基于深度卷积网络和在线学习跟踪的驾驶员打哈欠检测
2019-05-18张伟伟糜泽阳肖凌云钱宇彬
张伟伟 糜泽阳 肖凌云 钱宇彬
1.上海工程技术大学机械与汽车工程学院,上海,201620 2.中国标准化研究院,北京,100191
0 引言
驾驶员疲劳是造成交通事故的重要原因[1],而检测驾驶员面部疲劳信号之一的驾驶员打哈欠事件已经成为计算机视觉技术领域研究的热点。驾驶员打哈欠检测的首要任务是定位驾驶员面部,然后在面部区域检测嘴部并分析嘴角或嘴内的形状变化等。在人脸检测方面,学者们已经提出了多种不同的方法,如主成分分析法[2]、神经网络法[3]、支持向量机[4]以及建立人脸几何模型[5]等。VIOLA等[6]提出了一种基于 Haar特征的人脸自适应提升训练方法(AdaBoost),获得了较好的检测效果;SOCHMAN 等[7]提出的 Wald-Boost算法结合序列概率原理改进了AdaBoost算法,使其具有了更高的分类检测效率;HSU等[8]通过皮肤亮度补偿以及非线性颜色变换等技术来检测面部区域,然而该方法只在静态图像上进行了测试,且在具有宽动态光照范围的真实驾驶环境中,其“真白”假设前提不再成立,很难获得可靠的检测结果;CHOI等[9]采用 CDF(cumulative distribution funtion)分析方法定位驾驶员的瞳孔位置,然后根据检测到的驾驶员视线的变化来确定驾驶员的疲劳状态。实际上当驾驶员处于疲劳状态时,眨眼和点头的频率会显著增加,这些参数都可以用作疲劳评估的指标。
针对打哈欠检测,一些研究人员关注于嘴部的几何特征。SHABNAM等[10]首先通过皮肤分割来检测嘴部区域,然后对比嘴内外区域的像素比来确定是否发生打哈欠事件;MANDALAPU等[11]直接采用支持向量机来分别训练打哈欠与正常状态下嘴部的状态图,在只有20幅静态图像的测试集中获得了81%的检测正确率;童兵亮[12]采用灰度投影模型来定位嘴角,并使用线性分类模型来区分打哈欠时的嘴角特征;SHABNAM等[13]采用颜色模型来确定嘴部区域,并根据嘴部的主动轮廓模型来确定嘴部轮廓的高宽比等。然而,以上算法测试均采用有限数量的静态图像,且图像都来自于条件可控的室内环境。除此之外,NENOIT等[14]提出了一种基于谱频率的方法来检测嘴部闭合或张开状态,但该方法需基于驾驶员面部以及嘴部已经检测定位的前提;FAN等[15]使用Gabor小波变换提取嘴角点的纹理特征,然后据此判断驾驶员的疲劳状态,但这种方法易受到光照、遮挡和角度变化的影响;HYUN等[16]提出了一种基于多模态车辆和生理传感器数据的驾驶员状态估计算法,但与单图像识别驾驶员疲劳状态方法相比,其成本较高,且应用起来较为繁琐。
为适应真实驾驶环境,并虑及面部特征易受性别、面部朝向、光照、遮挡、面部表情以及图像尺度和图像低分辨率的影响等因素,本文提出一种基于深度卷积网络[17-18]和在线学习跟踪的驾驶员打哈欠检测方法。
1 系统框架
