视觉场景理解综述
2019-05-05王忠民张福涛
王忠民, 王 星, 李 刚, 张福涛
(1.西安邮电大学 计算机学院, 陕西 西安 710121;2.西安邮电大学 陕西省网络数据智能处理重点实验室, 陕西 西安 710121)
视觉场景理解,称为图像语义描述,也可称为“看图说话”,是一个融合机器视觉技术和自然语言处理技术等多个领域的热点问题[1-3]。视觉场景理解不仅需要理解图像中各个实体对象信息,还需要理解实体对象之间的联系。其主要任务是通过卷积神经网络(convolutional neural networks,CNN)学习图像特征,利用循环神经网络(recurrent neural network,RNN)学习语言模型,再使用长短期记忆网络(long short term memory,LSTM)结合图像特征和语言模型逐词逐句生成图像相应描述。深入研究视觉场景理解,不仅可以加强学科融合、加深视觉场景理解模型研究,还可以优化研究方法、开拓新的研究内容。视觉场景理解模型实用化研究的不断推进,对盲人辅助体系、机器人交互和代码注释等研究也具有重要意义[4-5]。
视觉场景理解模型依据不同核心方法,可划分为基于搜索的视觉场景理解模型、基于模板匹配的视觉场景理解模型和基于语言模型的视觉场景理解模型。
基于搜索的视觉场景理解模型通过目标检测算法获取图像所包含的对象,然后将这些对象与图像库中的图像做相似匹配,把最相似的K张图片的描述作为该未知图像的描述[6-8]。文献[9]通过建立文本与图像之间的联系,预测图像区域与其对应的词汇,再使用统计量信息计算图像与文本的映射关系,最后利用相似度计算获得相似图片,以此获得图像的描述,该模型执行简单高效,能够生成最符合人类描述的语句。文献[10]提出先对场景、对象等关键实体进行图像分类以实现整体性识别,再整合全局信息与局部信息,最后通过整合后的信息提高模型准确率。文献[11]提出建立视觉场景理解系统,通过计算一组图像和描述之间的评分,从而获得场景描述。该方法不仅考虑图像之间的相似程度,也考虑未知图片与已有描述的相似程度,提高了匹配的准确性。
基于模板匹配的模型,是在基于搜索的视觉场景理解方法中增加了重用能力,扩大适用场景,将对象检测与模板匹配相互结合,在场景模板的相应位置填入合适的单词[12-14]。该方法不仅可以适应需求场景,也在使用卡槽法进行内容替换时提高描述准确性。文献[15]通过汇总大量图片与描述信息,提出一种基于坐标位置的视觉场景描述模型,通过获取标签与图片对象的坐标对应关系,使模型产生偏向于特定结构的句子,然后向对应位置填充相应词汇实现自动描述。文献[16]提出基于分步实现的场景描述,通过对大量图片数据的学习获得标签与图像之间的对应关系,根据目标检测结果与统计分析获得自然语言的模型,共同选择构造最自然的描述语句。该模型是基于搜索的视觉场景理解模型的改进,在固定应用场景中可以生成更确切的描述。
基于注意力模型的思想灵感来自于机器翻译,以深度学习相关理论模型加以辅助,可以进一步增加模型泛化能力、描述更丰富的场景[17-19]。文献[17]率先将机器翻译模型-编码-解码框架引入视觉场景理解任务中,通过卷积神经网络获取最后一层非全连接层的特征;通过循环神经网络将词汇编码为D维的词向量,句子就可以表示为V×D维的“图片”矩阵,其中V表示句子中词汇的个数,D为词向量的维度;最后使用LSTM解码器结合图像特征和语言模型逐词逐句生成最终描述结果。随后,文献[18]在编码-解码框架的基础上将注意力模型引入视觉场景描述任务,通过建立注意力矩阵实现不同时刻,预测不同词汇时可自动关注不同区域,以此提升模型的描述性能。
