视听相关的多模态概念检测
2019-05-15奠雨洁
奠雨洁 金 琴
(中国人民大学信息学院 北京 100872)
近年来,计算机和移动网络技术逐渐成熟,互联网上出现了很多视频分享应用.视频应用的流行,使互联网上的视频数量快速增长.面对互联网上海量的视频,如何对视频进行分类、索引,从而帮助用户更高效、更准确地获取所需视频,成为亟待解决的问题.视频语义概念检测就是利用计算机自动地检测视频中包含的语义概念,如场景、事件、动作、事物等.将视频按照语义概念进行组织和管理,有助于构建结构化的视频检索数据库,能够更方便地为用户提供基于关键字的检索方式,从而更有效地为用户提供视频检索服务.
随着网络视频数量的快速增长,人们对视频检索的要求也越来越精细化.例如在动物养殖领域,人们可能需要通过视频了解动物在不同叫声状态下的表现,因此,人们可能会检索“dog woof”(狗欢快地叫)、“dog howl”(狗嚎叫)或“dog bark”(狗汪汪叫),而目前大量的视频层次化管理中并没有提供这样精细化的组织结构,因此用户只能得到有狗这一视觉形象或者包含任何狗叫声的视频,而无法区分更细粒度的满足要求的视频.在大量的应用场景下,需要声音和视觉形象同时出现,才能确定某个视频事件.目前大量的视频层次化管理中都倾向于将视频按照视觉信息所表达的概念进行组织,这样的组织方式忽略了视频具有多模态的特性.因此,本文考虑是否可以将视频语义概念组织成具有视听信息的多模态概念.这类多模态概念通过语义相关的视听信息共同来描述视频主要内容,将会更有助于满足用户的精细化检索需求.通过以这类语义概念为目标进行概念检测,应该可以学习到视频底层特征与高层语义之间更精细化的特征表示.
视频是多模态的信息源,不同模态的信息通过不同的方式表达和某个语义概念相关的的信息.因此,对于具有视听信息的多模态语义概念,自然可以使用视频中内在的视听信息来进行语义概念的检测.视频中的视听信息具有天然的相关性,与多模态概念本身的视听相关性是一致的,因此,本文使用卷积神经网络(convolutional neural network, CNN),利用视听相关性为监督信息进行多模态概念检测的研究.
本文的主要贡献在于:首先,本文提出了具有视听信息的多模态语义概念检测任务.多模态概念中视听信息具有相关性,更能满足用户的精细化检索需求,也更能准确描述视频中的语义信息.其次,以多模态概念为检测目标,本文使用CNN对视频进行端到端的概念检测.除了单模态的概念检测系统,本文利用视频的视听相关性为目标训练了多模态联合网络,该网络包含了3个子网:视觉子网、听觉子网、多模态联合学习子网.通过视听相关的多模态联合网络能够学习到精细化的特征表示.利用该网络还能够提取听觉和视觉特征,进而有效用于其他多媒体分析中.
1 相关工作
目前研究领域常见的语义概念通常包括场景、物体、事件、动作、情感等概念.有多种方式构建不同需求的语义概念.在文献[1]中,作者通过形容词-名词的形式构建了3 000多个具有情感信息的视觉概念集(visual sentiment ontology, VSO);在文献[2]中,作者通过WikiHow(在线问答网站)中定义的事件标签以及相关文本,提取了4 490个事件概念形成EventNet,涵盖日常生活中的运动、家务等事件;在文献[3]中,作者通过美国时间使用调查报告(American time use survey, ATUS)中对人类活动的分类,定义了203个人类活动的概念并组织成层次化的结构形式形成ActivityNet,这些概念包含了工作、吃喝、家务等不同的日常活动;文献[4]中,作者在网络文本中寻找有声音属性的词,然后在Freebase等知识库中对原始种子声音词进行匹配和筛选,得到一个层次化的声音事件概念集AudioSet.
