主动学习与半监督技术相结合的海冰图像分类
2019-05-17韩彦岭李鹏张云徐利军王静
韩彦岭,李鹏,张云,徐利军,王静
(上海海洋大学 信息学院,上海 201306)
0 引言
海冰是极地及中高纬度地区的海洋灾害之一,海冰的漂流、冻结和融化将对海洋生产作业产生重要影响。当部分海域发生大面积海冰灾害时,会对近岸港口、航海船只、海上资源开采平台造成不可估量的财产损失。为了正确评估海冰冰情确保财产安全,需加强海冰检测的研究并提高海冰类型识别能力[1]。
相较于其他传统的海冰检测方式,遥感海冰检测技术因能提供全天候、大面积、实时、准确的海冰信息,现已被广泛应用于海冰检测中。一般地,海冰遥感检测方式可大致分为监督分类、非监督分类和半监督分类。其中监督分类方法因为操作方便,可加入先验知识,检测精度高等特点,在海冰检测中具有较大的优势[2]。支持向量机(support vector machine,SVM)[3]是一种典型的监督分类方式,因为其对高维、小样本数据具有很好的泛化能力,近几年在遥感分类领域备受关注[4]。
监督分类的训练模型依赖标签训练样本的数量和质量,然而由于海冰覆盖区域地理环境的特殊性,对海冰遥感图像进行大量人工标注是一项非常耗时、困难的工作[5],尤其对地物类别交错复杂的区域进行标注,标签样本的质量往往难以得到保证。正因为人工标注上的困难,使得分类中获取大量高质量的训练样本往往很困难。针对上述的这种情况,本文提出将主动学习(active learning,AL)[6]与半监督学习(semi-supervised learning,SSL)[7]相结合,利用少量的标签样本及未标签样本一起建立模型解决海冰分类问题。
主动学习是一个人机交互的迭代过程[8]。在每次迭代过程中,分类器不再是被动地接受标签样本,而是通过采样算法主动地选择对于当前分类器模型最有价值的未标签样本,经人工标注后添加到标签样本集中,再利用更新后的标签样本集重新训练当前分类器模型。这一过程不断迭代,直到满足迭代的停止条件。利用主动学习,可以有效避免标注那些信息量低的样本,缩减标注时间及成本,从而在较小标注代价的情况下,获得较高的分类精度。
主动学习借助采样策略实现在较小的标注样本的情况下,获得较高的分类精度。但是主动学习训练模型阶段仍然依赖于专家标注样本。而半监督学习可以充分利用未标签样本中隐含的信息,更好地刻画地物类别分布,进一步减少人工标注的成本,并可获得更精确的分类模型。半监督学习也先从少量标签样本开始训练模型,不断扩充未标签样本加入训练样本集来更新当前分类器。直推式支持向量机 (transductive support vector machine,TSVM)[9]是一种典型的半监督学习方法,在建立模型阶段直接使用未标签样本。
尽管AL(监督学习)与TSVM(半监督分类)工作机制不同,但它们在减少人工标注成本、提高分类器精度方面具有内在相似性,将这2种方法进行结合是可行的。因此本文提出将主动学习技术和半监督技术相结合应用到海冰监测中,以期获得更加精确的海冰分类模型,为海冰监测的进一步深入研究提供理论依据。
1 基于主动学习与半监督学习的海冰分类
1.1 主动学习
1)主动学习。主动学习这一概念首先是由Angluin[10]提出,通过迭代扩充标签样本集选择有价值的样本交由专家标注,利用扩充后的训练样本集更新分类模型。一般地,主动学习过程可以用形如 (C,Q,E,T,U)[11]五元模型描述。其中,C是从标签样本T训练得到的监督分类器模型;Q是用于从未标注样本池U中选择最具信息量样本的采样函数;E是对选择的最具信息量样本进行标注的人类专家。
采样函数Q是主动学习最核心的部分。分类模型通过采样函数主动地选取信息含量大的未标签样本交由专家标注。不同的采样函数也是区分不同主动学习算法优劣的关键环节。边缘采样(margin sampling,MS)是不确定性采样的典型方法,然而MS方法仅适用于二类(two-class)SVM分类问题[12]。Joshi等提出了一种基于最优标号和次优标号(best vs second-best,BvSB) 的主动学习方法[6],可以较好地解决实际分类问题中的多类(multi-class)分类情况。
基于不确定性的采样策略面临的一个重要问题:当SVM分类面通过一个未标记样本密集区域时,那么存在大量样本分布在分类边界附近,同一聚类的样本通常具有相同的标记,若将大量样本交由专家标记,势必会增加人工标注成本。为解决这个问题,我们提出同时考虑通过差异性标准选择差异性较大的样本,尽量减少所选样本的冗余。因此本文采用不确定性准则与差异性准则结合的方式选择对当前分类器最具信息量的样本。其中不确定性采样策略选择BvSB采样方法;差异性准则采用改进的聚类算法实现差异性标准(enhanced clustering-based diversity,ECBD)。通过BvSB-ECBD方式,实现样本信息量和信息冗余之间的平衡,尽量在主动学习的每次迭代中选出最具代表性的样本。
2)基于BvSB-ECBD的主动学习查询策略。首先简单介绍下BvSB方法。假设一组未标签样本集U={x1,x2,…,xn},Y={y1,y2,…,yk}为所有可能出现的标签。利用已建立的训练模型,对未标签样本xi进行标签预测,并计算样本xi属于每个类别的概率P(yi|xi)。BvSB方法只考虑最优标号和次优标号的概率,即P(yBest|xi)和P(ySecond-Best|xi),避免了其他类别的干扰,BvSB主动学习准则可以描述为:

(1)
式中:argmin()为括号中样本xi差值最小的值所对应的下标i作为Cuncertainty(xi)的输出值。Cuncertainty(xi)的值越小,代表样本的信息含量越高,越有利于提高分类模型预测的精度。通过BvSB主动学习算法从样本集合U中,选择k个Cuncertainty(xi)值较小的样本,经标注后添加到训练样本集中。根据BvSB不确定性采样所选择的k个样本(x1,x2,…,xk),再利用ECBD主动学习算法进行差异性选择。首先,利用径向基核函数(radial basis function,RBF)将选出的k个样本映射到高维的特征空间中(通过解决高维空间中线性可分的情况,来解决原始空间中线性不可分的问题),在特征空间中将BvSB主动学习选择的k个样本划分成h(h (2) 1)TSVM半监督学习。TSVM这一概念是由Vapnik[3]首先提出。其主要思想是利用较少的标签样本和大量易获取的未标签样本共同建立分类模型[7],提高分类器的泛化能力。下面将对TSVM的原理进行简单介绍。 (3) 2)融合主动学习思想的TSVM查询策略。因为未标签样本数量庞大,因此基于主动学习选择信息含量大的样本的思想对TSVM未标签样本选择模块进行改进,利用未标签样本查询函数,在保证未标签样本所含信息量大的同时,避免大量冗余信息样本的加入。 (4) 式中:SV是支持向量集;αi和b是用来确定最优分类超平面的参数。对于海冰分类的问题,利用RBF核函数作为分类器的核函数,即k(·,·)。通过融入主动学习的算法思想从半标签样本集中选择信息含量大的样本[15-16]添加到训练集中,其数学模型可表示为: C(x)=f1(x)-f2(x) (5) H={x|x∈U,0≤C(x)≤2} (6) 通过置信度C(x)确立一批信息含量丰富的未标签样本集。其中x代表未标签样本,f1(x)和f2(x)则是在多个二类分类模型中构成的一对多分类框架下的最高和次高的决策函数的值。通过划定C(x)的范围确立信息含量更高的半标签样本集H,其中C(x)的值越接近于2越有利于优化分类超平面 (即分布在分类超平面附近的样本)[16]。通过采样算法从H中选择γ个样本。对于选中的这部分半标签样本,它们同样存在冗余信息的情况。因此需要对选出的γ个样本进一步筛选。本文利用RBF核函数将选出的这部分样本映射到高维特征空间中,并在特征空间中用核余弦相似性准则从已选择的γ个样本选择ρ(ρ<γ)个半标签样本。核余弦角相似性准则公式表示为[17]: (7) 主动学习和半监督学习都基于减少人工标注代价并提高分类精度的共同出发点,在实现方法上也具有内在的相关性。本文将基于BvSB+ ECBD的主动学习和TSVM半监督学习结合引入到遥感海冰图像分类中,在提高分类精度的基础上进一步减少初始标签训练样本的数量。 首先,通过主动学习迭代一定的次数选择信息量大、有代表性的标签样本,获得较可靠的分类器后再对未标签样本进行预测;再利用融合主动学习的半监督学习算法,从大量未标签样本中选择信息含量高的样本作为半标签样本,利用标签样本集与半标签样本集共同训练TSVM分类模型。将主动学习与半监督技术的结合的优点在于:一方面利用主动学习算法主动选择最有价值的样本加入到标签样本集中解决海冰检测中标签样本不足的问题;另一方面可以充分利用大量未标签样本的信息进一步减少标注成本并提高分类精度。 本文提出的海冰图像分类算法包括2个模块,即AL模块和TSVM模块,分类框架图如图1所示。 