目前,基于编码-解码框架的模型和基于注意力模型的研究已广泛应用于视觉场景理解中,基本实现图像向文字的翻译过程。结合国内外研究现状,本文在对已有文献进行综述的基础上,讨论视觉场景理解的最新技术动态,分析视觉场景理解的发展趋势并指出未来研究方向。
1 基于搜索的视觉场景理解模型
1.1 模型描述
基于搜索的视觉场景理解模型通常分为对象检测和描述生成两个阶段,视觉场景识别模型如图1 所示。
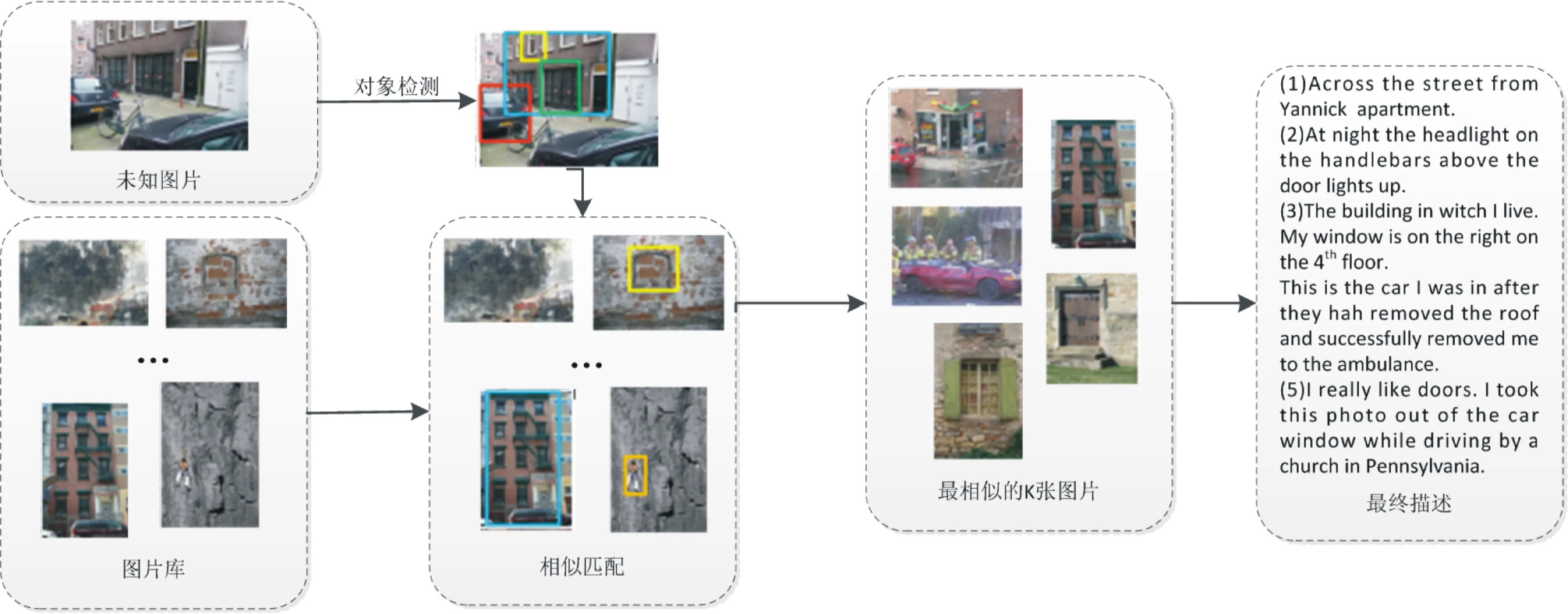
图1 基于搜索的视觉场景识别模型
阶段1主要任务为对象检测。对象检测是一种基于目标几何和统计特征的图像分割方法,将目标的分割和识别合二为一,可使整个系统更具准确性和实时性。目前实现对象检测的网络主要有Fast R-CNN(fast region-based convolutional network)[20]、Faster R-CNN(faster region-based convolutional network)[21]、YOLO(you only look once)[22]等分类效果较好地分类网络。对象检测主要检索的图像包含人、狗、鸟、飞机等前景对象信息;树、道路、河流、天空等背景对象信息;学校、商场、教堂等场景对象信息。具体过程分为3个部分。
(1) 目标定位
使用选择性搜索算法扫描输入图像,寻找可能存在的对象区域,生成大约2 000个可能存在对象的候选区域。
(2) 实例分割
计算2 000个候选区域与原始对象标定位置的重叠度,以重叠度确定是否检测到对象。该重叠度可通过设定交并比阈值(intersection-over-union,IoU)实现,保留存在对象的候选框Q。获取候选框Q的坐标及图中对象原有标记框B的坐标,计算重叠率
O=(Q∩B)/(Q∪B)。
通过对比交并比阈值与重叠率O的大小,可确定候选框Q中是否包含对象。
(3) 目标检测
目标检测和图像分类问题不同,每张图片待检测目标的数量不确定,导致目标检测的输出长度可变[23]。针对目标可变问题,传统方法通过设定划窗函数,给不同位置产生固定大小的特征窗,由窗口数量表示对象数量;而在深度学习中,通过搜索性算法粗略估计对象位置,由阈值确定对象具体位置,即获取对象集合E。
目标检测主要有两种实现方法:(1)利用哈尔特征(haar features,HF)生成多个简单的二元分类器实现。(2) 使用方向梯度直方图(histogram of oriented gradient,HOG)特征和支持向量机(support vector machine,SVM)分类实现[24-25]。例如:使用基于机器学习的方法R-CNN,把CNN特征提取器应用于图像的每个区域,再使用支持向量机分类获取最终分类结果;在Fast R-CNN分类网络中,对完整的图片进行CNN特征提取,利用兴趣区域(region of interest, RoI)进行集中特征映射,再根据前向传播网络进行分类和回归;Faster R-CNN分类网络是在Fast R-CNN基础上,添加候选区域网络,试图取消对搜索性算法的依赖,使得模型完全实现端对端的训练。