系统框架如图1所示。首先,面部检测器在图像多尺度滑窗中根据深度卷积网络定位驾驶员面部区域,同时,采用基于另一深度卷积网络的鼻子检测器在面部区域定位鼻子区域;然后,通过在线学习的方法训练随机森林目标检测器,对光流跟踪器的漂移误差进行校正。有相对刚性的人脸轮廓中,嘴部区域位于鼻子下方,当打哈欠事件发生时,嘴角具有较大形变,其边缘的水平方向梯度强度值将有剧烈的增大;而驾驶过程中驾驶员经常扭头查看两侧交通状况,因此,打哈欠检测器融合了左右嘴部区域的边缘梯度值、鼻子跟踪置信度以及面部运动方向等信息综合判断是否有打哈欠事件发生。
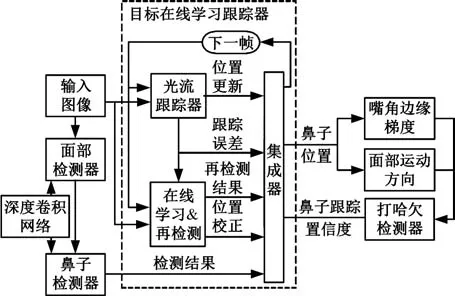
图1 驾驶员打哈欠检测系统原理框图Fig.1 Pipeline of driver yawning detection system
2 基于深度卷积网络的面部部件检测
深度卷积网络实质上是一种多层神经网络,其融合了局部感知野、共享权重以及空间降采样等特性,不仅可以大幅减少训练参数个数,还可以对一定程度的尺度缩放、旋转以及平移等保持鲁棒性。该深度卷积网络主要由交替连接的卷积层和降采样层组成,其中卷积层本质上是由不同的局部滤波器组合而成,而最终将得到的高层级的特征向量全连接到一个神经网络上。在驾驶员面部检测过程中,可以采用大量的原始面部图像数据库进行训练。图2显示了基于深度卷积网络的驾驶员面部检测结构图。
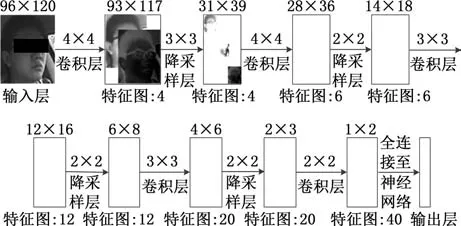
图2 用于驾驶员人脸检测的深度卷积网络的多层级结构Fig.2 Multi-level structure of deep convolution network for driver face detection
在图2的深度卷积网络中,输入图像统一设定为96pixel(宽)×120pixel(高)(图中简写为96×120)。第一层是一个滤波器感知野大小为4×4的卷积层,通过该卷积层,每一个输入图像得到4个特征图,其中显示了2个特征图例子。卷积层的下一层是降采样层,该层通过一个3×3的局部平均核对上一层的特征图进行空间降采样,最终其特征图像素由93pixel×117pixel降低至31pixel×39pixel,使得该卷积网络降低对于旋转和畸变的敏感度,该层中显示了3个经过降采样的特征图例子。经过三次不同的卷积层和降采样层的迭代,输入层最终演变为具有1pixel×2pixel的40个高层级特征图,因此最终形成的特征向量具有80个参数,全部连接至输出层的神经网络进行分类训练。如图2所示,每一层均由不同大小的卷积核或降采样核进行处理,形成不同个数的特征图,为简化表达,将图2所描述的深度卷积网络结构描述为96×120-4C4-3S4-4C6-2S6-3C12-2S12-3C20-2S20-2C40,其中字母 C 代表卷积层,字母S代表降采样层,字母前的数字为核尺寸,字母后的数字为特征图数量。
采用类似的方法设计了用于驾驶员鼻子检测的深度卷积网络架构。鼻子检测的训练图片全部来自于驾驶员人脸检测的数据集,同时鼻子的图像像素(14pixel×18pixel)远远小于驾驶员面部,且鼻子相对人脸具有较小的个体差异,因此,该深度卷积网络架构具有较少的层级结构和较少的层内滤波参数。用于驾驶员鼻子检测的深度卷积网络简化为14×18-3C6-2S6-3C10-2S10。