在这些概念集上进行的语义检测方法大致分为2类:基于模块化流程的语义概念检测和基于神经网络的端到端的语义概念检测.模块化流程的检测方法包括:视频预处理、特征提取、分类器训练和预测.例如,对于VSO的概念检测,作者使用相关图片的低层视觉特征(颜色直方图、局部二值特征等),并使用支持向量机(support vector machine, SVM)训练了对应的情感概念检测模型[1].对于EventNet的检测,作者使用在视频上预训练的卷积神经网络(convolutional neural network, CNN)提取中间层特征,基于该特征使用SVM训练了事件概念检测器[2].文献[5]中分别提取了视频中图像的颜色和纹理特征,短时音频帧特征和转录的文本特征,利用视频的多模态特性和相似度融合的方法,利用SVM进行常见概念的检测.基于神经网络的端到端的检测方法直接使用视频的帧或音频信息作为输入,通过网络学习视频与概念之间的相关性.例如文献[6]中作者使用CNN输入图像,进行视觉情感概念的检测.文献[7]中,作者探究了不同的CNN结构,对一个大规模视频数据集进行分类研究,其中CNN的输入直接使用视频中音频流的频谱图.文献[8]中利用视频的帧图像、光流帧、音频流的声学特征作为CNN的输入,进行人类动作的识别.
利用端到端的方式学习视频概念的好处在于,它保留了视频的原始信息,减少了特征提取环节可能造成的信息缺失.而且使用CNN通过分层的形式,可以学习到底层到高层之间的不同层次的特征,因此网络模型可以当做一个特征提取器,从中提取特征并有效用于其他任务中.例如文献[9]中作者使用了一个学生-老师的CNN结构,老师网络利用视觉先验知识作为监督,学生网络输入原始的音频流,网络能够学习到有效的音频特征表示.通过该网络可以从不同卷积层提取特征,在音频分类等任务上都表现出优异的性能.因此,本文将使用CNN探究端到端的概念检测方法,对视听相关的多模态概念进行概念检测研究.
2 视听相关多模态概念集的定义
2.1 视听相关多模态概念的定义
通过预先定义好的语义概念集为检测目标对视频进行分析,学习到的视频特征表示更具有语义信息,可以适当弥补语义鸿沟[10].本文提出具有视听信息的多模态概念.一个多模态概念必须同时具有听觉和视觉信息.因此,本文提出以名词-动词二元组的形式表示一个语义概念,从概念的名词中可以感受到视觉信息;从概念的动词中可以感受到听觉信息,且视听信息是相关的.多模态概念的定义和收集过程如图1所示:
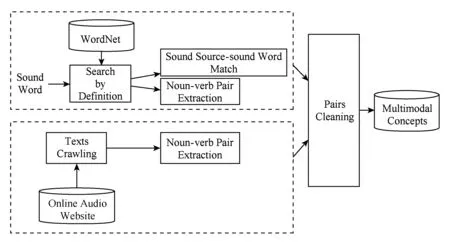
Fig. 1 The collecting procedure of multimodal concepts图1 多模态概念的定义和收集
本文多模态概念,从声音出发,其收集过程主要分为2种形式:1)基于象声词的多模态概念.从英文象声词在WordNet[11]中的定义寻找通过“Sound by(of)”连接的名词,该名词表示象声词对应的发声物,将发声物和象声词组合形成多模态概念;除此之外,还爬取象声词在字典[注]https://en.oxforddictionaries.com中对应的例句,将例句中抽取的短语关系为“nsubj(名词主语)”的名词-动词二元组作为多模态概念.2)从在线音频网站[注]www.freesoundeffects.com中对应音频的标题描述中抽取短语关系为“nsubj”的名词-动词二元组,形成多模态概念.最后,对收集的名词-动词二元组进行短语清洗和过滤,删除一些拼写错误或没有意义的词(如人名、地名、颜色词等),形成具有视听信息的多模态概念集,共包含2 098个概念.
多模态概念集是从声音出发构建的,因此自然具有听觉特性.本文将多模态概念的名词输入到ImageNet[12]中查找是否存在相应图片,分析发现,78%的多模态概念的名词能够在ImageNet中找到图片,这说明提出的多模态概念具有视觉信息.概念收集过程中,通过约束象声词及其发声物和抽取具有语法关系的短语,也保证了名词和动词之间是具有相关关系的.因此,最终的多模态概念是视听相关的语义概念.