阶段2主要任务为图像匹配。图像匹配是通过建立影像内容、特征、结构、关系、纹理及灰度等的对应关系,根据相似性和一致性的分析,寻求相似影像目标的过程。结合阶段1获得的对象集合E,对图像库中的每张图像进行检测,获得对象集合F,计算E与F的交集G,获取G最高的前K张图像,并以该K张图像对应的描述为未知图像的描述。以Dis(*)函数代表相似度计算函数,针对不同类别对象的相似度计算具体如下。
(1) 前景对象匹配
若查询图像窗口检测到对象Wq,匹配图像窗口检测到对象Wm,则这两个对象的相似概率的计算表达式为
P(Wq,Wm)=e-Dis(Wq,Wm),
其中,P(*)为相似概率值,e(*)为指数函数,用于将相似距离Dis(*)归一化至[0,1]之间。
(2) 行为匹配
若查询图像窗口检测到行为Aq,匹配图像窗口检测到行为Am,则这两个行为的相似概率的计算表达式为
P(Aq,Am)=e-Dis(Aq,Am)。
(3) 场景匹配
若查询图像窗口检测到场景Sq,匹配图像窗口检测到场景Sm,则这两个场景的相似概率的计算表达式为
P(Sq,Sm)=e-Dis(Sq,Sm)。
完成图像匹配后,模型即可将K张图像的描述作为自身描述直接输出。另外,利用逆文本频率指数(term frequency-inverse document frequency,TF-IDF)[26],对查询图像的内容和匹配标题的内容进行相似匹配操作,可确保描述具有更高的准确性。该指数的计算方法如下。
(1)计算词频
词频(term frequency,TF)是指给定的文件中某个给定的词语在该文件中出现的频率。第i个文本文件中第j个词的重要性可表示为
(1)
其中,nij表示为第i个文件中第j个词出现的次数,分母表示所有文件中第j个词出现的次数总和,k为文件总数。
(2)计算逆向文件频率
逆向文件频率(iinverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可由总文件数目除以包含该词语的文件数目,再将得到的商取对数得到,逆向文件频率的计算表达式为
(2)
其中,D表示文件总数,Dj表示包含第j个词汇的文档个数。
由式(1)和式(2),可得逆文本频指数计算表达式为
Rij=tij×rj。
因此,通过目标检测可获知图像中包含的具体对象,利用图像匹配算法与逆文本频率算法确定前K张最为相似的图像,并以该K张图像的描述作为未知图像的最终描述。
1.2 研究现状
基于搜索的视觉场景理解模型,可细分为建立全局特征进行搜索的视觉场景理解模型和建立图像与句子间映射关系的视觉场景理解模型。文献[27]通过一个大型图像数据库实现了对100万张图片的Flickr查询,并对每张图片赋以自动描述结果;文献[28]提供了一个可以计算图像和句子之间的分数的系统,该分数可用于将描述性句子附加到给定图像,以此实现场景理解。具体相关研究如表1所示。
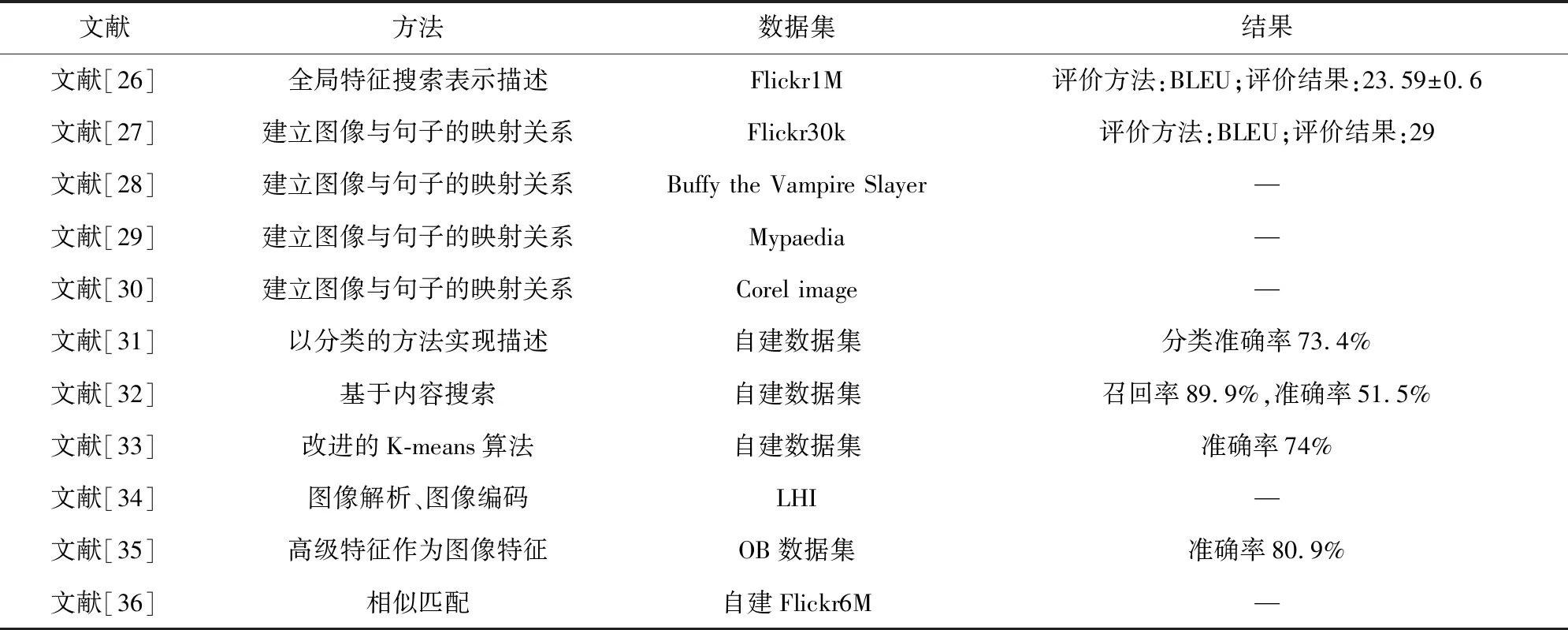
表1 基于搜索的视觉场景理解模型相关研究
2 基于模板匹配的视觉场景理解模型
2.1 模型描述
基于模板匹配的视觉场景理解模型也可分为对象检测和描述生成两个阶段。基于模板匹配的视觉场景理解模型如图2所示。
阶段1主要任务为对象检测。通过目标检测和属性检测算法确定图像中包含的人、狗、鸟、汽车等实体对象,以及对象之间的位置等属性关系。
(1)目标检测
目标检测方法与基于搜索的视觉场景理解方法相同,可使用哈尔特征、HOG、支持向量机等检测算法,也可使用R-CNN,Fast R-CNN,Faster R-CNN深度学习模型实现。
(2)属性检测