3 基于在线学习的目标跟踪方法
目前常用的目标跟踪方法有LK光流[19]、梯度直方图[20]以及均值漂移[20]等快速跟踪方法,但这些方法均要求目标始终保持在视频场景内,不能应对驾驶员面部目标因扭头观察邻车道车况而短时间遮挡或消失等情况,同时,LK光流跟踪法虽简单易行,但其光照亮度一致性的前提在驾驶场景中难以满足,在驾驶环境中容易产生漂移误差,而均值漂移等方法均采用直方图模型,对于驾驶过程中面部目标一定程度的旋转以及变形缺少适应性,缺少必要的模型更新。为适应驾驶过程中强烈的光照变化、面部目标可能的旋转形变、短时遮挡或消失等问题,有必要引入可在线学习目标的外观与姿态变化并进行训练的目标检测器,通过该在线检测器搭配可以快速跟踪的光流跟踪器对目标位置进行综合判定。为确保在线目标检测器的运行效率,采用低维的局部二比特特征和快速高效的随机森林分类器进行目标检测训练。
3.1 训练样本的局部二比特特征
在确定跟踪目标的初始位置之后,需要根据目标的外观以及周围背景在线训练目标检测器。为便于实时计算,在线训练的特征应能在反映物体梯度方向性的情况下尽量保持简洁性。启发于物体检测常用训练特征 Haar[6]、LBP(local binary pattern)[21]以 及 HOG(histogram oriental gradient)[22]等,特设计了更简洁的二比特特征,仅通过计算水平和垂直方向灰度总和,并比较大小便可实现前述三种特征对物体梯度方向的反映,避免了大量的梯度求导运算,具有更快的运行速度。该特征反映了图像区域内的边缘梯度方向,并对该梯度方向性进行了量化,最终获得了四种可能的编码结果。如图3所示,对目标区域随机选取若干个矩形框(图3中虚线框和实线框),对矩形实线框内灰度进行编码结果为00,其中I(Ai)(i=1,2,3,4)代表选定的图像框内的第i个区域内的灰度值总和;所有虚线框内二比特特征构成当前目标图像的特征向量X=(x1,x2,…,xk),其中k是目标区域选定的矩形图像框数量,反映了特征的维度,xk是四种可能的二比特特征。
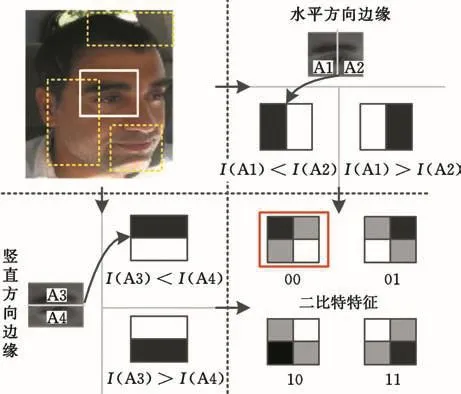
图3 在目标边界框内进行局部灰度梯度方向编码的二比特特征Fig.3 Binary-bit feature of local gray gradient direction coding in the target bounding box
为适应目标外观的动态改变,在线训练检测器的正负样本均来自于当前帧目标周围的图像块,其大小与目标大小一致。为提高在线检测器的分辨能力,只选择那些区域内部像素方差在目标图像方差一半以上的样本图像块。与目标区域的重合率大于0.7的100个图像块选为训练的正样本,重合率小于0.7的300个图像块视为训练的负样本。样本图像块与目标图像区域的重合率O的计算方法为
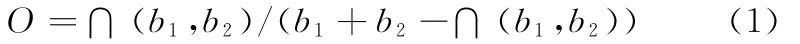