1)主动学习模块。首先确立未标签样本集U,并将训练样本集T1设置为空。在初始分类时,从未标签样本U中随机选取k个未标签样本,经人工标注后,建立初始的标签训练样本集T1,更新未标签样本集U和训练样本集T1。用训练样本集T1建立初始的SVM分类器,对未标签样本集U中的样本进行预测,并获取未标签样本属于每个类别的标号概率信息,即p(yi|x),yi∈Y,x∈U。 图1 基于AL-TSVM的海冰分类总体框架图 对于主动学习采样模块,采用不确定性与多样性结合的方式来选择未标签样本,即BvSB-ECBD。根据BvSB准则,首先从U中选取k个不确定性高的样本,记为kBvSB。再基于ECBD多样性准则从kBvSB个样本中选择hBvSB-ECBD个未标签样本,将hBvSB-ECBD个样本经人工标注后,添加到训练样本集T1中,利用更新后的T1重新训练SVM分类器。这一过程重复进行,直到迭代的次数达到预先设定迭代次数后停止。 2)半监督学习模块。当满足主动学习的停止条件后,将主动学习最后一次迭代确立的标签训练集T1作为TSVM初始的标签训练样本集T2。对于TSVM模块,从剩余的未标签样本集U中定义样本池psemi。首次利用初始的标签训练集T2来建立分类器模型,将主动学习思想融入半监督样本选择中,从psemi中确立半标签样本集。通过决策值来选取在区间[0,2]内的γ个半标签样本,再利用核余弦角相似性度量法则,从γ个半标签样本中选择ρ个最具代表性的半标签样本。最终,将ρ个半标签样本添加到T2中,更新训练样本集T2和半标签样本池psemi。更新后的T2就包含标签样本集与半标签样本集,利用更新后的T2建立TSVM分类模型,通过迭代的方式不断扩大训练样本集T2,利用每次更新后的T2重新训练分类模型,这一过程重复进行直到满足条件迭代次数才停止。 具体的AL-TSVM算法描述如算法1所示。 为了检验提出方法的可行性,利用2016年1月27日渤海鲅鱼圈区附近海域Landsat-8数据进行实验。因为海冰实测数据难以获取,用相同场景4.77 m分辨率的天地图遥感图像作为基准数据,然而实验数据与基准数据有3 d的时间差,但对于沿岸海域,海冰的分布基本一致,海冰受潮汐、洋流等外界影响因素可降低至最低。因此,选择2幅图像中沿岸重叠的区域进行海冰图像分类实验。图2(a)是选取实验区域图像,图2(b)是从图像中选取训练数据区域分布图。红色代表白冰,绿色代表灰冰,蓝色代表灰白冰。其中实验中的训练样本与测试样本如表1所示。 图2 实验数据 类别训练样本的数目测试样本的数目白冰 430300灰冰 423300灰白冰450300共计 1 303900 本次实验使用支持向量机作为基础分类器,以RBF核函数作为支持向量机分类器的核函数。对于支持向量机中所用到的两个参数:RBF核函数g和正则化参数c,对训练样本集用5倍交叉验证,估计不同c、g参数的性能。对于主动学习模块,随机从未标签样本池中选出9个样本建立初始标签样本集,通过主动学习查询函数每次选择6个样本添加到主动学习的训练样本集中,更新当前分类模型。对于TSVM模块,利用半标签样本采样算法每次添加6个半标签样本加入直推式支持向量机的训练样本集中。利用更新后的样本集训练分类器。并对相同场景内的基准图像区域使用混淆矩阵进行性能性评估,并用总体的平均分类精度显示算法的性能。 图3是BvSB-ECBD-TSVM方法与主动学习及随机采样方法总体分类精度的比较。从图3可以看出,随机采样得到的最终分类精度只达到89.76%,而采用主动学习最终分类精度达到92%。