基于半监督学习方法的磨煤机故障预警
2019-05-22欧阳春明
肖 黎,罗 嘉,欧阳春明
基于半监督学习方法的磨煤机故障预警
肖 黎1,罗 嘉1,欧阳春明2
(1.广东电科院能源技术有限责任公司,广东 广州 510080; 2.广东电网有限责任公司电力科学研究院,广东 广州 510080)
火电机组磨煤机运行环境恶劣,故障频发,对磨煤机故障进行预警,评估设备在相关故障状态下的剩余可用时间,对提高火电机组运行安全具有重要意义。本文提出一种基于半监督学习方法的磨煤机故障预警技术。首先采用DBSCAN聚类将磨煤机的历史运行数据划分为正常状态和故障状态,分配类标记并统计设备剩余可用时间,然后采用随机森林方法建立基于类标记序列的磨煤机运行状态分类预警模型,对磨煤机运行数据进行状态预测,根据类标记序列判断故障类别和对应的设备剩余可用时间。将此方法用于某火电厂磨煤机实际运行数据,并与k-近邻算法、朴素贝叶斯和线性判别分析的预警模型进行比较,结果表明:本文方法优于其他预警模型,可准确标记磨煤机不同故障发展阶段,也能较准确地给出磨煤机剩余可用时间。
磨煤机;DBSCAN聚类;故障预警;随机森林;半监督学习方法;预测
火电厂中磨煤机因结构复杂、运行环境恶劣多变,导致其故障频发。中国电力企业联合会2016年全国电力可靠性指标报告中指出:与给水泵、送风机、引风机和高压加热器相比,磨煤机因发生故障而停运的时间偏多。磨煤机故障类型较多,按照故障成因磨煤机故障可分为两类:一类是磨煤机发生磨损和老化造成;另一类是磨煤机运行参数偏离正常值造成,这是磨煤机停运的主要原因。对于因参数偏离正常运行状态产生的故障进行预警,对提高火电机组安全生产具有重要的工程价值。
现有故障预警方法可分为基于系统模型的故障预警技术、基于统计方法和基于数据驱动的故障预警技术。在基于系统模型的故障预警方面,Cai等人[1]建立对象的微分方程模型,通过比较残差来实现线性分布参数系统的故障预警;薛涵磊等[2]结合模型预测和溯因推理网络方法预测电网故障。在基于统计方法的故障预警方面,Abdenour Soualhi等[3]利用2个隐马尔可夫模型(hidden Markov models)来预测迫近的故障;Ding等人[4]则利用粒子滤波(particle filter)和非线性回归(nonlinear regression)监测非线性随机系统(nonlinear stochastic system)的早期故障,避免故障进一步发展。