基于B-Spline曲线的流式数据事件模板构建方法
2019-05-05王俊陆杨兴东宋宝燕
王俊陆,杨兴东,罗 浩,宋宝燕
(辽宁大学 信息科学与技术学院,沈阳 110036)
1 引 言
近年来,随着各行业产生数据规模的不断增大,流式数据系统应用也越来越广泛,如矿山灾害监控,云媒体流以及传感网络等[1].在这些应用中,如何对海量流式数据中的异常事件进行高效监测判识,成为领域的研究热点.例如,在煤矿灾害监测系统中[2,3],矿山周围的每个采集器每秒均可产生近万条流式微震感知数据,当发生煤矿冲击地压灾害时,需要对各个采集器同时进行灾害事件的识别,进而判断灾害发生的信息.由于矿区周围的地形、地质等自然条件复杂,且常伴有强噪声、电磁等人为干扰,导致每次发生灾害事件时,微震感知流式数据的值域及幅度域都存在较大差异,无法通过传统的数据流阈值比对方式进行判识,因此,如何通过已有灾害数据进行值域及幅度域的规格化处理,进而构建灾害事件模板支持实时判识,成为流式数据事件判识的研究热点及难点.
本文针对流式大数据事件的特征及判识难点,提出一种基于B-Spline曲线[5-7]的流式数据事件模板构建方法.主要贡献如下:
1)提出基于线性变换的流式大数据事件归一化处理方法,将多组不同大小的流式数据事件变换到相同的尺度下.
2)在此基础上,引入遗传算法[8],提出新的B-Spline控制节点求解方法,通过基因编码,选择,交叉操作,确定B-Spline的控制顶点和相应的节点矢量.
3)根据上述两种方法,分析流式大数据的特点,提出基于B-Spline曲线流式大数据事件模板构建方法.
2 相关工作
目前,国内外采用B-Spline对流式大数据事件模型构建方法,通常需要确定相应B-Spline的节点矢量,进而求出相应的控制点.通过给定的初始节点矢量,利用迭代手段得到满足要求的节点矢量.文献[2]提出一种基于遗传算法的B-Spline拟合方法,很好的解决了节点矢量选取随机性问题.但该方法没有考虑海量数据的问题,数据规模过大时,反求控制节点运算时间开销过大.文献[4]提出一种基于轮廓关键点的B-Spline拟合算法,在确保扫描线点列形状保真度前提下进行等距重采样处理,筛选出曲线轮廓关键点,生成初始插值曲线.但该方法计算量过大,执行效率较低.
流式数据作为今年来的研究热点,具有多样化,时序性,海量等特点.导致流式数据在存储和分析上具有较高的难度.文献[5]对流式数据的并行聚类算法进行了研究,将并行计算的思想引入到流式数据的聚类当中,实现了数据在多台计算机上的并行处理,从而提高了数据实时处理的吞吐量和容错量.文献[6]提出一种滑动窗口下的流式数据聚类算法,通过引入窗口模型,降低了流式数据聚类过程中的算法复杂度,提高了内存的使用率.文献[7]针对流式数据的查询问题,提出基于适应性层次聚类树方法,根据流式数据的时间性质,将数据划分为不同的粒度,并提出相应的构建以及聚类查询计算方法.文献[8]提出基于DME聚类分析模型分析方法,能有效的检测海量日志流中的异常情况.但上述聚类方法在数据对比准确性上都较低.
本文针对现有方法的不足,提出基于B-Spline曲线的流式大数据事件模板构建方法,利用线性变换对同类事件进行归一化处理,通过平均值法确定B-Spline输入事件,并引入遗传算法确定B-Spline输入事件的控制节点,有效的降低了事件模板构建过程中的计算量并提高了拟合精度.
3 事件模板构建预处理方法
由于感知节点所处的地理位置和地理环境的不同,每个感知器对事件的感知存在“漂移”现象,即不同的传感器对同一事件的表示形式均不同.导致同一感知事件在时间域和幅度域都存在差异,无法直接进行事件判识,因此,首先需对其进行归一化预处理,将事件的时间域和幅度域统一为同一个尺度下.
3.1 事件与模板
在流式数据上,常常会有连续异常数据产生,并且持续一段时间,本文称这样的连续数据点称为事件.
事件:流式数据上的事件是指由异常点发起,并持续一段时间的连续异常数据的集合,表示为E=(e1,e2,e3…en),其中ei代表事件中的某个异常数据点,e1异常数据的起始点.φ为给定的正常数据阈值范围,显然ei∉φ.
