个IMF 分量的瞬时幅值为相位,uk(t)为第k个IMF分量,Hk(t)为第k个分量的Hilbert变换。 式(9)中,Zk(t)的相位表达方式突出了Hilbert变换的物理意义,是基于时间序列形成的一个振幅和相位调制的三角函数。则Hilbert 谱的瞬时频率定义为[8] 其中,θk表示第k个IMF分量的相位。 然后,对于语音信号第k个IMF 分量uk(t)的幅值ak(t)和瞬时频率Wk(t),计算uk(t) 的平均瞬时频率(Mean instantaneous frequency, MIF)。根据获得的各IMF分量的MIF及幅值,计算原始信号的MIF表示为[10] 将各IMF 分量的平均瞬时频率、幅值以及原始信号的瞬时频率作为该语音信号的VMD-HT特征。 图2 各IMF 信号的边际谱图Fig.2 The marginal spectrum of each IMF signal MFCC由Stevens在1937年提出[11],MFCC参数是基于人耳对不同频率声音有不同敏感度的特点提出的,揭示了人耳对高频信号的敏感度低于低频信号的特点。语音信号由频率f转换到Mel 尺度的表达式为[12−13] 语音信号通过VMD 分解后,剔除余波分量,再重新聚合,对聚合信号提取MFCC 参数,即得到VMD-MFCC 特征。在将信号进行VMD 分解之后,提取MFCC参数的过程分为数步,流程如图3所示。 MFCC 参数提取采用一组基于Mel 尺度的三角带通滤波器,将语音信号转换到频域后,对语音信号进行滤波处理,使语音信号遵循Mel 尺度的衰减特性。滤波器组对频域信号进行切分,每个频段产生一个对应的能量值。本实验中滤波器个数取24,因此可得到24个能量值。 图3 MFCC 参数提取流程图Fig.3 MFCC parameter extraction flow chart 由于人耳对声音的感知程度具有非线性特性,用对数形式描述更好。因此,对能量值进行对数处理,再倒谱分析。 根据MFCC定义,对对数能量进行反傅里叶变换,再通过低通滤波器获得低频信号。使用离散余弦变换(Discrete cosine transform, DCT)可以直接获取低频信息,DCT 与离散傅里叶变换相似,但只有实数部分,该过程可表示为 式(13)中,Ek为第k个滤波器的对数能量值;Q为三角滤波器个数,一般取22∼26;m为当前计算的MFCC 特征参数的维数,L取12,12 维MFCC 特征参数足以代表一帧语音特征[14]。 以EMODB 中害怕情感语句为例,以256 个点为一帧,帧移为64,Mel 倒谱滤波器取24个,预加重系数为0.95,计算12 阶MFCC 参数如图4所示。采用本文方法对语音进行分解后提取的MFCC 参数如图5所示。由图4可知,直接提取的MFCC 特征参数每一帧之间差别较大,经过处理后的语音信号的MFCC特征参数每帧之间差别明显降低,可以使MFCC特征更易于通过分类器进行识别。 图4 FEAR 语句12 阶MFCC 参数Fig.4 FEAR statement 12th order MFCC parameters 图5 FEAR 语句12 阶VMD-MFCC 参数Fig.5 FEAR statement 12th order VMD-MFCC parameters 语音情感识别中最常用的分类器是支持向量机[15−16](Support vector machine, SVM)、人工神经网络[11,17−18](Artificial neural network, ANN)、K 最近邻算法[12](K-nearest neighbor, KNN)、Elman 神经网络[12]、高斯混合模型[19](Gaussian mixture model, GMM)长短时神经网络[20]( Long short-term memory, LSTM)和隐马尔可夫模型[10](Hidden Markov model, HMM)。