其中,b1和b2分别为样本图像块和目标图像区域的边界面积;∩代表图像边界框之间重叠部分的面积。
3.2 随机森林分类器
随机森林分类器是一种由多棵决策树组合而成的联合预测模型,是一种快速且有效的分类模型[23]。各决策树独立进行样本类别的预测,对所有的预测类别进行投票,票数最高的类别被选举为最终的结果。在训练中,每棵树上的叶节点记录了经过该节点的正样本的数量p和负样本数量n。而每棵决策树对每个输入图像的特征向量通过叶节点的后验概率进行类别的预测,其目标类别的后验概率
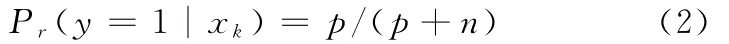
其中,k既是目标区域选定的矩形图像框数量,也代表了随机森林分类器中决策树的数量。
最终对来自所有决策树的后验概率进行均值计算,若均值大于0.5,则随机森林分类器输出类型为目标,否则为背景。而在整幅图像的扫描窗内检测单目标时,往往只选择具有最高随机森林预测概率输出的扫描窗格作为目标物体的边界框。
随机森林分类器由两个参数来决定其精度和速度:森林中决策树的数量m以及每棵决策树中包含特征的数量k。决策树的数量越多,随机森林分类器的分类性能越好,但运行的速度越慢。在本试验中,决策树数量m设定为10可以在满足实时性的同时保证分类的性能。而每棵树中所使用的特征维度k越大,随机森林分类器的判别能力越强。由于每个特征有4种可能的编码模式,因此每个决策树中叶节点的数量有4k个。在本文中,选定k为10。
3.3 在线目标跟踪
采用LK光流法由帧Ft到帧Ft+1前向跟踪目标时,跟踪点坐标Pt转换为Pt+1,而Pt+1也可由LK光流法在帧Ft上得到反向虚拟跟踪点P′t。若LK光流法跟踪正确,则跟踪误差e=|Pt-P′t|应足够小,如图4所示。
根据LK光流跟踪的误差以及在线随机森林检测器的目标位置,最终目标边界框的范围为
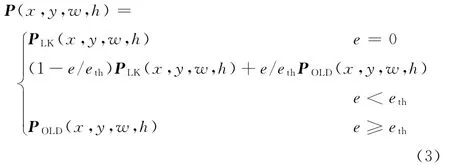
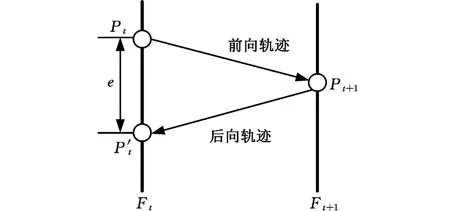
图4 LK光流跟踪误差Fig.4 Optical flow tracking error
其中,PLk(x,y,w,h)为LK光流法得到的纯跟踪边界框的左上角坐标(x,y)以及边界框的宽度w和高度h;POLD(x,y,w,h)为在线检测方法得到的目标边界框位置;eth为跟踪误差,其阈值为5个像素,大于此误差时认为光流法跟踪失败。
根据相邻帧得到的跟踪目标的边界框所选定的图像块bt之间的相似程度,可以大概估计目标跟踪的质量,即跟踪置信度T:
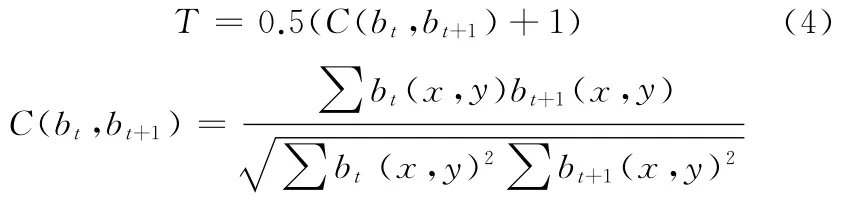
其中,C为正则化的图像互相关系数,图像块的大小均事先调整为相同的分辨率。
整个视频算法在公开的行人跟踪视频测试集[24]上进行了测试,并与行人的标准参考位置进行了对比,其效果如图5所示。
