荸荠优良品种‘桂蹄3号’球茎发育过程转录组测序分析
2019-05-14何芳练黄诚梅高美萍董伟清蒋慧萍黄诗宇
江 文,何芳练,黄诚梅,高美萍, 2*,董伟清,蒋慧萍,黄诗宇
(1. 广西壮族自治区农业科学院生物技术研究所,广西 南宁 530007;2. 福建农林大学园艺学院,福建 福州 350000)
【研究意义】荸荠(EleocharistuberoseSchulut)俗称马蹄,属单子叶莎草科多年生浅水草本植物,是我国14种重点发展的特色蔬菜之一。广西作为荸荠种植和加工主产区,种植面积(2×104hm2)和产量(7.5×105t以上)均占全国的一半以上,荸荠产业现已成为广西农业支柱产业之一。然而对荸荠分子遗传、转录组及基因组信息的研究十分缺乏,因此,开展荸荠球茎发育过程转录组研究,对荸荠产业的发展具有重要意义。【前人研究进展】荸荠前期的研究主要集中在种植栽培技术[1-3]、活性成分提取与利用[4-5]、组培苗及愈伤组织诱导试验[6-7]等。利用转录组研究植物相关基因功能和结构的方法已被广泛应用,分别针对植物不同组织部位、不同发育时期、不同品种等进行转录组测序,分析挖掘功能基因。张欢等[8]对杜梨根茎叶特异表达基因进行了RNA-Seq分析,探讨了梨属植物生长发育及组织间功能差异的分子机制;李和平等[9]对黄秋葵果实进行转录组测序,分析果实代谢途径信息,并发现830个SSR位点;对睡莲[10]、猕猴桃[11]及马铃薯[12]等植物的类似研究也均有报道,在植物抗病、抗逆的过程也有诸多应用[13-17]。【本研究切入点】针对荸荠转录组及基因组信息的研究十分缺乏。本研究利用RNA-Seq高通量测序技术,首次在荸荠优良品种‘桂蹄3号’球茎发育的不同时期进行转录组测序,分析球茎发育过程相关基因表达信息及品质相关代谢途径关键基因的表达情况,以期弥补荸荠品质形成相关分子机制的空白。【拟解决的关键问题】对发育期荸荠球茎进行转录组测序,采用生物信息学方法对得到的Uigene进行分类和功能注释,筛选荸荠球茎发育过程相关基因,为进一步开展荸荠品质形成分子机制等功能研究提供理论依据。
1 材料与方法
1.1 供试材料
试验材料为荸荠优良品种‘桂蹄3号’,从2017年10月20日开始,选择生长健壮无病虫害的球茎,每隔10 d取1次球茎,为球茎膨大初期(T01),球茎膨大中期(T02)和膨大后期(T03),清水冲洗干净,液氮速冻后放于-80 ℃超低温保存备用。
1.2 总RNA提取和检测
总RNA 的提取选用Trizol Reagent 方法,提取的RNA用无rnas DNaseI处理(TaKaRa生物科技有限公司)去除残留的DNA。采用Nanodrop检测RNA样品的纯度、Qubit 2.0和Aglient 2100检测浓RNA浓度和完整性,以备合格的样品进行转录组测序。