属性检测是对捕获对象进行外观分析,将提前训练好的属性分类器作用于给定图片并获取该图片所包含对象的各种属性特征。属性分类器可以通过DeepMind和Deep-ID等深度模型实现。
阶段2主要任务为生成描述。结合目标对象、属性描述和位置信息,通过序列判别方法建立实体之间的序列联系,根据预测内容和自然语言对文本进行统计,匹配最为相似的语句作为图像描述。常用自然语言处理方法为条件随机场(conditional random field,CRF)[37]和隐马尔可夫模型(hidden markov model,HMM)[38]等。以条件随机场为例,词汇预测模型具体实现如下。
条件随机场是一种判别式概率模型,常用于标注或分析序列资料,如自然语言文字或是生物序列,转化示例如图3所示。图3中圆圈代表一个实体对象,三角形代表对象属性,菱形代表关系,五边形表示根据语义补充的内容,六边形表示临时节点。利用对象检测器和属性分类器共同确定两个对象之间的关系,表示形式为(对象1∶关系词∶对象2)的三元组。由于条件随机场在推断时只能处理一元或者二元对象,加入一个中间节点可将其转化为一个一元对象和两个二元对象的组合。即在图3(a)中增加中间节点转化为图3(b),转化后的图谱可将原始三元组拆分为(属性1,对象1),(关系词),(属性2,对象2)三个元组,随后条件随机场再通过以上三个元组获得一组对象间的预测序列。
根据上述模型计算方法,可获得图2中包含<
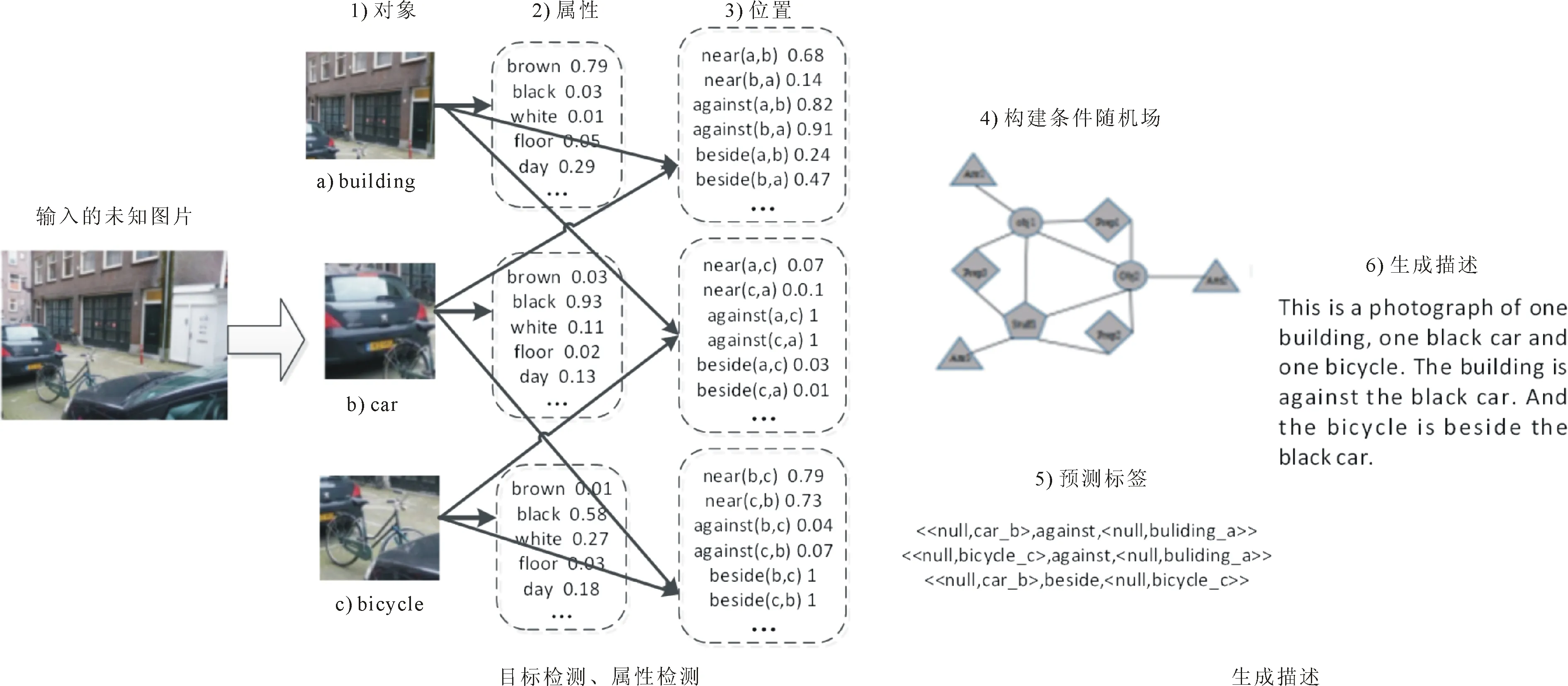
图2 基于模板匹配的视觉场景识别模型
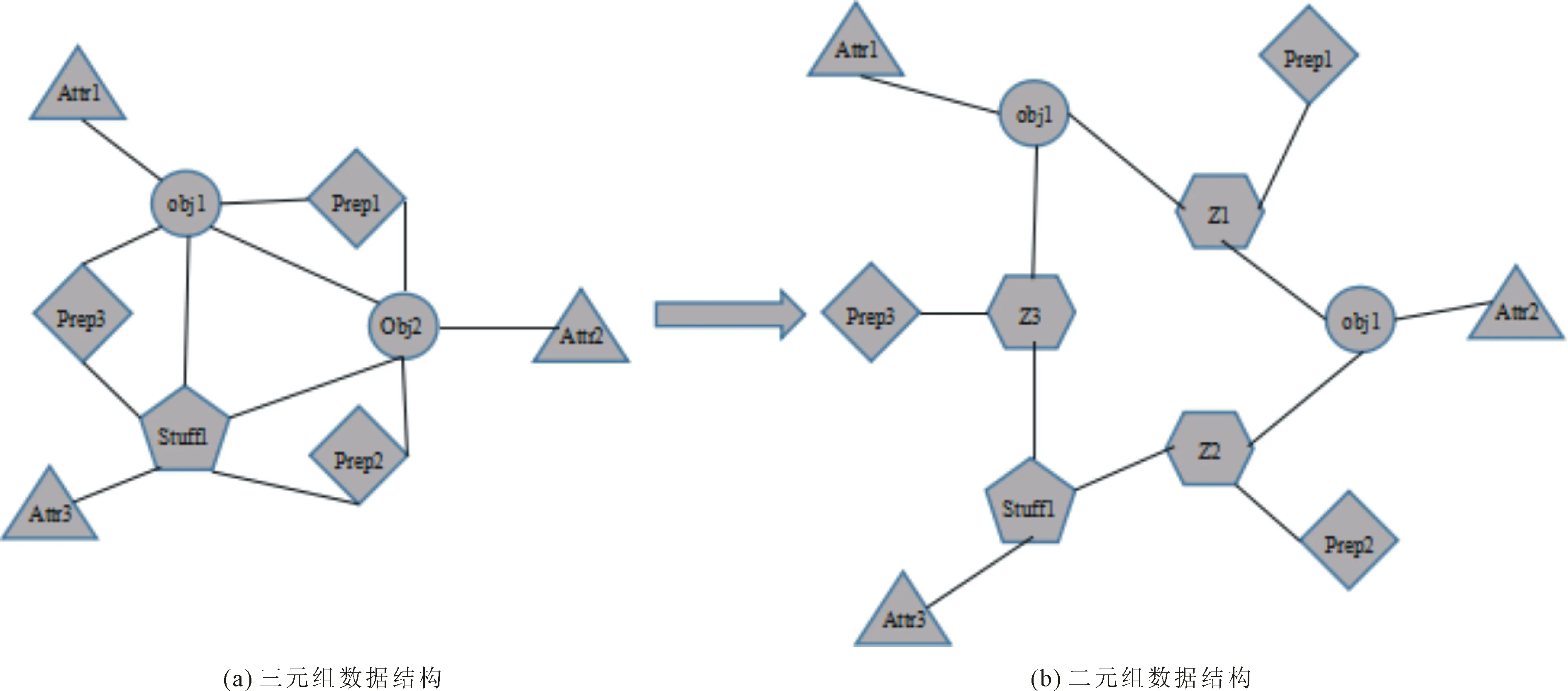
图3 三元组数据向二元组CRF转化
2.2 研究现状
基于模板匹配的视觉场景理解模型增加了具有灵活性的模板,提高了实际生产生活中的应用能力。应用场景包括:(1)工厂场景。记录印刷电路板的模板为“__号电路板__位置出现__问题”。(2)医院场景。不同病情的化验结果或X光结果描述结构相同,模板为“__患者__检查存在__问题”。(3)家庭陪护场景。保留陪护机器人的关键视频,并建立视频摘要,模板为“__时__分,__人干了__事,结果__”。具体相关研究如表2所示。

表2 基于模板匹配的视觉场景理解模型相关研究
3 基于注意力模型的视觉场景理解模型
与基于搜索的模型和基于模板匹配的模型不同,基于注意力模型的研究旨在学习视觉内容和文本句子在公共空间中的概率分布,即映射关系,以生成具有更灵活语法结构的新句子。目前,利用神经网络分析概率分布,已在图像描述任务中取得了重大突破。文献[45]提出建立多模态对数-双线性神经语言模型实现图像生成句子。文献[46]提出了一种端到端的神经网络体系结构,利用LSTM网络为图像生成句子,并在编码-解码框架的基础上结合注意力模型,提高了模型描述准确率。
3.1 模型描述
基于注意力模型的视觉场景理解模型是对基于编码-解码框架模型的视觉场景理解模型的补充与扩展。主要通过编码-解码框架与注意力模型两种技术,得到图像的最终描述。
3.1.1 编码-解码框架
编码-解码框架已广泛应用于自然语言处理中,主要完成端对端的学习任务,包括机器翻译、文本摘要提取和系统问答等[47-49]。在机器翻译中,输入序列是待翻译的文本,输出序列是翻译后的文本;在系统问答中,输入序列是提出的问题,输出序列是答案;在视觉场景理解中,输入序列是图像的特征图谱,输出序列是描述后的文本。而图像和其描述词汇之间具有对应关系,也可理解为构成了端对端的任务系统,因此,可在图像/视频描述生成任务中使用编码-解码框架。编码-解码框架的实现过程为将编码器作用于输入序列x,生成上下文向量c,再将上下文向量c传入解码器生成输出序列y,结构如图4所示。