2.2 视听相关多模态概念视频数据的收集
具有视听信息的多模态概念,目前没有专门的数据集,本文尝试直接使用2.1节定义的多模态概念到视频网站爬取了一部分视频,但视频时间长、噪声大、标注过程耗时耗力.由于本文的多模态概念是从声音出发定义的,AudioSet[4]中也包含了对音频事件的标注,而且提供了对应的视频数据,因此本文使用AudioSet作为多模态概念的数据来源.将多模态概念与AudioSet中的标签进行比对,如果概念的名词和动词都在某一个视频的标签里,则将这个视频作为多模态概念的样例视频.通过这种方式,共收集了93个概念对应的视频,作为多模态视频概念检测的数据.视频总数量为88 957,每个视频为10 s,总时长约为247 h.93个多模态概念及对应的视频数量分布见附录A.
3 端到端的多模态概念检测
针对2.2节中93个多模态概念,本文使用CNN进行端到端的语义概念检测.在语义概念集给定的情况下,视频概念检测转化为视频的分类问题.因此,本文的概念检测系统输入是一个视频和预定义的语义概念集,输出是与这个视频相关的多模态概念.本文将分别探索单模态的概念检测框架和多模态联合学习的概念检测框架.
3.1 单模态网络结构
本文基于视觉信息的概念检测系统,网络的输入是224×224的彩色图像.使用VGG16[13]作为基本网络结构,修改最后一个预测层神经元个数为93,并使用softmax输出预测概率.
基于听觉信息的概念检测系统同样使用VGG16作为基本结构,听觉网络的输入是大小为96×64的音频频谱图.修改全连接层神经元个数为1 024,最后一个预测层使用softmax输出93个多模态概念的预测概率.
3.2 视听相关的多模态联合网络学习
本文的视频概念检测的目标是多模态概念.多模态概念中体现了具有相关关系的视听信息.针对这类概念的检测,本文认为可以利用视频中视听信息的相关性.在大多数情况下,视频中的视觉信息和声音信息是同时出现的.因此,本文提出利用视频的视听相关性作为监督信息,同时使用视频的视觉信息和听觉信息进行端到端的视频概念检测.
3.2.1 联合学习网络结构
本文借鉴L3-net的网络结构[14],具体来说,网络的输入是语义相关的1帧图像和1个音频片段.语义相关指的是,图像中反映的语义概念与音频片段中的语义内容是有关联的.网络共包括3个子网结构:视觉子网、声音子网和联合学习子网.其中视觉子网使用VGG16的前5个块(block).听觉子网结构与视觉子网结构类似,使用VGG16的前5个块.联合学习子网由2个全连接层组成,它的输入是视觉子网和听觉子网各自最后1个池化层的输出进行全局最大下采样后,再拼接得到的1024维的向量.在融合网络中训练输出视频相关概念的预测概率.详细的网络结构如图2所示.本文提出的基于视听相关性的联合学习框架用于多模态概念检测,其中视觉信息和听觉信息在本文中使用了VGG16作为网络学习的主要结构,但其他典型的视觉、听觉网络结构也可以应用于该框架.
3.2.2 视听相关采样
联合学习的网络,同时接收语义相关的1帧图像和1个音频片段为输入,以视听信息的相关性为监督信息来学习视频.在数据预处理阶段,需要采样语义相关的帧和音频片段.本文假定某一个概念的样例视频中截取的帧和音频片段和这个概念是相关的,且来自一个视频的帧和对应的音频也是相关的.因此,从每个语义概念对应的视频中随机选择1个视频帧,选择这一帧所在的视频片段所对应的音频,由此组成的(帧-音频片段)二元组作为与这个语义概念相关的视听信息正例.

Fig. 2 The proposed multimodal joint network architecture based on audio-visual correlation图2 基于视听相关性的联合网络结构图
4 多模态概念检测实验分析
4.1 实验数据
本文实验数据使用2.2节中得到的93个多模态概念及对应的视频.实验数据分布如表1所示.
4.2 实验设置
本文中网络结构的实现使用keras框架[注]https://github.comfcholletkeras,后端使用Tensorflow[15].所有网络结构的训练,使用Adam优化器[16],学习率为10-4,权值衰减为10-5.
对于概念检测的性能评估,本文使用mAP(mean average precision)和AUC(area under curve).这2个指标mAP和AUC的计算见文献[17].