基于数据驱动的故障预警方面,Ma等人[5]和陈园艺等[6]使用支持向量机(support vector machine,SVM)分别对Tennessee Eastman过程和风电机组齿轮箱的故障进行预测;Zhang等人[7]结合信度规则(belief rule base)和证据推理(evidential reasoning)来训练故障预警模型;Tian等人[8]使用灰色时间序列模型来预测化工过程的趋势,实现故障预警;陆宁云等[9]根据工程系统自身固有的网络拓扑结构,构建多层贝叶斯网络模型,从而实现故障预警。基于系统模型和统计方法的故障预警方法存在自身固有的缺点,如预测效果受限于模型的精度等,而基于数据驱动的故障预警方法直接采用设备的历史数据和在线数据,使数据模型与实际设备相近,故障预警精度较高。同时现有故障预警方法侧重故障类型预测研究,对于故障检出后设备能继续工作的时间则研究较少。
目前对磨煤机故障预警方面研究较少。Rakic[10]使用自组织映射(self organizing map,SOM)实现了磨煤机的故障预警和故障隔离;Chen等人[11]使用基于证据k-近邻(k-nearest neighbour classifier,kNN)算法对包含磨煤机的火电设备进行故障早期报警;Liu等人[12]使用SVM预测磨煤机相关变量的变化趋势,进一步对故障进行预测。这些方法都能实现磨煤机故障预警,但无法进一步估算磨煤机的剩余可用时间。
本文提出一种基于半监督学习方法的磨煤机故障预警系统,采用基于密度的有噪声聚类(density-based spatial clustering of applications with noise,DBSCAN)方法对磨煤机历史运行数据进行正常状态和故障状态的聚类,采用随机森林(random forest,RF)分类方法建立磨煤机运行状态分类预警模型,在预测故障类别的同时实现磨煤机剩余可用时间的估算。
1 中速磨煤机故障特性分析
磨煤机故障可分成设备故障和工艺故障两大类[13]。设备故障包括磨煤机振动、磨煤机漏粉、主轴承过热、一次风管堵塞、磨煤机出力不足、磨煤机自燃和静压轴承油压异常。工艺故障包括磨煤机满煤和磨煤机断煤。磨煤机断煤、磨煤机堵煤、磨煤机自燃和一次风管堵塞故障属于运行参数偏离正常值造成的故障。其中,磨煤机断煤故障与磨煤机自燃故障在磨煤机多个过程参数的变化趋势相似,仅通过磨煤机的过程参数难于区分。