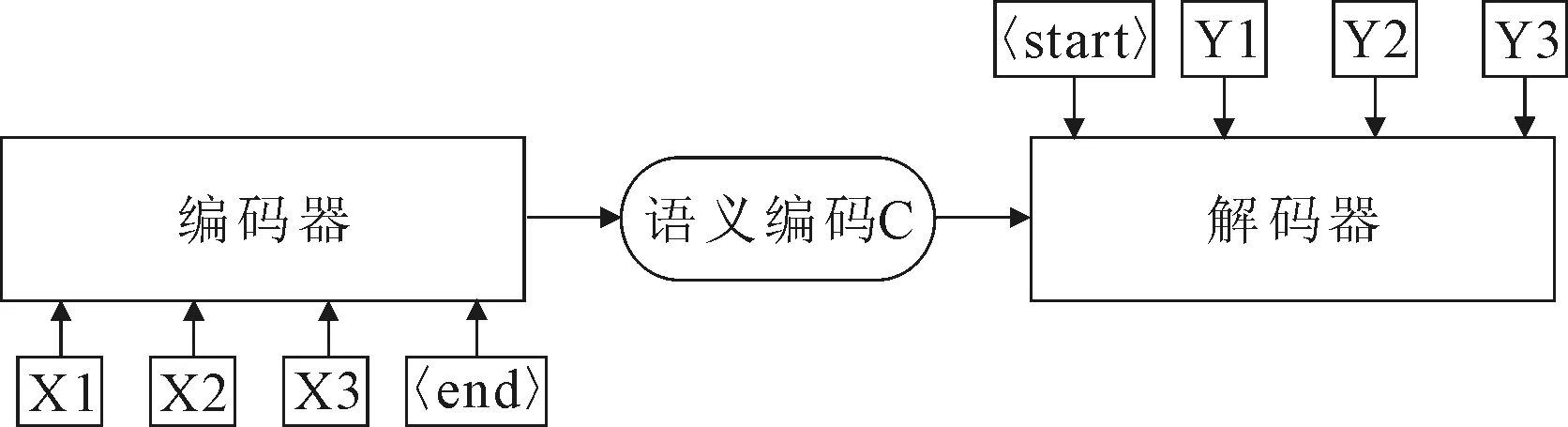
图4 编码-解码框架
编码-解码框架在编码阶段主要实现对图像的编码、建立语言模型和建立图像与文本映射关系;解码阶段是将语言模型、图像特征等数据送入解码网络生成自然语言描述。因此,基于注意力模型的视觉场景理解任务包含视觉理解和图像解码两个模块。
(1)视觉理解模块
视觉理解模块用于提取特征,获取图像中的对象信息、属性信息、位置信息等,并将这些信息编码为可以供解码器理解的中间向量。对于这一任务,大多数模型可通过卷积神经网络实现。卷积神经网络提取的特征向量又可称为注视向量,每个注视向量对应于图像的一个区域。注视向量可表示为
T=(a1,a2,…,am),ai∈D,
其中,ai表示图像的一个区域特征,m表示提取的特征总数,D表示每个特征的维度。
将图像I与注视向量T按位相乘,得到“注视”图谱
I′=I⊗T。
将每次注视完成后的“注视”图谱送入图像解码模块用于生成当前阶段词汇。
(2)图像解码模块
图像解码器的主要结构为LSTM网络,其输入包括t时刻的上下文向量ct,t-1时刻的隐藏状态ht-1,t时刻前生成的描述yt-1,则生成下一次词汇的表达式为
yt=Φ(ct,ht-1,yt-1)。
LSTM网络是解码模块的核心,而LSTM网络的核心组件为知识记忆单元(细胞),其围绕知识记忆单元建立遗忘门、输入门和输出门等一系列的门结构,这些门可用于知识筛选与知识更新[50-51],具体实现步骤如下。
步骤1通过遗忘门筛选信息。将新知识与旧知识进行对比,如果是对旧知识的改进,则遗忘旧知识。t时刻的遗忘门f的筛选结果的计算表达式为
ft=δ[Wf(ht-1,xt)+bf],
其中,δ表示sigmoid激活函数,Wf为遗忘门的权重矩阵,xt为t时刻的输入,bf为遗忘门的偏置量。
步骤2通过输入门筛选更新信息。利用目前学习到的知识,对当前学习到的知识进行过滤,使用新知识更新旧知识。t时刻输入门p和知识记忆单元N的筛选结果的计算表达式分别为
pt=δ[Wp(ht-1,xt)+bp],
Nt=φ[WN(ht-1,xt)+bN]。
其中,δ、φ分别为softmax和tanh激活函数,Wp、WN分别为输入门和知识记忆单元的权重矩阵,bp、bN分别为输入门和知识记忆单元的偏置量。
步骤3更新知识记忆单元。将旧知识与新知识进行整合,获得本轮要存入知识记忆单元的知识
步骤4通过输出门筛选数据并输出最终结果。t时刻输出门的输出结果和隐藏状态更新结果的计算表达式分别为

其中,Wo为输出门的权重矩阵,bo为输出门的偏置量。
经过上述步骤的多步迭代,将逐次逐句生成图像的完整描述。因此,基于编码-解码框架的视觉场景模型,首先通过CNN对训练数据进行训练,将获得模型中间一层或多层的特征图谱作为解码器解码时的输入特征。然后在图像解码模块中,将当前输入特征、知识记忆单元、以及上一时刻的隐藏状态向量一并送入LSTM,循环生成下一描述词汇,最终获得目标描述。该模型结构如图5所示。

图5 基于编码-解码框架的视觉场景理解模型
3.1.2 注意力模型
注意力模型主要应用在图像解码阶段,其表现为同一组特征图谱,在不同时刻对不同区域具有不同的注意力,通过关注系数取值高低来决定注意力,取值越高注意力越大,取值越低注意力越小。