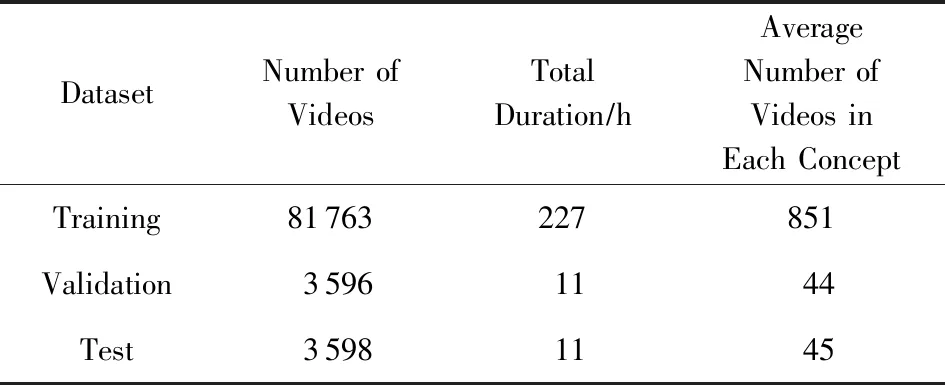
Table 1 Data Distribution of Our Multimodal Concepts Dataset表1 多模态概念检测实验数据分布
4.3 单模态概念检测结果及分析
4.3.1 实验说明
视觉网络实验中,在预处理阶段,每一个视频抽取了10帧图像,每帧图像处理成224×224的固定大小.每帧图像继承其对应视频的标签,输入到网络中参与训练;测试阶段,将视频每一帧图像的预测概率进行平均作为视频的概念预测概率.
听觉网络实验中,预处理阶段提取视频的音频流,每个音频流被切分成980 ms的音频片段,每个音频片段处理成频谱图的形式,大小为96×64(音频的预处理同文献[7]).训练阶段,每个音频片段继承视频的标签,输入到网络中进行训练.测试阶段,每个音频片段的概念预测概率进行平均作为整个视频的预测概率.
实验对比的基准方法是基于模块化流程的概念检测方法.分别对视频帧和音频提取视觉和听觉特征,使用SVM分类器进行视频的概念检测.
4.3.2 实验结果分析
基于单模态神经网络的概念检测实验结果如表2所示.
由表2中可以看出:1)基于CNN进行端到端视频概念检测,其mAP值相较于使用特征加SVM分类器的流程式方法性能更优,在听觉网络上mAP提高了9%,在视觉网络上,基于ImageNet预训练权重初始化的端到端网络比流程式的方法提高了12.5%.流程式方法将特征表示和分类训练分离开,而CNN端到端网络直接对池化层特征继续做分类,较好地保持了原始信息,实验结果验证了CNN网络结构在学习特征上的有效性.2)视觉网络中,使用ImageNet预训练权重效果更好(mAP比从零训练的视觉网络高50%).这说明了预训练模型的先验知识的重要性.而基于本实验视频帧的网络,因为实验数据集和多模态概念是弱相关,因此训练数据的帧图像和最终检测的概念可能存在并不相关的情况.例如多模态概念集中存在“thunder_growl”(电闪雷鸣)这类听觉特征更明显的概念,其视觉特征并不能较好地发挥作用.此外,训练数据较少也可能是潜在原因.3)听觉网络的检测性能明显优于视觉网络的检测性能.这一方面是由于10 s的视频中听觉信息比视觉信息更丰富,因此,更能捕捉到有区分性的信息;另一方面,可能由于实验数据集的来源本身是一个以声音为标注的数据集,因此,选择的多模态概念本身听觉信息比视觉信息更明显,即听觉信息在这类概念中发挥的作用更明显.
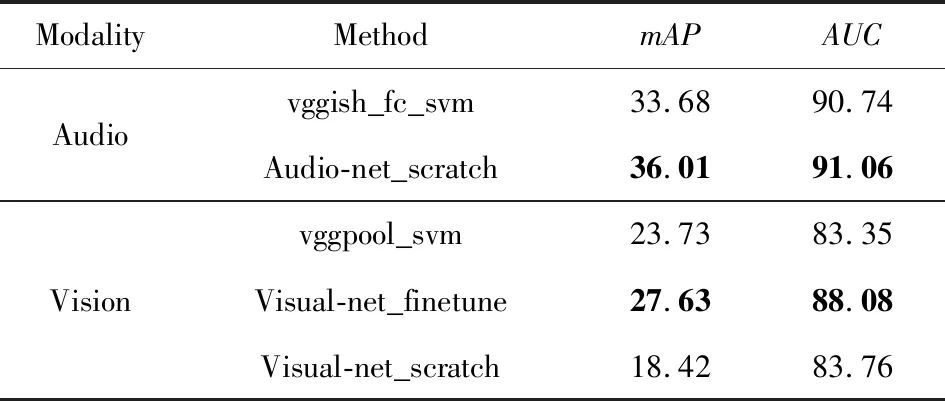
Table 2 Concept Detection Results Based on Single-modal Network表2 基于单模态网络的视频概念检测结果 %
vggish_fc_svm: SVM classifier with 128 dimensional features from the fully-connected layer of VGG trained on Youtube8M(audio only).