图5中,行人跟踪测试视频的分辨率为QVGA格式,各跟踪方法使用的测试函数(如光流、均值漂移、梯度直方图、随机森林分类器等)均采用MATLAB R2014a库函数。从图5中可以明显看出,梯度直方图与均值漂移等方法的跟踪效率随着视频帧数增加逐渐降低,大部分视频帧内不能有效跟踪行人的移动,而光流法虽能根据帧差原理检测到行人移动,但跟踪效率受光照影响太大而导致大部分跟踪结果产生漂移误差,与标准参考框的重合率大部分在0.5以下,而通过在线学习的方式训练的检测器可以有效地校正光流跟踪器产生的漂移误差,在随机森林决策树数量m为10的情况下(配置1)可以显著地改善跟踪效果,能连续跟踪复杂场景下的行人目标,使得大部分视频帧的跟踪重合率大部分在0.7以上,而决策树数量m降低为8(配置2)时,跟踪重合率有所下降,如图5a所示。
4 基于多信息融合的打哈欠检测
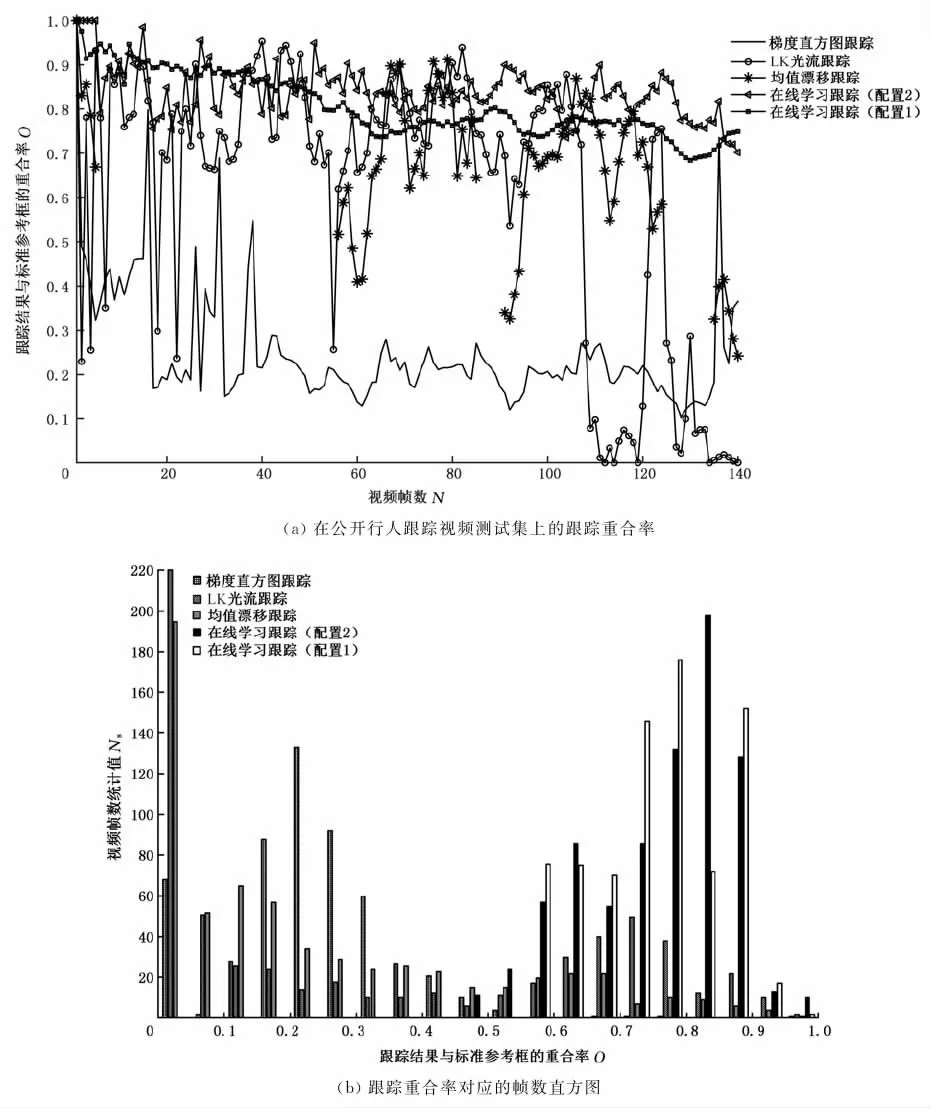
图5 在公开测试集上的跟踪重合率及其帧数统计直方图Fig.5 The tracking overlap and frame histogram on open datasets
在通过检测跟踪获得驾驶员鼻子位置之后,可以在鼻子正下方直接选定一个区域为嘴部形变分析区域。根据经验,该嘴部区域的宽度和高度分别设定为鼻子的1.5倍和1.8倍。嘴部区域由其竖直中心线分为左右两部分,如图6所示。
当打哈欠事件发生时,在嘴角处有明显的形变发生,竖直边沿的比例增大,因此,在嘴部区域对图像进行水平和竖直方向边缘滤波器卷积,并求取绝对梯度方向在0~10°内的像素的梯度强度和:当打哈欠事件发生时,0~10°范围内的像素梯度强度和会有明显的增大。像素梯度计算方法如下:
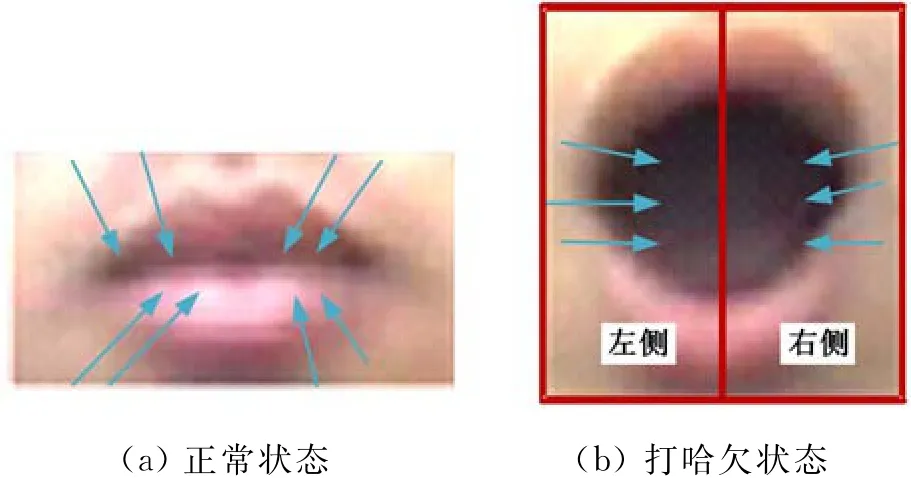
图6 两种状态嘴角梯度方向示意图Fig.6 Two state of mouth corner gradient
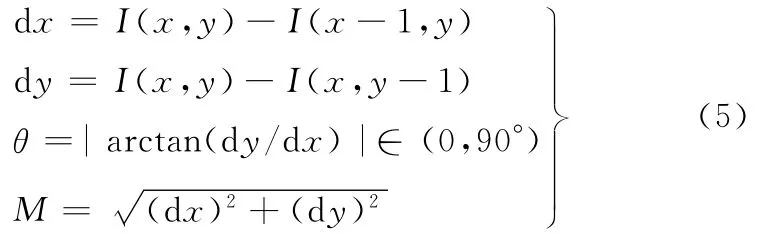
其中,I(x,y)为坐标点(x,y)处的像素值;θ和M 分别为点(x,y)处的梯度角度值和强度值。
图7显示了在打哈欠过程中,左侧嘴角部分0~10°范围内的像素梯度强度和(在3左右浮动)相对于正常状态数值明显增大(最高可达20)。在不同的光照条件下,相同的打哈欠事件的梯度强度和应该会有较大的差异。为在不同光照场景下确定不同嘴型打哈欠检测的统一阈值,需要将所有嘴部区域大小正则化至同一尺度(36×46),亮度值均由0~255正则化至0~1范围内。然而,当外界光照强烈变化时,跟踪质量急剧下降,此时无法分析嘴角梯度强度;当驾驶员扭头观察两侧车流时,嘴部区域往往包含面部与背景之间的竖直边沿,这为嘴角梯度强度的分析造成了极大的干扰。图8显示了车辆通过桥梁下方时光照的突变导致鼻子跟踪失败的情景。很明显,由于鼻子跟踪失败导致嘴部区域的误判,在右侧嘴角处面部与背景之间形成了较长的竖直边沿,使得右侧嘴角0~10°内的梯度强度和增大至29.40,该值远远大于左侧嘴角的8.7,同时右侧嘴角10°~20°范围内的梯度强度和18.61也远大于左侧梯度强度和3.68,而鼻子跟踪置信度降低至0.574 3,但此时并没有明显的嘴部打哈欠事件发生。
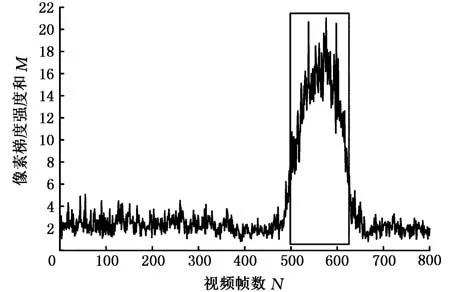