1.3 构建cDNA文库和illumina测序
样品检测合格后,构建cDNA文库,用带有Oligo(dT)的磁珠富集mRNA;加入Fragmentation Buffer使得mRNA随机被打断为短片段;以打断后的mRNA为模板,用六碱基随机引物合成cDNA第一链,然后加入缓冲液、RNase 、HdNTPs和DNA polymerase I,合成第二条cDNA链。纯化cDNA后,缓冲液洗脱,再经过末端修复、加碱基A,连接测序接头,再用AMPure XP beads选择片段,琼脂电泳回收目的片段,最后通过PCR扩增,完成cDNA文库制备,采用HiSeq 2500进行测序,测序读长为PE150[18]。
1.4 序列拼接和组装
通过去除重复测序,未知N含量和低质量读序,获得干净读序数据。转录组使用Trinity软件对干净序列进行从头组装获得转录本,使用Tgicl 软件进行聚类去冗余,获得非冗余的unigenes。
1.5 组装后的unigenes的功能注释
利用BLAST系列软件与网站公布的蛋白数据库进行比对分析,针对Nt(核酸数据库)、Nr(非冗余蛋白数据库)、Swiss-Prot(经注释的蛋白质序列数据库)和TrEMBL(核酸序列数据库)(E-value≤10-5)基于序列相似性检索蛋白质功能进行注释。利用KEGG(Kyoto Encyclopedia of Genes and Genomes)、GO、(Gene Ontology)COG(Clusters of Orthologous Groups)分别进行比对预测分析分子功能及相关的代谢通路[19]。
1.6 差异基因表达(DGEs)分析
FPKM方法消除了不同基因长度和序列水平对基因表达计算的影响,因此直接采用FPKM值比较不同样本间的基因表达差异,获得样品之间的差异表达基因集。采用校正后的P值,即FDR作为差异表达基因筛选的标准,将FDR≤0.01和差异表达倍数绝对值log2比率≥1作为2个样本之间基因表达的不同水平标准。
2 结果与分析
2.1 荸荠球茎转录组测序及组装
荸荠转录组测序获得39.96 Gb干净读序,Q30碱基百分比均不小于95.90 %;将Clean Data 进行组装,获得荸荠转录本223 182条,Unigene 90 542条,转录本和Unigene 的N 50分别为2032和1119(表1~2)。Unigene长度分布情况为:300~500 bp 序列占51.3 %,500~1000 bp序列占26.89 %,1000~2000 bp序列占13.99 %,大于2000 bp序列占7.82 %(表2)。荸荠测序数据与组装结果比对率达75 %以上(表3),组装完整性较高,效果较好,可用于进一步生物信息学分析。