Audio-net_scratch: End-to-end concept detection network with our dataset (audio only) from scratch.
vggpool_svm: SVM classifier with 512 dimensional features from pool5 of VGG trained on ImageNet.
visual-net_finetune: Fine-tuning model on our dataset from an ImageNet pre-trained VGG model.
visual-net_scratch: End-to-end concept detection network with our dataset (visual frames only) from scratch.
将视觉网络和听觉网络检测出的概念按照AP(average precision)进行排序.表3展示了AP值最高的前5个概念.基于预训练权重的视觉模型,对“train_clatter”(火车行驶中)的检测结果效果最好,达到85.73%.分析发现,视觉网络结果最好的这几个概念,本身就具有更强的视觉信息.这5个概念都包含了具体的物体(train,computer,boats,blender,ball),而在视频中也都有这些物体的具体存在.因此,基于在ImageNet训练得到的视觉网络自然能够捕捉到这些信息.而在本实验数据集上训练的视觉网络(视觉网络_scratch)中,AP值最高的前5个概念,也有相同的发现:概念本身包含的视觉信息更明显.

Table 3 Top 5 Concepts with the Highest AP (Based on Visual Network)表3 AP最高的前5个概念(视觉网络) %
而听觉网络AP值最高的前5个概念,如表4所示,和视觉网络检测出的概念都不相同,这说明了这些概念之间的听觉区分信息更强一些.但是“crowd_cheer”(观众欢呼)在视觉和听觉网络上的AP值都很高.事实上,将听觉网络和视觉网络检测的概念AP值进行排序,前50个概念中有32个概念是重合的.这也说明了概念集本身具有了多模态的特性.

Table 4 Top 5 Concepts with the Highest AP (Based on Audio Network)表4 AP最高的前5个概念(听觉网络) %
4.4 多模态概念检测实验结果及分析
4.4.1 实验说明
视频预处理时,每个视频抽取10帧图像.视听相关性采样中,随机选择4帧图像,并选择每一帧所在视频片段的音频提取频谱图,将每一个帧-频谱图二元组,继承视频标签,输入网络进行训练.实际训练中,本文采取2种方式更新整个网络权重:是否使用预训练权重初始化视听子网;使用视听相关性策略更新整个网络的所有权重或只更新融合子网(即全连接层)权重.预测时,每个视频的4个帧-频谱图二元组的平均概念预测概率作为这个视频的预测概率.
与多模态实验对比的基准方法是基于前期融合的流程式概念检测方法.前期融合选择的视觉特征是vggpool,听觉特征是vggish_fc,将特征进行拼接,输入到SVM中进行概念检测的判定.
4.4.2 实验结果分析
基于视听相关性学习的多模态联合网络的实验结果如表5所示:
Table 5Concepts Detection Results Based on Audio -VisualCoorrelated Joint Network
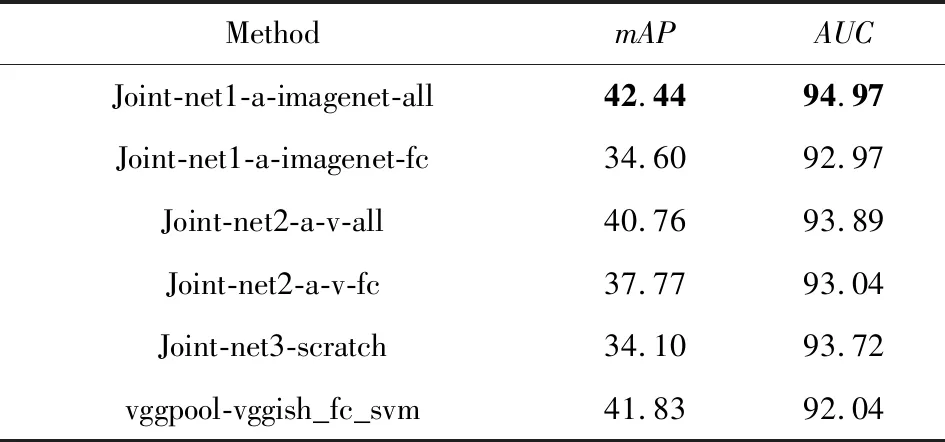
表5 基于视听相关的多模态网络概念检测结果%
Joint-net1-a-imagenet-all: Initializing the audio subset with audio-net_scratch in table2 and the vision subset with ImageNet pre-trained weights respectively, then the network learns and updates all weights.