在事件的基础上,提取出事件的特征,这种特征规律称为事件模板.
事件模板:流式数据事件可分为不同的类型,同一类型的事件通常具有相同或相似的特征规律.这些特征规律称为该类事件的事件模板.事件模版与事件应该具有相同的表示.
3.2 流式数据事件归一化处理
如3.1所述,事件漂移后使得感知器对同一事件的感知存在时间和幅度上的差异,这种差异导致不能使用原始的事件进行模板构建.因此,本文通过线性变换和平均值法,实现流式大数据事件的归一化处理.
•确定基本尺度事件
由于流式数据事件突发的普遍性,将会产生大量相同类型的事件,而“基本尺度事件”作为参照事件,表示其它事件都要进行线性变换到这个“基本尺度事件”的尺度下.设有m个事件,异常数据点ti为:
(1)

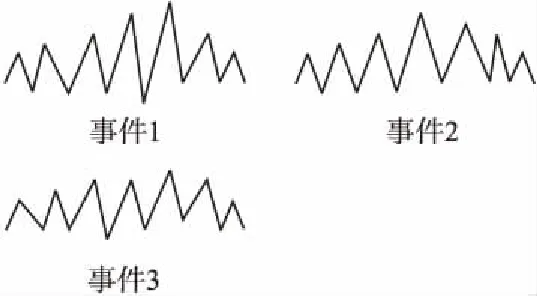
图1 流式数据中的三个同类事件Fig.1 Three similar events in streaming data
如图1所示,求得与平均事件Eavg差值绝对值最小的作为基本尺度事件.设求出的基本尺度事件为事件1,即图中黑色线段表示.
•事件的基本尺度化
获得基本尺度事件后,要进行事件的基本尺度化处理,将其它事件通过线性变换变换到基本事件的尺度下.由于线性变换前要求得变换矩阵,故使得所有事件的前3个点经过变换后与基本尺度事件的前3个点重合.例如,设有两个事件,其中一个为Ebasic,另一个为待变换事件E.假设变换矩阵为P,则有PE=Ebasic.根据E,Ebasic前3个点a1,a2,a3,b1,b2,b3,其中a1,a2,a3∈E,b1,b2,b3∈Ebasic.可以得到4个向量:x1=a2-a1,x2=a3-a2,Y1=b2-b1,Y2=b3-b2.
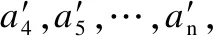


…
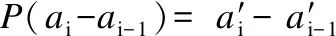
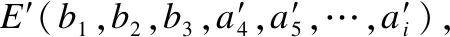
如图2所示,事件2,事件3经过基本尺度化后,结果可与Ebasic处于同一个尺度下.
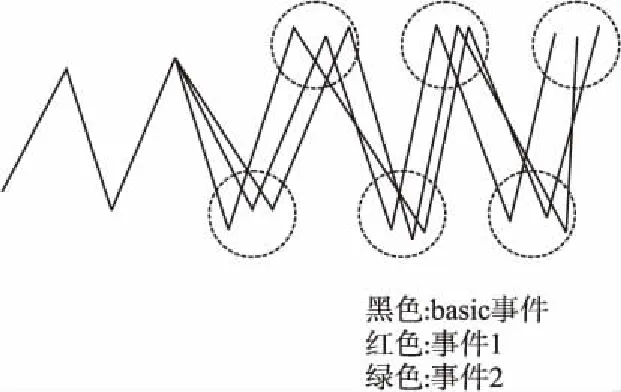
图2 事件的尺度化结果Fig.2 Scaled result of the event
•平均值法确定事件归一化数据点
经过基本尺度化变换后的事件处于同一个尺度下.前三个点重和在一起,而后面的其它点则分布在某个范围之内,利用平均值法求得相应位置上的数据点作为B-Spline输入曲线的数据点.其中,Ebasic为基本尺度事件,E1,E2,…,Em为经过尺度变换后的事件.ai1,ai2,ai3分别等于b1,b2,b3.令
(2)
求得后面B-Spline的标准拟合事件为E=(b1,b2,b3,a4,a5,a6,…,an).结果如图3所示.