2.2 基因注释和功能分类
通过BLAST搜索比对,共有50 583个Unigene成功注释(表4),由于缺少参考基因组信息,部分序列未能注释。与NCBI的Nr 数据库进行比对获得的基因注释信息较全面,占全部注释序列的92.10 %。与Swiss-prot 和Pfam数据库成功比对的序列分别有30 811和36 554条。

表1 ‘桂蹄3号’荸荠样品测序数据评估统计

表2 ‘桂蹄3号’荸荠组装结果统计

表3 ‘桂蹄3号’荸荠测序数据与组装结果的比对统计
2.3 荸荠球茎差异表达基因分析
2.3.1 荸荠球茎发育过程中差异表达基因比较 荸荠球茎发育过程中不同时期间基因表达差异见表5。结果显示,膨大初期T01与膨大中期T02相比,有4027条Unigene差异表达,其中2157个基因上调表达,1870个基因下调表达;膨大中期T02与膨大后期T03相比,共检测到3326个差异表达基因,其中1657个上调和1704个基因下调;T01与T03相比,检测到2931条差异表达基因,其中1675个基因上调,1256个基因下调。由上述结果可知,球茎膨大初期的差异表达基因所占比例高于其他比较,说明DEGs在早期发育阶段起着至关重要的作用。

表4 ‘桂蹄3号’荸荠Unigene注释统计

表5 ‘桂蹄3号’荸荠差异表达基因数目统计
2.3.2 荸荠球茎发育过程中差异表达基因GO功能富集 ‘桂蹄3号’荸荠球茎发育过程中的3个发育阶段T01、T02和T03经两两比对,获得的GO注释种类和数量大体相同。由图1可知,生物过程大多集中在代谢过程(metabolic process)、细胞活动过程(cellular process)和单生物代谢过程(single-organism process)。在细胞组分(cellular component)中,大多基因参与了细胞(cell)、细胞组成(cell part)和细胞器(organelle)的形成;在分子功能中,差异基因大多数富集到催化活性(catalytic activity)、结合(binding)和运转活性(transporter activity)。
2.4 荸荠球茎发育过程中差异表达基因COG功能分类
对荸荠球茎进行COG数据库比对分析结果(图2)表明,有17 743条Unigene比对成功,根据功能分类可分为25类。一般功能预测(General function prediction only),包含的Unigene最多,共4341个,占17.99 %;其次是转录、核糖体结构和生物合成功能(Translation, ribosomal structure and biogenesis),Unigene 2443个,占10.13 %;复制、重组和修复功能(Replication, recombination and repair)注释到Unigene 1881个,占7.8 %; 碳水化合物运输和代谢功能(Carbohydrate transport and metabolism)含Unigene1490,占6.18 %。