1.1 磨煤机断煤故障分析
落煤管或给煤管堵塞、给煤机断煤或一次风管堵塞、一次风量过小等均会造成进煤量减小,磨煤机内存煤量降低,最终导致磨煤机断煤故障。故障发生过程中,少量湿煤无法吸收一次风中过量的热,导致磨煤机出口温度上升。在系统自动运行时,给煤机转速较高,但进煤较少,一次风量随给煤机转速信号而增大,导致排粉机功耗上升,而磨煤机中煤少,造成功耗下降。
1.2 磨煤机自燃故障分析
磨煤机出口温度过高可能导致磨煤机发生自燃故障。造成磨煤机出口温度过高的原因较多,主要有:1)磨煤机入口热风过多,冷热风比失配;2)磨煤机断煤导致磨煤机无法有效吸收一次风热量;3)停磨或启磨时没有充分吹扫,残留煤粉导致自燃;4)煤质发生变化,如煤水分降低但未及时调整控制参数,导致一次风热量无法完全吸收,磨煤机出口温度超温。磨煤机自燃故障发生后,磨煤机出口温度快速升高,系统自动运行时热风门开度关至0,冷风门全开,导致一次风流量降低,磨煤机出入口风压降低,磨煤机差压降低。
1.3 磨煤机实际故障趋势分析
以某1 000 MW火电机组HP1163/Dyn中速磨煤机为研究对象。图1和图2分别为磨煤机发生断煤故障和自燃故障时相关参数的变化趋势。由图1和图2可见,磨煤机发生断煤故障或自燃故障时,磨煤机过程参数存在相似变化趋势,磨煤机出口温度均会上升,同时冷风门会增大开度,热风门减小开度,一次风入口压力降低。磨煤机发生断煤故障时,一次风量先增大后减小;磨煤机发生自燃故障时,一次风量降低。发生断煤和自燃故障时参数变化趋势相似,给磨煤机故障类型判断造成困扰,这也是难题之一。
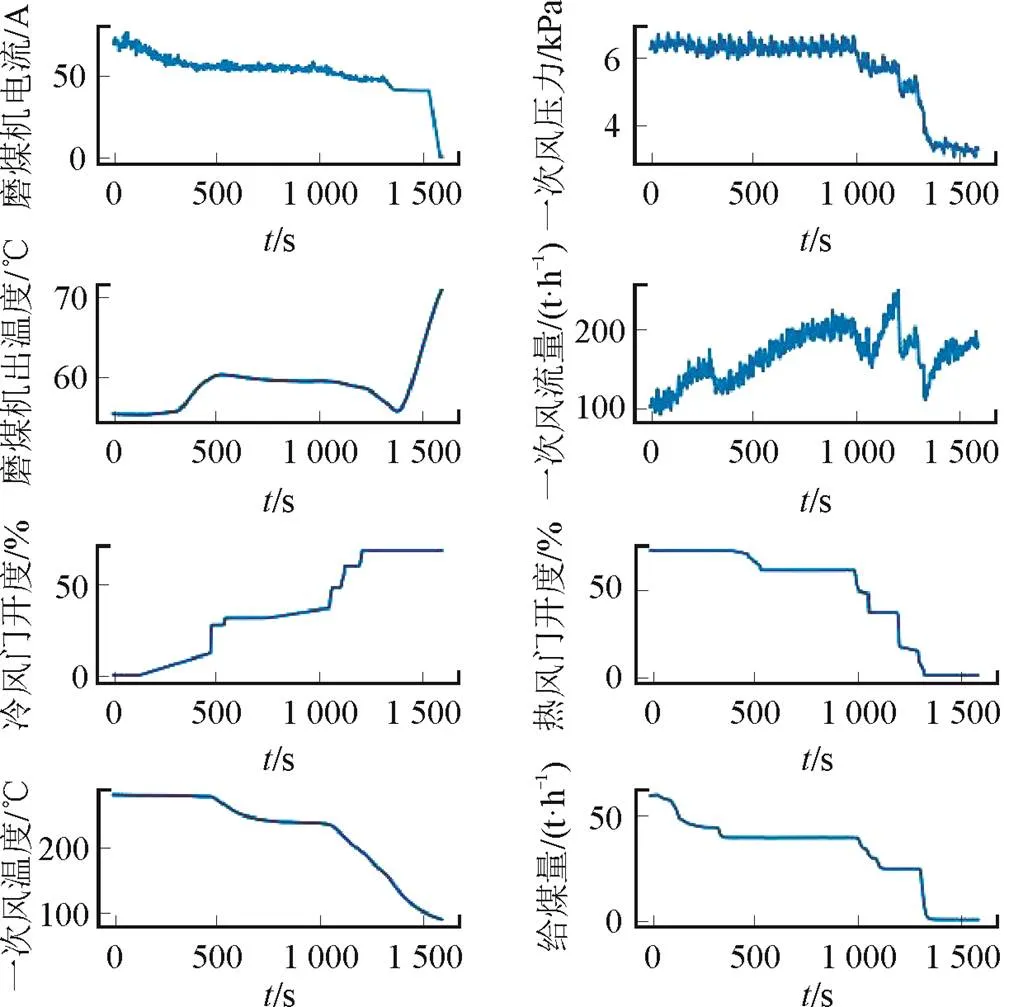
图1 磨煤机断煤故障中各参数变化趋势
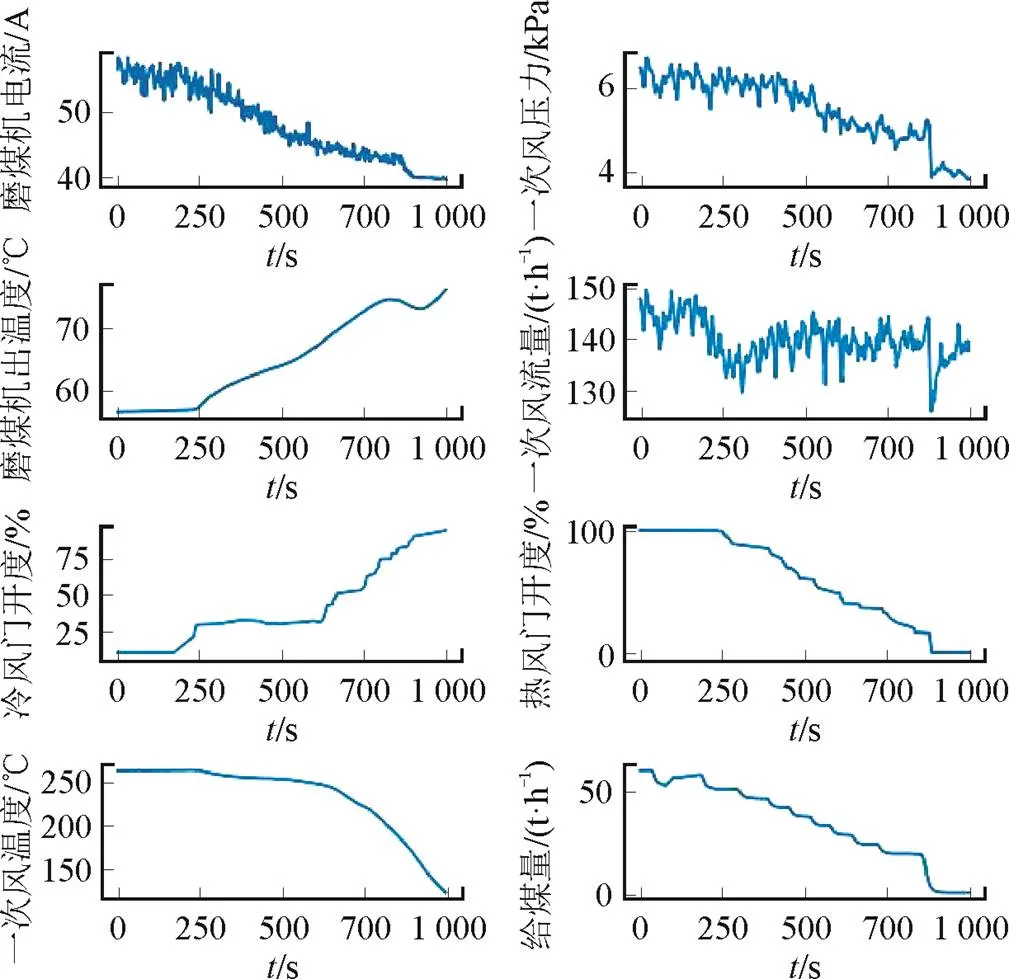
图2 磨煤机自燃故障中各参数变化趋势
2 基于半监督学习方法的故障预警
针对磨煤机的故障预警问题,本文提出一种基于半监督学习的磨煤机故障预警方法,使用DBSCAN聚类方法建立磨煤机的故障预警模型,采用随机森林方法实现故障预警和剩余可用时间的估算。磨煤机故障预警方法分离线训练和在线预警2个阶段,结构如图3所示。