图7 正常状态和打哈欠状态(矩形框内)下左侧嘴角0~10°范围内梯度强度和Fig.7 Gradient intensity in 0~10degree of left mouth corner in normal and yawning state(rectangle box)
为获得打哈欠检测的精确描述,在进行嘴角梯度强度分析的同时,引入鼻子跟踪置信度以及面部横向运动等信息以作综合判断。设定打哈欠判别值YD来融合以上三种信息:

图8 车辆通过桥梁时面部目标跟踪失败后的左右侧嘴部梯度强度和的对比Fig.8 Comparisons of gradient intensity of left and right mouth corners after failure of facial tracking when vehicle pass bridge

其中,SL和SR分别为尺寸亮度正则化后的左右两侧嘴部区域0~10°范围内梯度强度和,T为鼻子跟踪器输出的跟踪置信度,Tth为可靠跟踪的置信度阀值,设定为0.6。当跟踪失败时,T 值为0。而面部运动方向可以通过跟踪过程中的鼻子中心位置进行判断:如果鼻子中心横向像素值突然增大,则代表驾驶员面部向右运动;反之,则代表驾驶员面部向左运动,即
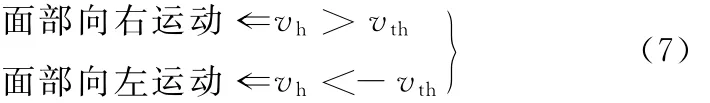
其中,vh和vth分别为驾驶员鼻子中心横向运动速度(横向坐标的帧间差分值)及其速度阈值。
5 实验
5.1 驾驶员面部分类
驾驶员面部分类数据库图像截取于本实验室内9名驾驶员的行车视频,以及公开的打哈欠测试视频YawDD[25]中的89个驾驶视频,该数据库共有52 344个正样本图像以及108 323个负样本图像,样本图像大小为96pixel×120pixel,图9显示了部分正样本示例。

图9 驾驶员面部数据库正样本示例Fig.9 Positive samples of driver facial database
从图9可以看出,驾驶员面部数据库正样本中包含多种光照条件下的不同面部角度的驾驶员面部图像。训练和测试均经过图2所示的卷积神经网络配置下的十折交叉验证,其中图2中的参数配置为缺省配置。为对比深度卷积网络的训练检测性能,分别设定了另外两种不同配置的深度卷积网络架构:第一种与本文缺省配置具有同样的网络层数,但每层具有更多的特征图数量,其网络结构简化为 96×120-4C4-3S4-4C8-2S8-3C16-2S16-3C32-2S32-2C64,该网络架构称为“多特征图网络”;第二种较本文缺省配置仅缺少最后一层降采样层,其他层数配置相同,其网络结构简化为96× 120-4C4-3S4-4C6-2S6-3C12-2S12-3C20-2S20,该网络称为“少一卷积层网络”。图10显示了三种方法下驾驶员面部检测深度卷积网络的ROC(receiveroperating characteristic)性能曲线。
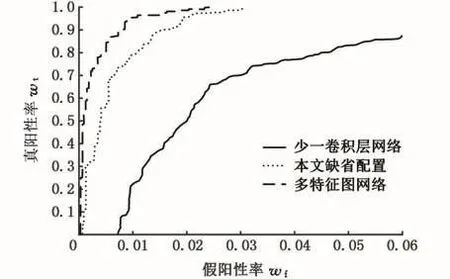
