基于AdaBoost算法的嘴唇检测与提取
2019-05-10李思潼冯彦婕杜帅朱从亮东北林业大学
李思潼 冯彦婕 杜帅 朱从亮 东北林业大学
引言
近几年,人机交互技术的应用越来越广泛,唇语识别作为人机交互中的关键技术,也越发受到关注。谷歌DeepMind实验室提出了一种新的唇语识别技术LipNet。目前唇语识别技术主要是针对语音识别在噪声较大环境下的识别率问题,作为对语音识别的补充和纠正。
关于唇语识别研究的热点主要在嘴唇特征提取以及唇动特征跟踪上,但如何从静态图片或动态视频流中检测出人脸和嘴唇区域并将嘴唇提取出来,对之后的嘴唇特征提取有着至关重要的影响。文献提出了使用RGB色彩空间对嘴唇区域进行提取,利用唇色与肤色在G、B分量上的差异对嘴唇进行提取。本文使用开源的计算机视觉库(OpenCv)中预先训练好的Harr Cascada分类器对人脸区域和嘴唇区域进行检测,之后对分割出来的嘴唇区域利用色彩空间进行嘴唇提取。
1 Haar-like特征
Paul Viola提出了一种快速的人脸检测算法,该算法是一种基于Haar-like特征和AdaBoost自适应增强算法的人脸检测算法,OpenCv中给出了该算法的实现。
Haar特征首先由Papageorgiou提出,用于对物体和人脸的快速检测,之后Rainer Lienhart在文献对其进行了补充,形成了Haar-like矩形特征库。本文所使用的OpenCv中的Harr Cascad分类器便是基于此特征库编写的。
由于使用Haar特征进行检测的特征数目过大,往往使用积分图的方式对矩形特征值进行计算。积分图的计算方法如下:在图像中取矩形D,其四个角的位置按顺时针方向分别标记为1、2、3、4,则其像素和可以根据如下公式计算:
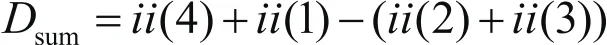
2 AdaBoost算法
AdaBoost算法是一个迭代过程,其思想是将分类效果较差的弱分类器组合起来,形成效果较好的强分类器。在过程中,AdaBoost算法不断提高被错误分类的样本的权值,使之在后面的训练中所占的比重更大,更新权值公式为
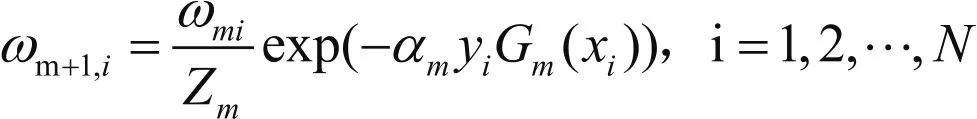
其中,Zm是规范化因子,am是基本分类器的系数
每一个Haar-like特征值便可视作一个弱分类器,通过AdaBoost算法后便可形成检测能力较强的强分类器,多个强分类器通过级联的方式组合起来,就形成了本文所使用的Harr Cascad分类器,如图1所示。
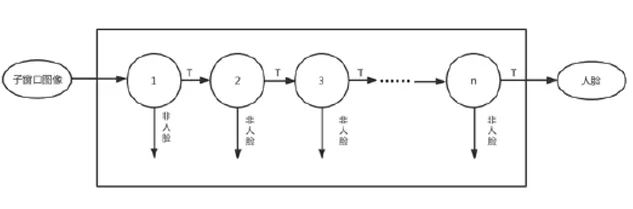
图1 级联分类器
3 嘴唇提取
根据Haar-like特征和AdaBoost算法可以对人脸和嘴唇区域进行检测,并将检测到的嘴唇区域分割出来,这样可以去除肤色和周围环境对嘴唇提取的干扰,从而可以使用基于色彩空间的方式将嘴唇提取出来。
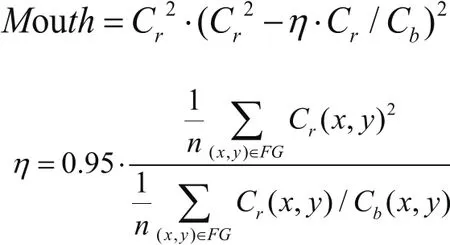
4 结果及分析
OpenCv中已经提供了训练好的Harr Cascad分类器,在haarcascades文件目录下。本文使用haarcascade_frontalface_default.xml和haarcascade_mcs_mouth.xml分别检测静态图片中的人脸和嘴唇区域,之后对检测出的嘴唇区域进行嘴唇提取。
对于输入的人脸图像,处理后的效果如图2所示。

图2 嘴唇提取的效果图
可知,该方法可以较为准确且完整地检测出人脸和嘴唇区域,并有效地提取出嘴唇。
5 结束语
本文提出了一种利用Haar-like特征和AdaBoost算法对人脸和嘴唇区域进行检测及分割,并使用 色彩空间对分割出的嘴唇区域进行嘴唇提取的方法。经证明,该方法具有快速、准确的特性,提取出的嘴唇轮廓较为完整。