Joint-net1-a-imagenet-fc: Initializing the audio subset with audio-net_scratch and the vision subset with ImageNet pre-trained weights respectively, then the network learns and updates weights of fully-connected layer.
Joint-net2-a-v-all:Initializing the audio subset with audio-net_scratch and the vision subset with visual-net_scratch respectively. then the network learns and updates all weights.
Joint-net2-a-v-fc: Initializing the audio subset with audio-net_scratch and the vision subset with visual-net_scratch respectively, then the network learns and updates weights of fully-connected layer.
Joint-net3-scratch: The network is trained using audio-visual correlation strategy from scratch with random initialization.
vggpool-vggish_fc_svm: SVM classifier with Early fusion withvggpoolandvggish_fcin table 2.
由表5可以看出:
1) 融合网络1-a-imagenet-all使用预训练权重且基于视听相关性更新融合网络所有权重,其mAP值有42.44%,是本文实验中的最高值.这一方面得益于ImageNet上的视觉先验知识,以及听觉网络通过CNN学到了有效的特征表示,经过结合能够提供互补信息,达到增强系统性能的效果;另一方面也体现了视听相关性学习的有效性.
2) 经过视听相关性更新所有权重的模型表现都比仅更新全连接层权重的表现好.在单独的视觉网络概念检测的mAP只有18.42%,但使用视听相关性训练的融合网络2-a-v-all,提升了1倍多的mAP值(40.76%).由于检测的是多模态概念,概念本身视听信息是相关的,而视频的视听内容也存在天然的相关性.因此,在基于视听相关性更新所有权重的过程中,有效地将相关性信息传递到了网络中,证明了视听相关反馈视觉和听觉子网的重要性.
3) 融合网络3-scratch使用随机权重从零训练的多模态网络,其mAP值是34.10%,比单独的听觉网络低了约2个百分点,本文推断和网络训练的数据有关系.视频中出现的声音不一定是连续的10 s,可能有其他声音的干扰,而听觉网络使用每个视频的所有音频片段训练,适当减少了这样噪音的影响,而视听融合网络随机选择4个二元组(音频数据的40%),这就造成了视听信息可能并不相关,增加了样本的不准确性.但是视听融合网络的AUC却比听觉网络的AUC高了近2个百分点,也证明了视听相关性在多模态概念检测中的有效性.
同样地,本文分析融合网络模型对多模态语义概念的影响.由于本文更关注视听相关性策略在多模态概念中的表现,因此,本文主要分析融合网络3-scratch对多模态语义概念检测的影响.表6中呈现了融合网络3-scratch所检测到的AP值最高的前5个概念.“crowd_cheer”(观众欢呼)的AP值最高,说明这个概念的视听信息相关度最高.这个概念在单模态网络中检测的AP值都居于前5,但基于视听相关性的网络仍然提高了其AP值.通过表6也发现了一些有趣的现象:如“rooster_crow”(公鸡报晓)这个概念的AP值比单纯基于前期融合或单模态网络要高.这个概念是通过象声词及其发声物匹配的方式收集的.象声词本身包含了发声物的信息,因此通过这种方式收集的多模态概念的视听信息是非常相关的.而这样的强相关性也正是视听融合网络用来学习的目标,因此检测结果较好.此外,在诸如“wind_blow”(刮大风)和“thunder_growl”(电闪雷鸣)这类语义概念中,视觉信息比较抽象,大量的视频中充满了人、雨伞,大多视频场景是室外,通过视觉信息不能很好地区分,但是加入视听信息相关性后就能够有效地与声音信息结合,从而增大其被检测出来的可能性.