图10 不同深度卷积网络配置下的驾驶员面部分类ROC曲线Fig.10 The ROC curves of driver facial classification with different deep network configurations
从图10可以看出,具有相同网络层数的情况下,多特征图网络相对于本文缺省配置具有更好的分类性能,但性能改善效果一般;而本文缺省配置若缺少一层网络配置,则其性能下降较为明显。表1显示了三种方法在同一工作站(配置酷睿i5-6500CPU和MATLAB R2014a)上的训练开销和测试精度。
可以看出,在本文缺省配置下可以获得较为满意的性能,且计算机内存和时间开销均较为适中,特将该缺省配置下的深度卷积神经网络与常规的AdaBoost算法及其改进版WaldBoost算法采用相同的面部数据库进行性能效果对比,如图11所示。通过图11可以看出,深度卷积网络相对于常规的Boost算法具有很明显的分类性能优势。

表1 不同深度卷积网络配置下的训练开销和测试精度Tab.1 Training overhead and test accuracy with different deep network configurations
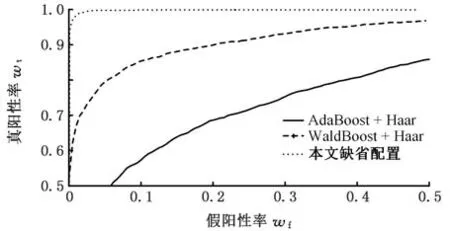
图11 用于驾驶员面部图像分类的深度卷积网络与Boost算法的ROC曲线性能比较Fig.11 Performance comparison of ROC curves between depth convolution network and Boost algorithm for driver face image classification
5.2 打哈欠事件分析
图12显示了车辆经过桥梁下方时驾驶员打哈欠过程中的若干视频截图。在车辆驶出桥梁下方的过程中,光照的突然变化使得跟踪逐渐恶化甚至于跟踪失败,跟踪置信度从0.874 66下降至0.574 3。由于跟踪失败,仅仅采用嘴角区域的边缘梯度强度分析易引起误警。如图12d~图12f所示,该时间段没有发生打哈欠事件,但因为跟踪失败导致嘴部区域判断有误,进而输出错误的打哈欠警告信息。

图12 车辆通过桥梁下方时跟踪失败引起的打哈欠误警事件的典型视频序列截图Fig.12 Typical video sequences of yawning error alert events caused by tracking failure when vehicles pass under bridges
图12中对应的视频序列中,右侧嘴部区域0~10°范围内的梯度强度和的变化趋势以及跟踪置信度值如图13所示。在该视频序列内打哈欠事件发生在579~656帧范围内,如图13中实线矩形框所示。当实线矩形框内打哈欠事件发生时,0~10°范围内的梯度强度和显著地增大,如图13a所示。然而,仅仅采用梯度强度值将会引入较多的误警率,如图13b中矩形虚线区域所示,此段时间内并没有打哈欠事件发生,但此区域内梯度强度和甚至会高于矩形实线区域内的梯度强度和。误判产生的主要原因来自于跟踪质量下降和跟踪失败引起的鼻子位置误差,如图13b所示,跟踪置信度在矩形虚线区域迅速减小,甚至跟踪丢失。