图3 磨煤机故障预警过程
离线训练阶段主要包括:
1)从历史数据库中提取与磨煤机运行状态相关的历史数据;
2)对数据进行标准化预处理;
3)根据运行日志和运行经验,提取磨煤机不同故障的历史数据,并加上相应的状态标签;
4)采用DBSCAN聚类算法对历史数据进行聚类分析,结合状态标签,对不同故障分配类标记序列和统计不同故障的发生时间;
5)建立随机森林模型,实现故障预警分类。
在线预警阶段主要包括:
1)对在线数据进行预处理;
2)预处理后的数据作为随机森林的输入,通过分类计算给出磨煤机的运行状态标记序列,如果给出的标记序列对应某类磨煤机故障,则进一步给出设备的剩余可用时间;
3)如果故障预警系统给出的预估状态与运行人员判断不一致,则利用新数据,重新训练故障预警模型。
2.1 数据标准化处理




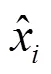
2.2 基于DBSCAN聚类的磨煤机故障分析
DBSCAN聚类算法是一种基于密度的聚类,根据数据样本在样本空间中的紧密程度将样本分成不同的簇,该方法聚类速度快,可以有效处理异常数据。
在DBSCAN聚类算法中,给定数据集D={1,2, …,x}相关定义如下:

定义2 密度直达 若x位于x的∈邻域中,且x为核心对象,则称x由x密度直达;
定义3 密度可达 对于x与x,若存在样本序列{1,2, …,p},其中1=x,p=x,且p1由p密度直达,则称x由x密度可达。
DBSCAN聚类算法先根据给定的邻域参数∈和MinPts找出所有核心对象,然后以任一核心对象为出发点,找出由其密度可达的样本,生成聚类簇,直到所有核心对象均被访问为止。
磨煤机的大部分故障存在一个逐步发展的过程,当故障征兆比较微弱时,磨煤机的相关过程参数开始偏离正常运行值。现有大多数故障预警方法偏重研究故障检测方法,而针对不同的故障类型对设备剩余的可用时间缺少相应的研究。不同的故障下,设备的过程参数在时间和空间上都存在一定的差异。考虑到故障发展通常需要一定的时间,可利用不同故障在发展过程中的不同演变趋势,对故障类型和设备剩余可用时间进行估计。
从历史数据库中提取磨煤机的正常运行状态和故障状态的历史数据,选取合适变量并进行标准化处理。利用DBSCAN聚类对故障数据进行故障分离。在划分不同故障阶段后,对每个故障分配类标记序列,统计不同阶段的设备剩余可用时间。类标记序列为某一故障的不同阶段的类标记按照时间变化组成的序列。不同故障应有不同的类标记序列,即使同一故障,也可能出现不同的类标记序列。
2.3 基于随机森林的预警模型