Table 6Top 5 Concepts with the HighestAP(Based on Joint net3-scratch)
表6AP最高的前5个概念(基于融合网络3-scratch)%

4.5 多模态网络学习的精细化特征
在视听融合网络中还发现了网络能够学习到一些精细化的特征,能够区分一些视觉听觉上都很相似的语义概念.图3中给出了测试集上对应概念的预测率最高的5个视频中所截取的帧图像.从“dog_bark”(狗的“汪汪”叫)和“dog_howl”(狗嚎叫)图3中可以清楚地看到,“dog_howl”这个概念对应的视频当中的狗,都是头部呈90度上扬,狗的嘴巴张开的幅度较小,动作状态多为静止;而“dog_bark”这个概念对应的视频,狗几乎都是面向前方,嘴巴张开的幅度较大,动作状态多为跑动.实际上,这就是狗在不同状态下的表现.这2类概念视觉信息都是狗,而听觉信息都包含了狗叫的声音,视听信息都很相似的情况下,基于视听相关性的网络能够很好地将他们区分开来.

Fig. 3 Examples of learned fine-grained features from joint network图3 融合网络学习到的精细化特征示例
此外,在听觉信息上也体现了这样的精细化差异.例如“sheep_bleat”和“goat_bleat”,听觉上都反应的是羊“咩咩”叫的声音,但视觉上前者更多的是白色的绵羊,而后者更多的是黑色的山羊.值得一提的是,这些特征在基于单模态的网络结构或基于多模态特征融合的概念检测方法中都没能体现出来,这说明了视频视听信息相关性在视频分析中的重要性,也从侧面反映了基于视听信息的多模态概念的必要性.只有通过精细化的语义概念,才能更精确地构建起视频底层特征与高层精细化语义之间的桥梁.
4.6 多模态网络的视听特征有效性分析
本文的目标是通过构建具有视听信息的多模态概念,获得视频底层特征与高层语义之间更精细化的联系,因此,为了验证本文的多模态视听网络是否能够有效表示视频特征,本文将从文中基于视听相关性的联合网络模型中提取视听特征,在标准数据集上验证特征的有效性.
4.6.1 基于联合网络视觉子网的特征
验证视觉特征有效性的数据集是Huawei视频概念检测数据集[注]http://www.icme2014.orghuawei-accurate-and-fast-mobile-video-annotation-challenge.这个数据集包含了2 666个视频和10个语义概念,每个视频标注了其中相关的概念和它出现的片段.10个语义概念分别是:“kids”,“flower”,“city_view”,“car”,“beach”,“party”,“Chinese_antique _building”,“dog”,“food”,“football_game”.本文首先将每个视频按照标注信息切割成视频片段,每个片段有1个或多个概念标签,每个视频片段作为1个样本(每个视频片段不超过2 min).预处理后,共有5 828个样本,其中4 187个样本作为训练集,609个样本作为验证集,1 153个样本作为测试集.对每个样本,提取关键帧,输入到网络结构中得到图像特征,将每个关键帧的图像特征进行平均作为这个视频整体的视觉特征,使用SVM进行监督训练.评测指标为mAP.
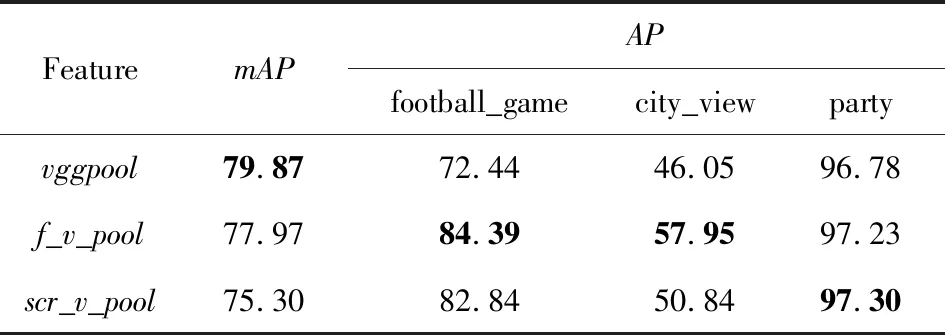
Table 7 Classification Results on the Huawei Dataset表7 Huawei视频分类结果 %
vggpool:512 dimensional features from pool5 of VGG trained on ImageNet with global max pooling.
f_v_pool: 512 dimensional features from the output of pool5 of vision subset in joint-net1-a-imagenet-all in table 5 with global max pooling.
scr_v_pool: 512 dimensional features from the output of pool5 of vision subset in joint-net3-scratch in table 5 with global max pooling.