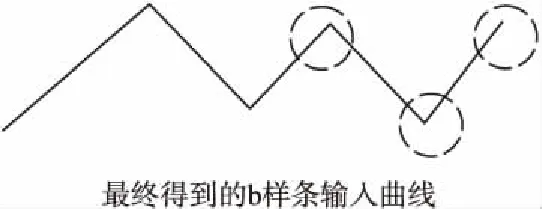
图3 B-Spline输入曲线Fig.3 B-Spine input line
如图3所示,经过平均值法处理后,相应位置上的聚集点群变成单点,作为B-Spline输入曲线上相应位置的点.B-Spline输入曲线保留了同一类事件的特征,能有效的作为事件模板构建曲线.
4 事件模板构建
如3.2节所述,通过线性变换归一方法,使事件都处于基本尺度事件的尺度下.在此基础上,得到B-Spline输入曲线,实现将多个同类事件拟合成统一化模型.B-Spline输入曲线是由大量的数据点构成,这些数据点代表了事件模版的特征.但是由于数据点太多,无法直接使用作为事件模版进行计算.本文在B-Spline基础上,使用遗传算法求出B-Spline输入曲线的控制顶点.进一步实现事件模版的构建.能有效的减少事件模版的数据点数目.
基于遗传算法的事件控制点确定方法:
通过初始化事件种群,对事件进行01编码,然后评估种群中的个体的适应程度.进而进行选择,交叉,变异操作.丛而筛选出最优的控制节点.
•事件编码方案
由于是从标准拟合事件E=(e1,e2,e3,…,en)选取m个控制顶点,所以最好的方法是采用二进制编码,将事件E=(e1,e2,e3,…,en)映射为一个二进制串S=S1S2S3…Sn,S称为事件序列,其中Si对应事件E中的ai,具体映射方法为:当Si为1时,说明ai被选中当作控制点,当Si为0时,说明ai没有被选中当作控制点.例如S=01010110101,说明事件第2、4、6、7、9、11个数据点被当作控制.对应的节点矢量T= [t0,t1,t2,…,tn+1].本文采用k=3,m=6,n=m+k,k为B-Spline阶数,m为控制点个数,所以T=[0,1,2,…,10].均匀的节点矢量方便了B-Spline事件模板的计算过程.
•事件适应度函数
由上节可以得到大量的标准拟合事件序列,但是不是所有的标准拟合事件序列都可以作为标准拟合事件的控制节点.可以采用如下适应度函数来进行事件序列的筛选.适应度函数如公式(3)所示:

(3)
其中,error代表控制节点采用标准拟合事件序列的B-Spline曲线拟合误差,α为上一代满足条件的个体事件的平均误差,α初始为零,ε代表B-Spline曲线拟合误差与上一代平均误差范围阈值.可以看出,当曲线拟合误差与平均误差的差值在合理范围内,即ε,事件的适应度函数为1,则要保留这个事件;反之,当事件的适应度函数为0时则抛弃这个事件.为了避免算法快速收敛,得不到理想的解,每当事件集合的迭代次数为10的倍数时,将ε设置为ε/2,这样能够减缓算法收敛速度.当误差范围ε趋近于零的时候,得到的事件种群就是要寻找的最优解解集,也就是欲得到的控制顶点事件序列所在的解集.选取最优解解集中误差最小的事件序列作为最终的标准拟合事件的控制顶点.
•选择算子
本文采用杰出策略来将当前最优事件序列直接传递给下一代,其余事件序列采用轮盘赌的方式做出选择,也就是采用随机算法来复制对象,但是要保证下面的两种情况事件序列被选取的几率更大.当两个事件序列误差一样的情况下,控制点较少事件序列会被优先选取;当控制点相同的情况下,控制点分布均匀事件序列会被优先选取.在流式数据的事件模板构建过程中,要保存同一类事件的大部分信息并且使得计算量较少.就要在给定误差下使得控制节点均匀分布并且数量较少.
•交叉变异
假设事件序列集合中的事件序列以Pc概率进行交叉变换,确定下来的事件序列为a1,b1,经过单点交叉变换后的个体为a2,b2,采用“零序列优先交叉”原则,即如果一个事件序列中存在连续的零序列,那么这个零序列就有可能进行交叉变换.这个变换的依据是让B-Spline的控制顶点尽可能分散均匀.然后将a1,b1,a2,b2直接复制到下一代.
本文在原有的随机概率变异的基础上,根据实际情况增加了“密集序列变异”规则.当一个事件序列中有超过三个连续的0或连续的1序列时,那么这个序列中就会有一个基因会发生变异.
具体变异方式:对于连续的1序列或0序列,将其中某个点由1变为0或由0变为1.例如某个事件序列编码为S=001010111111000,那么这个事件就可能变异为S=001010110111000.变异后的事件序列能使得节点矢量分布更加均匀,能更好的进行事件模板的构建.