通过DBSCAN聚类对磨煤机的历史数据的分析,得到带有类标记的历史数据。随机森林分类通过对带类标记的历史数据进行学习,区分不同标记的数据,并且对新的数据预测类标记。通过随机森林对实时数据进行类标记预测,可以判断磨煤机当前所处的状态。训练时将历史数据分成训练数据集和测试数据集。训练数据集用于建立预警模型,模型的性能通过测试数据进行评估和验证。
关于训练数据,首先应用z-score标准化方法进行数据预处理,然后提取与设备健康状况相关的有用特性,选取的特征子集,以实现更低的维度和更少的冗余。在在线预警阶段,先对在线数据预处理。预处理后的数据作为随机森林的输入,计算给出磨煤机的预测状态,如果给出故障预测,则进一步给出设备的剩余可用时间。如果故障预警系统给出的状态估计与运行人员判断不一致,则利用新的数据,重新训练故障预警模型。
3 仿真试验
从某1 000 MW火电机组的历史数据中提取与磨煤机运行相关的过程参数。根据文献[13]中总结的磨煤机不同故障下过程参数变化趋势,选取与故障相关的变量,具体结果见表1。从1年的历史数据中选取磨煤机正常运行和故障运行的数据,采样时间为1 s。根据运行经验选取了合计123 min的数据,包括1组典型正常运行数据、3组断煤故障、 1组自燃故障。不同故障的发展时间存在一定的差异,以磨煤机电机电流开始下降到停机为故障数据的时间范围。数据集基本信息见表2。
表1 磨煤机故障预警系统选取的相关变量

Tab.1 The variables selected for the coal mill fault prediction system
表2 数据集基本信息

Tab.2 Basic information of the coal mill dataset
首先,将1组正常运行数据和3组故障数据(断煤故障I、II和1组自燃故障)作为训练数据集,建立预警模型。将断煤故障III数据作为测试数据集。训练数据集占数据集的84%,用来建立磨煤机故障预警模型;测试数据集占数据集的16%,用来评价预警模型。
3.1 磨煤机运行状态的DBSCAN聚类
DBSCAN聚类的相关参数∈和MinPts无通用确定方法,通常根据所分析数据的特征进行选取。MinPts取值过小会导致过多的簇,可采用ln()来确定[15],其中为数据点数。∈的取值根据实际的聚类效果确定。本文仿真中∈和MinPts的取值分别为0.55和20。
在磨煤机故障数据集中,最终簇类数为9,用类标记序列来描述各故障的类标记分配情况。其中异常数据1类,类标记为–1;正常运行数据1类,类标记为0;断煤故障I数据3类,类标记序列为(1,2,3);断煤故障II数据为3类,类标记序列为(1,6,7);自燃故障数据2类,类标记序列为(4,5)。同时统计各故障下设备的剩余可用时间和各类数据包含的样本数见表3,聚类结果如图4所示。由表3和图4可以看出,即使是相同的断煤故障,其趋势变化也有一定的区别。
表3 聚类数据包含的样本数和对应的剩余可用时间

Tab.3 The sample numbers in clustering data and the corresponding remaining usable time
磨煤机断煤故障和自燃故障的初始阶段(类标记分别为1和4)包含的样本数比其他阶段更多。说明磨煤机的缓变故障在初期的变化缓慢,且会维持较长的一段时间。当磨煤机的故障经过初始阶段后,变化迅速,在特定阶段维持时间较短。因此,若能在磨煤机故障的初始阶段预测到故障的种类,让现场人员有充足时间做出反应,则可以有效提升磨煤机运行的安全性。

图4 DBSCAN在数据集上的聚类结果
3.2 基于随机森林的故障预警
3.2.1评价指标
对于二分类问题,可将样本根据真实类别和分类器预测类别的组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative)4种情形,4种类别的数量分别表示为P、P、N、N。分类结果的混淆矩阵(confusion matrix)见表4。
表4 混淆矩阵

Tab.4 The confusion matrix
为验证故障分类准确性,定义



式中,为查准率,为查全率,1值综合考虑了查准率和查全率。1值越高,则查准率和查全率越高。


3.2.2预测结果和讨论
各分类器在训练数据集和测试数据集的1值见表5。由表5可见:在训练数据集,kNN预警模型和LDA预警模型的1值均小于0.9,显著低于随机森林预警模型和NB预警模型,说明随机森林预警模型和NB预警模型在训练数据集上的学习能力更强。在测试数据集,随机森林预警模型的1值高于其他3个分类器预警模型,表明随机森林预警模型的泛化能力更强。
表5 各分类器在训练数据集和测试数据集的F1值