最少的是核结构(Nuclear structure),注释到9个Unigene,占0.4 %。可见,在球茎发育过程中,除复制、翻译及转录等最基本的生命活动外,碳水化合物代谢占重要地位,表明碳水化合物代谢在荸荠球茎形成与发育中起到重要作用。
2.5 荸荠球茎发育过程中差异表达基因通路分析
对差异表达基因的代谢通路注释分析有利于进一步解读基因功能。结果表明,T01与T02 2个阶段的差异表达基因共参与116种代谢,T02与T03、T01与T03阶段分别涉及110和114种代谢途径。差异表达基因参与的主要代谢途径分类图如图3所示,其中淀粉-蔗糖代谢在3个文库比对中占主要作用,其它主要代谢途径是苯丙氨酸代谢(Phenypropanoid biosynthesis)、植物激素信号转导(Plant hormone signal transduction)、氨基酸合成(Biosynthesis of amino acids)。
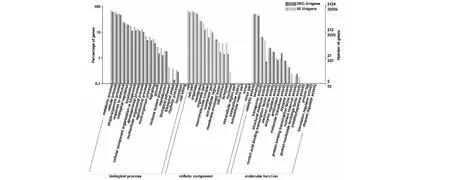
图1 ‘桂蹄3号’荸荠球茎发育过程中差异表达基因GO功能富集Fig.1 Gene Ontology functional enrichment of differentially expressed genes in expansion of corms in water chestnuts ‘Guiti 3’
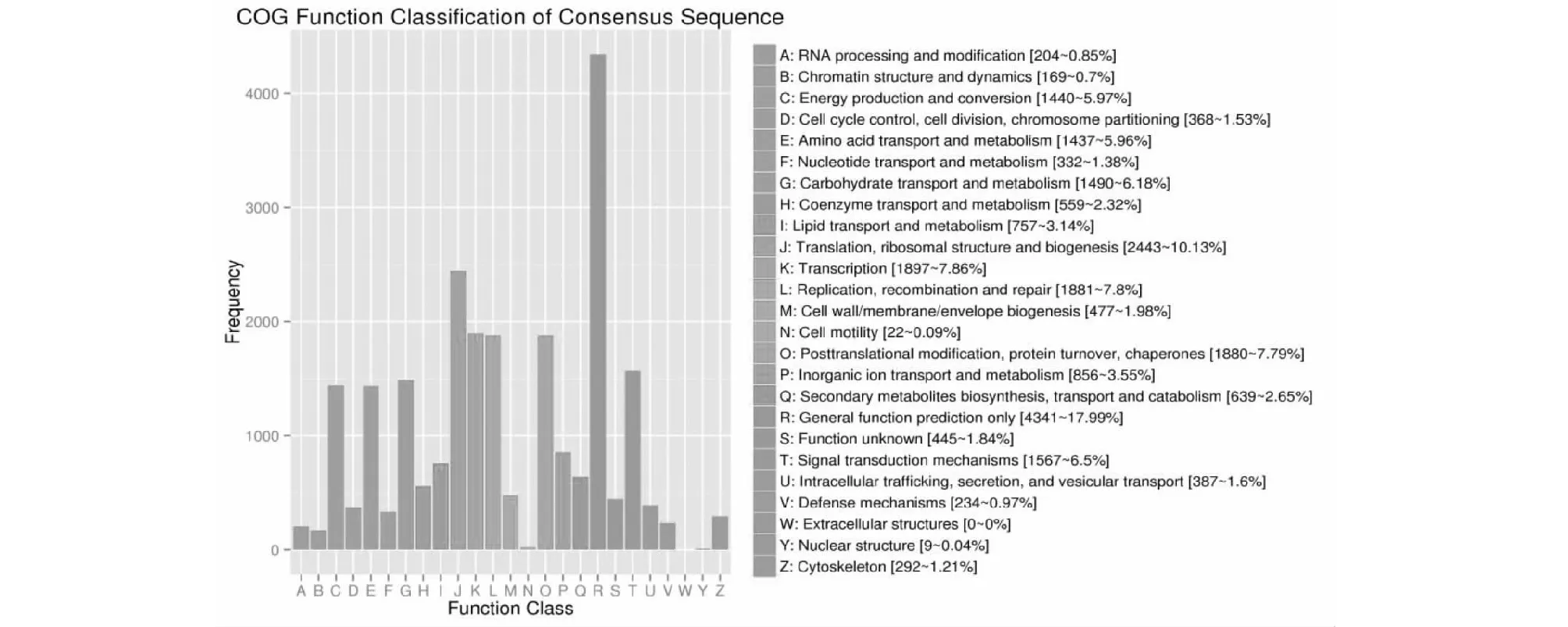
图2 ‘桂蹄3号’荸荠球茎发育过程中差异表达基因COG注释分类统计Fig.2 Clusters of Orthologous Groupsannotation classification of differentially expressed genes in expansion of corms in water chestnut ‘Guiti 3’
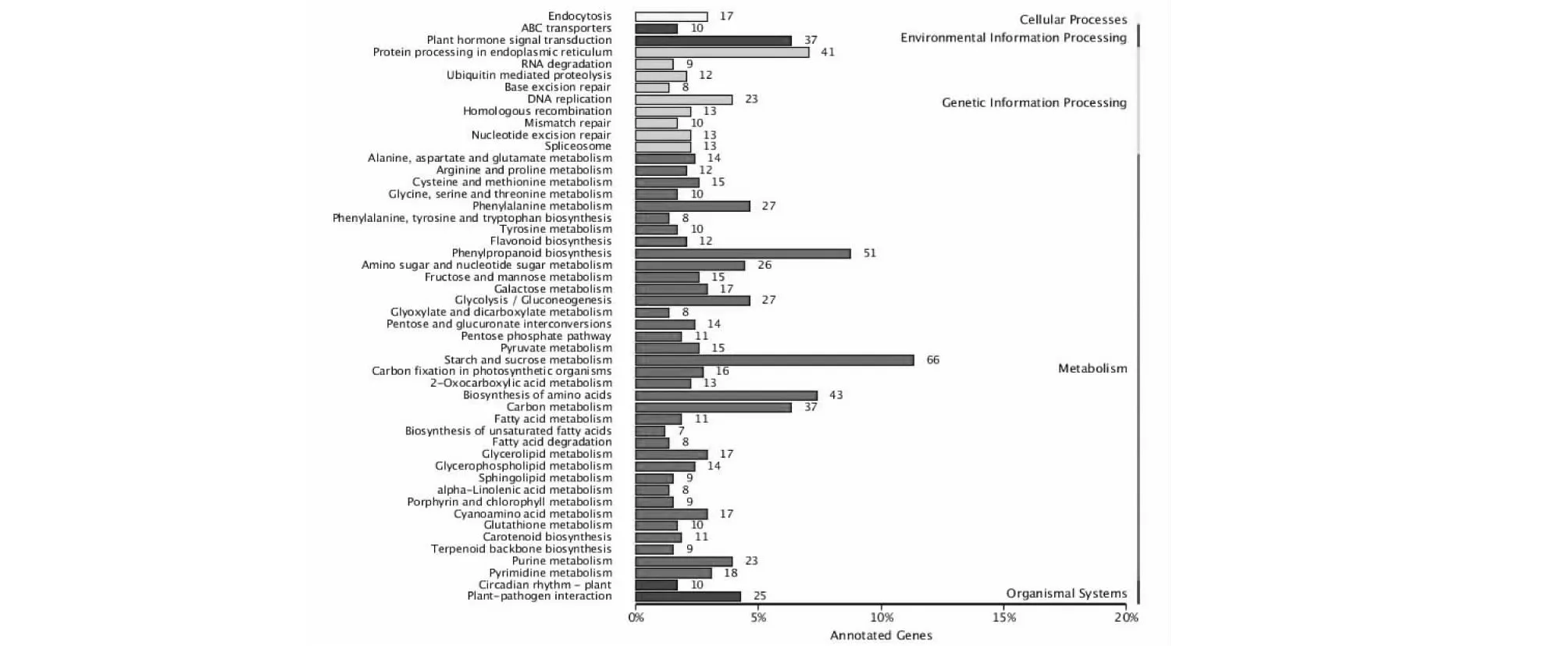
图3 ‘桂蹄3号’荸荠球茎发育过程中差异表达基因KEGG分类Fig.3 Kyoto Encyclopedia of Genes and Genomes classification of differentially expressed genes in expansion of corms in water chestnut ‘Guiti 3’
3 讨 论