5 实验与分析
实现数据集为煤矿真实感知流式数据,采样频率为每秒10000条数据,感知节点个数为10.数据规模为每秒10万数据.实验环境为Intel Core i5 3.2GHz CUP,8GB内存.
5.1 迭代次数-最优染色体控制定点数关系
设置事件序列长度L为60,标准事件集合规模k为600,节点率R范围0.5~0.7,交叉概率pc为0.75,变异概率pm为0.75,表1给出了随着迭代次数的增加,平均误差Erroravg,平均标准误差ε,以及当前最优事件序列控制点数的关系,如表1所示:
表1 迭代次数-最优染色体控制顶点数关系
Table 1 Iterator numbers-optimal chromosome control Vertex number relationship
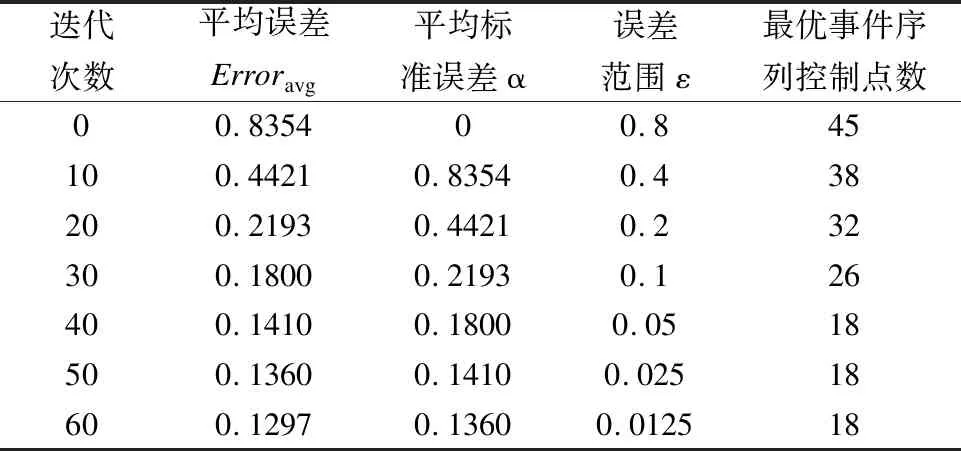
迭代次数平均误差Erroravg平均标准误差α 误差范围ε最优事件序列控制点数00.835400.8 45100.44210.83540.4 38200.2193 0.44210.232300.18000.2193 0.1 26400.14100.1800 0.0518500.13600.14100.02518600.12970.13600.012518
算法初始的平均标准误差为0,随着迭代次数的增加,种群的平均误差在不断下降,与平均标准误差的差值在不断减小,当算法迭代到40次时,算法开始收敛,最优染色体的控制点数稳定在18,因此,通过18个通知顶点就可以拟合60个数据点.
表2 同类型的事件序列求出的控制点
Table 2 Control Points obtained from events sequences of the same type
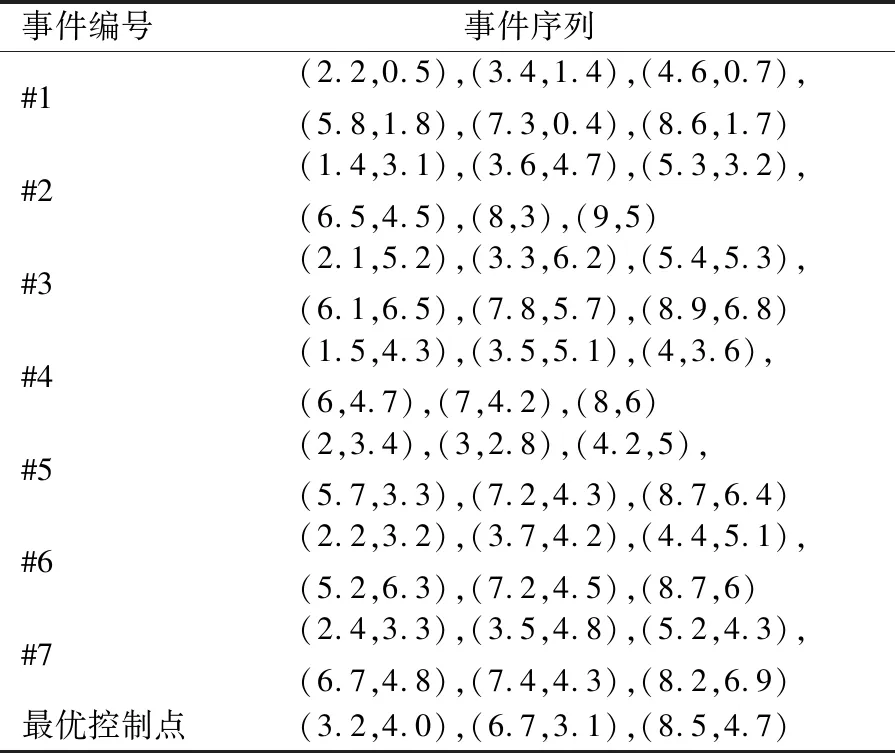
事件编号 事件序列#1(2.2,0.5),(3.4,1.4),(4.6,0.7),(5.8,1.8),(7.3,0.4),(8.6,1.7)#2(1.4,3.1),(3.6,4.7),(5.3,3.2),(6.5,4.5),(8,3),(9,5)#3(2.1,5.2),(3.3,6.2),(5.4,5.3),(6.1,6.5),(7.8,5.7),(8.9,6.8)#4(1.5,4.3),(3.5,5.1),(4,3.6),(6,4.7),(7,4.2),(8,6)#5(2,3.4),(3,2.8),(4.