在本文多模态融合网络的实验中,融合网络在学习过程中,视觉子网使用了ImageNet预训练权重,再利用视听相关性更新网络所有权重.因此实验将对比基于视听相关性更新网络前后的特征.表7中给出了在整个测试集上的mAP和在特定概念上的AP值.
整体来说,在这个数据集上,vggpool的效果略优于本文的视听融合网络的特征.因为Huawei数据集上某些概念在本文所使用的视频集中没有出现,但是在ImageNet中出现过,比如 “flower”,“food”.在这些类别上由于vggpool的模型中包含了先验知识,因此效果比较好.但是,对于在ImageNet预训练模型和本文融合网络模型训练中都出现的相关概念,如“football_game”,“party”,“city_view”,本文融合网络的视觉特征是优于vggpool的.这是因为这3个概念本身就是具有视听信息的,这些概念相关的视频中通常都伴随着人们欢呼、说话等听觉信息,而本文的多模态概念中也包括了如“crowd_cheer”,“crowd_clap”这样的概念,联合网络通过对这些概念和相关视频的学习,使得网络具有了相应的特征.scr_v_pool来自于文中的未使用任何先验知识的融合网络3-scratch,其性能也表现出非常有竞争力的优势.这也证明了本文基于视听相关性的多模态网络的有效性.
4.6.2 基于联合网络听觉子网的特征
本文选择在ESC50验证听觉特征的有效性.ESC50是一个包含了2 000个音频的声音分类的标准数据集[18].这个数据集中的每个音频有5 s,被划分到50个类别(大致包括动物声音、自然声音、人类声音、室内声音和室外声音).数据集被预先划分成5个子集,每个子集的音频片段来源相同.评测指标是在5个子集上的平均准确率.本文实验中,先将5 s的每个音频划分成980 ms的音频片段,每个音频片段提取频谱图(预处理过程同4.3),将该频谱图输入到本文的视听融合网络的听觉子网中提取特征.所有音频片段的特征进行平均作为整个音频的特征,输入到SVM进行分类验证.
实验结果如表8所示.基于视听相关性的融合网络所提取的特征(scr_a_pool),在ESC50音频事件数据集的分类效果超过了vggish_fc约5.7%,而后者训练数据的数量远远大于本文实验中所使用的数据量.这也再次证实了本文方法的有效性.

Table 8 Classification Results on the ESC50 Dataset表8 ESC50音频分类结果 %
vggish_fc: The 128 dimensional features from the fully-connected layer of VGG trained on Youtube8M(audio only).
scr_a_pool: The 512 dimensional features from the output of pool5 of audio subset in joint-net3-scratch in table 5 with global max pooling.
5 总 结
本文探索了具有视听信息的多模态语义概念检测工作.多模态概念是指概念中包含了视听信息的概念,其中视听信息具有相关性,共同表达了语义概念所描述的事件.多模态概念的构建更能满足用户的精细化检索需求,也更能准确确定视频中的语义信息.本文以多模态概念为检测目标,探索了基于CNN的端到端的概念检测框架.除了使用CNN训练单模态的概念检测系统,本文利用多模态概念的视听相关性为目标训练了联合学习网络.实验表明:通过视听相关性的联合网络相比目前研究领域通用的视听觉特征,在多模态概念检测任务上有更好的表现.同时,联合网络能够学习到精细化的特征表示,利用该网络提取的视听觉特征也能够有效运用于其他多媒体分析任务.本文的研究工作将有效构建起视频底层特征与高层精细化语义之间的桥梁.
在今后的工作中,本文将继续探索更大规模的多模态概念的定义以及更准确的相关视频数据.本文提出的基于视听相关性的联合学习框架用于多模态概念检测,其中视觉信息和听觉信息在本文工作中只是采用简单的VGG模型作为网络学习的主要结构,在今后的工作中也将探索利用其他更为复杂的视觉、听觉网络学习模型.此外,本文的多模态联合学习,仅仅利用了视频的视听相关性,并未完全研究视觉信息和听觉信息之间究竟存在怎样的关系以及如何利用这个关系,这也是今后工作中一个值得深入的研究方向.