这是因为随机采样算法对样本的选择具有较大的随机性,并不能确保所选样本的信息量,而主动学习是主动地选择一部分信息含量高的未标签样本进行标注,避免了样本选择的随机性,可有效提高分类器模型的泛化能力。 图3 BvSB-ECBD-TSVM与随机及主动学习分类精度的比较 相对于随机采样算法,主动学习建立的分类模型可进一步提高分类精度。然而不同的主动学习方法,因为采样方式不同,它们的性能也存在着差异。从图3可以看出:在获得相同分类精度的情况下,BvSB-ECBD方法的迭代次数明显小于BvSB与Entropy的迭代次数。例如,当BvSB-ECBD的分类精度达到89.36%时,只需要4次迭代,而BvSB方法则需要迭代6次,Entropy方法则需要迭代7次才能达到近似的精度。这也说明了BvSB-ECBD方法基于多样性与不确定性2个准则选择的样本更具信息量和代表性,更加有利于提高海冰的分类精度。 当BvSB-ECBD主动学习过程迭代8次,已经确定了一定数量的标签样本。TSVM半监督学习在已建立的标签样本集的基础上,再利用半标签样本,优化分类超平面,进一步地提高分类精度。从图3可以看出,BvSB-ECBD-TSVM的最终分类精度可达到96.54%,相对于BvSB-ECBD最终的分类精度,精度提高了6.78%。这表明在BvSB-ECBD主动学习后,TSVM算法可利用那些分布在标签样本周边的半标签样本调整分类超平面。在标签样本的基础上,通过半标签样本采样算法选出半标签样本建立预测准确率更高的TSVM分类模型。 因为半监督学习对初始标签样本集具有一定的敏感性[16],本文进行了主动学习迭代不同次数的标签样本集对TSVM分类精度的影响实验。在实验中TSVM初始标签样本集是由BvSB-ECBD方法确定的,利用10组独立的数据实验,并取它们总体精度的平均值来显示分类结果。 表2表示的是BvSB-ECBD主动学习迭代不同次数确立的标签训练样本集对后续TSVM分类精度的影响。从表2中可知:当BvSB-ECBD只迭代2次的情况下,后续TSVM所得到的分类精度要低于BvSB-ECBD迭代次数更多时所得到的TSVM分类精度。当BvSB-ECBD只迭代2次时,TSVM总体的分类精度会存在一定的波动;而当BvSB-ECBD迭代4次时,总体分类精度随着TSVM迭代次数的增加相对稳定;当BvSB-ECBD迭代8次时,总体分类精度的波动明显减少,这是因为TSVM对初始标签样本集比较敏感,虽然BvSB-ECBD可以选择可靠的标签样本,但是当标签训练样本数量较少时,TSVM选择的半标签样本对分类超平面的优化存在歧义,存在着部分样本标签类别误判的情况,会导致TSVM分类精度下降,因此需要主动学习迭代一定的次数,以获得足够数量的标签样本。但是随着主动学习迭代次数的增加,标签样本集的数量不断扩大,人工标注的工作量也在增加,为了在标注成本与分类精度之间取得平衡,本文采用BvSB-ECBD迭代8次时确定的标签样本集作为后续TSVM分类器的初始标签样本。 表2 不同大小的BvSB-ECBD标签训练样本集对TSVM总体分类精度的影响 % 图4是不同的主动学习方法迭代8次后分别与TSVM结合的分类精度图(其中,前8次迭代由不同主动学习方法分别得到的分类精度,9到15次则代表结合TSVM后总体的分类精度)。从图4可以发现:在主动学习的前8次迭代中,本文BvSB-ECBD方法所获得的海冰总体的分类精度要明显高于其他方法的精度,说明在少量的初始标签样本的情况下,利用BvSB-ECBD方法可获得更高质量的标签样本。