2,5),(5.7,3.3),(7.2,4.3),(8.7,6.4)#6(2.2,3.2),(3.7,4.2),(4.4,5.1),(5.2,6.3),(7.2,4.5),(8.7,6)#7(2.4,3.3),(3.5,4.8),(5.2,4.3),(6.7,4.8),(7.4,4.3),(8.2,6.9)最优控制点(3.2,4.0),(6.7,3.1),(8.5,4.7)
表2为给定的同类型的矿震事件下,先进行“事件归一化”,然后利用“遗传算法”求出的最优控制点.
5.2 模板构建误差对比
图4为模板构建误差对比实验结果.
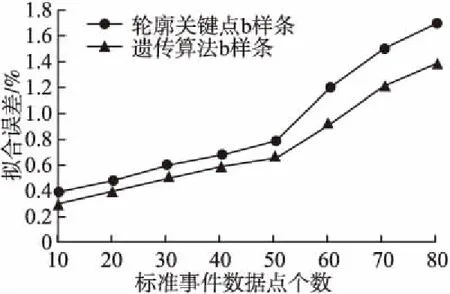
图4 模板构建误差对比Fig.4 Template construction error comparison
如图4所示,随着标准拟合事件的数据点的增多,遗传算法B-Spline的拟合误差要低于轮廓关键点B-Spline方法的拟合误差.说明文本提出的方法在模板构建方面更能精确.
5.3 模板构建时间对比
图5为基于遗传算法B-Spline与轮廓关键点B-Spline模板构建时间对比测试,实验中采用标准拟合事件的数据点数来衡量方法的模板构建时间.
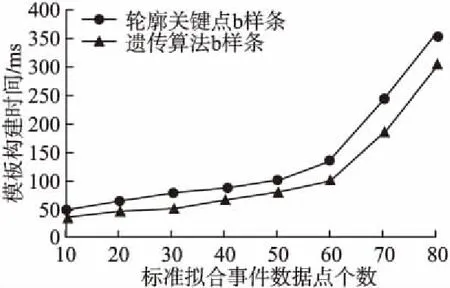
图5 模板构建时间对比Fig.5 Template construction time comparison
从图5可以看出,随着标准拟合事件的数据点的增多,采用遗传算法B-Spline方法在模板构建时间上比轮廓关键点B-Spline所花费的时间较少,说明本文提出的遗传算法B-Spline在模板构建效率上要高于原有的轮廓关键点B-Spline算法的效率.
6 总 结
本文针对流式数据上事件模板构建过程中存在的计算量过大,使用的数据节点较多,误差较大等问题进行了深入的研究.针对模板构建中存在不足,提出了一种基于B-Spline曲线的流式大数据事件模板构建方法.提出了流式数据上的事件定义和事件模板定义.确定了基本尺度事件,并且利用线性变换将同类事件进行归一化处理,最后采用平均值法得到B-Spline的标准输入曲线.针对B-Spline曲线拟合的几个重要因素,提出在均匀的节点矢量下使用遗传算法求解B-Spline的节点矢量,分别从事件编码方案,事件适应度函数,选择算子,交叉变异这几个方面来探讨具体的求解过程.从而减少了事件模板构建过程中的计算量大,数据节点多,误差较大等问题.