在众多人工神经网络中,将快速模型学习与准确预测能力相结合的极限学习机,应用于多模式情感识别和计算语言学,以适度的计算资源获得了最好的结果[21−23]。 最初,ELM作为单隐层前馈网络的一种快速学习方法——反向传播的另一种方法提出[21]。与传统的神经网络和机器学习算法相比,ELM 方法学习速度快、泛化性能好。因此,本实验采用ELM 方法进行情感特征分类,基本ELM的体系结构如图6所示。 图6 ELM 基本结构图Fig.6 ELM basic structure 式(14)为ELM 神经网络处理输入数据的公式,式中g(x)为激活函数,Wi= [wi,1,wi,2,··· ,wi,n]T为输入权重,βi为输出权重,bi为第i个隐藏单元的偏置,Xj是输入的数据,·表示内积。 单隐层神经网络学习目标是使输出误差最小,表示为 即存在βi、Wi和bi,使得 以矩阵的形式表示为 式(17)中,N为隐含层节点输出,β为隐含层到输出层的权重系数,T为训练所需要得到的期望结果。为了对隐含层神经元进行训练,得到βi、Wi和bi的解为 式(18)中,i= 1,··· ,L,该式用最小化损失函数表示为 传统的一些基于梯度下降法算法(如反向传播(Back propagation, BP)、多层感知器(Multi-layer perception, MLP))可以用来求解这样的问题,但这些学习算法需要在迭代过程中调整所有参数。而ELM 算法的输入层权重Wi和隐含层bi在初始化时已被随机产生且唯一,因此隐含层的输出矩阵N就被确定,只需要调整隐含层到输出层的权重系数βi,对该系数的训练可转化为求解一个线性系统Nβ=T。输出权重可由式(20) 确定, 式(20)中,N†是矩阵的Moore-Penrose广义逆。可证明求得解的范数最小且唯一,且ELM 的计算速度较基本梯度下降算法快数倍[21]。 本实验基于德国BerlinEMODB语音情感数据库和美国RAVDESS 视听情感数据库,下面对两种数据库进行简单的介绍。 德国BerlinEMODB 语音情感数据库是最为常用的公开语音情感数据库之一,它是由德国柏林工业大学录制的德语情感数据库,由10位专业演员(5男5女)参与录制,得到包含生气、无聊、厌恶、害怕、高兴、中性和悲伤等7类基本情感的800条语句。对于文本语料的选择遵从选择语义中性、无明显情感倾向的日常语句,且语音在专业录音室中录制而成。经过20 个说话人的听辨测试,最终得到494 条情感语句用于实验评价[11]。 美国RAVDESS 视听情感数据库是为北美英语的科学家和治疗师提供一个可自由使用的动态视听语音录音库,由24名演员(12 男,12女)参与录制,他们用北美英文口音说话和唱歌,语音中包含各种情绪。包含7356 个情感中性陈述的高品质视频录音,用一系列情绪说出和唱出。演讲集包括8 个情绪表达:中性、冷静、快乐、悲伤、愤怒、恐惧、惊讶和厌恶。歌曲集包括6 种情绪表达:中性、冷静、快乐、悲伤、愤怒和恐惧。除了中性以外的所有情绪都表现为两种情绪强度:正常和强烈。