在描述生成过程中,结合t-1时刻的知识记忆单元Nt-1、t时刻的输入xt、t-1时刻的隐藏状态ht-1,生成t时刻的描述yt,并通过隐藏状态对输入数据的影响实现关注位置的迁移。基于注意力模型的视觉场景理解模型如图6所示。其中,编码阶段获得图片的结构化集合V可描述为
V={v1,v2,…,vM},
其中,vi表示图像中第i块对应集合的元素,代表输入信息中某个时间片或者空间位置上的输入信息,M表示集合V分块数。每个集合对于上下文向量在t时刻所表达的注意力得分表达式为
对得分结果进行归一化处理,获得第i个位置t时刻的归一化权重
则归一化后t时刻的注意力权重矩阵
将V与βt进行按位相乘运算,可获取t时刻的上下文向量,则更新上下文向量的计算表达式为
ct=V⊗βt。
将更新的上下文向量ct、t-1时刻的隐藏状态ht-1、t-1时刻的描述送入解码器网络生成t时刻的描述
yt=Φ(ct,ht-1,yt-1),
经过多步迭代,将逐次逐句生成图像的完整描述。

图6 基于注意力模型的视觉场景理解模型
3.2 研究现状
基于注意力模型的视觉场景理解模型可分为软注意力模型与硬注意力模型两个内容。文献[52]通过注意力的自然基础理论提出了一个组合自下而上和自上而下的注意机制,使注意力能够在对象之外的多个方面发挥作用。文献[53]提出了一种新的编码器-解码器框架的扩展——审查网络,该网络是通用的,可以增强任何现有的编码器-解码器模型。该网络对编码器隐藏状态执行多个审查步骤,每个审查步骤后输出一个思想向量,思想向量作为解码器中注意力模型的输入,以此保证整体描述的连贯性。具体相关研究如表3所示。
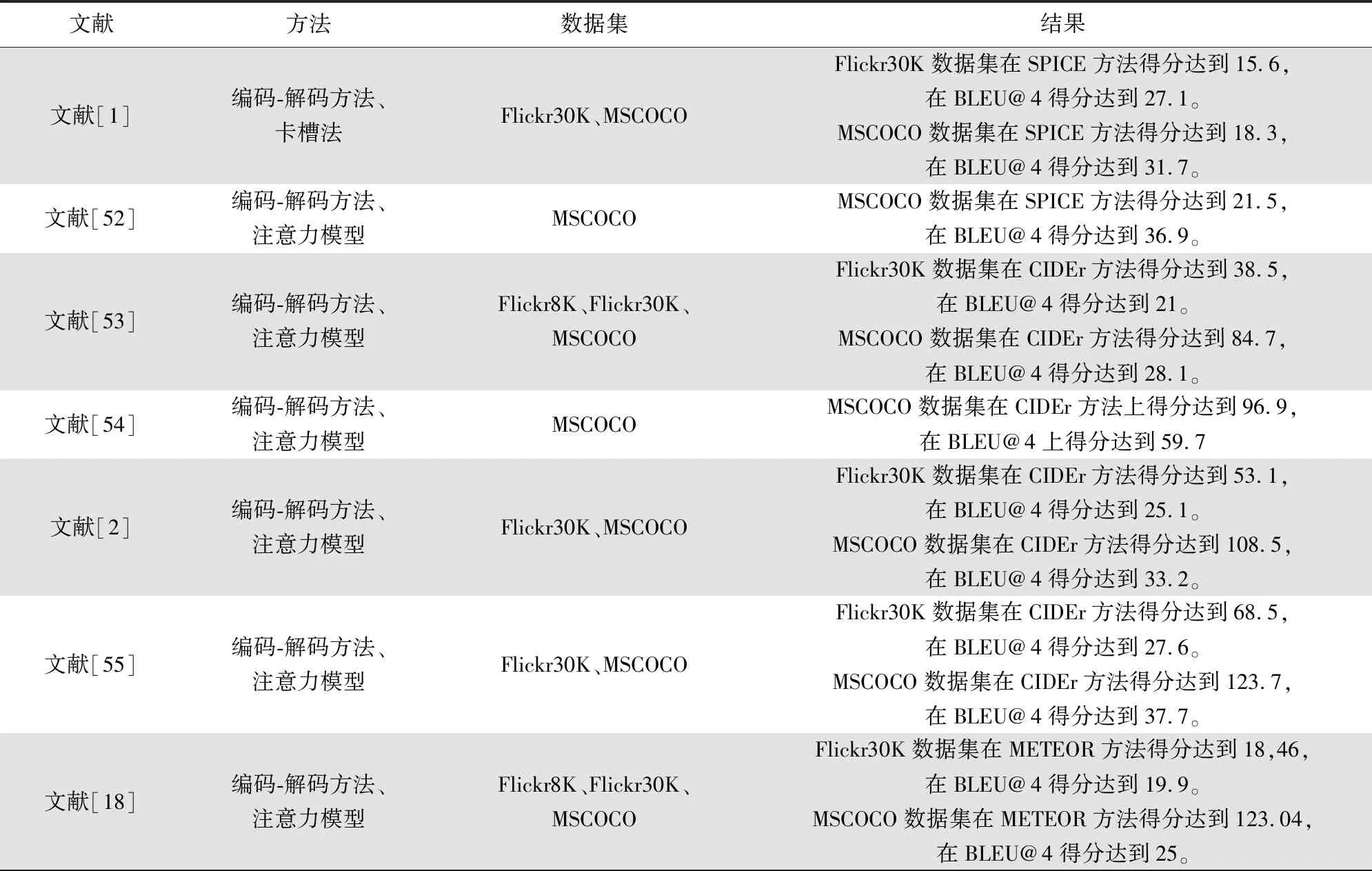
表3 基于注意力模型的视觉场景理解模型相关研究
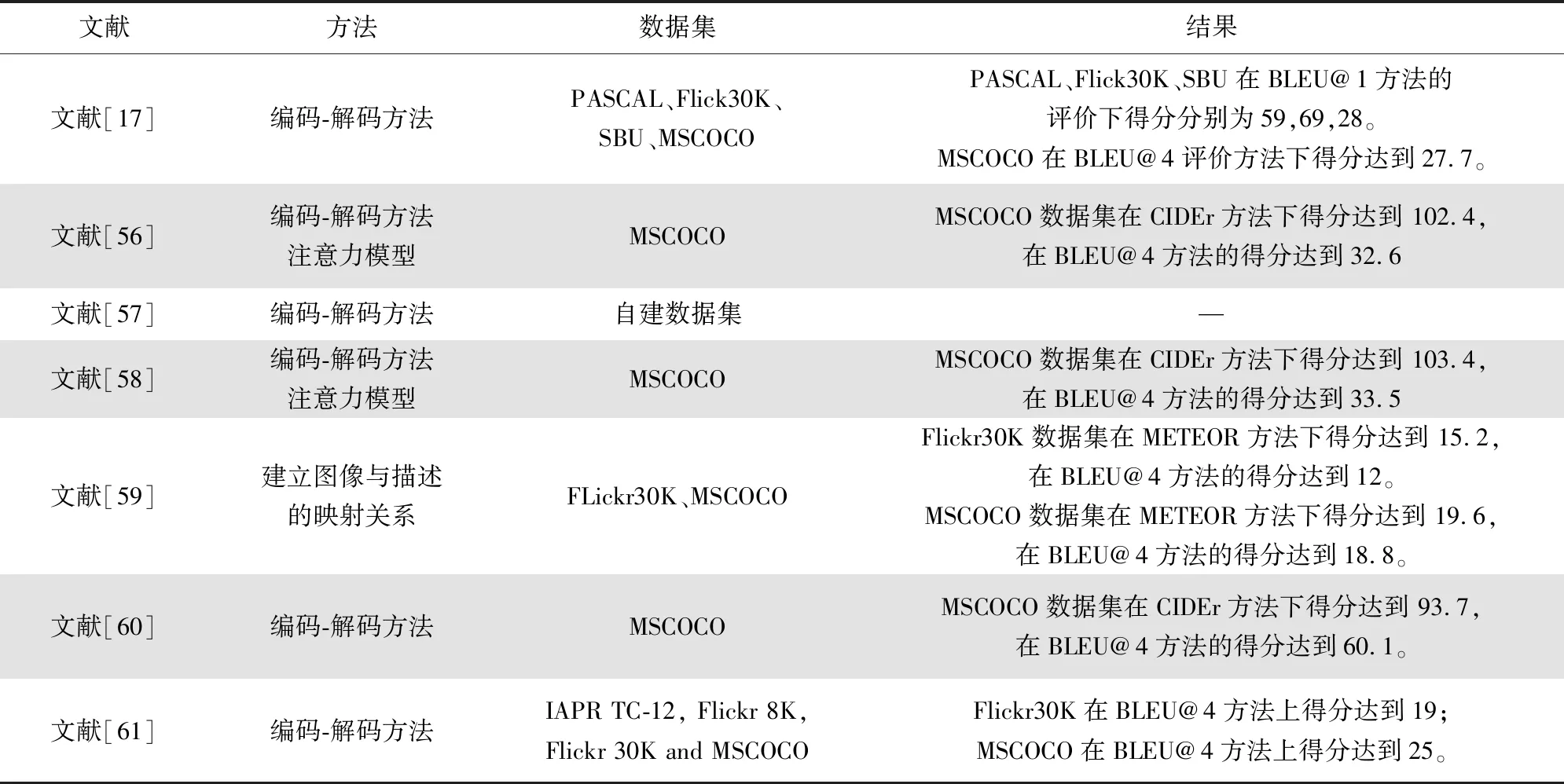
(续表3)
4 评价标准与数据集
视觉场景理解任务基于机器视觉、自然语言处理等多个领域。因此,针对机器翻译性能的评价准则也同样适用于视觉场景理解任务。
4.1 评价准则
视觉场景理解任务的灵感来源于机器翻译,对其评价标准可以参考机器翻译的评价方法,将生成语句与人工描述相匹配,获取一个相似度得分,以此来衡量描述的准确性。常用的评价准则有:基于双语互译质量评估准则(bilingual evaluation understud,BLEU)[62]、基于加权平均数与单字召回率的评估准则Meteor[63]、基于共识的图像描述评价准则(consensus-based image description evaluation,CIDEr)[64]、基于召回率的相似性度量准则(recall-oriented understudy for gisting evaluating,ROUGE)[65]等。各评价准则详细描述如下。
(1)BLEU
BLEU为双语互译质量评估准则,是评估机器翻译质量的工具。通过两个句子的共现词频率计算,判断两个句子的相似程度,与多个给定描述进行对比,从而获得平均得分。分数越高说明翻译效果越好。BLEU准则表达式
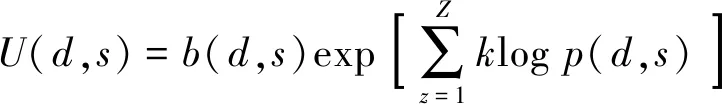
其中,d表示候选描述,s表示参考描述,b为惩罚函数,k表示选取某一个描述的概率,通常为1/n,p表示精度度量函数。Z表示相似判断时每次使用的连续词汇长度,z表示从句子中选取词汇的起始位置,z∈[1,Z-3]。
(2) Meteor