Tab.5 The F1 value of each classifier in training dataset and test dataset
图5为各分类器预警模型在训练数据的预测结果。随机森林预警模型和kNN预警模型在断煤故障I的预测标记序列为(1,2,3),在自燃故障的预测标记序列为(4,5),在断煤故障II上的预测标记序列为 (1,6,7)。与实际一致。NB预警模型在断煤故障I中出现误报,将断煤故障预测成自燃故障,同时在自燃故障中存在严重的“跳跃”现象。LDA预警模型也存在误报和“跳跃”现象,将断煤故障II预测成自燃故障,在断煤故障1中有短时间的来回“跳跃”。可以看出,随机森林预警模型相较于其他分离器预警模型,不仅准确率高,也更加稳定,没有误报和“跳跃”的情形。

图5 各分类器预警模型在训练数据集的预测结果
3.2.3运行数据验证
采用断煤故障III作为验证数据,检验随机森林预警模型的有效性。对于基于不同方法的磨煤机故障预警模型,当磨煤机发生断煤故障,其预测的标记序列应为(1,2,3)或(1,6,7)。若出现其他类标记,如4或者5,则认为出现了误报。若中间样本的类标记预测为–1,表明该样本受到噪音干扰,可继续维持前一时刻的预测标记,不认为是误报。
依次提取断煤故障数据的相关变量,标准化后送入各分类器预警模型,最终的预测结果如图6所示。由图6可见,NB预警模型和LDA预警模型存在误报现象和“跳跃”现象,而kNN预警模型在磨煤机断煤故障早期存在“跳跃”现象。随机森林预警模型的预测标记序列为(0,1,2,3),预测该磨煤机断煤故障数据属于断煤故障I,且不存在误报和“跳跃”现象。可以看出,本文提出的随机森林预警模型,在实际应用中优于其他分类器预警模型。

图6 各分类器预警模型对磨煤机断煤故障的预测结果
随机森林预警模型估计的设备剩余可用时间见表6。在断煤故障类标记为1的阶段,实际的设备剩余可用时间在模型估计的剩余可用时间范围内。但是在断煤故障类标记为2和3的阶段,实际设备剩余可用时间大于模型估计的设备剩余可用时间,但是量级一致,预测较为保守。
表6 随机森林预警模型估计的磨煤机剩余可用时间