BvSB-ECBD-TSVM与其他结合方法相比,BvSB-ECBD-TSVM仍然获得最高的分类精度,并且明显高于只采用主动学习(BvSB-ECBD)的分类结果,这一方面说明TSVM对主动学习选择的标签样本集比较敏感,高质量的标签样本可以改进TSVM的分类精度,另一方面也说明与TSVM结合后,利用大量的未标签样本所包含的信息,确实可以提高分类精度。 从图4也可以观察到:Random-TSVM这种结合方式的分类精度不够稳定,并且分类精度和其他方法比起来精度明显偏低,这是因为随机采样方式,对样本的选择具有较大的随机性,导致总体上分类精度较低而且不稳定。综上,本文建议的BvSB-ECBD-TSVM方法在进行海冰检测过程中具有较好的优势。 图4 不同方法与TSVM结合的分类精度的比较 为了更清晰地展示提出建议的方法对海冰分类的效果,本文选取部分海域进行海冰分类实验。图5(a)是选择的实验海域的原始海冰图像;图5(b)是选择的部分标签样本集;图5(c)是基准图像的分类图,其中红色代表白冰,绿色代表灰冰,蓝色代表灰白冰;图5(d)表示的是BvSB-ECBD-TSVM方法的分类结果图。本实验中的海冰总体平均分类精度可达到96.31%。我们选择最后一次得到的预测标签与基准标签计算Kappa系数,Kappa系数为92.15%。从实验结果可以看出,本文建议的方法结合了主动学习和半监督方法的优势,利用少量的标签样本,借助于主动学习方法选择出高信息量和代表性的样本进行标注,并充分利用大量未标签样本包含的信息,达到了较好的海冰分类效果,可以有效用于海冰检测。 图5 海冰检测分类结果 针对遥感海冰检测中标签样本获取困难、遥感图像标注成本较高及海冰检测精度偏低等问题,本文提出一种将主动学习和半监督技术相结合的方法进行海冰检测,并将该方法与其他传统方法进行了对比分析。实验结果表明,BvSB-ECBD-TSVM方法可在较少的人工标注成本的情况下,在总体上获得较优的检测性能,具体总结如下: ①主动学习可选择一批信息含量丰富且有代表性的样本建立分类模型。因主动学习采样策略不同,导致最终的分类精度表现出一定的差异性,基于BvSB-ECBD的采样方式要优于其他采样方法。 ②从实验中可知,半监督学习可以充分利用未标签样本的分布信息可进一步提高分类精度。通过主动学习与半监督学习结合的方式可解决海冰分类中因标签样本不足导致分类器泛化能力受限的问题。这种结合方式,提高分类精度的同时进一步减少人工标注样本的工作量。 ③因为半监督学习对初始标签样本具有一定的敏感性,本文利用主动学习选择一批信息含量丰富的标签样本,并作为TSVM初始的标签样本。实验结果表明,合理的主动学习迭代次数可以达到标注成本和分类精度之间的平衡,实现用尽量少的标注成本获得更高的分类精度,达到较好的海冰分类效果,为海冰检测提供了一种新的方式。
1.2 半监督学习
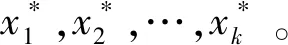



2 主动学习与半监督技术相结合的海冰分类算法
2.1 算法实现框架

2.2 算法描述

3 实验与分析
3.1 数据描述


3.2 实验设置
3.3 BvSB-ECBD-TSVM与主动学习方法的精度比较

3.4 主动学习迭代次数对分类精度的影响

3.5 不同主动学习方法与TSVM结合的分类精度比较

3.6 海冰实验分类效果图

4 结束语