Meteor是基于单精度的加权调和平均数与单字召回率的评价准则,其目的是解决BLEU标准中固有的缺陷,Meteor准则表达式为
J=F(1-ν),
其中,F为召回率的加权调和平均数,ν为惩罚系数。
(3) CIDEr
CIDEr将每个句子看作“文档”,表示成TF-IDF向量的形式,再计算参考描述与模型生成描述的余弦相似度以此作为评分结果。其评分表达式为
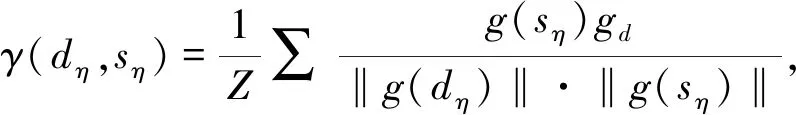
其中,‖*‖为计算范数的操作,dη为候选描述,sη为参考描述,η表示测试数据集中图片的编号,g为将描述转化为TF-IDF向量的函数。
(4)ROUGE
ROUGE是一种基于召回率的相似性度量方法,和BLEU类似,缺少召回率的加权调和平均数的评价功能,主要考察翻译的充分性和忠实性,无法评价参考译文的流畅度,其计算的是N元组在参考描述和待评测描述的贡献概率。
4.2 数据集
(1)Flickr30k数据集
Flickr30K数据集[66]包含31,783张图片,每张图片带有5个人类语言描述的标签,共158 915条描述。
(2)MS COCO
MS COCO(common objects in context)[68]是用于图像识别、图像分割和视觉场景理解的数据集。该数据集共包含30万张图片,每张图片包含多于3个对象,并且为每张图片配有5个描述。
(3)PASCAL VOC
PASCAL VOC数据集[69]不仅提供大量图片-句子数据,也提供了标准图像检测算法和图像描述性能的评估系统。数据集共包含20个类别,分别为人类;鸟、猫、牛、狗、马、羊等动物;飞机、自行车、船、公共汽车、小轿车、摩托车、火车等交通工具;瓶子、椅子、餐桌、盆栽植物、沙发、电视等室内物品。
4.3 模型对比
分别从模型优劣势和典型方法性能两方面对比基于搜索的视觉场景理解模型、基于模板匹配的视觉场景理解模型和基于注意力模型的视觉场景理解模型。
(1)模型优劣势对比
表4从主要技术、特点分析两方面对3类模型进行分析,列举了每类模型的主要技术和优劣势,具体如表所示。

表4 3种视觉场景理解模型优缺点对比
(2)典型方法性能对比
分别对比基于搜索的视觉场景理解模型的Im2Text[6];基于模板匹配的视觉场景理解模型的BabyText[8];基于语言模型的视觉场景理解模型的Google NIC[17]和SAT[18]等4种典型方法的性能及人类自然描述Human,其中Google NIC模型没有使用注意力模型。实验中使用PASCAL VOC数据集[69]与SBU数据集[6]作为实验数据集,使用BLEU@4[62]准则作为评价准则,即判断连续4个词汇是否相似。具体对比结果如表5所示。
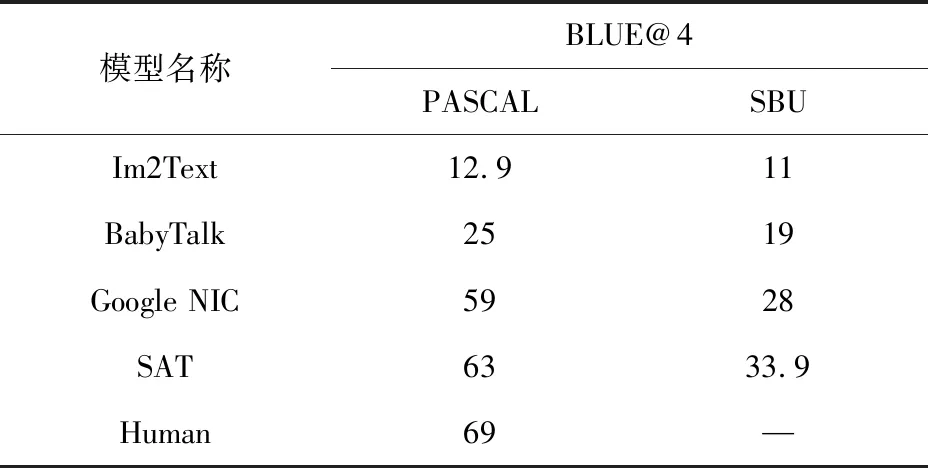
表5 视觉场景理解的典型模型性能对比
5 视觉场景理解的发展趋势
5.1 发展趋势
视觉场景理解已开始尝试应用在盲人辅助系统的视觉信息分析、机器人视觉系统的场景理解、无人驾驶系统中路况场景分析等现实需求各个方面。学者们一方面需要研究新的研究方式方法以满足各种新应用的挑战,还要改进原有理论体系应对不断变化的应用场景。视觉场景理解的发展也促进了智能硬件和智慧城市等研究的发展。因此,视觉场景理解的发展需要向标准化和面向社会应用的实用化趋势发展。
(1)标准化趋势