Tab.6 The remaining usable time of each cluster label for coal breakdown fault
4 结 论
1)利用DBSCAN方法对磨煤机故障进行聚类分析,可以将故障发展过程划分为不同的类,方便描述故障发展的不同阶段。仿真结果表明磨煤机断煤和自燃故障在初始阶段变化较缓慢,后期变化迅速。
2)与基于k-近邻算法、朴素贝叶斯和线性判别分析的预警模型相比,随机森林预警模型可准确标记磨煤机不同故障发展阶段,对磨煤机剩余可用时间也能给出较准确的预估
[1] CAI J, FERDOWSI H, SARANGAPANI J. Model-based fault detection, estimation, and prediction for a class of linear distributed parameter systems[J]. Automatica, 2016, 66: 122-131.
[2] 薛涵磊, 刘晓琴. 基于模型预测方法的电网故障预测[J]. 辽宁石油化工大学学报, 2017, 37(2): 60-65. XUE Hanlei, LIU Xiaoqin. Power grid fault forecast based on model prediction method[J]. Journal of Liaoning University of Petroleum & Chemical Technology, 2017, 37(2): 60-65.
[3] SOUALHI A, CLERC G, RAZIK H, et al. Hidden Markov models for the prediction of impending faults[J]. IEEE Transactions on Industrial Electronics, 2016, 63(5): 3271-3281.
[4] DING B, FANG H. Fault prediction for nonlinear stochastic system with incipient faults based on particle filter and nonlinear regression[J]. ISA Transactions, 2017, 68: 327-334.
[5] MA J, XU J. Fault prediction algorithm for multiple mode process based on reconstruction technique[J]. Mathematical Problems in Engineering, 2015, 1: 1-8.
[6] 陈园艺, 孙建平. 基于PSO-SVR和SPC的风电机组齿轮箱故障预警研究[J]. 电力科学与工程, 2016, 32(5): 43-48. CHEN Yuanyi, SUN Jianping. Research on fault early warning of wind turbine gear box based on PSO-SVR and SPC[J]. Electric Power Science and Engineering, 2016, 32(5): 43-48.
[7] ZHANG B, YIN X, WANG Z, et al. A BRB based fault prediction method of complex electromechanical systems[J]. Mathematical Problems in Engineering, 2015, 1: 1-8.
[8] TIAN W, HU M, LI C, et al. Fault prediction based on dynamic model and grey time series model in chemical processes[J]. Chinese Journal of Chemical Engineering, 2014, 22(6): 643-650.
[9] 陆宁云, 何克磊, 姜斌, 等. 一种基于贝叶斯网络的故障预测方法[J]. 东南大学学报(自然科学版), 2012, 42(增刊1): 87-91. LU Ningyun, HE Kelei, JIANG Bin, et al. A fault prognosis method using Bayesian network[J]. Journal of Southeast University (Natural Science Edition), 2012, 42(Suppl.1): 87-91.
[10] RAKIĆ A Ž. Early fault detection and isolation in coal mills based on self-organizing maps[C]//10th Symposium on Neural Network Applications in Electrical Engineering. Belgrade: IEEE, 2010: 45-48.
[11] CHEN X, WANG P, HAO Y, et al. Evidential KNN-based condition monitoring and early warning method with application in power plant[J]. Neurocomputing, 2018, 315: 18-32.
[12] LIU J, GENG G. Fault prediction for power plant equipment based on support vector regression[C]//International Symposium on Computational Intelligence and Design. Hangzhou: IEEE, 2016: 461-464.
[13] 刘畅. 电站设备辅机状态监测与故障诊断[D]. 北京: 华北电力大学, 2017: 13-17. LIU Chang. Condition monitoring and fault diagnosis of auxiliary equipment in power plant[D]. Beijing: North China Electric Power University, 2017: 13-17.
[14] BREIMAN L. Random forests[J]. Machine Learning, 2001, 45(1): 5-32.
[15] ESTER M, KRIEGEL H P, XU X. A density-based algorithm for discovering clusters in large spatial databases with noise[C]//The 2nd International Conference on Knowledge Discovery and Data Mining. California: AAAI Press, 1996: 226-231.
Research on coal mill fault prediction based on semi-supervised learning method
XIAO Li1, LUO Jia1, OUYANG Chunming2
(1. Guangdong Diankeyuan Energy Technology Co., Ltd., Guangzhou 510080, China; 2. Electric Power Research Institute of Guangdong Power Grid Co., Ltd., Guangzhou 510080, China)
In thermal power plants, the operating environment of coal mills is harsh and faults in coal mills occur frequently. Early warning of the coal mill failures and evaluating remaining usable time of the devices under relevant fault conditions is of great significance to improving the safety of thermal power plants. This paper proposes a novel coal mill fault prediction technology based on semi-supervised learning method. Firstly, the DBSCAN clustering is applied to divide the history data of the coal mill into normal states and fault states. Different class labels are assigned to different states and the remaining usable time of the equipment is counted. Then, the random forest classifier is used to establish a fault prediction model for the coal mill according to the class label sequence, the state of the coal mill operating data is predicted, and the fault category and corresponding equipment remaining usable time are determined. Finally, this method is applied in a thermal power unit by using the actual running data of the coal mills, and the prediction result is compared with that of the early warning models of other classification algorithms such as k- nearest neighbor algorithm, naive Bayes and linear discriminant analysis. The experimental results show that, this method is superior to other early warning models, which can accurately mark the different development stages of the mill faults and give the remaining available time of the mills more accurately.
coal mill, DBSCAN clustering, fault prediction, random forest, semi-supervised learning method, prediction
Science and Technology Project of China Southern Power Grid Co., Ltd. (GDKJQQ20152014)
TK223; TP273
B
10.19666/j.rlfd.201807134
肖黎, 罗嘉, 欧阳春明. 基于半监督学习方法的磨煤机故障预警[J]. 热力发电, 2019, 48(4): 121-127. XIAO Li, LUO Jia, OUYANG Chunming. Research on coal mill fault prediction based on semi-supervised learning method[J]. Thermal Power Generation, 2019, 48(4): 121-127.
2018-07-21
中国南方电网有限责任公司科技项目(GDKJQQ20152014)
肖黎(1989—),男,博士,主要研究方向为电厂热工自动控制,361944474@qq.com。
(责任编辑 杜亚勤)