有2452 个独特的发声,所有这些都有三种模式格式:完整的音频-视频(720p,H.264)、纯视频和纯音频(波形)。该数据库已经在涉及297名参与者的感知实验中得到验证[24]。 传统语音情感特征为基频特征、韵律谱特征以及部分非线性特征[10],本文将VMD-MFCC、VMD-HT 和传统语音情感特征相结合作为实验选取的特征,称为底层特征,底层特征描述见表1。 表1 底层特征描述Table1 Description of the underlying features 为了验证VMD-HT 和VMD-MFCC 特征在语音情感识别中的应用效果,取两种语音情感数据集中共有的生气、伤心、害怕、开心、中性五种情感,取10名说话人的情感语句各50句。其中,随机抽取40句用来做训练,10句用来测试,进行10次实验,实验结果以10次实验识别率的平均值作为评估指标,整个实验与说话人无关。采用KNN(K=5)、SVM(核函数设置为sigmoid)、ELM 作为分类方法,输入为91 维底层情感特征,并采用Sethu V 的EMD 特征和向磊的EEMD 特征进行对比实验,对比实验中的输入特征中25∼76 和80∼91 维分别替换为基于EMD和EEMD的特征。实验结果见表2、表3。 由表2、表3可知,ELM 分类准确度要高于KNN 和SVM;在两个数据集中,加入VMD 特征的ELM 方法分别在中性和害怕情绪的识别率达到最高,而开心情感识别率在两个数据集中都为最低。相较于传统语音情感特征,基于EMD 的特征通过选取主导IMF 分量,不仅减少了计算负担,而且避免包含冗余或信息量较少的数据,有效地提升了语音情感识别性能;基于EEMD 的特征,由于避免了EMD分量的模态混叠问题,识别率在EMD 特征的基础上有所提升;在加入VMD 特征之后,由于VMD 分解方法不仅解决了EMD 方法模态混叠的问题,还提升了IMF 信号的分解完整性,因此,基于VMD 的特征在三种分类方式上的识别度都高于基于EMD 和EEMD 的特征。以EMODB 为例,害怕的识别率提高了2%,中性的识别率提高了5%,生气的识别率提高了2%。因此,将VMD 特征用于语音情感识别,可以有效提高识别准确率,且将VMD 特征和ELM分类器结合,有更好的识别效果。 表2 EMODB 数据集分类实验结果(识别率)Table2 EMODB data set classification experiment results 表3 RAVDESS 数据集分类实验结果(识别率)Table3 RAVDESS data set classification experiment results 根据语音信号非平稳、非线性特点,本文将变分模态分解(VMD)引入到语音情感特征识别中,通过Hilbert 变换和提取MFCC 参数,组成新的语音情感非线性联合特征。将该特征应用于语音情感识别,实验将基于VMD 提取的VMD-MFCC 特征和VMD-HT特征与传统语音情感特征相结合,采用极限学习机进行语音情感分类。实验结果表明,相较于基于EMD 和EEMD 的情感特征,基于VMD 的语音特征结合极限学习机进行语音情感分类的方法,具有更高的识别率。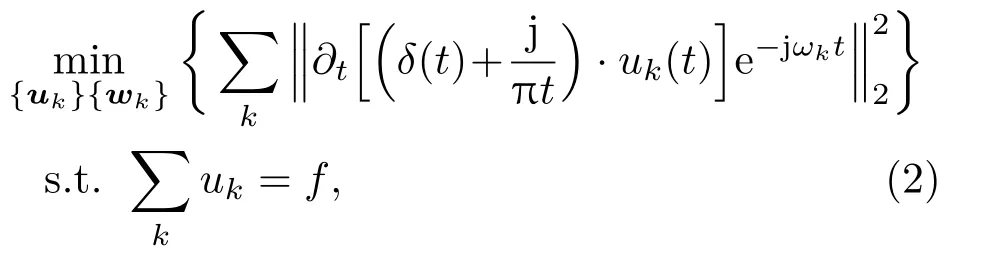
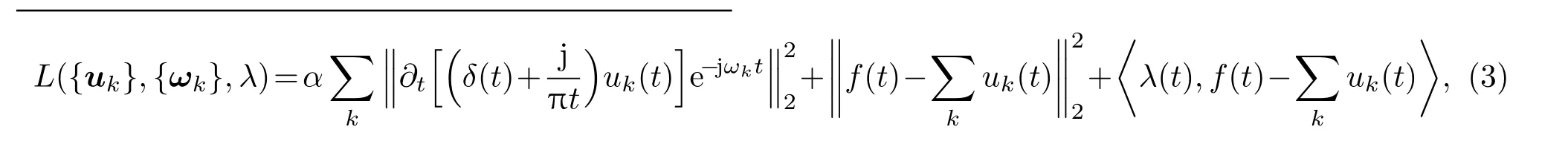
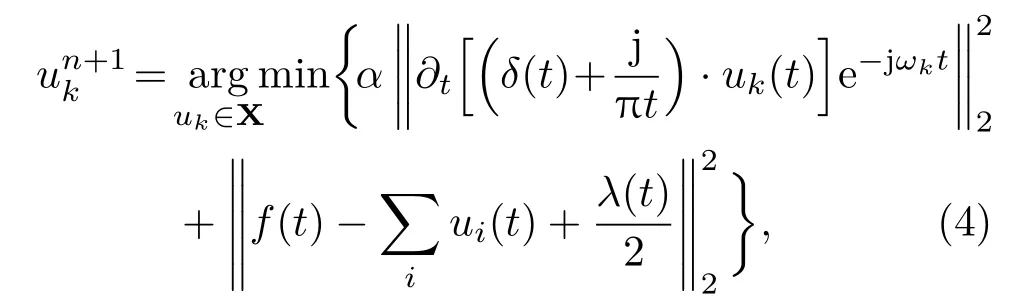