标准化是科学研究发展到一定阶段的产物,建立标准化的研究体系有利于把握研究方向,并能在此基础上不断衍生新的课题。视觉场景理解模型研究是计算机视觉和自然语言处理相互结合的产物,对其建立标准化体系将为计算机视觉与自然语言处理提供更多的原动力。
(2)面向社会应用的实用化趋势
深度学习网络与嵌入式技术的大力发展给视觉场景理解模型的实际应用带来了新的机遇与挑战。目前的研究已经开始在盲人辅助体系、机器人辅助视觉和无人驾驶辅助体系等现实需求中做出大量尝试,但网络模型大、嵌入式设备计算不足等问题使其与工业级应用仍然具有较大差距。但是,随着智能硬件、工业4.0等思想的提出,深度网络压缩、图形处理器(graphics processing unit,GPU)等技术的不断突破;深圳市大疆创新科技有限公司和杭州海康威视数字技术股份有限公司等企业的不断尝试使视觉场景理解模型走向实用成为现实。
5.2 研究方向
不断涌现的现实需求与不断革新的信息技术不仅为视觉场景理解模型走向实用提供了技术理论支撑,还为视觉场景理解带来了新的机遇与挑战,使其在未来的研究中不仅需要在理论研究方面进行大量创新,还需要针对智能硬件、智能制造、智慧城市等实际应用中需求进行大量探索,尽快实现工业级应用。因此,视觉场景理解模型的下一发展阶段应更加联系实际,结合智能制造、智慧城市建设的浪潮,不断优化模型、优化算法体系、贴近现实,实现在提高模型能力的基础上也提高模型实用性。在对已有文献进行综述的基础上,总结了视觉场景理解的最新技术动态,通过分析视觉场景理解的发展趋势,给出了基于多种注意力模型融合的视觉场景理解、基于辅助网络的视觉场景理解和基于树形结构的视觉场景理解等模型进行探索,不断增强模型能力。
(1) 基于多种注意力模型融合的视觉场景理解模型
注意力模型虽然能在描述生成过程中有选择的关注图像区域,但是,目前方法采用的特征均来自于分类器网络的最后一个卷积层,这层虽然具有最高级的语义特征,但受神经元的影响,使得对象之间的区分度变小,并抑制了注意力模型的能力。因此,在后续研究中,可以探究低级特征或多层次特征对描述性能的影响,并借用目标跟踪中使用多层特征线性组合的思想,构建新的特征图谱,建立基于多层空间的注意力模型,提高特征定位能力;与此同时,在每一层内部使用通道关注模型定位最能表述内容的区域,从而提高描述的准确性。
(2) 基于辅助网络的视觉场景理解模型
视觉场景理解的数据集为MSCOCO、Flickr30K、Flickr8K等,每个数据集的场景有限,而且识别粒度不同,在模型调整过程中参考的内容是当前数据,因此,在每个数据集上训练的模型都难以适应其他数据集的描述,从而降低了原始模型的表达范围,使得最终所能识别的对象只能来自于训练集。因此,在解码阶段尝试补充实体内容,丰富描述的多样性。
(3) 基于树形结构的视觉场景理解模型
机器翻译中序列到序列的生成机制,要求对前后语义理解正确,一旦前一词汇表述错误将直接导致整个描述失败。因此,若将视觉场景理解回归目标检测与卡槽填充,不仅有助于生成鲁棒性更高地新颖描述,还可以有效降低错误描述的概率。通过目标检测获得图像中的实体对象,并将这些实体对象以二叉树的非叶子节点组织起来构成描述的基本框架;然后通过属性检测器获得每个实体对象更加细致的表达,以此丰富表述结果。
6 结语
基于注意力模型的视觉场景理解模型具有更好的场景适应性,泛化能力高,容错能力强。视觉场景理解模型将以建立标准化和面向社会应用的实用化为未来研究趋势,基于多种注意力模型融合的视觉场景理解模型、基于辅助网络的视觉场景理解模型和基于树形结构的视觉场景理解模型等多个模型可作为未来深入探索的研究内容。