RNA-Seq技术具有高通量、成本低、完成速度快等优点,目前该技术已广泛应用于特异基因的挖掘及其功能预测。国内外对荸荠研究主要集中在繁殖方式、栽培技术、病虫害防治等生理栽培等研究,对荸荠的分子生物学方面特别是功能基因方面研究较少。本研究利用转录组测序分析荸荠球茎发育,为荸荠新基因挖掘及代谢途径研究奠定了良好基础。
淀粉是荸荠球茎中碳水化合物的重要贮藏物质,荸荠的生长发育过程中淀粉不断累积。研究表明,淀粉的生物合成和降解与蔗糖有着密切关系。本研究中注释到的Unigene较多的是生物学过程中的代谢过程,大部分基因与荸荠的球茎发育代谢相关。KEGG功能注释获得20 667条Unigene,涉及116条代谢途径,注释到最多的代谢途径是淀粉-糖代谢,共注释到155条;其次是植物激素信号转到途径,有100条;苯丙氨酸代谢途径共注释到81条。可见,荸荠球茎发育过程中激素代谢通路也被激活。利用转录组测序技术研究淀粉-糖代谢在其他植物中也有相关报道。刘玉林等[19]应用Illumina Solexa Hiseq 2000高通量测序技术对辽东栎进行转录组测序,发掘出67条参与淀粉合成的Unigene 以及15 901个SSR 位点。Wang等[20]对马铃薯研究发现,AGPase基因很大程度上调节淀粉-糖代谢,该基因的沉默,引起淀粉产物的减少和可溶性糖的积累。程立宝等[21]利用转录组测序技术在莲藕根状茎膨大阶段进行淀粉积累研究,发现了10个贮藏蛋白合成相关基因和5个淀粉合成相关基因(Lrgbss、Lrsbe1、Lrsbe2、LrsbeⅡ和LrsbeⅢ),筛选出对莲藕根状茎的膨大起到重要作用的基因Lrplp8和Lrgbss。李雪艳等[22]采用二代高通量测序技术对百合小鳞茎形成与发育过程进行转录组测序,发现淀粉合成相关酶在小鳞茎中的表达丰度要高于母鳞片中的表达丰度,且以支链淀粉合成相关酶为主,而淀粉分解相关酶的基因表达量在母鳞片中较高;并在此基础上挖掘百合小鳞茎形成与发育过程中差异表达的淀粉-蔗糖关键酶SuSy和INV,探讨其在小鳞茎发育不同阶段的表达模式。
后期可对淀粉-糖生物合成相关基因进行深入研究,分析出其关键基因。深入挖掘影响荸荠淀粉-糖代谢途径的相关因素,可以为阐明荸荠淀粉生物合成机理提供理论依据,为荸荠的分子育种奠定基础。
4 结 论
本研究首次利用高通量转录组测序技术建立了荸荠优良品种‘桂蹄3号’球茎的转录组数据库,组装共得到223 182条Transcript和90 542条Unigene,平均长度为809 bp,N50为1119。共有50 583条Unigene在7个数据库成功注释。经KEGG代谢通路比对,有20 667个基因获得功能注释,共有116条代谢途径,其中注释到最多的代谢途径是淀粉-糖代谢,共注释到155条。