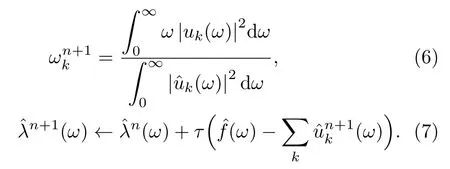
1.2 基于VMD-HT的语音情感特征
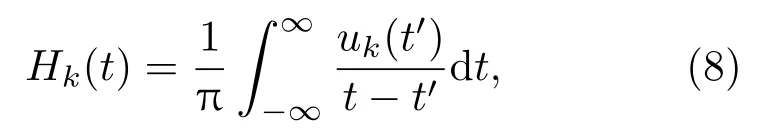

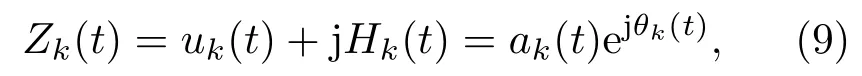
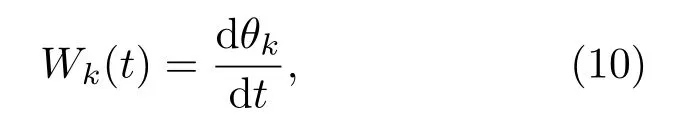
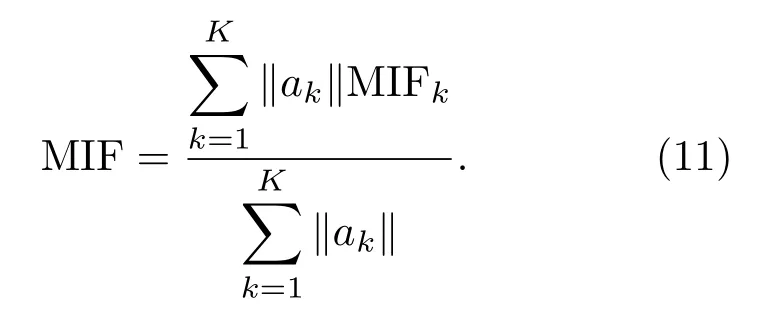
1.3 基于VMD-MFCC的语音情感特征
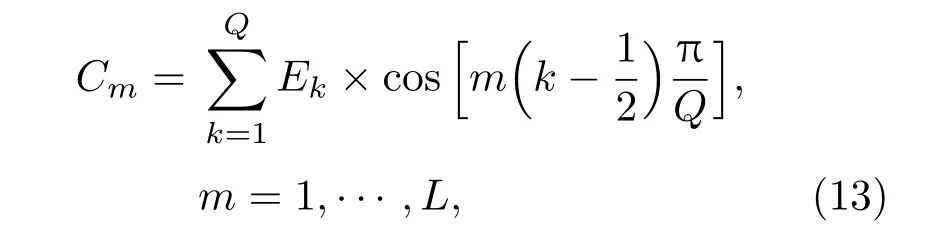


2 分类算法
2.1 分类算法简介
2.2 ELM简介


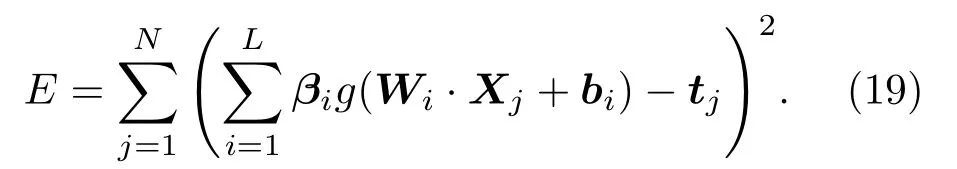

3 实验验证
3.1 数据集选取
3.2 特征选取

3.3 仿真结果

4 结论