另一种易引起误警率的现象是驾驶员行车过程中扭头引起的嘴部区域选择误差。图14显示了驾驶员面部在视频331~385帧中转向右侧时右侧嘴角梯度强度与鼻子中心横向位置分析。
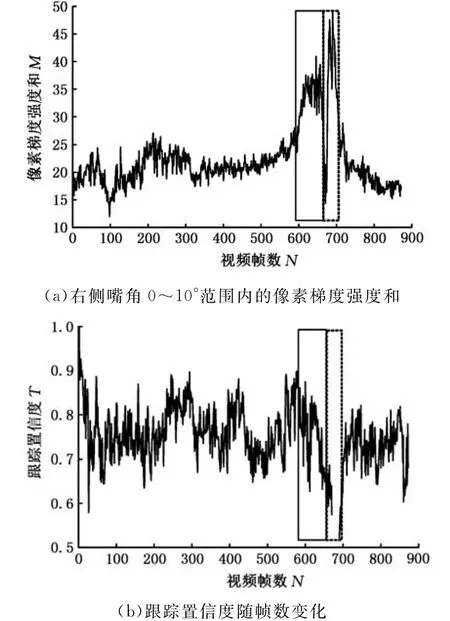
图13 跟踪质量下降时的驾驶员打哈欠检测的多数据分析Fig.13 Multi-data analysis of yawning detection when the tracking quality is degrading
在图14所示的视频序列中,打哈欠事件发生在517~645帧之间,如矩形实线区域所示,然而仅进行梯度强度分析将在331~382帧之间引入误警,如矩形虚线区域所示,此段区间内驾驶员面部转向右侧,如图14b所示。因此有必要综合考虑嘴部区域的梯度强度、鼻子跟踪置信度以及驾驶员面部运动方向等信息来确定是否有打哈欠事件发生。
图15显示了图13和图14两个视频序列内对应的打哈欠判别值YD的变化情况。
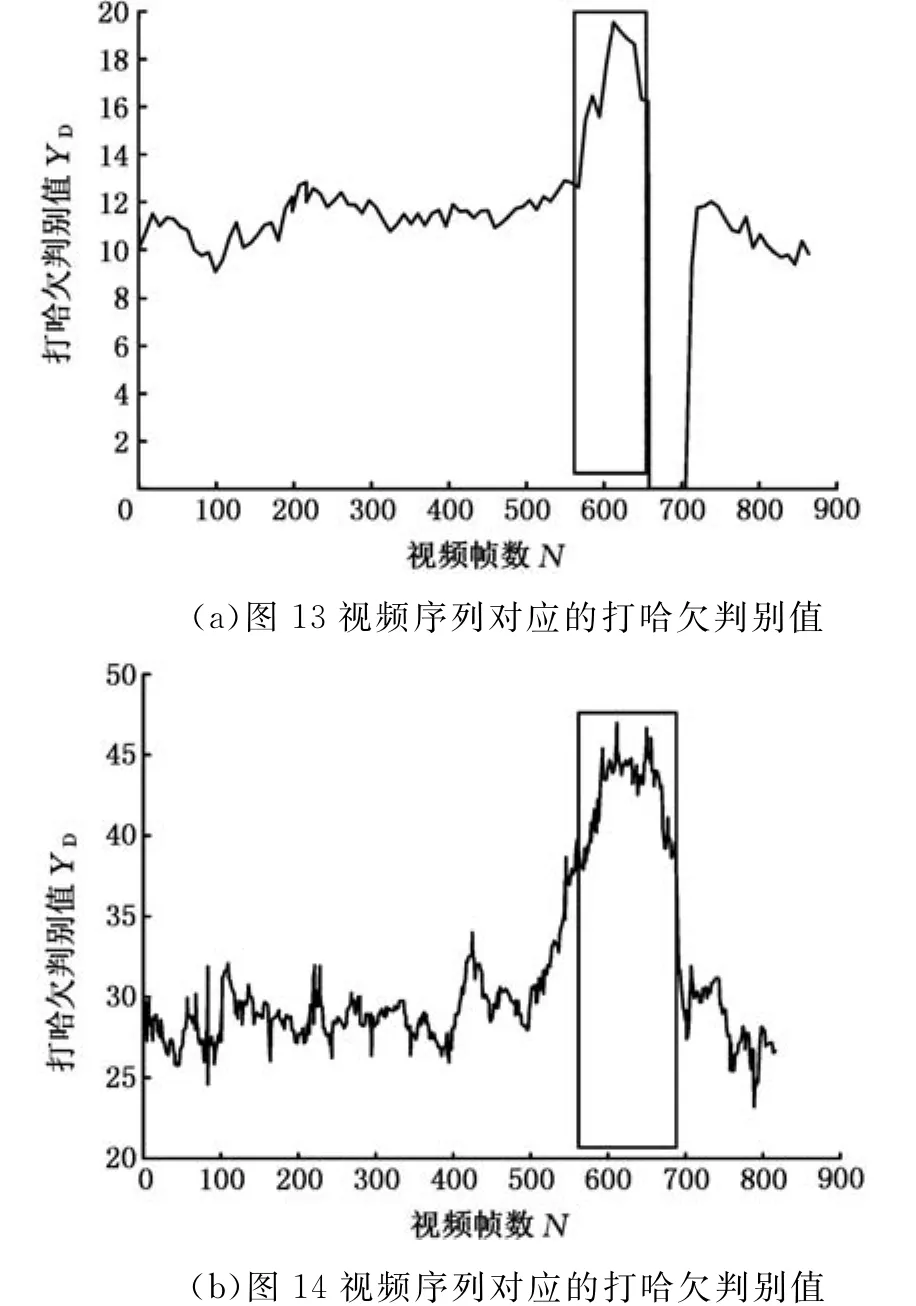
图15 图13和图14对应的视频序列内的打哈欠判别值YD的变化情况Fig.15 The changes of yawning discrimination value YDin Fig.13and Fig.14video sequences
图15中,在打哈欠事件发生时,YD可以智能化地选择左侧或右侧嘴部区域作为分析对象,从而在图15a和图15b分别显示了图13和图14视频序列内打哈欠事件发生时YD值的明显增大,可以通过左侧区域的恒虚警率自适应阈值[26]检测到矩形实线框内打哈欠事件的发生,且最大限度地降低了误警事件发生的可能性。该驾驶员打哈欠检测方法在YawDD视频集[25]上进行了测试,打哈欠检测成功率达到93.7%,远高于文献[25]中60%的检测成功率。本方法仍未达到完全的检测效率,其主要原因在于:①少量视频内驾驶员打哈欠时面部有旋转,在鼻子正下方无法准确选定嘴部区域;②少量视频内驾驶员打哈欠时有用手遮挡面部的习惯,导致面部跟踪失败或嘴部区域无法定位。
6 结论
(1)根据交通场景复杂多变、光照强度变化范围大、驾驶员面部特征个体差异大的特点,设计了深度卷积网络架构对驾驶员面部进行分类检测,根据其监督式训练学习机制,可以深度提取面部的主要特征,使得该分类网络获得较为理想的分类检测效果。
(2)设计了低维的局部二比特特征,同时利用该类特征在线训练了随机森林面部目标检测器,将其与传统的光流跟踪器搭配,可以克服光流跟踪器易受光照影响的缺点,弥补了光流跟踪器的漂移误差。整个在线学习跟踪算法可以通过跟踪置信度反映跟踪质量。
(3)采用统计方式分析了嘴角区域的梯度强度,可以避免低分辨率下直接定位嘴角的困难;同时,在驾驶视频测试集上的实验结果证明,结合鼻子跟踪器置信度以及面部运动方向等综合判断驾驶员打哈欠行为,在提高检测正确率的同时也降低了误警事件发生的可能。
